 如何让Transformer在征程5上跑得既快又好?以SwinT部署为例的优化探索
如何让Transformer在征程5上跑得既快又好?以SwinT部署为例的优化探索
摘要:SwinT是目前视觉transformer模型中的典型代表,在常见视觉任务,如分类、检测、分割都有非常出色的表现。虽然在相同计算量的模型指标上,SwinT已经可以和传统CNN为基础的视觉模型相媲美,但是SwinT面向不同平台的硬件离线部署仍然存在很多问题。本文以SwinT在地平线征程5平台上的量化部署为切入点,重点介绍两个方面,一方面是如何通过调整量化配置训练得到SwinT最优的量化精度,另一方面是如何通过调整模型结构使得SwinT在征程5平台上能够得到最优的延时性能。最终在地平线征程5平台上,可以通过低于1%的量化精度损失,得到FPS为133的部署性能。同时该结果与端侧最强GPU上SwinT的部署性能相当(FPS为165)。
简介
Transformer用直接计算sequence间元素的相关性(attension)在NLP方面彻底替换了RNN/LSTM,近年来很多工作都在尝试把Transformer引入到视觉任务中来,其中ViT,SwinTransformer等都是视觉Transformer的典型代表。
SwinT主要是解决Transformer应用在图像领域的两个问题:图像的分辨率很大、视觉实体的尺寸区别很大。这都会造成Transformer在图像领域的计算代价巨大。SwinT通过层级式的transformer和移动窗口,在计算量可控的情况下,利用Transformer得到图像在不同尺度下的特征表示,从而直接在现有视觉框架下,部分替换CNN。
根据SwinT论文中提供的结论,SwinT在分类、检测、分割等经典视觉任务上都有很好的表现,但是相对于传统CNN来说,并没有绝对的优势。尤其在检测部署的帧率上,使用SwinT作为backbone的情况下,参数量比较大,同时帧率会出现显著的下降。其实涉及到Transformer相关的模型,在目前已有的计算平台上的量化部署都会遇到类似的问题。
SwinT的量化主要有三种问题:第一,算子量化(包括部署)不支持,如roll算子在旧的ONNX框架上没有支持;第二,算子自身不适合直接量化,如LayerNorm,Softmax,GeLU等,这些算子直接量化一般会造成比较大的精度损失;第三,辅助信息的输入,如位置编码,需要注意量化的方式。
SwinT的部署主要有两种问题:第一,Vector计算占比比较大,如Elementwise、Reduce等;第二,数据不规则搬运的算子比较多,如Reshape、Transpose等。这些原因导致SwinT对大算力张量计算的平台来说并不友好。
因此本文主要着重对于上面提到的,SwinT在地平线征程平台上的量化部署问题,有针对性的提出量化和部署需要改进的地方,得到SwinT在征程5平台上的最优量化部署性能,同时这种建议未来也可以推广到在征程5平台上优化任何Transformer相关的模型。
优化方法
1.基本情况
在优化之前,首先明确一下SwinT在征程5平台上支持的基本情况,这些情况能够保证SwinT可以在征程5平台上运行起来,然后才能进一步讨论优化方向和优化思路。
算子支持情况
SwinT公版模型需要的所有算子列表如下:
reshape、permute、transpose、view、roll、LayerNorm、matmul、mean、mul、add、flatten、masked_fill、unsqueeze、AdaptiveAvgPool1d、GeLU、Linear。
目前,在地平线的量化工具和征程5平台上,以上SwinT需要的所有算子都是可以完全支持的,这是保证SwinT能够在征程5平台上正常运行的基础。
量化精度
在SwinT的量化过程中,使用Calibration+QAT的量化方式得到最终的SwinT的量化精度。由于SwinT中所有算子的量化是完全支持的,那么得到初版的量化精度是非常简单的。
不过在默认的量化配置下,初步的量化精度只有76.90%(浮点80.58%),相对于浮点下降接近于4个点。这是比较明显的量化损失。需要说明的是,默认的量化配置是指全局采用int8的量化方式。
部署情况
SwinT模型在地平线征程5平台的初次部署,性能极低,FPS小于1,几乎处于不可用的状态。通过分析发现,SwinT相比于传统CNN的模型,Vector计算占比比较多,如Elementwise、Reduce等;同时数据不规则搬运的算子较多,如Reshape,Transpose等。这些特性对大算力张量计算的征程5平台来讲极不友好。
这里有一些征程5平台部署SwinT的情况分析:
SwinT模型张量Tensor与向量Vector的计算比例大约是218:1(将矩阵乘运算归类为张量运算),而征程5平台的实际张量运算能力与向量运算的计算比例远高于此,导致SwinT在征程5平台的利用率不高。
Reshape / Transpose 等数据搬运算子占比较高。在Transformer之前的CNN模型没有这方面的需求,因此初次处理SwinT相关的Transformer模型时,这类算子除了本身的实现方式,功能、性能优化都不太完善。
2.量化精度优化
因为SwinT的量化训练,主要是采用Calibration+QAT的方式来实现的,因此量化精度的优化,主要从两个方面入手,分别是算子的支持方式、量化训练的参数配置。
算子的支持方式
算子的支持方式,主要是针对一些量化不友好的算子,在中间结果引入int16的量化方式,这在地平线征程5平台上是可以有效支持的。常见的量化不友好算子,如LayerNorm,SoftMax等。以LayerNorm为例:其量化方法是使用多个细粒度的算子(如mul,add,mean,sqrt)拼凑起来的。为了保证量化的精度,尤其是mean的操作,因此LayerNorm除了在输入输出端使用int8量化之外,中间的结果均采用int16的量化方法。
使用方式:参考目前地平线提供的QAT量化工具,浮点算子到QAT算子的自动映射。用户只需要定义浮点模型,由QAT工具自动实现浮点和量化算子的映射。因此大部分量化算子的实现方式,用户是不需要感知的,尤其像LayerNorm和SoftMax这种算子的量化方式,工具本身默认提供int16的量化方式,用户只需要正常使用社区的浮点算子即可,而不需要再手动设置QAT相关的配置。
注:需要说明的是,LayerNorm有时候需要使用QAT量化工具提供的浮点算子,但原因在部署优化中会提到,和算子量化方式的支持没有关系。
量化训练的参数配置
量化训练的参数配置主要分为量化配置和训练的超参配置。量化配置除了算子自身的实现方式外,主要是针对输入输出的调整,输入分为两种类型,如果是图像输入,可以采用固定的scale(一般为1/128.0);如果是辅助信息输入,如位置编码,需要采用统计的动态scale,才能使得量化过程保留更多输入信息。而对于模型输出默认采用更高精度的方式(如int32)即可。
使用方式:量化训练过程的超参设置,则比较简单,常见的调整内容如Lr大小,Epoch长度等,详细内容参考量化训练工具提供的Debug文档。
3.部署优化
部署优化的前提是不改变模型的结构和计算逻辑,不需要重训模型,模型参数可以等价复用。基于这样的原则,从编译器的角度,结合SwinT模型的计算方式,对SwinT在征程5平台上的部署进行针对性的优化。
上文中分析了SwinT的部署主要有Vector计算占比过高和不规则数据搬运算子较多这两个问题,因此,整个编译器优化的方式,其实就是通过软件优化Tile,提高数据复用,减少了数据加载带宽,算子合并实现优化。
接下来重点讲一下,从编译器的思路出发,根据编译器可以优化的内容,要么编译器内部优化,要么模型有针对性的进行调整,最终可以得到SwinT部署的最优性能。需要注意的是,如果是模型需要针对性调整的地方,会在具体的使用方式中体现出来。如果不需要调整,属于编译器内部优化的,则会自动沉淀到编译器默认使用方式中去,直接使用即可。
算子映射的优化
将不同的算子进行灵活的映射,充分利用硬件资源,增加并行计算的机会。如使用Conv运算部件实现Reduce操作;使用MatMul实现Transpose等。
matmul的优化使用方式:

LayerNorm的优化使用方式,这里是单独的transpose优化,和上文中用户不需要感知的int16量化(默认使用)区分开来:

算子优化
算子优化主要是针对算子实现方式的单独优化,如Reshape/Transpose算子Tile优化,Batch MatMul的支持优化等。
使用方式:其中Batch MatMul的优化,内部batch级别的循环展开的Tile优化,由量化工具和编译器内部完成,用户不需要感知。
算子合并
征程5平台是张量运算处理器,数据排布是多维表示,而Reshape,Transpose的表达语义是基于CPU/GPU的线性排布。连续的Reshape & Transpose操作,例如window partition、window reverse,征程5平台可只进行一次数据搬运实现。
编译器内部,连续的reshape可合并成一条reshape,连续的transpose算子可合并成一条permute,征程5平台可一次搬运完成。
而window partition,window reverse则被封装成独立的算子,在模型,量化,部署阶段,直接使用即可,这样可以让编译器在部署过程中获得最佳性能。
使用方式:

其他图优化
对于pixel to pixel计算的算子或者数据搬运的算子(如elementwise,concat/split的部分轴),reshape/transpose算子可穿透这些算子,前后移动reshape/transpose穿透以上算子,移动后可进行算子合并的优化。
使用方式:这些优化由编译器内部完成,用户不需要感知。
4维高效支持
地平线征程5平台最早针对的是以CNN为基础的图像处理,但在实践过程中,逐渐衍生出支持语音,Transformer等类型的模型。不过以CNN为基础的模型仍然是效率最高的模型,这一点在编译器内部的体现就是4d-Tensor仍然是最高效的支持方式。
如果不是4d-Tensor的话,很多算子编译器内部也会主动转成4d(某些维度为1)来做,结合编译器常规的padding方式(如2H16W8C/2H32W4C对齐),会导致一些计算如Conv,MatMul的效率很低,因为多了很多无效的计算。
这一点在模型上的体现就是,可以使用常规的4维算子替换原来任意维度的设置,避免不必要的冗余计算。常见的替换方式如下,中间配合任意维度的reshape,view,transpose可以完成等价替换。
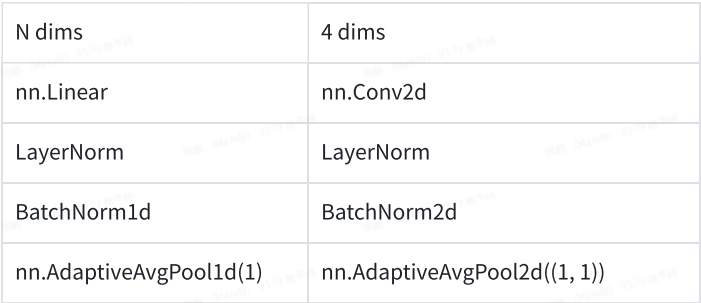
使用方式(以patch merging为例):

实验结果
1.SwinT在征程5平台优化结论
量化效果

部署效果
通过优化,SwinT在征程5平台上,可以达到的FPS为133。
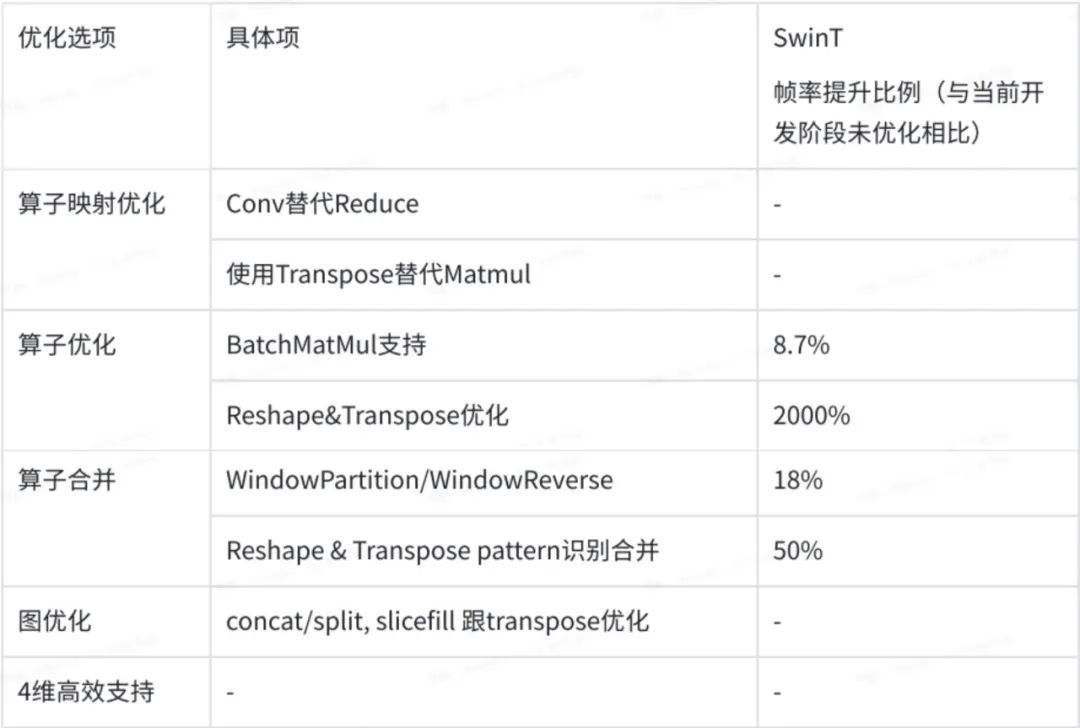
注:-代表缺失实际的统计数据
参考SwinT在端侧最强GPU上的部署性能(FPS=165),地平线征程5平台部署SwinT模型,在有性能保证的情况下,具有一定的精度优势。
2.Transformer在征程5平台上的优化建议
在完成SwinT在征程5平台上的高效部署之后,其实也可以得出常见的Transformer征程5平台上的优化思路。这里简单列一些方向供参考。
使用已封装算子
上面提到的window partition,window reverse,在模型层面封装成一个算子,编译器只进行一次数据搬运即可完成高效部署。因此建议在模型搭建阶段使用已经封装好的算子,其他常见的还有LayerNorm,MatMul等。未来地平线也会提供更多定制算子的高效实现,如MultiHeadAttention等。
Tensor的对齐建议
征程5平台运算的时候有最小的对齐单位,并且不同的算子对齐不一致,以下简单列出常见的征程5平台运算部件的计算对齐要求:

2H16W8C,表示计算的时候H方向对齐到2, W方向对齐到16,C方向对齐到8,例如:

以上elementwise add 实际计算为数据对齐后的大小[1,2,3344,2232], 所以尽量让算子的对齐浪费少些。如果像layernorm中有连续的如上的elementwise操作,其实可以将Tensor reshape为[1,2,1666, 2227] 再进行连续的elementwise计算。
按照征程5平台的计算对齐合理的构建Tensor大小能提高征程5平台的计算利用率。因此结合SwinT部署优化中的4维高效支持的建议:4d-Tensor,结合合理的大小设置,可以稳定提供部署的利用率。
减少算子间的Reorder
根据Tensor对齐建议中提到的征程5平台不同的运算部件有不同的对齐,在不同运算部件切换的时候,除了计算对齐浪费的开销,还有数据Reorder的开销,即从2H16W8C 向256C转换的开销。所以在此建议构建模型顺序的时候尽量避免不同计算对齐的算子连续横跳。
在此给一些优化的建议,比如Conv->ReduceSum->Conv串接的模型,其实reduce sum也可以替换成用conv实现,比如reduce on C可以构建为input channel = C, output channel = 1的conv, reduce on H/W 可以构建为kernel_h = H or kernel_w = W 的conv。
总结
本文通过对SwinT在地平线征程5平台上量化部署的优化,使得模型在该平台上用低于1%的量化精度损失,得到FPS为133的部署性能,与主流竞品相比效果相当。同时,通过SwinT的部署经验,推广到所有的Transformer,给出Transformer在征程5平台上高效部署的优化建议。
审核编辑:汤梓红
- gpu
+关注
关注
27文章
4553浏览量
127963 - 模型
+关注
关注
1文章
2998浏览量
48208 - Transformer
+关注
关注
0文章
135浏览量
5933 - nlp
+关注
关注
1文章
481浏览量
21913 - 征程5
+关注
关注
0文章
14浏览量
2656
原文标题:如何让Transformer在征程5上跑得既快又好?以SwinT部署为例的优化探索
文章出处:【微信号:horizonrobotics,微信公众号:地平线HorizonRobotics】欢迎添加关注!文章转载请注明出处。
发布评论请先登录
相关推荐
为什么transformer性能这么好?Transformer的上下文学习能力是哪来的?
跑在ram里快还是跑在flash里快?
如何更改ABBYY PDFTransformer+界面语言
如何更改ABBYY PDFTransformer+旋转页面
以贴片天线设计为例的HFSS在天线设计中的应用介绍
以hello world为例介绍如何让代码部署并运行在ARM平台上
你了解在单GPU上就可以运行的Transformer模型吗
如何让WindowsXP跑得更快更稳
我们可以使用transformer来干什么?






 工商网监
工商网监
评论