 针对英特尔,博通、微软、谷歌他们做了什么
针对英特尔,博通、微软、谷歌他们做了什么
凭借其GPU的领先优势,英伟达过去几年炙手可热,乘着ChatGPT热潮,公司的市值从今年年初至今更是大涨了93.6%,过去五年的涨幅更是达到惊人的385%。虽然GPU是英伟达的最重要倚仗,但这绝不是美国芯片“当红炸子鸡”的唯一武器。
通过过去几年的收购和自研,英伟达已经打造起了一个涵盖DPU、CPU和Switch,甚至硅光在内的多产品线巨头,其目的就是想在一个服务器甚至一个机架中做很多的生意。但和很多做GPGPU或者AI芯片的竞争对手想取替GPU一样,英伟达的“取替”计划似乎也不是不能一帆风顺。
近日,三巨头更是再次出手,想把英伟达拒之门外。
1/博通芯片,瞄准Infiniband
熟悉博通的读者应该知道,面向Switch市场,美国芯片巨头拥有三条高端产品线,分别是面向高带宽需求的Tomahawk、面向更多功能的 Trident,以及虽然带宽不高,但是却拥有更深的Buffer和更高可编程性的Jericho。
昨日,他们带来了Jericho系列最新的产品Jericho3-AI。在他们看来,这是比英伟达Infiniband更适合AI的一个新选择。

据博通所说,大公司(甚至 NVIDIA) 都认为 AI 工作负载会受到网络延迟和带宽的限制,而Jericho3-AI 的存在则旨在减少 AI 训练期间花在网络上的时间。其结构的主要特性是负载平衡以保持链路不拥塞、结构调度、零影响故障转移以及具有高以太网基数(radix)。
博通强调,AI 工作负载具有独特的特征,例如少量的大型、长期流,所有这些都在 AI 计算周期完成后同时开始。Jericho3-AI 结构为这些工作负载提供最高性能,具有专为 AI 工作负载设计的独特功能:
完美的负载均衡将流量均匀分布在结构的所有链路上,确保在最高网络负载下实现最大网络利用率。
端到端流量调度的无拥塞操作可确保无流量冲突和抖动。
超高基数独特地允许 Jericho3-AI 结构将连接扩展到单个集群中的 32,000 个 GPU,每个 800Gbps。
零影响故障转移功能可确保在 10 纳秒内自动收敛路径,从而不会影响作业完成时间。
利用这一独特的功能,与 All-to-All 等关键 AI 基准测试的替代网络解决方案相比,Jericho3-AI 结构的工作完成时间至少缩短了 10%。这种性能改进对降低运行 AI 工作负载的成本具有乘法效应,因为它意味着昂贵的 AI 加速器的使用效率提高了10%。此外,Jericho3-AI 结构提供每秒 26 PB 的以太网带宽,几乎是上一代带宽的四倍,同时每千兆比特的功耗降低 40%。

此外,Broadcom 表示,因为它可以处理 800Gbps 的端口速度(对于 PCIe Gen6 服务器)等等,所以它是一个更好的选择。对于将“AI”放在产品名称中,Broadcom 并没有做出过多解读,甚至关于网络 AI计算功能,他们也没涉及,这着实让人摸不着头脑,因为这是英伟达Infiniband 架构的主要卖点。
尽管如此,Broadcom 表示其 Jericho3-AI 以太网在 NCCL 性能方面比 NVIDIA 的 Infiniband 好大约 10%。
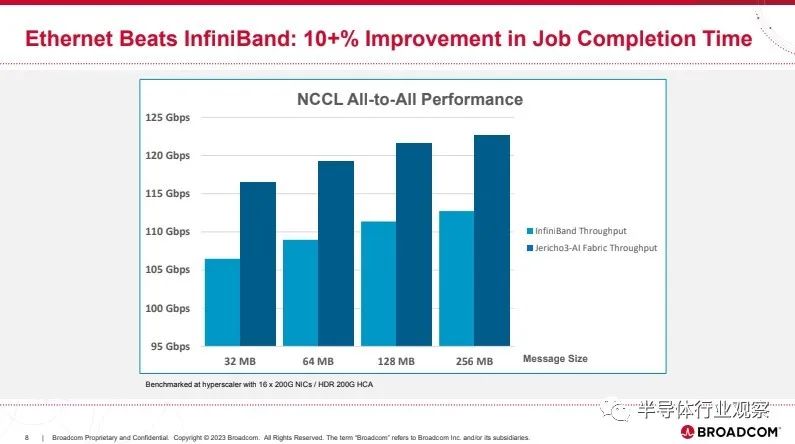
“Jericho3-AI 结构的一个独特之处在于它提供了最高的性能,同时还实现了最低的总拥有成本。这是通过长距离 SerDes、分布式缓冲和高级遥测等属性实现的,所有这些都使用行业标准以太网提供。这些因素为最大的硬件和软件提供商生态系统提供了网络架构和部署选项的高度灵活性。”博通强调。
2/微软,自研芯片再曝进展
因为ChatGPT大火的企业除了英伟达外,作为ChatGPT投资人的微软也备受关注。在半导体行业观察日前发布的文章《英伟达H100市面价格飙升!Elon Musk:每个人都在买GPU》中我们也披露,为了发展ChatGPT,微软已经抢购了不少GPU。随着算力需求的增加,微软在后续必须要更多的芯片支持。
如果一如既往地购买英伟达GPU,这对英伟达来说会是一笔昂贵的支出,他们也会为此不爽。于是,就恰如其分地,微软的自研芯片有了更多信息曝光。
据路透社引述The Information 的报道,微软公司正在开发自己的代号为“Athena”的人工智能芯片,该芯片将为 ChatGPT 等人工智能聊天机器人背后的技术提供支持。
根据该报告,这些芯片将用于训练大型语言模型和支持推理——这两者都是生成 AI 所需要的,例如 ChatGPT 中使用的 AI 来处理大量数据、识别模式并创建新的输出来模仿人类对话。报告称,微软希望该芯片的性能优于目前从其他供应商处购买的芯片,从而为其昂贵的 AI 工作节省时间和金钱。
虽然目前尚不清楚微软是否会向其 Azure 云客户提供这些芯片,但据报道,这家软件制造商计划最早于明年在微软和 OpenAI 内部更广泛地提供其 AI 芯片。据报道,该芯片的初始版本计划使用台积电 (TSMC) 的 5 纳米工艺,不过作为该项目的一部分,可能会有多代芯片,因为微软已经制定了包括多个后代芯片的路线图。
据报道,微软认为自己的 AI 芯片并不能直接替代 Nvidia 的芯片,但随着微软继续推动在Bing、Office 应用程序、GitHub和其他地方推出 AI 驱动的功能,内部的努力可能会大幅削减成本。研究公司 SemiAnalysis 的 Dylan Patel 也告诉The Information,“如果 Athena 具有竞争力,与 Nvidia 的产品相比,它可以将每芯片的成本降低三分之一。”
关于微软造芯,最早可以追溯到2020年。据彭博社在当时的报道,微软公司正在研究用于运行公司云服务的服务器计算机的内部处理器设计,以促进全行业减少对英特尔公司芯片技术依赖的努力。知情人士透露,这家全球最大的软件制造商正在使用Arm的设计来生产将用于其数据中心的处理器。它还在探索使用另一种芯片来为其部分 Surface 系列个人电脑提供动力。
近年来,微软加大了处理器工程师的招聘力度,在英特尔、超微、英伟达等芯片制造商的后院招聘。2022年,他们甚至还从苹果公司挖走了一位经验丰富的芯片设计师,以扩大自身的服务器芯片业务。据报道,这位名为Mike Filippo 的资深专家将在由 Rani Borkar 运营的微软 Azure 集团内从事处理器方面的工作。微软发言人证实了 Filippo 的聘用,他也曾在 Arm和英特尔公司工作过。
今年年初,微软更是宣布收购了一家名为Fungible的DPU芯片公司。
微软 Azure 核心部门的 CVP Girish Bablani 在一篇博文中写道:“Fungible 的技术有助于实现具有可靠性和安全性的高性能、可扩展、分解、横向扩展的数据中心基础设施”。他进一步指出:“今天的公告进一步表明微软致力于数据中心基础设施进行长期差异化投资,这增强了公司的技术和产品范围,包括卸载、改善延迟、增加数据中心服务器密度、优化能源效率和降低成本。”Fungible 在其网站上的一份声明中写道。“我们很自豪能成为一家拥有 Fungible 愿景的公司的一员,并将利用 Fungible DPU 和软件来增强其存储和网络产品。”
由此我们可以看到微软在芯片上做更多的发布也不足为奇。
3/谷歌TPU,已经第四代
在取代英伟达的这条路上,谷歌无疑是其中最坚定,且走得最远的一个。
按照谷歌所说,公司谷歌早在 2006 年就考虑为神经网络构建专用集成电路 (ASIC),但到 2013 年情况变得紧迫。那时他们意识到神经网络快速增长的计算需求可能需要我们将数量 增加一倍我们运营的数据中心。从2015年开始,谷歌就将其TPU部署到了服务器中,并在后续的测试中获得了不邵的反馈,以迭代其产品。
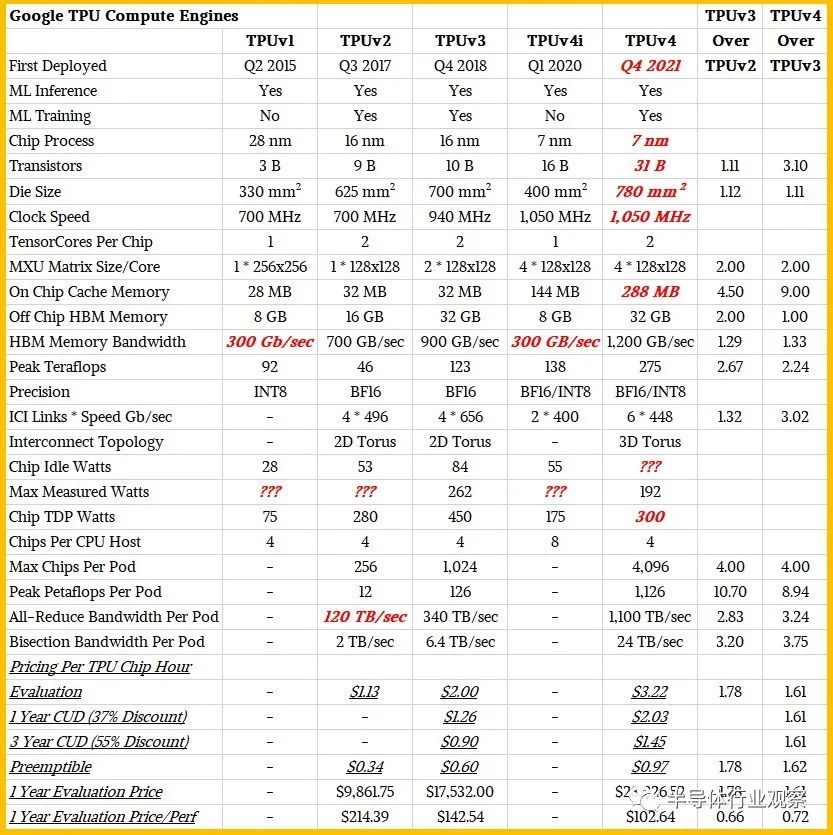
近日,谷歌对其TPUv4及其基于这个芯片的打造的超级计算系统进行了深度披露。
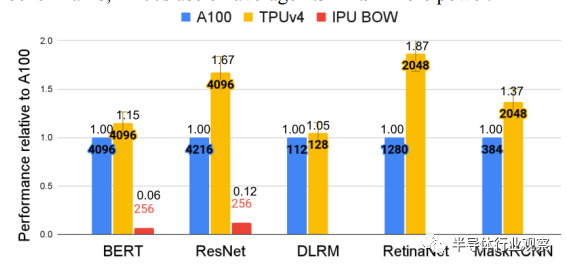
据他们在一篇博客中介绍,得益于互连技术和领域特定加速器 (DSA) 方面的关键创新,谷歌云 TPU v4 在扩展 ML 系统性能方面比 TPU v3 有了近 10 倍的飞跃;与当代 ML DSA 相比,提高能源效率约 2-3 倍。在与Nvidia A100 相比时,谷歌表示,TPU v4比前者快 1.2-1.7 倍,功耗低 1.3-1.9 倍。在与Graphcore的IPU BOW相比,谷歌表示,其芯片也拥有领先的优势。
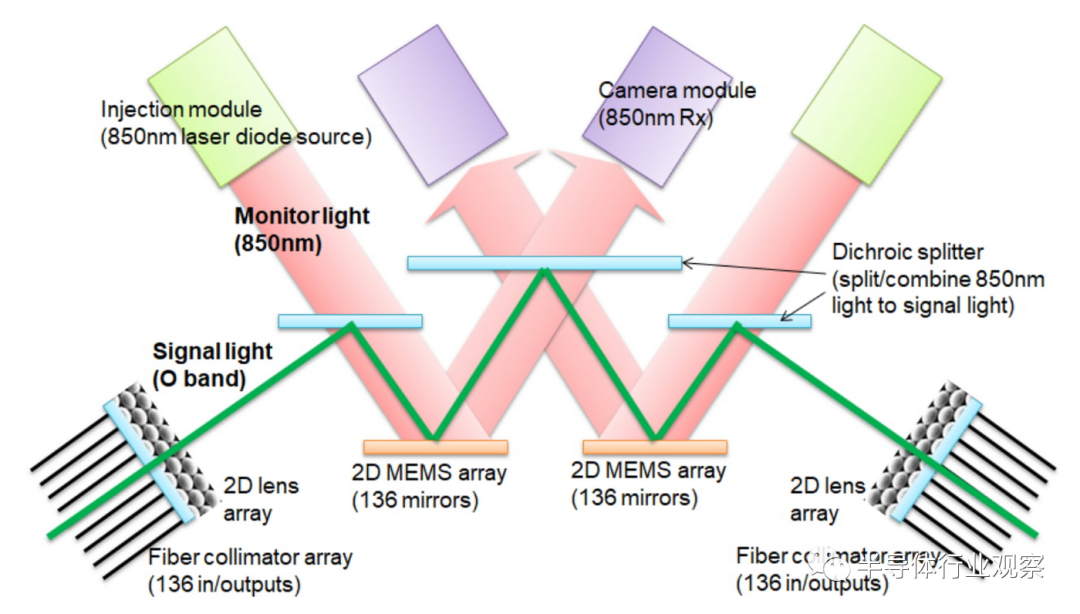
基于这个芯片,谷歌打造了一个拥有 4,096 个张量处理单元 (TPU)的TPU v4 超级计算机。谷歌表示,这些芯片由内部开发的行业领先的光电路开关 (OCS) 互连,OCS 互连硬件允许谷歌的 4K TPU 节点超级计算机与 1,000 个 CPU 主机一起运行,这些主机偶尔(0.1-1.0% 的时间)不可用而不会引起问题。
据谷歌介绍,OCS 动态重新配置其互连拓扑,以提高规模、可用性、利用率、模块化、部署、安全性、功率和性能。与 Infiniband 相比,OCS 和底层光学组件更便宜、功耗更低且速度更快,不到 TPU v4 系统成本的 5% 和系统功耗的 5% 以下。下图显示了 OCS 如何使用两个 MEM 阵列工作。不需要光到电到光的转换或耗电的网络分组交换机,从而节省了电力。
值得一提的是,TPU v4 超级计算机包括 SparseCores,这是一种更接近高带宽内存的中间芯片,许多 AI 运算都发生在该芯片上。SparseCores 的概念支持 AMD、英特尔和高通等公司正在研究的新兴计算架构,该架构依赖于计算更接近数据,以及数据进出内存之间的协调。
此外,谷歌还在算法-芯片协同方面做了更大的投入。如半导体行业观察之前的文章《从谷歌TPU 看AI芯片的未来》中所说;“随着摩尔定律未来越来越接近物理极限,预计未来人工智能芯片性能进一步提升会越来越倚赖算法-芯片协同设计,而另一方面,由于有算法-芯片协同设计,我们预计未来人工智能芯片的性能仍然将保持类似摩尔定律的接近指数级提升,因此人工智能芯片仍然将会是半导体行业未来几年最为热门的方向之一,也将会成为半导体行业未来继续发展的重要引擎。”
写在最后
综合上述报道我们可以直言,对于英伟达而言,其面临的挑战是方方面面的,而不是仅仅局限于其GPU。其对手也不仅仅是芯片公司,因此如何在规模化优势的情况下,保证其高性价比,是安然度过未来潜在挑战的有效方法之一。
不过,可以肯定的是,围绕着数据中心的创新远未接近停止,甚至可以说因为大模型的流行,这场战斗才刚刚开始。
-
英特尔
+关注
关注
61文章
9949浏览量
171687 -
cpu
+关注
关注
68文章
10854浏览量
211567 -
谷歌
+关注
关注
27文章
6161浏览量
105295 -
服务器
+关注
关注
12文章
9123浏览量
85320 -
DPU
+关注
关注
0文章
357浏览量
24169
发布评论请先 登录
相关推荐
世纪大并购!传高通有意整体收购英特尔,英特尔最新回应

英特尔或被道琼斯指数除名
英特尔CEO:AI时代英特尔动力不减
英特尔、AMD等联手推出UALink,希望用它取代Nvidia NVLink接口

英特尔与微软合作在其AI PC及边缘解决方案中支持多种Phi-3模型
微软正在与英伟达、AMD和英特尔合作以改进PC游戏画质技术


Cirrus Logic与英特尔和微软在全新的PC参考设计上进行合作
英特尔拿下微软芯片代工订单

微软将使用英特尔的18A技术生产芯片






 工商网监
工商网监
评论