 In-Context-Learning在更大的语言模型上表现不同
In-Context-Learning在更大的语言模型上表现不同
最近,在语言模型领域取得了巨大的进展,部分是因为它们可以通过In-Context- Learning ( ICL)来完 成各种复杂的任务。在ICL中,模型在执行未见过的用例之前,会首先接收一些输入-标签对的示例。一 般来说,ICL对模型的增强,有以下原因:
按照上下文示例的格式,利用预训练阶段得到的语义先验知识来预测标签(例如,当看到带有“正面情感”和“负面情感”标签的电影评论示例,使用先验知识来做情感分析)。
从给的上下文示例中学习输入-标签的映射(例如,正面评论应该映射到一个标签,负面评论应该映射到另一个标签的模式)。
在本文中,我们旨在了解这两个因素(语义先验知识和输入-标签映射)在ICL的影响,尤其是当语言模 型的规模发生变化时。我们通过2种实验方法来对这两个因素进行研究,实验方法分别为:翻转标签的 ICL (flipped-label ICL)和语义无关标签的ICL ( SUL- ICL)。
在翻转标签的ICL中,上下文示例的标签的语义被翻转(例如原先的标签为“Negative”,被反转为 “Positive”),使得语义先验知识和输入-标签映射不匹配。
ps:可以理解为,语义先验知识中与该上下文示例相似的标签都是“Negative”的,但是此处通过“翻转标签”方法,变为“Positive”后,先验知识与当前的上下文示例的输入-标签映射产生了不匹配。
在SUL- ICL中,上下文示例的标签被替换为与上下文中所呈现的任务在语义上无关的词语(例如,原 先的标签“Positive”,被替换为"Foo")。
ps:例如,原先的标签为影评领域的,现在替换为美食或者其他领域的词
我们发现,覆盖先验知识是随着模型规模的增大而涌现的一种能力(ps:覆盖先验知识可以理解为,从上 下文示例中学习,而不是预训练阶段的先验知识),从语义无关标签的上下文中学习的能力也是如此。我们还发现,指令微调(Instruct-tuning)对学习先验知识能力的加强上要超过对学习输入-标签映射的 增强。(下图为普通ICL,翻转标签ICL和语义无关ICL的示例)
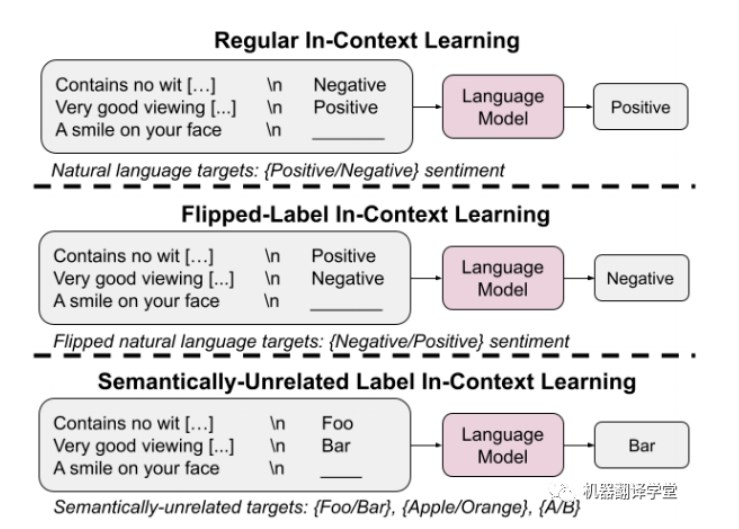
实验设计
我们在七个广泛使用的自然语言处理(NLP)任务上进行了实验:情感分析、主/客观分类、问题分类、 重复问题识别、蕴含关系识别、金融情感分析和仇恨言论检测。我们在5种LLM上进行测试:PaLM、Flan- PaLM、GPT-InstructGPT和Codex。
翻转标签(Flipped Labels-ICL)
在这个实验中,上下文示例的标签被翻转,意味着先验知识和输入-标签映射不一致(例如,包含正面情 感的句子被标记为“Negative”),从而让我们可以研究模型是否能够覆盖其先验知识。在这种情况下, 具备覆盖先验知识能力的模型的性能应该会下降(因为真实的评估标签没有被翻转)。(下图为使用翻 转标签ICL后,不同语言模型的不同尺寸的在测试集上的准确率变化)
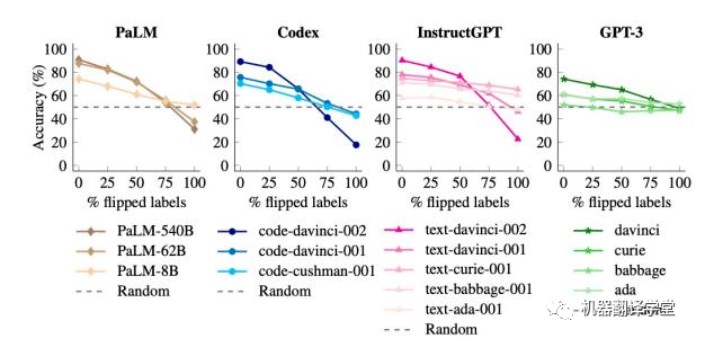
我们发现,当没有标签被翻转时,大型模型的性能优于小型模型(如预期所示)。但是,当我们翻转越来越多的标签时,小型模型的性能保持相对稳定,而大型模型的性能下降得非常明显,甚至低于随机猜 测的水平(例如,对于code-davinci-002模型,性能从90%下降到22.5%)。
这些结果表明,当上下文中出现与先验知识不一致的输入-标签映射时,大型模型可以覆盖预训练的先验 知识,而小型模型则无法做到。
作者说:此处,我理解为,更大的语言模型在覆盖先验知识的能力上更强,也就是更容易从给的上下文示例中学习到新的知识,如果给的上下文示例中存在与先验知识冲突的情况,则模型会更加偏重上下文示例。
语义无关标签(SUL-ICL)
在这个实验中,我们将标签替换为语义不相关的标签(例如,在情感分析中,我们使用“foo/bar”代替 “negative/positive”),这意味着模型只能通过学习输入-标签映射来执行ICL。如果模型在ICL中主要依 赖于先验知识,那么在进行这种更改后,其性能应该会下降,因为它将无法再利用标签的语义含义进行 预测。而如果模型能够在上下文中学习输入-标签映射,它就能够学习这些语义无关的映射,并且不应该 出现主要性能下降。
(下图为使用语义无关标签ICL后,不同语言模型的不同尺寸的在测试集上的准确率变化)
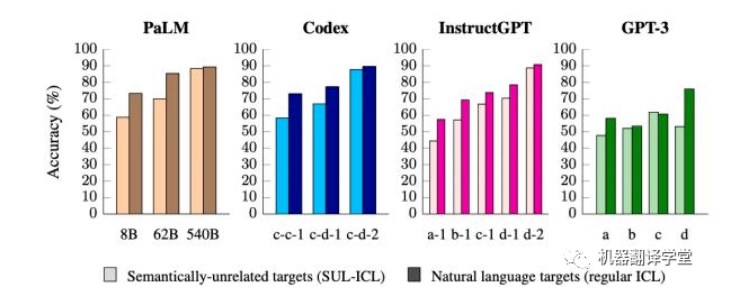
事实上,我们发现对于小型模型来说,使用语义无关标签导致了更大的性能下降。这表明,小型模型主要依赖于它们的语义先验知识进行ICL,而不是从给的的输入-标签映射示例中学习。另一方面,当这些标签标签不再具备其原来所有的语义时,大型模型的学习上下文中的输入-标签映射的能力更强。
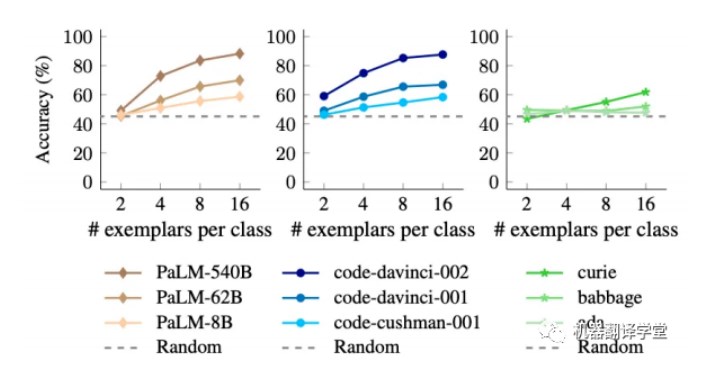
我们还发现,模型输入更多的上下文示例对于大型模型的性能的提升要强于小模型,这表明大型模型比 小型模型更擅长从上下文示例中学习。
(下图为使用不同数量的语义无关标签ICL后,不同语言模型的不同尺寸的在测试集上的准确率变化)
指令微调(Instruction tuning)
指令微调是一种提高模型性能的常用技术,它将各种自然语言处理(NLP)任务调整为指令的形式输入 给模型(例如,“问题:以下句子的情感是什么?答案:积极的“)。然而,由于该过程使用自然语言标签,一个悬而未决的问题是,它是否提高了学习输入-标签映射的能力,亦或是增强了学习并应用语义先验知识的能力。这两者都会给ICL任务带来性能提升,因此目前尚不清楚这两者中哪一个生效了。
我们通过前两个实验方法继续研究这个问题,但这一次我们专注于比较标准语言模型(PaLM)与经过指令微调的模型(Flan- PaLM)之间的差异。
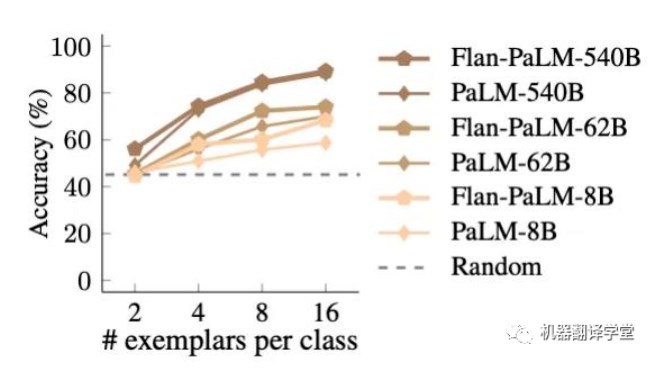
首先,我们发现在使用语义无关标签时, Flan- PaLM要优于PaLM。在小型模型中,这种效果非常明显, Flan- PaLM-8B的性能超过PaLM-8B约9.6%,并且接近PaLM-62B的性能。这一趋势表明,指令微调增强了学习输入-标签映射的能力。
(下图表明:指令微调后的模型更容易学习输入-标签映射)
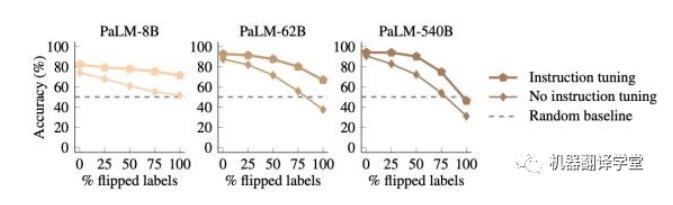
更有趣的是,我们发现Flan- PaLM在遵循翻转标签方面实际上比PaLM要差,这意味着经过指令调整的模型无法覆盖其先验知识(Flan- PaLM模型在100%翻转标签的情况下无法达到低于随机猜测 的水平,而没有经过指令调整的PaLM模型在相同设置下可以达到31%的准确率)。这些结果表明,指令调整必须增加模型在有语义先验知识可用时依赖于语义先验知识的程度。
(下图表示:指令微调后的模型,在使用翻转标签ICL时,更不容易覆盖先验知识)
结合之前的结果,我们得出结论,虽然指令微调提高了学习输入-标签映射的能力,但它在学习语义先验 知识上的加强更为突出。
结论
通过上述实验,可以得到以下的结论:
首先,大语言模型可以在输入足够多的翻转标签的情况下学会对先验知识的覆盖,并且这种能力随 着模型规模的增大而加强。
其次,使用语义无关标签进行上下文学习的能力随着模型规模的增大而加强。
最后,通过对指令微调后的语言模型的研究,发现指令微调虽然可以提高学习输入-标签映射的能 力,但远不如其对学习语义先验知识的加强。
未来工作
这些结果强调了语言模型的ICL行为在模型规模方面可能发生变化,而更大的语言模型具有将输入映射到更多种类型标签的能力,这可能使得模型可以学习任意符号的输入-标签映射。未来的研究可以帮助我们更好地理解这种现象。
审核编辑:刘清
-
Palm
+关注
关注
0文章
22浏览量
11283 -
icl
+关注
关注
0文章
28浏览量
17231 -
nlp
+关注
关注
1文章
488浏览量
22033
原文标题:In-Context-Learning在更大的语言模型上表现不同
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
大型语言模型的逻辑推理能力探究
【大语言模型:原理与工程实践】揭开大语言模型的面纱
【大语言模型:原理与工程实践】大语言模型的基础技术
【大语言模型:原理与工程实践】大语言模型的评测
【大语言模型:原理与工程实践】大语言模型的应用
大语言模型:原理与工程时间+小白初识大语言模型
HarmonyOS/OpenHarmony应用开发-Stage模型ArkTS语言AbilityStage
微软视觉语言模型有显著超越人类的表现
应用于任意预训练模型的prompt learning模型—LM-BFF

一文解析In-Context Learning
In-context learning如何工作?斯坦福学者用贝叶斯方法解开其奥秘
In-context learning介绍
大模型LLM领域,有哪些可以作为学术研究方向?

首篇!Point-In-Context:探索用于3D点云理解的上下文学习

鸿蒙开发组件:FA模型的Context





 工商网监
工商网监
评论