 SAS:数据集的横向合并(一)
SAS:数据集的横向合并(一)
一、一对一合并数据集
1.具有不同变量的数据集
在横向合并中,当两个或更多的SAS数据集没有相同的变量时,此时合并数据集的变量均会展示在数据集中。
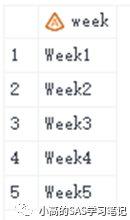
data one;
input week $10.;
cards;
Week1
Week2
Week3
Week4
Week5
;
run;
/ 结果如下: /
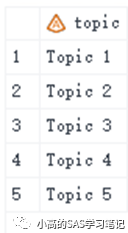
data two;
input topic $10.;
cards;
Topic 1
Topic 2
Topic 3
Topic 4
Topic 5
;
run;
/ 结果如下: /
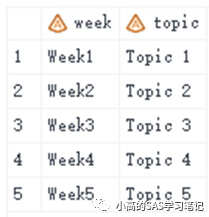
data all1;
merge one two;
run;
/ 结果如下: /
2.具有相同变量的数据集(不使用by语句)
当两个或更多的SAS数据集有相同的变量时,第 2 个数据集中的变量将覆盖第 1 个数据集中的相同变量。如果不想要被覆盖,则可以使用RENAME数据步骤选项来重新命名。
data three;
input ID $3. balance 4.;
cards;
001 102
005 89
002 231
004 147
003 192
;
run;
/ 结果如下: /

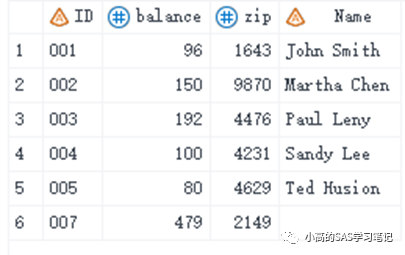
data four;
input Name $ 1-15 @17 balance 4.;
cards;
John Smith 96
Ted Husion 80
Martha Chen 150
Sandy Lee 100
Paul Leny 192
Avery 200
;
run;
/ 结果如下: /

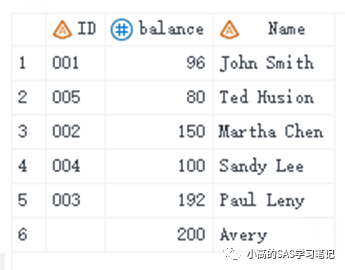
data all2;
merge three four;
run;
/ 结果如下: /
**3.具有相同变量的数据集(使用by语句) **
与by语句的合并允许根据by变量的值来匹配观测值。在合并之前,所有的输入数据集必须按照BY或KEY变量进行排序。
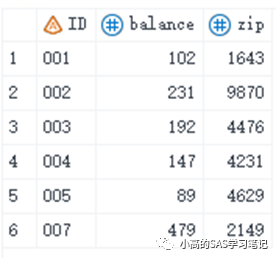
data five;
input ID $3. balance 4. zip 6.;
cards;
001 102 16431
005 89 46298
002 231 98704
004 147 42316
003 192 44765
007 479 21496
;
run;
proc sort data=five;
by id;
run;
/ 结果如下: /
data six;
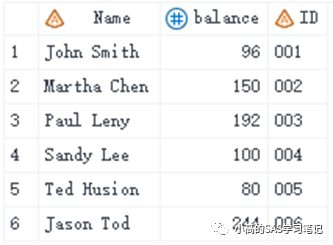
input Name $ 1-15 @17 balance 4. @23 ID $3.;
cards;
Sandy Lee 100 004
Paul Leny 192 003
John Smith 96 001
Ted Husion 80 005
Martha Chen 150 002
Jason Tod 244 006
;
run;
proc sort data=six;
by id;
run;
/ 结果如下: /
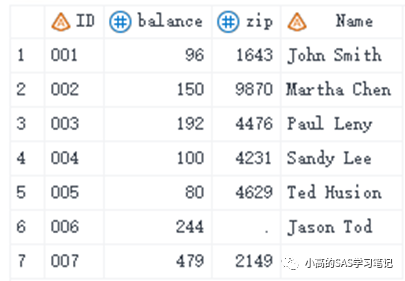
data all3;
merge five six;
by id;
run;
/ 结果如下: /
4.具有相同变量的数据集(使用by语句和in选项)
在上面的例子中,观察值6和7来自两个数据集中的一个。IN=选项创建了一个变量,可以识别数据集是否对输出有贡献。举以下三个例子来让大家理解:
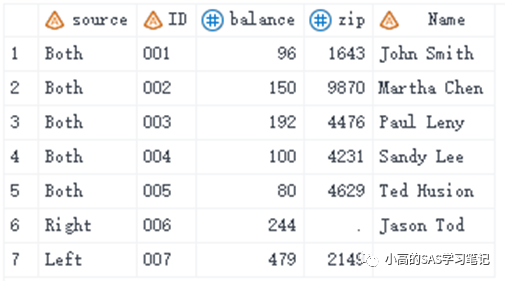
例1:在上面的例子中,我们添加了另一个变量 "source",并使用IN=选项来识别每个输入数据集的贡献:
data all4;
length source $8;
merge five(in=in1) six(in=in2);
by id;
if in1 and in2 then source='Both';
else if in1 then source='Left';
else source='Right';
run;
/ 结果如下: /
例2:在上面的例子中,如果我们希望输出的数据集只包含来自两个输入数据集的观察值:
data all5;
merge five(in=in1) six(in=in2);
by id;
if in1 and in2 ;
run;
/ 结果如下: /

例3:我们希望输出的数据集包含所有来自five输入数据集的观测值:
data all6;
merge five(in=in1) six(in=in2);
by id;
if in1 ;
run;
/ 结果如下: /
注意:如果匹配合并的目的是一对一的匹配合并,输入的数据集应该没有重复的键。因此,在合并之前,可能需要在合并前对proc sort使用NODUPKEY选项。
二、一对多或多对一合并数据集
BY变量值在某一输入数据集中存在重复值,即在其中一个输入数据集中,含有两条或两条以上的观测具有相同的BY变量值,也称为一对多合并。
在匹配过程中会遵循如下原则:由输入数据集读入的变量值,会保留在PDV中,直到被下一个读入的观测值覆盖或该BY组合处理完毕被重置为缺失值为止。为了更好的理解,通过一个简单的例子来具体讲解这一原则。
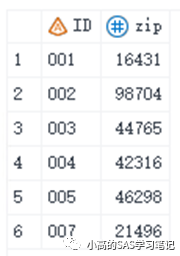
data seven;
input ID $3. zip 6.;
cards;
001 16431
005 46298
002 98704
004 42316
003 44765
007 21496
;
run;
proc sort data=seven out=seven;
by id;
run;
/ 结果如下: /
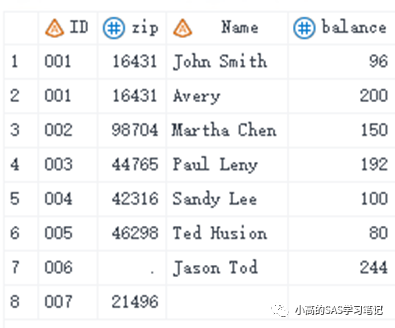
data eight;
input Name $ 1-15 @17 balance 4. @23 ID $3.;
cards;
Sandy Lee 100 004
Paul Leny 192 003
John Smith 96 001
Ted Husion 80 005
Martha Chen 150 002
Jason Tod 244 006
Avery 200 001
;
run;
proc sort data=eight out=eight;
by id;
run;
/ 结果如下: /

data all7;
merge seven eight;
by id;
run;
/ 结果如下: /
三、多对多合并数据集
虽然在匹配合并时,一般情况下BY变量值至多在某一个数据集中有重复,但并不代表匹配合并只能处理这一种情况,它同样可以处理两个或两个以上输入数据集中的BY变量值重复的情况,也就是实现多对多合并。
SAS的匹配原则和一对多合并时一样,并且新数据集中每一个BY变量值重复的次数和输入数据集中重复次数最多的一样。
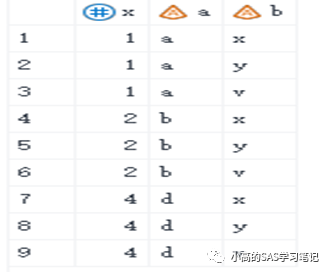
data nine;
input id$3. number;
cards;
001 2
001 3
002 2
002 4
;
run;
proc sort data=nine out=nine;
by id;
run;
/ 结果如下: /

data ten;
input id$3. balance;
cards;
001 100
001 192
002 150
002 200
003 136
;
run;
proc sort data=ten out=ten;
by id;
run;
/ 结果如下: /

data all8;
merge nine ten;
by id;
run;
/ 结果如下: /

在上例中,all8数据集中有一部分id号的number信息,如果不想将这些id的信息包含在新生成的数据集中,就需要确定数据集使用数据集选项IN=可以帮助实现这一功能。
data all9;
merge nine(in=in1) ten(in=in2);
by id;
if in1;
run;
/ 结果如下: /

-
SAS
+关注
关注
2文章
523浏览量
32860 -
数据集
+关注
关注
4文章
1208浏览量
24688
发布评论请先 登录
相关推荐
SAS走进企业级存储应用
串行连接SCSI(SAS)技术开辟宽数据路径
SAS分区规范为所有SAS物理结构提供灵活高效的接入控制,其特性包括
SAS固态硬盘存储技术
SAS硬盘有什么特点?
SAS接口的设计
一种大数据的密度统计合并算法
5个必须知道的Pandas数据合并技巧
SAS:数据集的横向合并(二)

Yonghong Desktop端Excel 数据集的优化





 工商网监
工商网监
评论