 分析unidbg(unidbgMutil)多线程机制
分析unidbg(unidbgMutil)多线程机制
一、概述
由于在工作中遇到了某翻译so中有多线程调用,因此使用unidbg分析(基于unidbgMutilThread)并增加阻塞唤醒机制(futex系统调用),但仍未调用成功,因此本文概述对unidbg多线程的理解、android多线程的创建流程、实现简单的阻塞唤醒、以及近段时间分析的总结,也希望大神网友能提出宝贵意见及分析方向,文末会有相关内容。
二、准备
android6.0(sdk23) ,kernel源码
相关源码路径:
/bionic/libc/bionic/pthread_create.cpp
/bionic/libc/bionic/pthread_mutex.cpp
/bionic/libc/bionic/pthread_cond.cpp
/bionic/libc/bionic/clone.cpp
/bionic/libc/arch-arm/bionic/__bionic_clone.S
/bionic/libc/private/bionic_futex.h
/kernel/kernel/futex.c
三、开始分析
1. unidbgMutil的多线程创建分析
我们知道,在C中创建一个线程是要用到pthread_create这个函数的,这个函数简单来说,在用户空间通过mmap为子线程分配线程栈空间,在底层的是使用了clone这个系统调用创建线程。
因此unidbgMutil也选择在clone这个系统调用里面实现自己的线程创建。
//com.github.unidbg.linux.ARM32SyscallHandler
private int pthread_clone(Backend backend, Emulator? emulator) {
. . . . . .
Pointer child_stack = UnidbgPointer.register(emulator, ArmConst.UC_ARM_REG_R1);
Pointer fn = child_stack.getPointer(0);
child_stack = child_stack.share(4);
Pointer arg = child_stack.getPointer(0);
child_stack = child_stack.share(4);
threadId = ++ThreadDispatcher.thread_count_index;
emulator.getThreadDispatcher().threadMap.put(threadId, new LinuxThread(emulator,child_stack, fn, arg));
. . . . . .
}
这里可以看到,在clone的系统调用里,我们取出了R1寄存器的值,然后又通过R1取得了fn、arg,接着创建一个LinuxThread对象,并把当前线程id和这个对象绑定在一起,存入全局的threadMap中。然后在LinuxThread里保存当前cpu上下文,保存线程栈,通过arg.getPointer(48) 获取子线程函数的地址。通过this.arg.getPointer(52) 获取子线程参数的地址。
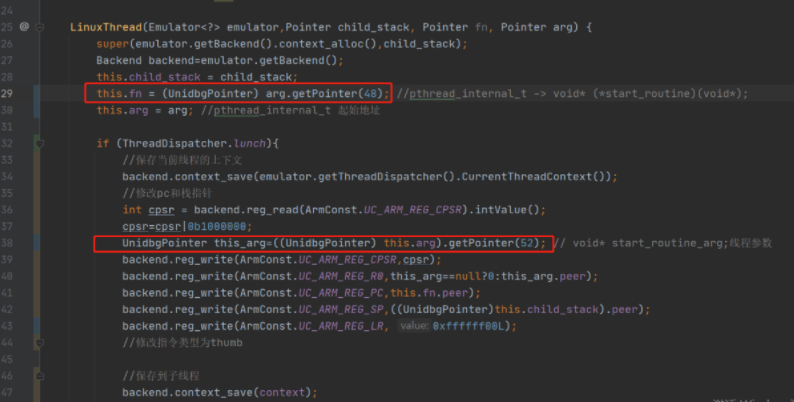
其实到这里,我们需要分析一下,child_stack的连续取地址,arg的pointer 48,52的偏移究竟是什么,不然我们后续增加功能,修改代码,就会一头雾水。
2. Android 多线程分析
前边简单概述了pthread_create的相关内容,但如果要了解unidbg的多线程实现,我们则要详细分析Android是如何创建多线程的。我们看代码:
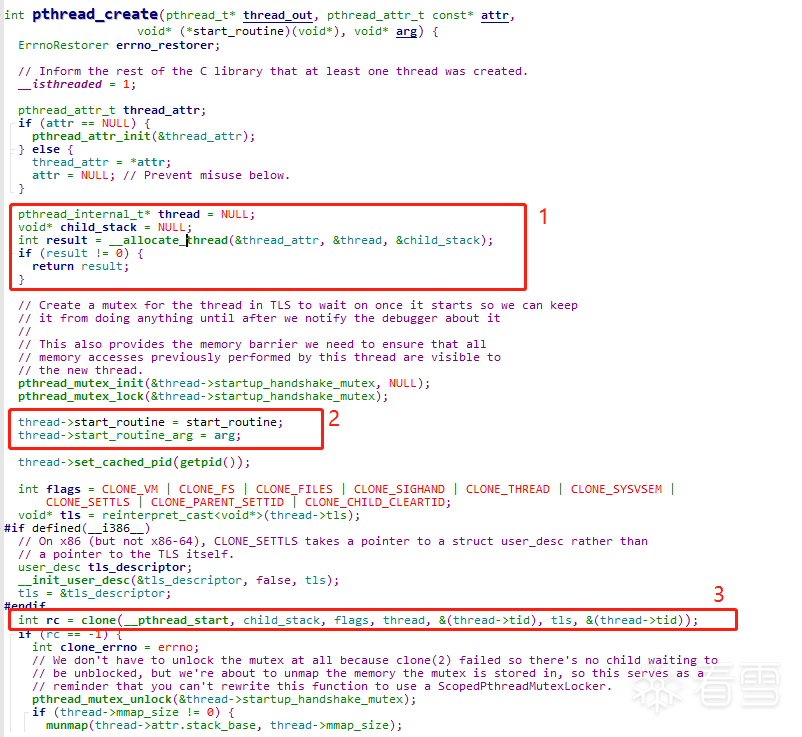
我们知道pthread_create一共有4个参数,这里要关注第三和第四个参数,也就是子线程函数的地址和参数。代码块1 调用了__allocate_thread函数,传入thread变量(pthread_internal_t结构体,很重要),和child_stack指针。
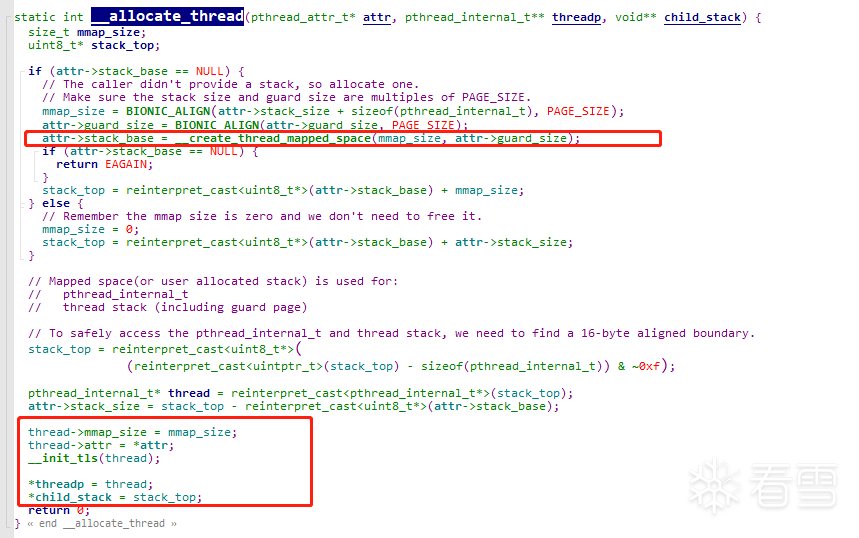
进入后我们发现,这个函数的作用其实就是为我们的子线程,开启一份栈空间,attr->guard_size是线程栈的保护区域这里是4k,__create_thread_mapped_space函数内部通过mmap系统调用,分配出一份匿名、私有的空间供子线程使用。然后将分配的内存大小,栈顶地址,赋值给threadp即pthread_internal_t。

到这里我们的栈空间已经分配完成,接下来就要进行子线程函数地址和参数的分配。也就是我们看到的在pthread_create代码块2那里,将start_routine和arg全都赋值给thread这个变量。然后就调用到clone这个函数。
clone:
int clone( int (*fn)(void *),
void *child_stack,
int flags,
void *arg,
.... /* pid_t *ptid, struct user_desc *tls, pid_t *ctid */ );
通过查阅资料,linux中进程和线程的创建在内核中都是通过clone系统调用完成的,区别在于flags参数,因为线程是可以共享进程中的资源的,而进程和进程之间是隔离的,就是因为在clone系统调用中,flags参数的作用,如CLONE_VM,CLONE_FS,CLONE_SIGHAND等。
也就是说线程创建的本质是共享进程的虚拟内存、文件系统属性、打开的文件列表、信号处理,以及将生成的线程加入父进程所属的线程组中等等。这里flags参数在pthread_create内部已经写好,我们这里只需要关注fn,child_stack和arg就可以了。
fn 表示 clone 生成的子进程/线程会调用 fn 指定的函数,我们发现这里的fn,并不是pthread_create中传进来的子线程函数(start_routine),而是pthread_create内部的函数__pthread_start,而这个函数的参数必然不可能是子线程函数的参数,我们看一下,他的参数是thread变量(pthrea_internel_t),在我们前面的分析中,我们知道子线程的函数地址和函数参数就在这个thread变量中!
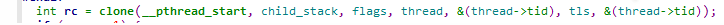
接着往下走,进入clone函数:
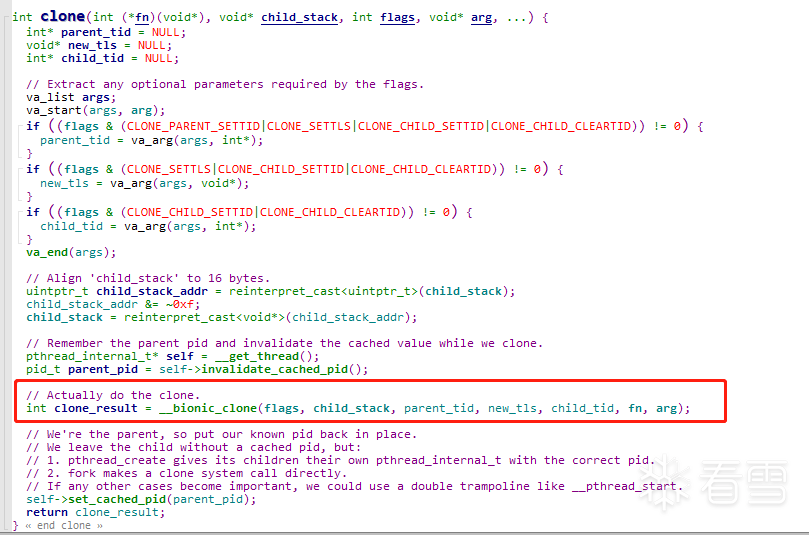
到这里,我们进入了_bionic_clone这个函数,这个函数在libc中是用汇编写的,这里我们要注意下,_bionic_clone的参数和clone的参数位置,因为接下来我们要分析寄存器里的内容,如果参数搞混了就头疼了。这里我们记住,fn虽然是clone要调用的子线程函数,但是我们真正的子线程函数在arg(thread)里。即fn -> __pthread_start,arg -> thread(子线程函数,参数),child_stack是mmap分配的,不用多说。

进入__bionic_clone这个汇编,他有7个参数,我们知道arm函数调用的参数传递,少于4个参数由R0-R3完成,多于4个参数用栈(sp)传递,并且入栈的方式是从右向左入栈。
这个代码以及注释已经写得很清楚了,首先保存sp栈指针的值 mov ip, sp;然后将R4-R7入栈。linux的栈是高地址向低地址压的,而且arm规定sp指向栈顶位置,因此下面两条指令的含义是存储原始的R4-R7寄存器的值,即将R4-R7入主线程的栈中,然后将ip中的值,也就是原始sp栈中的参数tid,fn,arg,加载到R4-R6寄存器中。
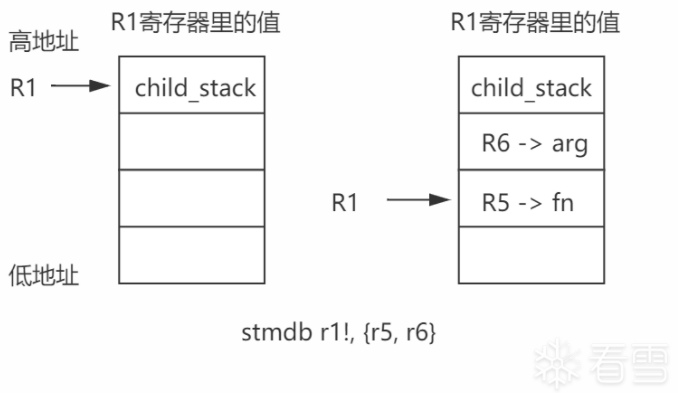
具体的stmfd,ldmfd,stmdb指令,可以查看相关资料,我画了一个图应该更容易理解这几条指令。

接下来的指令stmdb r1!, {r5, r6},很重要,这条指令是理解unidbg中对child_stack的指令偏移的关键。stmdb的含义是,地址先减然后完成操作,因此r1寄存器的地址先减4(减4是因为32位)然后存入r6,再减4,存入r5。根据上边的指令,r6里边存的是arg参数,r5里边存放的是fn指针。
接下来的指令ldr r7, =__NR_clone;swi #0;则是通过R7传递系统调用号,swi软中断(现在是svc指令,功能相同)从用户空间(libc)真正进入到内核空间,之后的操作则是在内核态由kernel操作(位置在/kernel/kernel/fork.c -> SYSCALL_DEFINE5 -> do_fork完成,这里不是我们的重点),在unidbg里则是直接进入了ARM32SyscallHandler中的hook方法。
现在我们再来看一下child_stack的操作:

首先获取R1寄存器的值(记得我们已经在"内核态"了),通过上边的分析,我们已经非常清楚了,此时R1里的值就是fn,这个fn就是__pthread_start,child_stack.share(4);相当于R1地址加4,getPointer(0)就是获取当前地址里的值,即arg,还记得这个arg实际上是一个pthread_internel_t的结构体,里面有我们子线程的函数地址和参数。
那么,this.fn = (UnidbgPointer) arg.getPointer(48);和UnidbgPointer this_arg=((UnidbgPointer) this.arg).getPointer(52);
猜想也能够知道,就是pthread_internel_t的结构体里的子线程函数和参数,我们这里验证一下pthread_internel_t所占的内存大小,由于类class(结构体struct)中定义的成员函数和构造和析构函数不占整体的空间。
因此可以计算,next,prev,cleanup_stack(指针类型占4字节),tid(int类型占4字节),join_state(枚举类型占4字节),即5 * 4 = 20个字节。
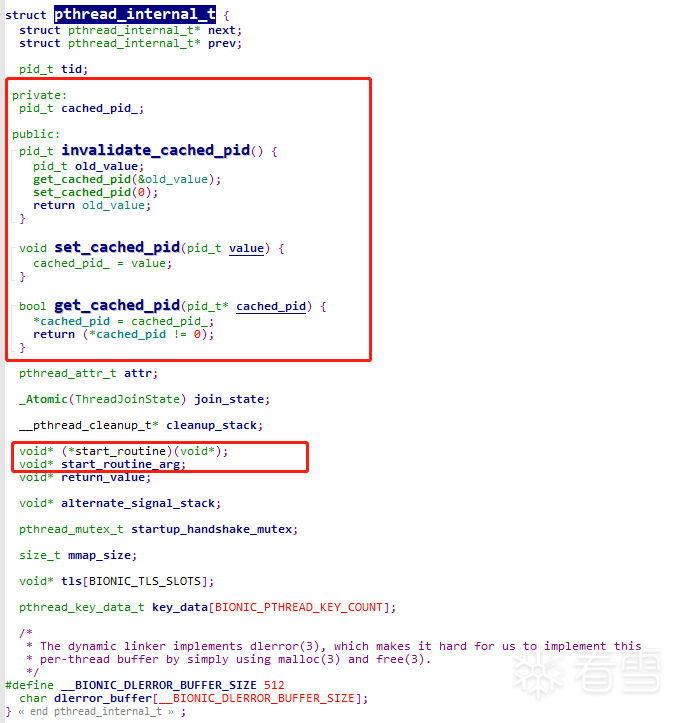
其中attr为结构体,里面是int和指针类型,占4 * 6=24个字节,不过按照我这里的计算方式为44个字节偏移,少了4个字节,可能是计算join_state占用空间不对,或者在哪块有内存对齐,有大神知道的话可以指导一下。

不过最终,start_routine所在的偏移是48个字节是没毛病的,start_routine_arg所占的字节自然是48+4=52的位置。
到此,我们已经完整的分析了unidbgMutil的多线程创建机制,接下来将实现阻塞唤醒功能,以及提出我遇到的问题。
四、问题
当我在调用这个翻译的so时,配置好环境后,用unidbg调用,在单线程的时候,有些是可以成功的。调用这个so分两步:
(1) 加载模型
(2) 翻译

但问题是大部分要传入翻译的字段,在unidbg里会陷入一个死循环,在系统调用号240的位置(futex),于是在大致看看so之后,发现这个so是使用多线程的,其中导入函数里面有很多关于线程同步的东西,锁,信号量,条件变量等。于是我准备在unidbg的基础上实现同步机制。
1. 测试
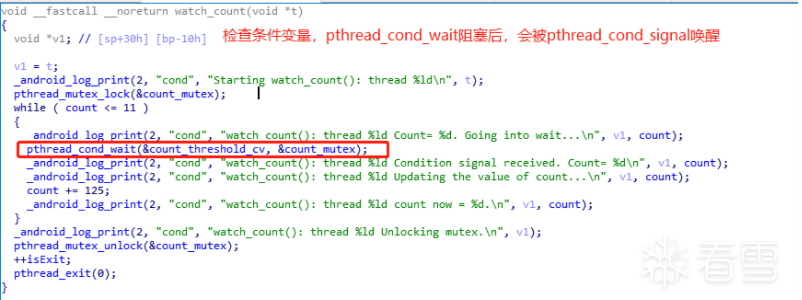
首先写了一个demo,例子很简单,就是创建3个线程,在子线程里进行加锁,并用条件变量控制。主线程里是一个死循环,只有子线程操作完毕后,主线程才会退出循环,输出完成的log。(测试用例的位置在unidbg-android/src/main/java/thread/Test )


2. 增加功能
在这个测试例子中,我们使用到了锁(pthread_mutex_lock),条件变量(pthread_cond_wait/signal)对线程进行同步控制,而这些函数的底层机制都是使用到了futex这个系统调用,因此要了解一下linux futex机制。
(1) Futex概述
关于futex系统调用,网上资料很多,简单来说,在android里可以实现进程/线程间阻塞唤醒功能。他的参数有很多,最主要的是前三个参数,第二个参数futex_op在android里只有两个选项,FUTEX_WAIT,FUTEX_WAKE即阻塞和唤醒。
int futex ( int *uaddr, int futex_op, int val,
const struct timespec *timeout, /* or: uint32_t val2 */
int *uaddr2, int val3);
第一个参数uaddr是一个地址,地址里边是一个int的值,一般被称为futex字,或者futex变量。这个值一般是由用户空间定义,比如pthread_mutex_lock函数在使用futex时,futex字就是&mutex->state这个值。
他的作用是当futex_op的类型为FUTEX_WAIT时,会比较futex字和第三个参数val的大小,如果相同表示要进入阻塞(不相等则失败)。当futex_op的类型为FUTEX_WAKE时,第三个参数val的值,代表要唤醒阻塞着的进程/线程数,比如使用pthread_cond_broadcast时,val为INT_MAX,即唤醒所有线程。
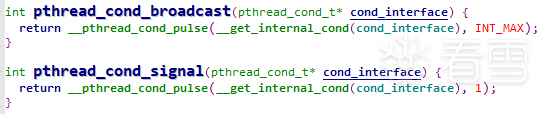
(2) unidbg futex修改
知道了futex的原理,我们自己实现阻塞唤醒也就有了思路,由于实现多线程的方式是基于指令的时间片。

因此,阻塞对于我们来讲,也就是在一个线程被阻塞后,unidbg切换线程时,不要切换到这个阻塞线程。唤醒就是可以重新切换到这个阻塞的线程。
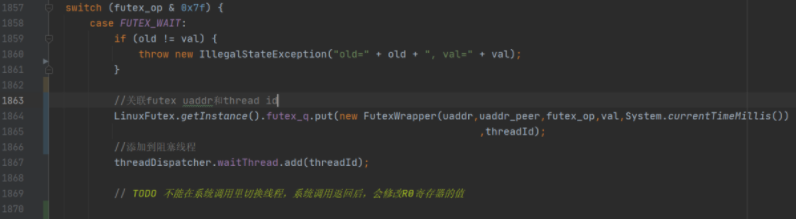
因此我这里实现的方式比较简单,在futex_wait里,将futex uaddr和当前线程id关联起来,然后将当前线程id添加进阻塞线程。
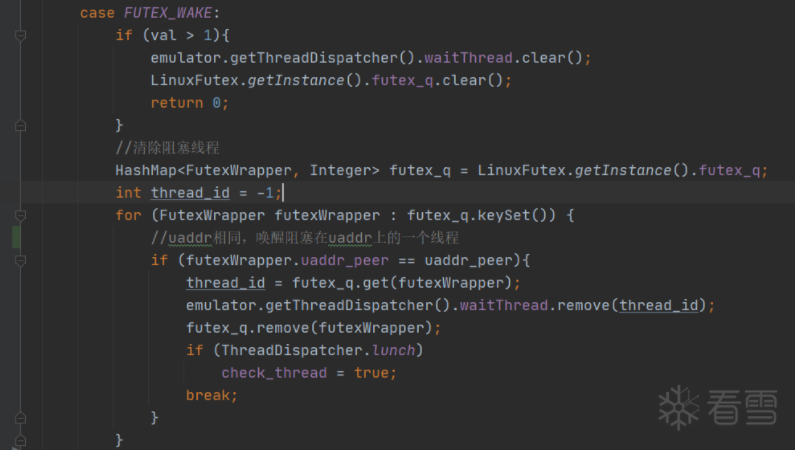
唤醒的方式,同样简单粗暴,移除阻塞在uaddr上的任意一个线程即可。
然后,每当调用到futex阻塞和唤醒后,切换线程。
之前我切换线程时,直接在futex里进行切换,后来导致unicorn数据错乱,一直报Invalid memory read (UC_ERR_READ_UNMAPPED)错误,这个错误是unicorn在emu_start里,如果某条指令出现问题,则会抛出异常,但是并不会告诉你是哪条指令。
幸运的是unidbg提供了tracecode的功能,于是经过多次调试后最终发现,在切换完线程进行保存/恢复寄存器上下文后,R0寄存器的值总是为0,这个奇怪的现象联想到,这正是futex的返回值。系统调用返回后,会修改R0寄存器的值,进而导致了数据错乱。接着我们把切换线程的代码放到系统调用返回之后就OK了。

然后,我们的阻塞唤醒已经基本完成了(pthread_exit里有锁会调用futex,会出现问题,不过线程已经退出了这个问题就没有再研究)。
五、总结
到这里,本文也快结束了,其实本文看似是个分析贴,实则是一个求助帖,因为最后我仍然没有把翻译so调用成功。所以回过头来,想了想近段时间一直在研究unidbg而减少了对翻译so本身的研究,而对翻译so的分析本身也充满了挑战。
所以请教各位网友,也想和大家交流一下,我们的目标是用unidbg成功调用so,并不需要还原so的算法,如何更好的去分析多线程的so,然后用unidbgvwin 出来,目前我的思路可能就是看出错堆栈,然后frida去hook原始so,比较跟unicorn调用的不同?
这个翻译so在加载模型阶段,会开启4个线程,如果只单线程模式调用(只运行主线程),模型的加载可以成功,但后续的翻译阶段有的会陷入死循环。使用多线程加载时,加载模型阶段失败。希望有厉害的网友可以帮忙看一看。
最后,虽然没有成功调用,但是对unidbg的理解又加深了一些,大致如下。
unidbg的内存布局:
[0xffffffffL-0xffff0000L] :svc #0 0xffff0fa0: bx lr
[0xffff0000L-0xfffe0000L]: ARMSvcMemory jni引用
[0xc0000000L-0xbff00000L] : 栈空间
[xxx - 0x40000000L] : so起始地址
- 打断点:emulator.attach().addBreakPoint(address);
- 任意位置调试: emulator.attach().debug();
- 任意位置打印调用栈:emulator.getUnwinder().unwind();
- tracecode: emulator.traceCode(begin,end);
- patchcode: emulator.getMemory().pointer(address).setInt(patchCode); // nop 0xbf00bf00;
- 获取modules:emulator.getMemory().getLoadedModules()。
- 继承IOResolver接口,在resolve函数里可以监控open系统调用。
- 实现VirtualModule子类,注册register方法,可以实现"虚拟"so的加载。
- 使用:
vm.setDvmClassFactory(newProxyClassFactory());ProxyDvmObject.createObject(vm,value);
通过反射可以直接使用java里的类。
-
Android
+关注
关注
12文章
3935浏览量
127335 -
寄存器
+关注
关注
31文章
5336浏览量
120224 -
Linux系统
+关注
关注
4文章
593浏览量
27392
发布评论请先 登录
相关推荐
Java多线程的用法
Linux下多线程机制
QNX环境下多线程编程
LabWindows_CVI多线程技术的应用研究

关于多线程编程教程及经典应用案例的汇总分析
多线程好还是单线程好?单线程和多线程的区别 优缺点分析
什么是多线程编程?多线程编程基础知识
linux多线程机制-线程同步
Python多线程的使用
Linux中多线程编程的知识点





 工商网监
工商网监
评论