 基于机器学习的水体化学需氧量高光谱反演模型对比研究
基于机器学习的水体化学需氧量高光谱反演模型对比研究
引言
化学需氧量(COD)是以化学方法测量水样中需要被氧化的还原性物质的量。水样在一定条件下的COD以氧化1升水样中还原性物质缩小化的氧化剂的量为指标,折算成每升水样全部被氧化后,需要的氧的毫克数,以mg·L-1来表示。COD测试可以很容易地量化水中有机物的含量。COD最常见的应用是量化地表水(如湖泊和河流)或废水中可氧化污染物的量,在水质监测中起到了巨大的作用。传统的有重铬酸盐滴定法和分光光度法等方法,电化学方法和流动注射分析法用于COD检测,但这些检测方法都存在检测周期较长、消耗试剂等缺点,对水体的批量检测也难以实现。
而利用高光谱技术和机器学习手段对水质参数进行反演近期已成为国内外热点研究问题。高光谱技术能够获得物体连续的光谱信息,近年来逐步应用于水农产品检测、生植被和水资源调控等领域。在水质参数高光谱反演建模中,国内外学者采取机器学习方法对不同水质参数进行建模,如总氮、总磷、水质浊度、一般悬浮物、化学需氧量等,并取得了一定成果。
实验部分
2.1 预处理
高光谱数据通常包含由相机或仪器产生的随机噪声和光谱变化。光谱预处理可以减少或消除数据中与自身性质无关的信息,降低模型的复杂性,提高数据和模型的可解释性(鲁棒性和准确性)。光谱数据的预处理在进行多变量分析之前是必不可少的。SG平滑能够使光谱曲线平滑,MSC方法能够消除基线漂移和平移现象。采用SG平滑、MSC以及SG平滑结合MSC光谱预处理手段对原始光谱进行预处理并进行比较。
2.2 特征波段提取
高光谱波段由大量的波段组成,有些波段的相关性较高而且存在冗余以及噪声等。对特征波段的提取在一定程度上可以规避这两种情况。
2.3 反演模型
选取线性回归、随机森林、AdaBoost、XGBoost四种机器学习建模方法。线性回归是一种确定两个或多个变量间相互依赖定量关系的机器学习方法;随机森林算法是决策树的集成,通过平均决策树可以大大降低过拟合的风险,是比单一决策树性能更优的模型;Adaboost是将弱学习器结合创造一个强学习器的机器学习方法;XGBoost是一种改进的梯度提升迭代决策树(GBDT)算法。
2.4 模型评估
采取RMSE,R²和RPD三个指标对反演模型进行对比和评价。
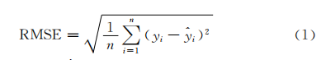

结果与讨论
3.1 原始光谱及数值统计分析
图1为样本水体的原始光谱曲线,水体在550~600nm的反射率较高,在700~750nm的反射率较低。从图中可以看出每个水体样本曲线的变化趋势类似,没有呈现较大的差异,而且难以直接通过光谱曲线对其COD含量进行判断。水体样本的COD值统计结果如表1所示。
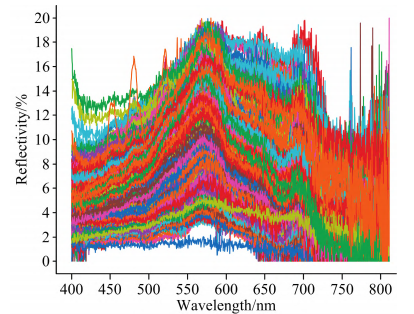
图1 水体样本原始光谱反射率曲线
表1 COD含量描述统计分析
图 2 土壤样本去包络的反射率
3.2 光谱预处理结果
使用三种光谱预处理方法对原始光谱进行预处理,预处理后的光谱分布如图3(a,b,c)所示。经过光谱预处理后,高光谱的数据质量得到了一定改善,但还是无法直观的从光谱曲线上判断水体的COD含量,因此还需要通过机器学习方法对其建模进行分析。
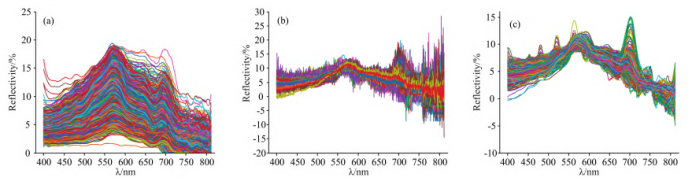
图3 水体样本预处理后的光谱分布
3.3 反演模型
对原始光谱数据和三种不同的预处理方法分别使用四种机器学习模型建模。模型的反演精度与建模的训练时间如表2—表5所示。由表2—表5中数据可以看到,XGBoost在原始光谱以及三种经过预处理数据上的建模精度均优于其他模型,且训练时间小于随机森林模型以及Adaboost模型。线性回归所建的反演模型表现较差,说明COD与光谱数据并没有直接的线性关系。在所有的模型中,通过XGBooost对经过SG平滑和MSC处理的数据所建的反演模型精度最高,其中R2为0.92,RMSE为7.1mg·L-1,RPD为3.4。通过不同预处理方式所得的XGBoost反演模型散点图如图4(a—d)所示。
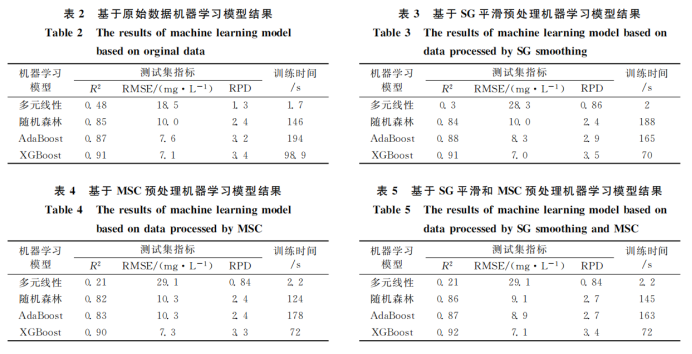
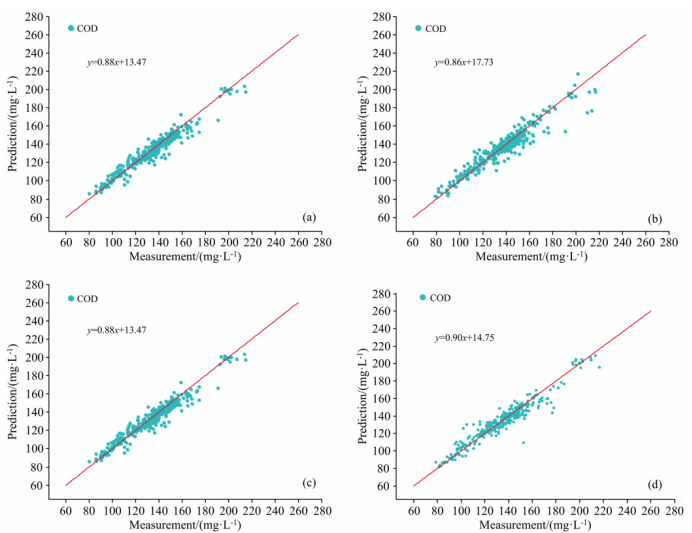
图4 不同预处理方法下XGBoost反演模型COD预测值与实测值关系散点图
结论
在实际生产过程中可根据实际需求,综合考虑模型精度、模型训练时间等因素进行模型的选择。研究结果表明,基于机器学习的高光谱COD反演模型精度可以达到较高水平,为机器学习在高光谱水质监测领域的应用提供了参考。此外,机器学习模型可解释性需要进一步研究。
欢迎关注公众号:莱森光学,了解更多光谱知识。
莱森光学(深圳)有限公司是一家提供光机电一体化集成解决方案的高科技公司,我们专注于光谱传感和光电应用系统的研发、生产和销售。
审核编辑黄宇
-
机器学习
+关注
关注
66文章
8406浏览量
132556 -
高光谱
+关注
关注
0文章
330浏览量
9934
发布评论请先 登录
相关推荐
光学知识水体COD光谱特性分析
水体参数高光谱反演模型对比研究

机器学习在遥感高光谱图像中的应用
机器学习中的无模型强化学习算法及研究综述

模型化深度强化学习应用研究综述

利用反射率、偏振度光谱特性进行叶绿素浓度反演
高光谱遥感技术在悬沙水体研究中的应用说明
高光谱遥感技术在地质领域的应用研究
手持式地物光谱仪对水体叶绿素的光谱特性测试研究
高光谱技术估测烟草生化成分的机理和研究进展
基于高光谱的模拟壁画盐含量反演
内陆水体藻蓝蛋白遥感反演研究进展





 工商网监
工商网监
评论