 shell脚本基础:正则表达式grep
shell脚本基础:正则表达式grep
在Linux上有许多命令可以使用正则表达式,其中最常见的是grep命令和sed命令。正则表达式有多种类型,每种类型中可以使用的元字符类型不同。最常见的是基本正则表达式和扩展正则表达式。
▲grep命令
grep [选项] 匹配模式 输入文件 ...
【选项】
对于grep指令来说会将指定的匹配模式视为基本正则表达式,但是如果指定了-E选项,则会视为扩展正则表达式。此外,如果指定-F选项,则指定的匹配模式将不会被当作正则表达式,而会被当作固定的普通字符串来处理。
-i选项用于忽略字母大小写的差异。如果指定了该选项,就不再区分字母的大小写,而是同时对大写和小写字母进行匹配。
-v选项用于对匹配的结果进行取反操作.使用该选项之后则正相反,被输出的是没有匹配到指定匹配模式的行。
-n选项用于在输出结果的同时输出匹配的行号。指定了这个选项后,输出结果的格式为“行号:行内容”。
-H和-h是与文件名相关的两个选项。如果没有指定任何选项,则grep命令的基本处理方式是只输出匹配到的行的内容,不输出文件名。但是,如果输入文件有两个及以上,那么在输出匹配结果时,grep命令还会在匹配到的行前面加上文件名,即以“文件名:行的内容”的格式输出。
如果与-n选项搭配使用,就可以同时输出文件名和行号,输出结果的格式为“文件名:行号:行内容”。
-o选项用于输出匹配到指定模式的那一部分内容。通常,grep命令会输出匹配到指定模式的行的全部内容,但如果指定了-o选项,则不再输出整行,而只输出匹配到的部分。
-L选项和-l选项可以以文件为单位统计某个文件是否包含指定的匹配模式,检查文件内部的行。
-q选项可以让grep命令不管能否匹配到结果,都不输出任何内容。这个选项主要在if语句中作为判断条件使用
#!/bin/bash if grep -q bash /etc/shell; then echo Found fi
【匹配模式】
接下来介绍用于进行位置匹配的元字符。这种元字符也称为“锚”,可以指定字符串中用于匹配的位置。
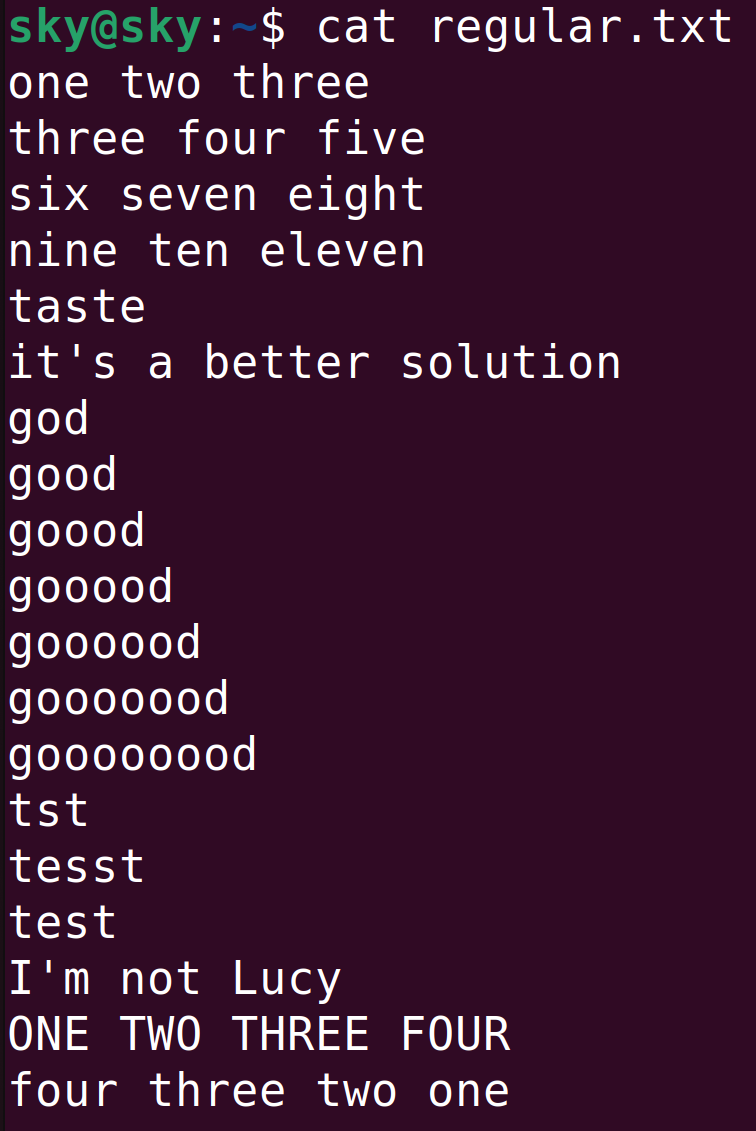
1、在匹配一个字符的元字符中,最常用的是.(点号)。这个元字符可以匹配任意一个字符。类似于linux指令中常用的*,如下
查找test打头的所有字符 $grep '/tset./' example.txt 匹配括号中的任意一个字符 $grep '/test[123]/' example.txt /test1/file_1 /test1/file_2 /test2/file_1 /test3/file_x /work/test1/file_x 在括号内的开始处添加^字符可以表示相反的意思(即除123以外的数字) $grep '/test[^123]/' example.txt
2、^和$。^用于匹配行首,$用于匹配行尾。
比如,^/test1/用于匹配行首为/test1/的字符串,所以当某行的中间出现/test1/时,是不可能匹配的。
3、用于进行重复匹配的元字符
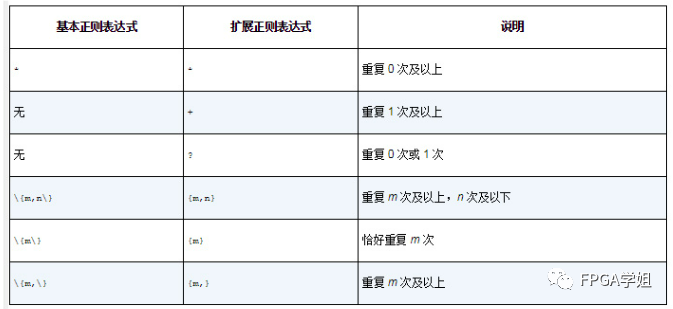
例如,ab*表示a之后的b要重复0次或更多次。因此,它可以匹配到a、ab、abb等。
如果想要明确指定重复次数,可以使用{m,n}指定重复次数。比如ab{2,4}可以匹配到abb、abbb和abbbb。在扩展正则表达式中,指定时可以不用而直接使用{m,n}、{m}或{m,}。还可以使用+和?元字符。这两个元字符分别表示“重复1次及以上”和“重复0次或者1次”。
4、辅助型的元字符
字符用于取消其后的元字符的特殊含义,将其作为普通的字符进行匹配。
例如:.表示匹配.本身,而不是匹配任意一个字符。
( )用于对正则表达式分组。在指定重复次数时,可以使用它对分组后的内容整体进行指定。
例如:a(bc)*可以匹配到a、abc、abcbc等字符串。
|可以连接多个正则表达式,匹配满足其中任意一个正则表达式的字符串。
例如:abc|xyz可以匹配到abc或xyz,abc|xyz|123可以匹配到abc、xyz、123中的任意一个。
审核编辑:汤梓红
-
Linux
+关注
关注
87文章
11291浏览量
209308 -
Shell
+关注
关注
1文章
365浏览量
23354 -
脚本
+关注
关注
1文章
389浏览量
14858 -
grep
+关注
关注
0文章
22浏览量
4723 -
正则表达式
+关注
关注
0文章
27浏览量
3483
原文标题:shell脚本基础(七)正则表达式grep
文章出处:【微信号:FPGA学姐,微信公众号:FPGA学姐】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
什么是正则表达式?正则表达式如何工作?哪些语法规则适用正则表达式?
shell正则表达式学习
深入浅出boost正则表达式
关于java正则表达式的用法详解
快速入门IPv6和正则表达式

Linux中的Grep正则表达式详细资料说明
Python正则表达式的学习指南

Python正则表达式指南
python正则表达式中的常用函数
Linux入门之正则表达式





 工商网监
工商网监
评论