 基于AX650N部署EfficientViT
基于AX650N部署EfficientViT
一背景
端侧场景通常对模型推理的实时性要求较高,但大部分轻量级的Vision Transformer网络仍无法在已有边缘侧/端侧AI设备(CPU、NPU)上达到轻量级CNN(如MobileNet)相媲美的速度。为了实现对ViT模型的实时部署,微软和港中文共同在CVPR2023提出论文《EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention》。
本文将简单介绍EfficientViT的基本架构原理,同时手把手带领感兴趣的朋友基于该论文Github项目导出ONNX模型,并将其部署在优秀的端侧AI芯片AX650N上,希望能给行业内对边缘侧/端侧部署Transformer模型的爱好者提供新的思路。
二EfficientViT
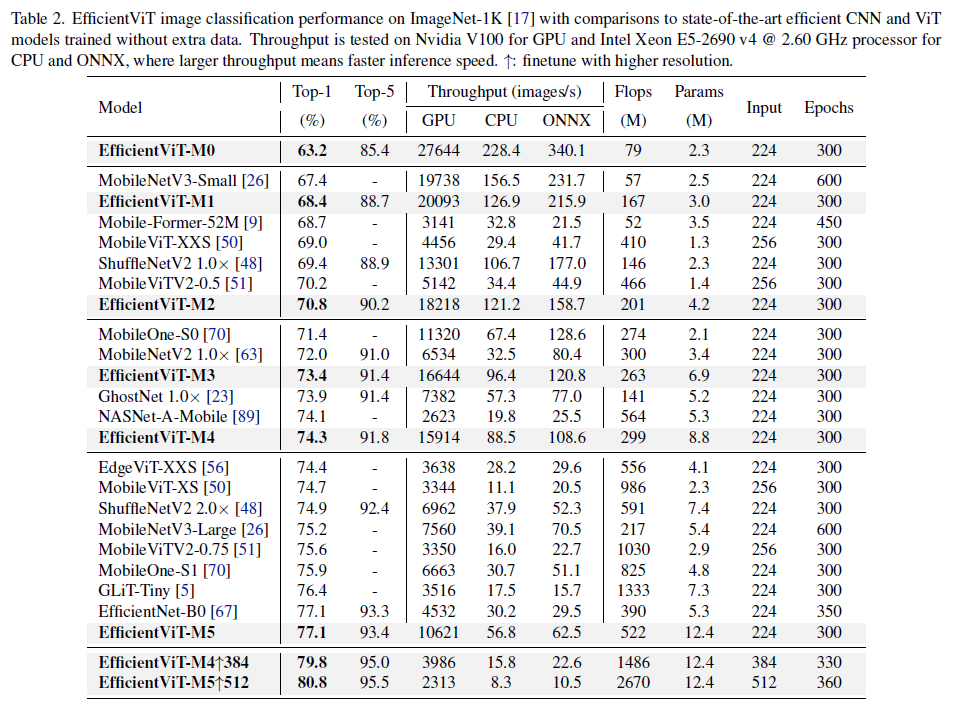
论文从三个维度分析了ViT的速度瓶颈,包括多头自注意力(MHSA)导致的大量访存时间,注意力头之间的计算冗余,以及低效的模型参数分配,进而提出了一个高效ViT模型EfficientViT。它以EfficientViT block作为基础模块,每个block由三明治结构(Sandwich Layout)和级联组注意力(Cascaded Group Attention, CGA)组成。在论文中作者进一步进行了参数重分配(Parameter Reallocation)以实现更高效的Channel、Block和Stage数量权衡。该方法在ImageNet数据集上实现了77.1%的Top-1分类准确率,超越了MobileNetV3-Large 1.9%精度的同时,在NVIDIA V100 GPU 和 Intel Xeon CPU上实现了40.4%和45.2%的吞吐量提升,并且大幅领先其他轻量级ViT的速度和精度。
● 论文:
https://arxiv.org/abs/2305.070271
● Github链接:
https://github.com/microsoft/Cream/tree/main/EfficientViT1
2.1 骨干网络
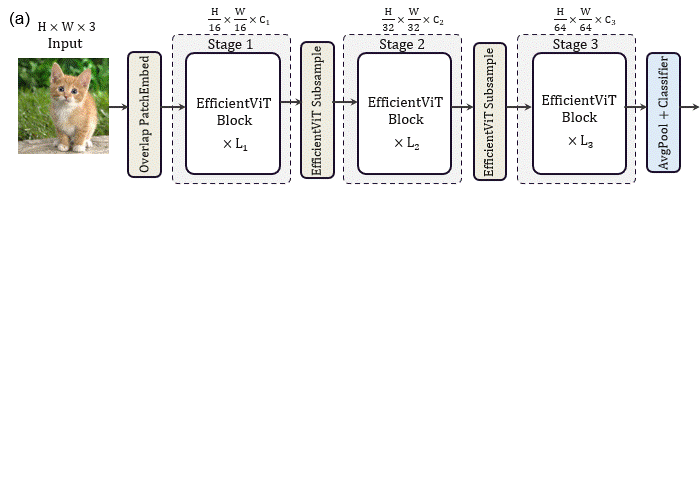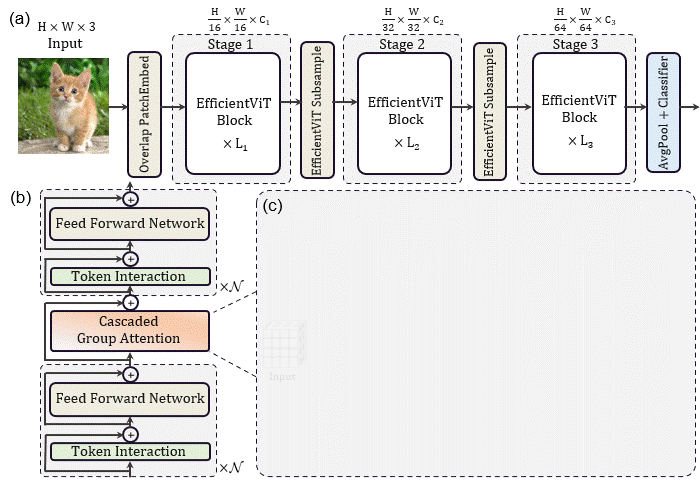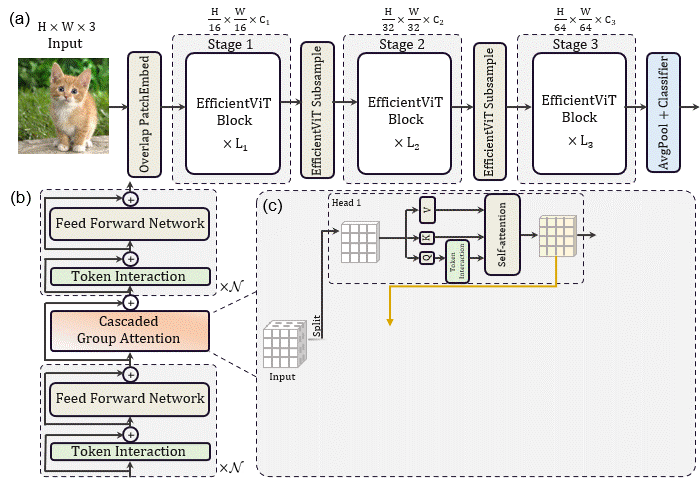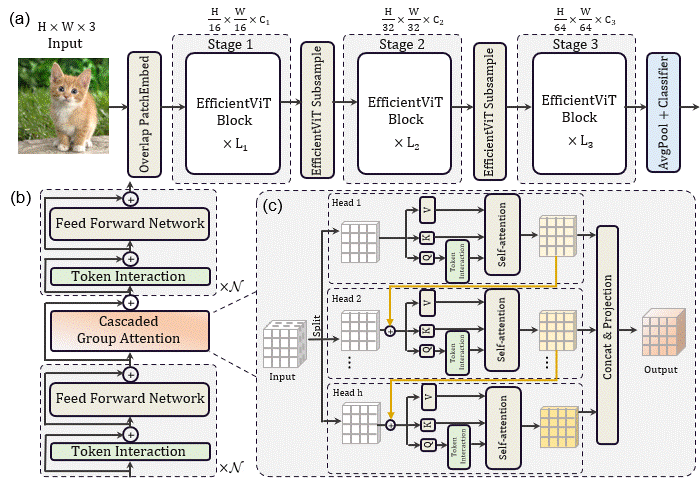
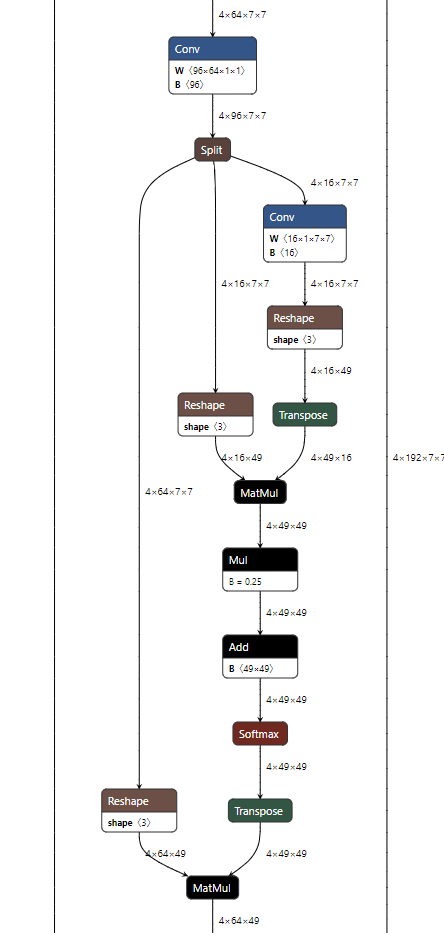
该论文的核心贡献是提出了一种EfficientViT block,每个EfficientViT block的输入特征先经过N个FFN,再经过一个级联组注意力CGA,再经过N个FFN层变换得到输出特征。这一基础模块减少了注意力的使用,缓解了注意力计算导致的访存时间消耗问题。同时,作者在每个FFN之前加入了一层DWConv作为局部token之间信息交互并帮助引入归纳偏置。
另外考虑到BN可以与FC和Conv在推理时融合以实现加速。因此使用Batch Normalization替换Layer Normalization,同时在大尺度下层数更少,并在每个stage用了小于2的宽度扩展系数以减轻深层的冗余。
qkv-backbone
benchmark
三AX650N
AX650N是一款兼具高算力与高能效比的SoC芯片,集成了八核Cortex-A55 CPU,10.8TOPs@INT8 NPU,支持8K@30fps的ISP,以及H.264、H.265编解码的VPU。接口方面,AX650N支持64bit LPDDR4x,多路MIPI输入,千兆Ethernet、USB、以及HDMI 2.0b输出,并支持32路1080p@30fps解码。强大的性能可以让AX650N帮助用户在智慧城市,智慧教育,智能制造等领域发挥更大的价值。
四模型转换
本文以EfficientViT-M5为例。
4.1 Pulsar2
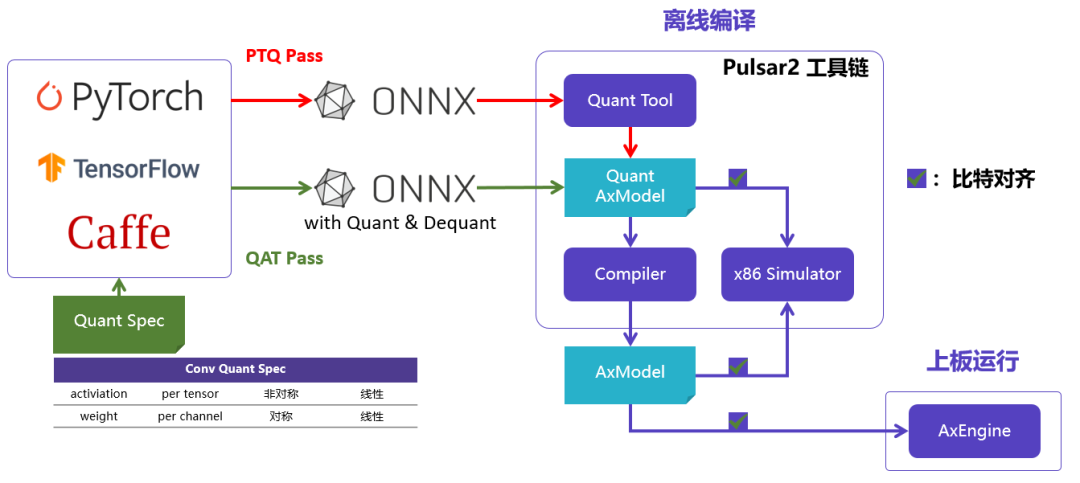
Pulsar2是新一代AI工具链,包含模型转换、离线量化、模型编译、异构调度四合一超强功能,进一步强化了网络模型高效部署的需求。在针对第三NPU架构进行了深度定制优化的同时,也扩展了算子&模型支持的能力及范围,对Transformer结构的网络也有较好的支持。
npu-software-arch
4.2 模型下载
下载github仓库,并进入到EfficientViT/Classification路径下安装相关依赖库
下载安装
$ git clone https://github.com/microsoft/Cream.git $ cd Cream/EfficientViT/classification/ $ pip install -r requirements.txt
●获取PyTorch模型
虽然官方仓库中已经提供了ONNX模型,但是我们发现其ONNX模型的Batch Size=16,并不适合普通的端侧芯片进行评估,因此这里选择从pth文件重新生成Batch Size=1的ONNX模型,更利于端侧芯片部署。
●下载pth文件
下载pth文件
$ wget https://github.com/xinyuliu-jeffrey/EfficientViT_Model_Zoo/releases/download/v1.0/efficientvit_m5.pth
●导出ONNX模型并初步优化计算图
导出onnx
$ python export_onnx_efficientvit_m5.py $ onnxsim efficientvit_m5.onnx efficientvit_m5-sim.onnx
● export_onnx_efficientvit_m5.py源码如下所示。
export_onnx源码
from model import build
from timm.models import create_model
import torch
model = create_model(
"EfficientViT_M5",
num_classes=1000,
distillation=False,
pretrained=False,
fuse=False,
)
checkpoint = torch.load("./efficientvit_m5.pth", map_location='cpu')
state_dict = checkpoint['model']
model.load_state_dict(state_dict)
model.eval()
dummy_input = torch.rand([1,3,224,224])
model(dummy_input)
torch.onnx.export(model, dummy_input, "efficientvit_m5.onnx", opset_version=11)
4.3 模型编译
一键完成图优化、离线量化、编译、对分功能。整个过程耗时只需20秒。
编译log
$ pulsar2 build --input model/efficientvit_m5-sim.onnx --output_dir efficientvit-m5/ --config config/effientvit_config.json
Building onnx ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00
patool: Extracting ./dataset/imagenet-32-images.tar ...
patool: running /usr/bin/tar --extract --file ./dataset/imagenet-32-images.tar --directory efficientvit-m5/quant/dataset/input_1
patool: ... ./dataset/imagenet-32-images.tar extracted to `efficientvit-m5/quant/dataset/input_1'.
Quant Config Table
┏━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Input ┃ Shape ┃ Dataset Directory ┃ Data Format ┃ Tensor Format ┃ Mean ┃ Std ┃
┡━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ input.1 │ [1, 3, 224, 224] │ input_1 │ Image │ RGB │ [123.67500305175781, 116.27999877929688, │ [58.39500045776367, 57.119998931884766, 57.375] │
│ │ │ │ │ │ 103.52999877929688] │ │
└─────────┴──────────────────┴───────────────────┴─────────────┴───────────────┴─────────────────────────────────────────────────────────┴─────────────────────────────────────────────────┘
Transformer optimize level: 2
32 File(s) Loaded.
[14:22:37] AX LSTM Operation Format Pass Running ... Finished.
[14:22:37] AX Refine Operation Config Pass Running ... Finished.
[14:22:37] AX Transformer Optimize Pass Running ... Finished.
[14:22:37] AX Reset Mul Config Pass Running ... Finished.
[14:22:37] AX Tanh Operation Format Pass Running ... Finished.
[14:22:37] AX Softmax Format Pass Running ... Finished.
[14:22:37] AX Quantization Config Refine Pass Running ... Finished.
[14:22:37] AX Quantization Fusion Pass Running ... Finished.
[14:22:37] AX Quantization Simplify Pass Running ... Finished.
[14:22:37] AX Parameter Quantization Pass Running ... Finished.
Calibration Progress(Phase 1): 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 32/32 [00:03<00:00, 8.60it/s]
Finished.
[1442] AX Passive Parameter Quantization Running ... Finished.
[1442] AX Parameter Baking Pass Running ... Finished.
[1442] AX Refine Int Parameter pass Running ... Finished.
quant.axmodel export success: efficientvit-m5/quant/quant_axmodel.onnx
Building native ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 000
......
2023-05-19 1448.523 | INFO | yasched.test_onepass1438 - max_cycle = 1052639
2023-05-19 14:22:55.172 | INFO | yamain.command.build890 - fuse 1 subgraph(s)
4.4 Graph Optimize
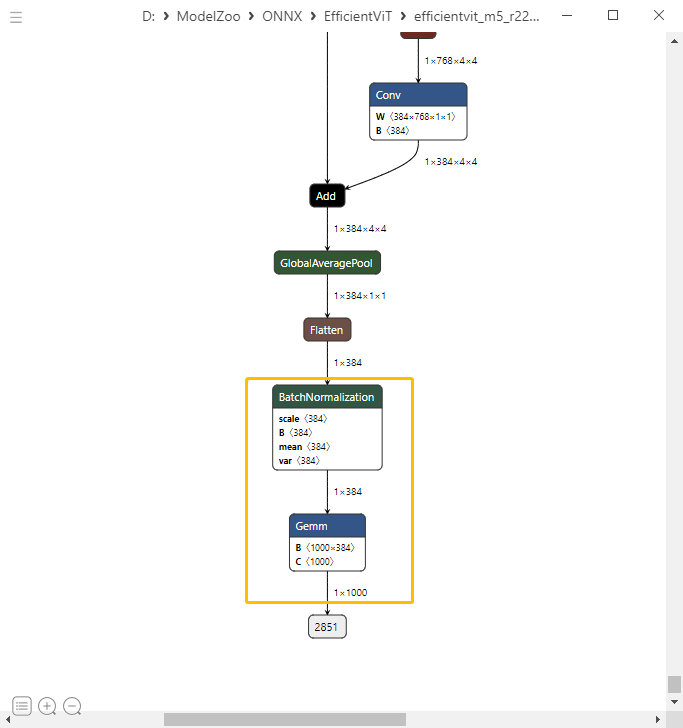
这里主要是对输出头的BN+FC的结构进行了简单的融合,利于后续编译阶段提升执行效率。
图优化-前
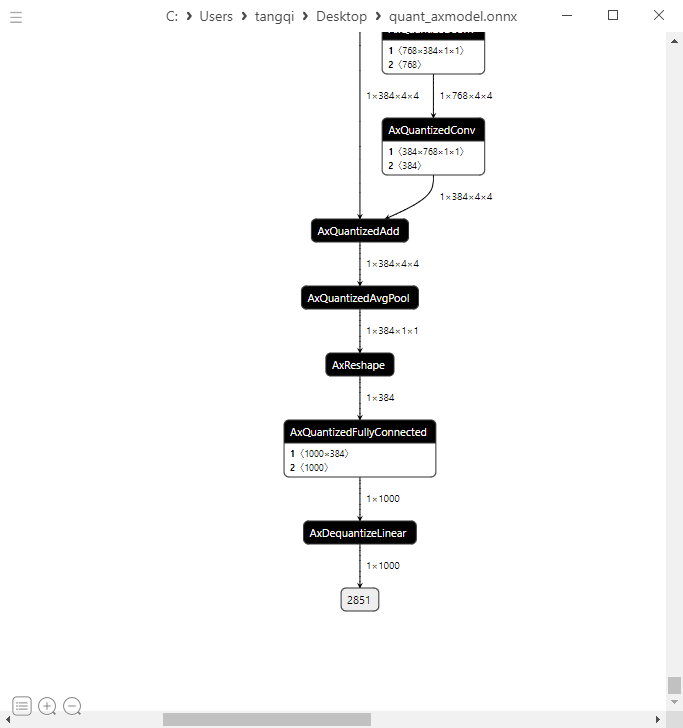
图优化+量化后
五上板部署
5.1 AX-Samples
开源项目AX-Samples实现了常见的深度学习开源算法在爱芯元智的AI SoC上的示例代码,方便社区开发者进行快速评估和适配。最新版本已逐步完善基于AX650系列的NPU示例,其中Classification通用示例可直接运行前面章节编译生成的EfficientViT模型。
https://github.com/AXERA-TECH/ax-samples/blob/main/examples/ax650/ax_classification_steps.cc
5.2 运行
运行log
-------------------------------------- /opt/qtang # sample_npu_classification -m efficientvit-m5-npu1.axmodel -i cat.jpg -r 10 -------------------------------------- model file : efficientvit-m5-npu1.axmodel image file : cat.jpg img_h, img_w : 224 224 -------------------------------------- topk cost time:0.07 ms 5.5997, 285 5.3721, 283 5.0079, 281 4.5982, 284 4.1884, 282 -------------------------------------- Repeat 10 times, avg time 1.24 ms, max_time 1.24 ms, min_time 1.24 ms --------------------------------------
六性能统计
AX650N总算力10.8Tops@Int8,支持硬切分为三个独立小核心或一个大核心的能力,即:
●NPU1,3.6Tops
●NPU3,10.8Tops
| Models | FPS (NPU1 Batch 8) | FPS (NPU3 Batch 8) |
| EfficientViT-M0 | 4219 | 6714 |
| EfficientViT-M1 | 3325 | 5263 |
| EfficientViT-M2 | 2853 | 4878 |
| EfficientViT-M3 | 2388 | 4096 |
| EfficientViT-M4 | 2178 | 3921 |
| EfficientViT-M5 | 1497 | 2710 |
七
后续计划
●尝试部署基于Transformer网络结构的分割模型,敬请期待。
审核编辑:汤梓红
-
cpu
+关注
关注
68文章
10854浏览量
211563 -
AI
+关注
关注
87文章
30726浏览量
268870 -
模型
+关注
关注
1文章
3226浏览量
48804 -
GitHub
+关注
关注
3文章
468浏览量
16427 -
NPU
+关注
关注
2文章
279浏览量
18582
原文标题:爱芯分享 | 基于AX650N部署EfficientViT
文章出处:【微信号:爱芯元智AXERA,微信公众号:爱芯元智AXERA】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于AX650N/AX620Q部署YOLO-World
基于AX650N/AX630C部署端侧大语言模型Qwen2
爱芯元智发布第三代智能视觉芯片AX650N,为智慧生活赋能

【爱芯派 Pro 开发板试用体验】在爱芯派 Pro上部署坐姿检测
【爱芯派 Pro 开发板试用体验】篇一:开箱篇
【爱芯派 Pro 开发板试用体验】爱芯元智AX650N部署yolov5s 自定义模型
【爱芯派 Pro 开发板试用体验】爱芯元智AX650N部署yolov8s 自定义模型
【爱芯派 Pro 开发板试用体验】ax650使用ax-pipeline进行推理
爱芯元智第三代智能视觉芯片AX650N高能效比SoC芯片
如何优雅地将Swin Transformer模型部署到AX650N Demo板上?
基于AX650N部署DETR
基于AX650N部署SegFormer
基于AX650N部署SegFormer
基于AX650N部署视觉大模型DINOv2
爱芯元智AX620E和AX650系列芯片正式通过PSA Certified安全认证






 工商网监
工商网监
评论