 人工智能、算法与机器学习辨析
人工智能、算法与机器学习辨析
人工智能 (AI)、机器学习 (ML) 和算法这几个词经常出现误用、混淆和误解。尽管它们都有各自的固定含义,但是人们常常会将这几个概念互换使用。遗憾的是,如果没有领会这些含义,它们可能会让本已十分复杂的快速发展领域乱上加乱。现在,就让我们认识一些有关算法、人工智能和机器学习的基础知识,了解它们是什么、如何使用、用在哪里以及分别是为了什么才创造出它们。我们首先从算法开始讨论,因为算法构成了人工智能和机器学习的基础。
算法
简而言之,算法就是执行计算或解决特定问题时要遵循的一组规则,它包含求解所需的一系列步骤。尽管我们大多数人对算法的第一个反应都是向计算机发出的指令,但哪怕是今天您做晚餐时用到的简单食谱,也可以视为一种算法。
算法实质上是一种快捷地告诉计算机下一步要做什么的方式,通过使用“and”(与)、“or”(或)或“not”(非)语句给出这些指令。它们可能非常简单,也可能极其复杂。
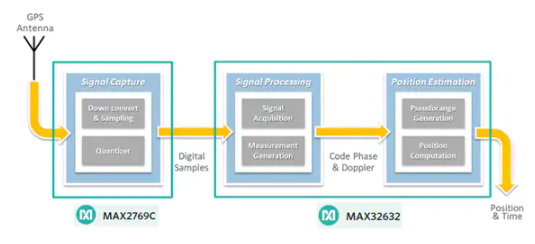
图1: 一种用于在随机排列的数字列表中找出最大数字的简单算法。(来源:维基百科)
对于(图1)中的算法,其高级描述如下:
如果数组中没有数字,则没有最大数字。
假设数组中的第一个数字是其中的最大数字。
对于数组中剩余的每个数字:如果该数字大于当前的最大数字,则假设该数字为数组中的最大数字。
如果数组中的数字都已经循环到,则将当前的最大数字视为数组中的最大数字。
这些指令可以明确地编写成具体程序;但是,还有一些算法则使计算机能够自行学习,比如机器学习。在讨论机器学习之前,让我们介绍一下人工智能这一更广泛的主题。
人工智能
人工智能 (AI) 需要将一系列的算法结合起来,以便处理意外情况。如果说人工智能就像一把伞,那么机器学习和深度学习 (DL) 就好比是伞骨。AI系统能够以一种自然的方式与用户交互。Amazon、Google和Apple处于利用人工智能及其核心非结构化数据的最前沿。
2018年,人工智能的阅读理解能力朝着人类同等能力的目标迈出了巨大的一步。开发人员利用监督学习和带标签的示例来训练AI模型,以执行诸如图像分类等有具体目标的任务。一年后,人工智能出现了一种新的趋势。自我监督学习被用来通过容易获得的相关内容帮助模型形成对语言中丰富上下文语义的理解。这种突破性方法帮助模型学习的一种方式是通过阅读文本、屏蔽不同的单词并根据剩余的文本进行预测。
利用这种自我监督的学习,Microsoft的Turing模型在2020年达到了170亿参数量的新高度,实现了包括生成摘要、语境预测和问题解答在内的各种实用语言建模任务。通过其对人类语言深刻的根本性理解,Microsoft Turing模型能够获取人们所要表述的含义,并对实时对话和文档中的问题准确作出回应。
准确性会随着AI系统的学习而提高。在未来数年内,AI系统的参数量预计将达到万亿级,这将使AI能够更轻松地协助用户,实现仅凭结构化数据无法得到的惊人准确性。那么,是什么让这种学习带来前所未有的准确性的呢?
机器学习
机器学习使用结构化数据输入和算法进行假设、重新评估数据,并根据新发现的条件重新配置原始算法(图2)。它无需人工干预即可做到这一点,因此称为机器学习。因为机器学习系统可以非常快速地处理大量数据,所以它的优势在于可以用人类无法企及的速度和能力发现所有可能的模式和解决方案。
然而,复杂的系统也提出了复杂的挑战。由于机器学习太依赖于假设了,因此系统可能会迅速走上错误的道路,从而导致意外的行为和结果。一个例子就是Uber的自动驾驶试点项目,由于错误假设导致撞死了一名行人,最终在2018年叫停了所有试验。
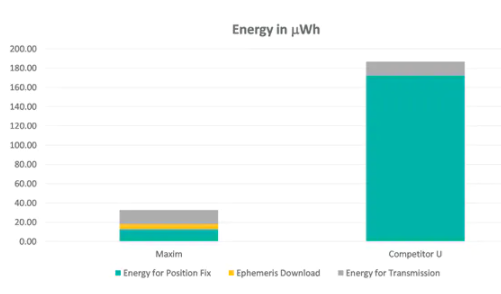
图2: 机器学习涉及自动根据经验改进的计算机算法。这种算法基于样本或训练数据构建模型,目的是作出预测(学习)。(来源:维基百科)
有关机器学习的例子不胜枚举, 这里我们就举一个信用卡欺诈检测的例子。在这一场景中,如果信用卡的使用超出了预期中持卡人的正常使用模式,则要求用户验证可疑交易是否合法。然后,机器学习系统进一步调整和修正其对可接受使用模式的理解。
机器学习可以预想到一系列结果,这些结果可能全部正确,但是许多结果一开始可能是不可预测的。机器学习项目缺乏准确性的原因还有很多。
问题出在哪里?
大多数人工智能实验失败的原因之一是缺乏能够让机器学会推理的早期指导。机器只认得“0”和“1”, 不能处理其他模棱两可的情况。
例如,想象一下“痛”的概念。孩子需要有人教她说:“如果你摸到火炉会好痛,这样做不对。” 或者,同样也可以说:“如果你要跑步,就有可能会疼。你会感到痛,这是正常现象。” 推理有助于让机器学习系统知道正面结果与负面结果之间的差异。从Uber的例子可以看出,这在深度学习中变得更加重要,因为如果某种类型的指导者没有提供反馈,系统就可能会做出错误的假设。只有在引导机器如何处理各种模棱两可结果之后,机器才谈得上实现了充分学习。如果一个问题的答案是“也许”而不是“是”或“否”,则必须提出更多问题!
另一个挑战在于,要有无穷无尽的时间和无限的资金,才能使用各种可能的组合和条件建立例程,而且还不能止步于此—— 还应考虑各种条件和它们的组合在将来可能会如何改变。例程往往会流于僵化,从而导致数据流不灵活。
推理的要义在于举一反三。随着引擎变得更智能,修正成为了可能。购物单上看似清楚的“half-and-half”(鲜奶油),如果用户没有修正,则会因为把and作为逻辑运算符而只显示两个“half”。但是,如果用户修正了条目,引擎将考虑这种更正,并可能考虑上万个其他条目中的相同修正,从而默认接受“half-and-half”作为有效项目。这就像教孩子说英语: 了解单词的含义,然后理解在特定的条件下将一个单词与另一个单词放在一起,可能会使含义发生变化。
必须要有这样的规则和规定,算法才能正确地发挥作用。算法本身是没有常识的,它对明显的错误一无所知——程序根本就不知道这是怎么回事。算法需要有非常完善、具体且明确的行动计划才能发挥作用。问题的症结恐怕就在这里。
总而言之,当您审视人工智能、算法与机器学习这几个特定词语的性质时,很显然不应该将它们混为一谈。最好的做法是,将它们以这样的方式来看待:算法是解决问题的公式或指令,人工智能使用数据和算法来激发行动和完成任务。另一方面,机器学习是人工智能的一种应用,相当于基于先前数据和历史的自动学习。算法是人工智能和机器学习的基础,而后者是我们未来的基础。
审核编辑:郭婷
-
计算机
+关注
关注
19文章
7488浏览量
87846 -
人工智能
+关注
关注
1791文章
47182浏览量
238199 -
机器学习
+关注
关注
66文章
8406浏览量
132553
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论