 探秘消息在RocketMQ中短暂而又精彩的一生
探秘消息在RocketMQ中短暂而又精彩的一生
这篇文章我准备来聊一聊RocketMQ消息的一生。
不知你是否跟我一样,在使用RocketMQ的时候也有很多的疑惑:
- 消息是如何发送的,队列是如何选择的?
- 消息是如何存储的,是如何保证读写的高性能?
- RocketMQ是如何实现消息的快速查找的?
- RocketMQ是如何实现高可用的?
- 消息是在什么时候会被清除?
- ...
本文就通过探讨上述问题来探秘消息在RocketMQ中短暂而又精彩的一生。
核心概念
- NameServer :可以理解为是一个注册中心,主要是用来保存topic路由信息,管理Broker。在NameServer的集群中,NameServer与NameServer之间是没有任何通信的。
- Broker :核心的一个角色,主要是用来保存消息的,在启动时会向NameServer进行注册。Broker实例可以有很多个,相同的BrokerName可以称为一个Broker组,每个Broker组只保存一部分消息。
- topic :可以理解为一个消息的集合的名字,一个topic可以分布在不同的Broker组下。
- 队列(queue) :一个topic可以有很多队列,默认是一个topic在同一个Broker组中是4个。如果一个topic现在在2个Broker组中,那么就有可能有8个队列。
- 生产者 :生产消息的一方就是生产者
- 生产者组 :一个生产者组可以有很多生产者,只需要在创建生产者的时候指定生产者组,那么这个生产者就在那个生产者组
- 消费者 :用来消费生产者消息的一方
- 消费者组 :跟生产者一样,每个消费者都有所在的消费者组,一个消费者组可以有很多的消费者,不同的消费者组消费消息是互不影响的。
基于 Spring Boot + MyBatis Plus + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
- 项目地址:https://github.com/YunaiV/ruoyi-vue-pro
- 视频教程:https://doc.iocoder.cn/video/
消息诞生与发送
我们都知道,消息是由业务系统在运行过程产生的,当我们的业务系统产生了消息,我们就可以调用RocketMQ提供的API向RocketMQ发送消息,就像下面这样
DefaultMQProducerproducer=newDefaultMQProducer("sanyouProducer");
//指定NameServer的地址
producer.setNamesrvAddr("localhost:9876");
//启动生产者
producer.start();
//省略代码。。
Messagemsg=newMessage("sanyouTopic","TagA","三友的java日记".getBytes(RemotingHelper.DEFAULT_CHARSET));
//发送消息并得到消息的发送结果,然后打印
SendResultsendResult=producer.send(msg);
虽然代码很简单,我们不经意间可能会思考如下问题:
- 代码中只设置了NameServer的地址,那么生产者是如何知道Broker所在机器的地址,然后向Broker发送消息的?
- 一个topic会有很多队列,那么生产者是如何选择哪个队列发送消息?
- 消息一旦发送失败了怎么办?
路由表
当Broker在启动的过程中,Broker就会往NameServer注册自己这个Broker的信息,这些信息就包括自身所在服务器的ip和端口,还有就是自己这个Broker有哪些topic和对应的队列信息,这些信息就是路由信息,后面就统一称为路由表。
 Broker向NameServer注册
Broker向NameServer注册当生产者启动的时候,会从NameServer中拉取到路由表,缓存到本地,同时会开启一个定时任务,默认是每隔30s从NameServer中重新拉取路由信息,更新本地缓存。
队列的选择
好了通过上一节我们就明白了,原来生产者会从NameServer拉取到Broker的路由表的信息,这样生产者就知道了topic对应的队列的信息了。
但是由于一个topic可能会有很多的队列,那么应该将消息发送到哪个队列上呢?
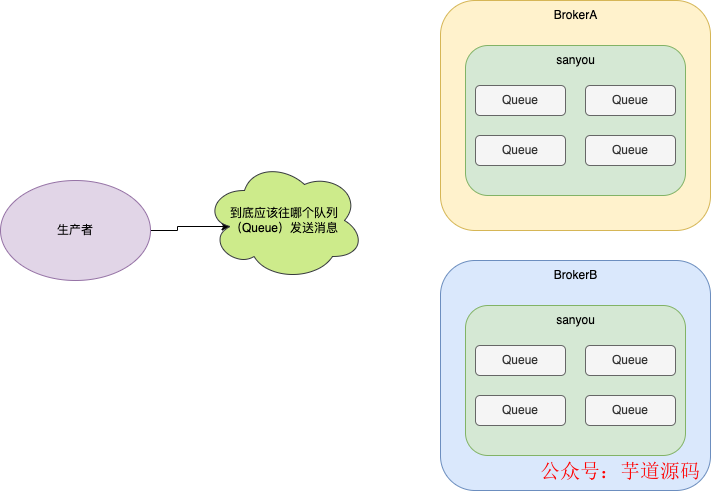
面对这种情况,RocketMQ提供了两种消息队列的选择算法。
- 轮询算法
- 最小投递延迟算法
轮询算法 就是一个队列一个队列发送消息,这些就能保证消息能够均匀分布在不同的队列底下,这也是RocketMQ默认的队列选择算法。
但是由于机器性能或者其它情况可能会出现某些Broker上的Queue可能投递延迟较严重,这样就会导致生产者不能及时发消息,造成生产者压力过大的问题。所以RocketMQ提供了最小投递延迟算法。
最小投递延迟算法 每次消息投递的时候会统计投递的时间延迟,在选择队列的时候会优先选择投递延迟时间小的队列。这种算法可能会导致消息分布不均匀的问题。
如果你想启用最小投递延迟算法,只需要按如下方法设置一下即可。
producer.setSendLatencyFaultEnable(true);
当然除了上述两种队列选择算法之外,你也可以自定义队列选择算法,只需要实现MessageQueueSelector接口,在发送消息的时候指定即可。
SendResultsendResult=producer.send(msg,newMessageQueueSelector(){
@Override
publicMessageQueueselect(Listmqs,Messagemsg,Objectarg) {
//从mqs中选择一个队列
returnnull;
}
},newObject());
MessageQueueSelector RocketMQ也提供了三种实现
- 随机算法
- Hash算法
- 根据机房选择算法(空实现)
其它特殊情况处理
发送异常处理
终于,不论是通过RocketMQ默认的队列选择算法也好,又或是自定义队列选择算法也罢,终于选择到了一个队列,那么此时就可以跟这个队列所在的Broker机器建立网络连接,然后通过网络请求将消息发送到Broker上。
但是不幸的事发生了,Broker挂了,又或者是机器负载太高了,发送消息超时了,那么此时RockerMQ就会进行重试。
RockerMQ重试其实很简单,就是重新选择其它Broker机器中的一个队列进行消息发送,默认会重试两次。
当然如果你的机器比较多,可以将设置重试次数设置大点。
producer.setRetryTimesWhenSendFailed(10);
消息过大的处理
一般情况下,消息的内容都不会太大,但是在一些特殊的场景中,消息内容可能会出现很大的情况。
遇到这种消息过大的情况,比如在默认情况下消息大小超过4M的时候,RocketMQ是会对消息进行压缩之后再发送到Broker上,这样在消息发送的时候就可以减少网络资源的占用。
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
消息存储
好了,经过以上环节Broker终于成功接收到了生产者发送的消息了,但是为了能够保证Broker重启之后消息也不丢失,此时就需要将消息持久化到磁盘。
如何保证高性能读写
由于涉及到消息持久化操作,就涉及到磁盘数据的读写操作,那么如何实现文件的高性能读写呢?这里就不得不提到的一个叫零拷贝的技术。
传统IO读写方式
说零拷贝之前,先说一下传统的IO读写方式。
比如现在需要将磁盘文件通过网络传输出去,那么整个传统的IO读写模型如下图所示
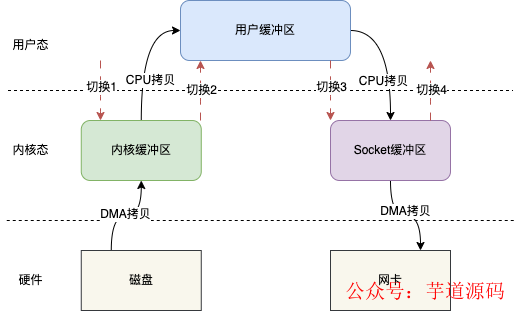
传统的IO读写其实就是read + write的操作,整个过程会分为如下几步
- 用户调用read()方法,开始读取数据,此时发生一次上下文从用户态到内核态的切换,也就是图示的切换1
- 将磁盘数据通过DMA拷贝到内核缓存区
- 将内核缓存区的数据拷贝到用户缓冲区,这样用户,也就是我们写的代码就能拿到文件的数据
- read()方法返回,此时就会从内核态切换到用户态,也就是图示的切换2
- 当我们拿到数据之后,就可以调用write()方法,此时上下文会从用户态切换到内核态,即图示切换3
- CPU将用户缓冲区的数据拷贝到Socket缓冲区
- 将Socket缓冲区数据拷贝至网卡
- write()方法返回,上下文重新从内核态切换到用户态,即图示切换4
整个过程发生了4次上下文切换和4次数据的拷贝,这在高并发场景下肯定会严重影响读写性能。
所以为了减少上下文切换次数和数据拷贝次数,就引入了零拷贝技术。
零拷贝
零拷贝技术是一个思想,指的是指计算机执行操作时,CPU不需要先将数据从某处内存复制到另一个特定区域。
实现零拷贝的有以下几种方式
- mmap()
- sendfile()
mmap()
mmap(memory map)是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。
简单地说就是内核缓冲区和应用缓冲区共享,从而减少了从读缓冲区到用户缓冲区的一次CPU拷贝。
比如基于mmap,上述的IO读写模型就可以变成这样。
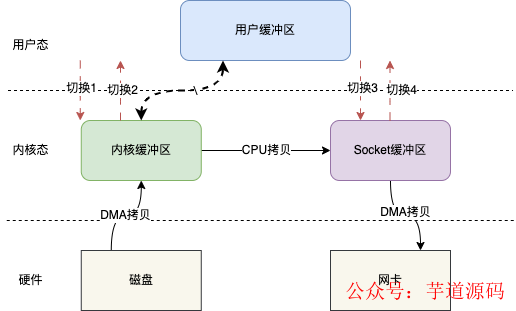
基于mmap IO读写其实就变成mmap + write的操作,也就是用mmap替代传统IO中的read操作。
当用户发起mmap调用的时候会发生上下文切换1,进行内存映射,然后数据被拷贝到内核缓冲区,mmap返回,发生上下文切换2;随后用户调用write,发生上下文切换3,将内核缓冲区的数据拷贝到Socket缓冲区,write返回,发生上下文切换4。
整个过程相比于传统IO主要是不用将内核缓冲区的数据拷贝到用户缓冲区,而是直接将数据拷贝到Socket缓冲区。上下文切换的次数仍然是4次,但是拷贝次数只有3次,少了一次CPU拷贝。
在Java中,提供了相应的api可以实现mmap,当然底层也还是调用Linux系统的mmap()实现的
FileChannelfileChannel=newRandomAccessFile("test.txt","rw").getChannel();
MappedByteBuffermappedByteBuffer=fileChannel.map(FileChannel.MapMode.READ_WRITE,0,fileChannel.size());
如上代码拿到MappedByteBuffer,之后就可以基于MappedByteBuffer去读写。
sendfile()
sendfile()跟mmap()一样,也会减少一次CPU拷贝,但是它同时也会减少两次上下文切换。
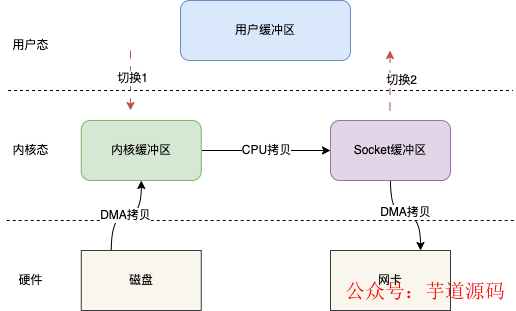
如图,用户在发起sendfile()调用时会发生切换1,之后数据通过DMA拷贝到内核缓冲区,之后再将内核缓冲区的数据CPU拷贝到Socket缓冲区,最后拷贝到网卡,sendfile()返回,发生切换2。
同样地,Java也提供了相应的api,底层还是操作系统的sendfile()
FileChannelchannel=FileChannel.open(Paths.get("./test.txt"),StandardOpenOption.WRITE,StandardOpenOption.CREATE);
//调用transferTo方法向目标数据传输
channel.transferTo(position,len,target);
通过FileChannel的transferTo方法即可实现。
transferTo方法(sendfile)主要是用于文件传输,比如将文件传输到另一个文件,又或者是网络。
在如上代码中,并没有文件的读写操作,而是直接将文件的数据传输到target目标缓冲区,也就是说,sendfile是无法知道文件的具体的数据的;但是mmap不一样,他是可以修改内核缓冲区的数据的。假设如果需要对文件的内容进行修改之后再传输,只有mmap可以满足。
通过上面的一些介绍,主要就是一个结论,那就是基于零拷贝技术,可以减少CPU的拷贝次数和上下文切换次数,从而可以实现文件高效的读写操作。
RocketMQ内部主要是使用基于mmap实现的零拷贝(其实就是调用上述提到的api),用来读写文件,这也是RocketMQ为什么快的一个很重要原因。
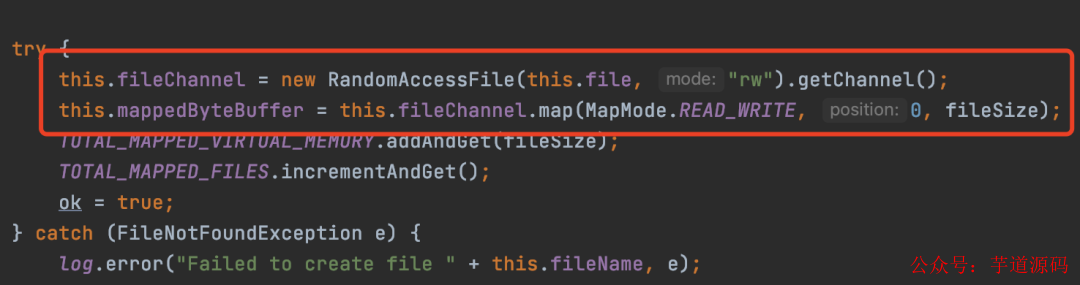 RocketMQ中使用mmap代码
RocketMQ中使用mmap代码
CommitLog
前面提到消息需要持久化到磁盘文件中,而CommitLog其实就是存储消息的文件的一个称呼,所有的消息都存在CommitLog中,一个Broker实例只有一个CommitLog。
由于消息数据可能会很大,同时兼顾内存映射的效率,不可能将所有消息都写到同一个文件中,所以CommitLog在物理磁盘文件上被分为多个磁盘文件,每个文件默认的固定大小是1G。

当生产者将消息发送过来的时候,就会将消息按照顺序写到文件中,当文件空间不足时,就会重新建一个新的文件,消息写到新的文件中。

消息在写入到文件时,不仅仅会包含消息本身的数据,也会包含其它的对消息进行描述的数据,比如这个消息来自哪台机器、消息是哪个topic的、消息的长度等等,这些数据会和消息本身按照一定的顺序同时写到文件中,所以图示的消息其实是包含消息的描述信息的。
刷盘机制
RocketMQ在将消息写到CommitLog文件中时并不是直接就写到文件中,而是先写到PageCache,也就是前面说的内核缓存区,所以RocketMQ提供了两种刷盘机制,来将内核缓存区的数据刷到磁盘。
异步刷盘
异步刷盘就是指Broker将消息写到PageCache的时候,就直接返回给生产者说消息存储成功了,然后通过另一个后台线程来将消息刷到磁盘,这个后台线程是在RokcetMQ启动的时候就会开启。异步刷盘方式也是RocketMQ默认的刷盘方式。
其实RocketMQ的异步刷盘也有两种不同的方式,一种是固定时间,默认是每隔0.5s就会刷一次盘;另一种就是频率会快点,就是每存一次消息就会通知去刷盘,但不会去等待刷盘的结果,同时如果0.5s内没被通知去刷盘,也会主动去刷一次盘。默认的是第一种固定时间的方式。
同步刷盘
同步刷盘就是指Broker将消息写到PageCache的时候,会等待异步线程将消息成功刷到磁盘之后再返回给生产者说消息存储成功。
同步刷盘相对于异步刷盘来说消息的可靠性更高,因为异步刷盘可能出现消息并没有成功刷到磁盘时,机器就宕机的情况,此时消息就丢了;但是同步刷盘需要等待消息刷到磁盘,那么相比异步刷盘吞吐量会降低。所以同步刷盘适合那种对数据可靠性要求高的场景。
如果你需要使用同步刷盘机制,只需要在配置文件指定一下刷盘机制即可。
高可用
在说高可用之前,先来完善一下前面的一些概念。
在前面介绍概念的时候也说过,一个RokcetMQ中可以有很多个Broker实例,相同的BrokerName称为一个组,同一个Broker组下每个Broker实例保存的消息是一样的,不同的Broker组保存的消息是不一样的。
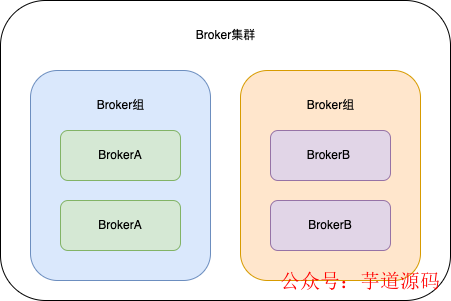
如图所示,两个BrokerA实例组成了一个Broker组,两个BrokerB实例也组成了一个Broker组。
前面说过,每个Broker实例都有一个CommitLog文件来存储消息的。那么两个BrokerA实例他们CommitLog文件存储的消息是一样的,两个BrokerB实例他们CommitLog文件存储的消息也是一样的。
那么BrokerA和BrokerB存的消息不一样是什么意思呢?
其实很容易理解,假设现在有个topicA存在BrokerA和BrokerB上,那么topicA在BrokerA和BrokerB默认都会有4个队列。
前面在说发消息的时候需要选择一个队列进行消息的发送,假设第一次选择了BrokerA上的队列发送消息,那么此时这条消息就存在BrokerA上,假设第二次选择了BrokerB上的队列发送消息,那么那么此时这条消息就存在BrokerB上,所以说BrokerA和BrokerB存的消息是不一样的。
那么为什么同一个Broker组内的Broker存储的消息是一样的呢?其实比较容易猜到,就是为了保证Broker的高可用,这样就算Broker组中的某个Broker挂了,这个Broker组依然可以对外提供服务。
那么如何实现同Broker组的Broker存的消息数据相同的呢?这就不得不提到Broker的高可用模式。
RocketMQ提供了两种Broker的高可用模式
- 主从同步模式
- Dledger模式
主从同步模式
在主从同步模式下,在启动的时候需要在配置文件中指定BrokerId,在同一个Broker组中,BrokerId为0的是主节点(master),其余为从节点(slave)。
当生产者将消息写入到主节点是,主节点会将消息内容同步到从节点机器上,这样一旦主节点宕机,从节点机器依然可以提供服务。
主从同步主要同步两部分数据
- topic等数据
- 消息
topic等数据是从节点每隔10s钟主动去主节点拉取,然后更新本身缓存的数据。
消息是主节点主动推送到从节点的。当主节点收到消息之后,会将消息通过两者之间建立的网络连接发送出去,从节点接收到消息之后,写到CommitLog即可。
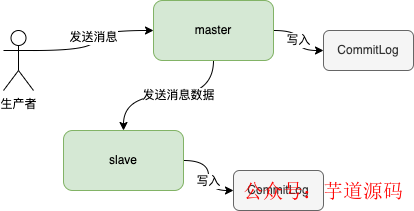
从节点有两种方式知道主节点所在服务器的地址,第一种就是在配置文件指定;第二种就是从节点在注册到NameServer的时候会返回主节点的地址。
主从同步模式有一个比较严重的问题就是如果集群中的主节点挂了,这时需要人为进行干预,手动进行重启或者切换操作,而非集群自己从从节点中选择一个节点升级为主节点。
为了解决上述的问题,所以RocketMQ在4.5.0就引入了Dledger模式。
Dledger模式
在Dledger模式下的集群会基于Raft协议选出一个节点作为leader节点,当leader节点挂了后,会从follower中自动选出一个节点升级成为leader节点。所以Dledger模式解决了主从模式下无法自动选择主节点的问题。
在Dledger集群中,leader节点负责写入消息,当消息写入leader节点之后,leader会将消息同步到follower节点,当集群中过半数(节点数/2 +1)节点都成功写入了消息,这条消息才算真正写成功。
至于选举的细节,这里就不多说了,有兴趣的可以自行谷歌,还是挺有意思的。
消息消费
终于,在生产者成功发送消息到Broker,Broker在成功存储消息之后,消费者要消费消息了。
消费者在启动的时候会从NameSrever拉取消费者订阅的topic的路由信息,这样就知道订阅的topic有哪些queue,以及queue所在Broker的地址信息。
为什么消费者需要知道topic对应的哪些queue呢?
其实主要是因为消费者在消费消息的时候是以队列为消费单元的,消费者需要告诉Broker拉取的是哪个队列的消息,至于如何拉到消息的,后面再说。

消费的两种模式
前面说过,消费者是有个消费者组的概念,在启动消费者的时候会指定该消费者属于哪个消费者组。
DefaultMQPushConsumerconsumer=newDefaultMQPushConsumer("sanyouConsumer");
一个消费者组中可以有多个消费者,不同消费者组之间消费消息是互不干扰的。
在同一个消费者组中,消息消费有两种模式。
- 集群模式
- 广播模式
集群模式
同一条消息只能被同一个消费组下的一个消费者消费,也就是说,同一条消息在同一个消费者组底下只会被消费一次,这就叫集群消费。
集群消费的实现就是将队列按照一定的算法分配给消费者,默认是按照平均分配的。
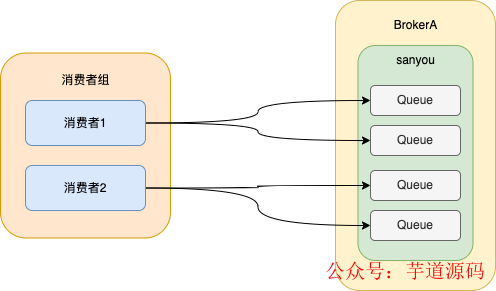
如图所示,将每个队列分配只分配给同一个消费者组中的一个消费者,这样消息就只会被一个消费者消费,从而实现了集群消费的效果。
RocketMQ默认是集群消费的模式。
广播模式
广播模式就是同一条消息可以被同一个消费者组下的所有消费者消费。
其实实现也很简单,就是将所有队列分配给每个消费者,这样每个消费者都能读取topic底下所有的队列的数据,就实现了广播模式。
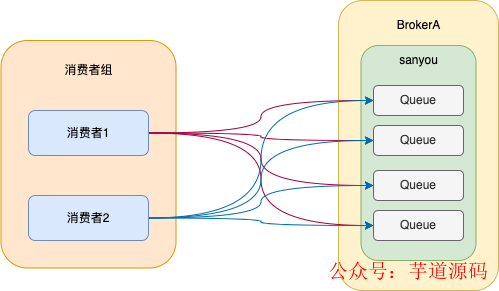
如果你想使用广播模式,只需要在代码中指定即可。
consumer.setMessageModel(MessageModel.BROADCASTING);
ConsumeQueue
上一节我们提到消费者是从队列中拉取消息的,但是这里不经就有一个疑问,那就是消息明明都存在CommitLog文件中的,那么是如何去队列中拉的呢?难道是去遍历所有的文件,找到对应队列的消息进行消费么?
答案是否定的,因为这种每次都遍历数据的效率会很低,所以为了解决这种问题,引入了ConsumeQueue的这个概念,而消费实际是从ConsumeQueue中拉取数据的。
用户在创建topic的时候,Broker会为topic创建队列,并且每个队列其实会有一个编号queueId,每个队列都会对应一个ConsumeQueue,比如说一个topic在某个Broker上有4个队列,那么就有4个ConsumeQueue。
前面说过,消息在发送的时候,会根据一定的算法选择一个队列,之后再发送消息的时候会携带选择队列的queueId,这样Broker就知道消息属于哪个队列的了。当消息被存到CommitLog之后,其实还会往这条消息所在的队列的ConsumeQueue插一条数据。
ConsumeQueue也是由多个文件组成,每个文件默认是存30万条数据。
插入ConsumeQueue中的每条数据由20个字节组成,包含3部分信息,消息在CommitLog的起始位置(8个字节),消息在CommitLog存储的长度(8个字节),还有就是tag的hashCode(4个字节)。
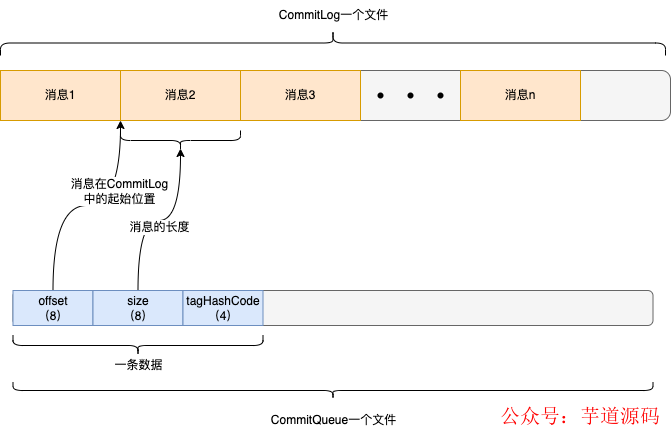
所以当消费者从Broker拉取消息的时候,会告诉Broker拉取哪个队列(queueId)的消息、这个队列的哪个位置的消息(queueOffset)。
queueOffset就是指上图中ConsumeQueue一条数据的编号,单调递增的。
Broker在接受到消息的时候,找个指定队列的ConsumeQueue,由于每条数据固定是20个字节,所以可以轻易地计算出queueOffset对应的那条数据在哪个文件的哪个位置上,然后读出20个字节,从这20个字节中在解析出消息在CommitLog的起始位置和存储的长度,之后再到CommitLog中去查找,这样就找到了消息,然后在进行一些处理操作返回给消费者。
到这,我们就清楚的知道消费者是如何从队列中拉取消息的了,其实就是先从这个队列对应的ConsumeQueue中找到消息所在CommmitLog中的位置,然后再从CommmitLog中读取消息的。
RocketMQ如何实现消息的顺序性
这里插入一个比较常见的一个面试,那么如何保证保证消息的顺序性。
其实要想保证消息的顺序只要保证以下三点即可
- 生产者将需要保证顺序的消息发送到同一个队列
- 消息队列在存储消息的时候按照顺序存储
- 消费者按照顺序消费消息

第一点如何保证生产者将消息发送到同一个队列?
上文提到过RocketMQ生产者在发送消息的时候需要选择一个队列,并且选择算法是可以自定义的,这样我们只需要在根据业务需要,自定义队列选择算法,将顺序消息都指定到同一个队列,在发送消息的时候指定该算法,这样就实现了生产者发送消息的顺序性。
第二点,RocketMQ在存消息的时候,是按照顺序保存消息在ConsumeQueue中的位置的,由于消费消息的时候是先从ConsumeQueue查找消息的位置,这样也就保证了消息存储的顺序性。
第三点消费者按照顺序消费消息,这个RocketMQ已经实现了,只需要在消费消息的时候指定按照顺序消息消费即可,如下面所示,注册消息的监听器的时候使用MessageListenerOrderly这个接口的实现。
consumer.registerMessageListener(newMessageListenerOrderly(){
@Override
publicConsumeOrderlyStatusconsumeMessage(Listmsgs,ConsumeOrderlyContextcontext) {
//按照顺序消费消息记录
returnnull;
}
});
消息清理
由于消息是存磁盘的,但是磁盘空间是有限的,所以对于磁盘上的消息是需要清理的。
当出现以下几种情况下时就会触发消息清理:
- 手动执行删除
- 默认每天凌晨4点会自动清理过期的文件
- 当磁盘空间占用率默认达到75%之后,会自动清理过期文件
- 当磁盘空间占用率默认达到85%之后,无论这个文件是否过期,都会被清理掉
上述过期的文件是指文件最后一次修改的时间超过72小时(默认情况下),当然如果你的老板非常有钱,服务器的磁盘空间非常大,可以将这个过期时间修改的更长一点。
有的小伙伴肯定会有疑问,如果消息没有被消息,那么会被清理么?
答案是会被清理的,因为清理消息是直接删除CommitLog文件,所以只要达到上面的条件就会直接删除CommitLog文件,无论文件内的消息是否被消费过。
当消息被清理完之后,消息也就结束了它精彩的一生。
消息的一生总结
为了更好地理解本文,这里再来总结一下RokcetMQ消息一生的各个环节。
消息发送
- 生产者产生消息
- 生产者在发送消息之前会拉取topic的路由信息
- 根据队列选择算法,从topic众多的队列中选择一个队列
- 跟队列所在的Broker机器建立网络连接,将消息发送到Broker上
消息存储
- Broker接收到生产者的消息将消息存到CommitLog中
- 在CosumeQueue中存储这条消息在CommitLog中的位置
由于CommitLog和CosumeQueue都涉及到磁盘文件的读写操作,为了提高读写效率,RokcetMQ使用到了零拷贝技术,其实就是调用了一下Java提供的api。。
高可用
如果是集群模式,那么消息会被同步到从节点,从节点会将消息存到自己的CommitLog文件中。这样就算主节点挂了,从节点仍然可以对外提供访问。
消息消费
- 消费者会拉取订阅的Topic的路由信息,根据集群消费或者广播消费的模式来选择需要拉取消息的队列
- 与队列所在的机器建立连接,向Broker发送拉取消息的请求
- Broker在接收到请求知道,找到队列对应的ConsumeQueue,然后计算出拉取消息的位置,再解析出消息在CommitLog中的位置
- 根据解析出的位置,从CommitLog中读出消息的内容返回给消费者
消息清理
由于消息是存在磁盘的,而磁盘的空间是有限的,所以RocketMQ会根据一些条件去清理CommitLog文件。
审核编辑 :李倩
-
算法
+关注
关注
23文章
4607浏览量
92826 -
服务器
+关注
关注
12文章
9123浏览量
85322 -
队列
+关注
关注
1文章
46浏览量
10891
原文标题:面试官喜欢问RocketMQ,那就好好准备下
文章出处:【微信号:芋道源码,微信公众号:芋道源码】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
雷军:做芯片“九死一生”,是什么让小米坚持研发?

一生的职业生涯都耗费在研究真空管上的人

RocketMQ和RabbitMQ的区别
“一生一芯”厦门基地正式启动

矽速科技宣布认可“一生一芯”计划CBAS新认证体系,获认证同学自动获得开源实习生联合培养工程的实习OF

2024“一生一芯”暑期宣讲会圆满成功
RT-Thread宣布认可“一生一芯”计划CBAS新认证体系,获认证同学自动获得开源实习生联合培养工程的实习OFFER






 工商网监
工商网监
评论