 基于文本到图像模型的可控文本到视频生成
基于文本到图像模型的可控文本到视频生成
1. 论文信息
2. 引言
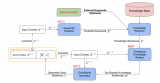
大规模扩散模型在文本到图像合成方面取得了巨大的突破,并在创意应用方面取得了成功。一些工作试图在视频领域复制这个成功,即在野外世界建模高维复杂视频分布。然而,训练这样的文本到视频模型需要大量高质量的视频和计算资源,这限制了相关社区进一步的研究和应用。为了减少过度的训练要求,我们研究了一种新的高效形式:基于文本到图像模型的可控文本到视频生成。这个任务旨在根据文本描述和运动序列(例如深度或边缘地图)生成视频。
如图所示,它可以有效地利用预训练的文本到图像生成模型的生成能力和运动序列的粗略时间一致性来生成生动的视频。
最近的研究探索了利用 ControlNet 或 DDIM inversion 的结构可控性进行视频生成。在这项工作中,我们提出了一个无需训练的高质量和一致的可控文本到视频生成方法ControlVideo,以及一种 交错帧平滑器来增强结构平滑度。
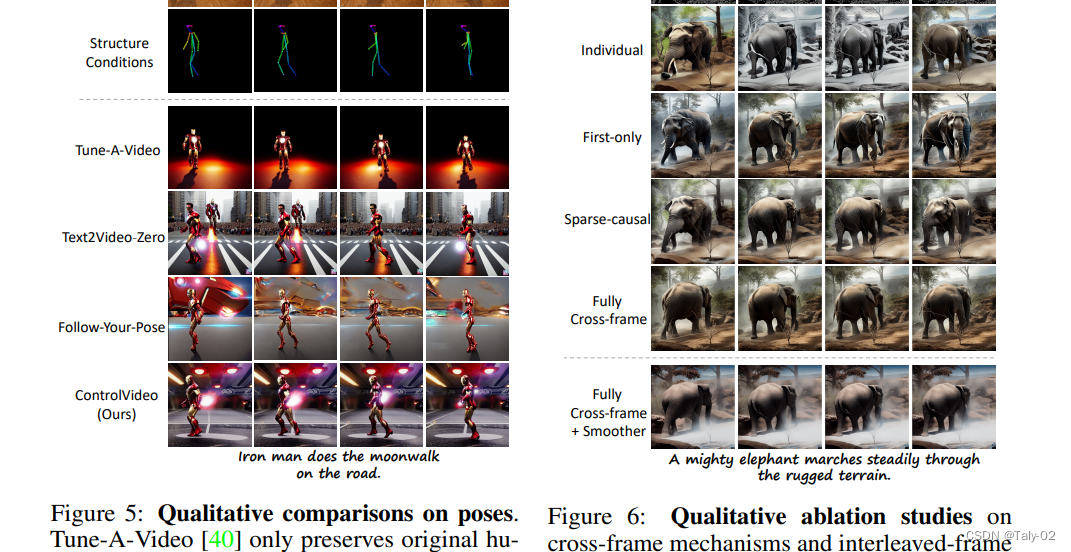
ControlVideo直接继承了 ControlNet 的架构和权重,通过扩展自注意力与 完全跨帧交互 使其适用于视频,与之前的工作不同,我们的完全跨帧交互将所有帧连接起来成为一个“更大的图像”,从而直接继承了 ControlNet 的高质量和一致的生成。交错帧平滑器通过在选定的连续时间步骤上交错插值来消除整个视频的闪烁。
如图所示,每个时间步骤的操作通过插值中间帧平滑交错的三帧片段,两个连续时间步骤的组合则平滑整个视频。为了实现高效的长视频合成,我们还引入了一种分层采样器来生成具有长期连贯性的独立短片段。具体而言,长视频首先被分割成多个具有选定关键帧的短视频片段。然后,关键帧通过全帧交互预先生成以实现长期连贯性。在关键帧的条件下,我们顺序合成相应的中间短视频片段,以实现全局一致性。作者在广泛收集的运动提示对上进行了实验。
实验结果表明,我们的方法在质量和量化标准上都优于其他竞争对手。由于采用了高效的设计,即 xFormers 实现和分层采样器,ControlVideo 可以在一个 NVIDIA 上几分钟内生成短视频和长视频。
3. 方法
3.0. 背景
潜在扩散模型(Latent Diffusion Model,简称LDM)是一种用于密度估计和生成高维数据(如图像和音频)的概率模型。它由Jonathan Ho和Stefano Ermon在2020年的论文Denosing Diffusion Probabilistic Models中提出。
LDM基于一个扩散过程,每一步向数据添加噪声,然后通过去噪函数去除噪声。扩散过程进行到数据完全被破坏,只剩下高斯噪声。模型通过反向扩散过程生成新数据,从高斯噪声开始,逐步去除噪声。
形式上,LDM定义了一系列条件分布,给出数据如下:
其中表示时间t的数据,是一个神经网络,将映射到,是一个固定的方差参数。扩散过程从原始数据开始,进行到,其中T是扩散步骤的总数。
为了生成新数据,LDM反转扩散过程,从以下条件分布中采样:
从开始,向后进行到。LDM可以通过最大化模型下数据的对数似然来进行训练,可以使用随机梯度下降有效地完成。LDM已经在图像生成和密度估计任务中取得了最先进的结果,并且已经扩展到处理缺失数据和半监督学习。
3.1. 方法
论文提出的方法包括三个关键组件:ControlNet、ControlVideo 和交错帧平滑器。这些组件通过控制噪声的传播路径,在生成的视频中保持了文本描述和运动信息之间的一致性,并通过完全跨帧交互和交错帧平滑器来保持了视频的连贯性和平滑性。
3.1.1 Fully Cross-Frame Interaction:
Fully Cross-Frame Interaction模块旨在通过使所有帧之间相互作用来增强生成视频的时间一致性。这是通过将所有视频帧连接成一个“大图像”,然后使用基于注意力机制的Fully Cross-Frame Interaction来计算帧间交互来实现的。完全跨帧交互模块可以表示为:
其中是通过连接所有视频帧形成的“大图像”,,和是查询、键和值矩阵,,和是可学习的权重矩阵。注意力机制通过将查询和键矩阵相乘,然后使用softmax函数进行归一化来计算注意力权重。最后,通过将注意力权重乘以值矩阵得到注意力值。
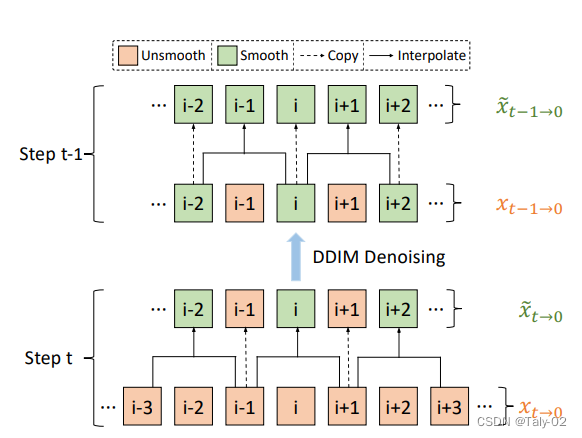
3.1.2 Interleaved-Frame Smoother:
Interleaved-Frame Smoother模块旨在减少合成视频中的抖动效果。这是通过插值每个三帧剪辑的中间帧,然后以交错的方式重复它来实现的。Interleaved-Frame Smoother可以表示为:
其中表示视频序列的第帧。Interleaved-Frame Smoother通过取前一帧和后一帧的平均值来插值每个三帧剪辑的中间帧。
3.1.3 Hierarchical Sampler:
Hierarchical Sampler模块旨在通过逐个剪辑地生成视频来实现高效和一致的长视频合成。在每个时间步中,将长视频分成多个短视频剪辑,并使用Fully Cross-Frame Attention预先生成关键帧以确保长距离的一致性。然后,在每对关键帧的条件下,按顺序合成相应的剪辑以确保整体一致性。Hierarchical Sampler可以表示为:
其中表示视频序列的第帧,是关键帧,是一个扩散模型,它在先前和下一帧的条件下生成视频帧。关键帧是使用Fully Cross-Frame Attention预先生成的,以确保长距离的一致性,而其余帧则使用扩散模型生成。
4. 实验

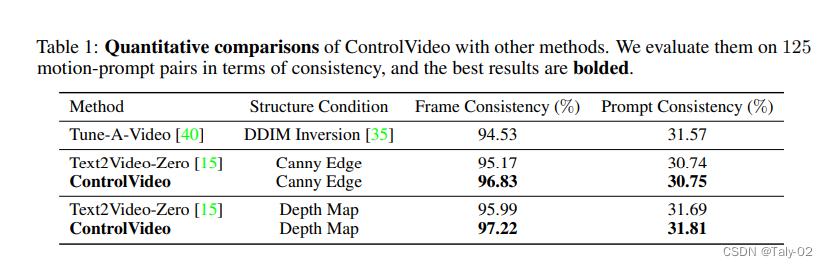
上图展示了对于视频生成方法的实验数据比较表格。共比较了三种方法:Tune-A-Video、Text2Video-Zero和ControlVideo。表格中的指标分为两列:Frame Consistency和Prompt Consistency。其中,Frame Consistency指的是生成的视频帧与输入的条件(Structure Condition)之间的一致性;Prompt Consistency指的是生成的视频与输入的描述(Prompt)之间的一致性。两列指标的数值都是百分比形式。可以看出,使用Canny Edge或Depth Map作为Structure Condition时,ControlVideo的Frame Consistency都比其他两种方法高,且Prompt Consistency基本持平。这说明ControlVideo在结构一致性方面表现优异,而在描述一致性方面与其他方法相当。需要注意的是,Prompt Consistency的数值普遍较低,这也是视频生成领域的一个研究难点。从具体数字来看,可以发现ControlVideo在两种Structure Condition下的Frame Consistency均优于其他两种方法,并且在Prompt Consistency方面与其他方法相当。此外,即使在表格中的最好表现下,Prompt Consistency的数值也普遍较低,这表明在描述一致性方面仍然存在改进空间。
该表格展示了一项用户偏好研究的结果,比较了两种方法和一种新的视频合成方法“Ours”。该研究评估了每种方法合成的视频在三个方面的质量:视频质量、时间一致性和文本对齐。表格中展现了在每个方面上有多少评估者更喜欢“Ours”合成的视频而不是其他方法的视频。总体而言,结果表明,“Ours”在视频质量、时间一致性和文本对齐方面表现比其他两种方法更好,因为它在所有三个方面上都得到了更高比例的评估者偏好。然而,需要注意的是,该研究仅反映了评估者的意见,可能并不一定反映视频合成方法的客观质量。

这一部分主要介绍了在用户研究和消融实验方面的结果,以及将该方法扩展到长视频生成的有效性。在用户研究中,本文与其他竞争方法进行了比较,并让参与者根据视频质量、时间连贯性和文本对齐等三个方面选择更好的合成视频。结果表明,本文的方法在所有三个方面都表现出了强大的优势。在消融实验中,本文进一步评估了完全跨帧交互和交错帧平滑器的效果,并发现它们都对视频生成的质量和连续性产生了重要影响。最后,本文还展示了如何将该方法扩展到长视频生成,通过引入分层采样器实现了高效的处理,使得该方法可以在低端硬件上生成高质量的长视频。
5. 讨论
这份工作存在以下局限性:
该方法的生成结果受预训练的文本到图像生成模型的质量和性能影响,因此其生成的视频可能存在与图像生成模型相关的问题,如图像分辨率、细节和颜色等方面的不足。
该方法需要输入运动序列,如深度或边缘地图,以帮助生成视频,这可能会限制其适用范围,因为这些运动序列可能难以获取。
由于该方法使用分层采样器来生成长视频,因此在生成非常长的视频时可能会存在一些不连贯的问题。
该方法的处理速度受到硬件和预训练模型的性能限制,对于某些应用场景可能需要更快的处理速度。
大规模扩散模型在文本到视频合成方面取得了巨大进展,但这些模型成本高昂且不对公众开放。我们的ControlVideo专注于无需训练的可控文本到视频生成,并在高效视频创建方面迈出了重要一步。具体而言,ControlVideo可以使用普通硬件合成高质量的视频,因此可供大多数研究人员和用户使用。例如,艺术家可以利用我们的方法在更短的时间内创建出迷人的视频。此外,ControlVideo为视频渲染、视频编辑和视频到视频转换等任务提供了洞见。然而,虽然作者不打算将模型用于有害目的,但它可能会被滥用并带来一些潜在的负面影响,例如制作欺骗性、有害性或含有不当内容的视频。尽管存在以上担忧,但我们相信可以通过一些措施来将其最小化。例如,可以使用NSFW过滤器来过滤不健康和暴力内容。此外,我们希望政府能够建立和完善相关法规以限制视频创作的滥用。较为合适的应用场景包括但不限于:
视频游戏开发:可以使用该方法生成游戏场景中的动态场景,如人物移动、车辆行驶等。
电影和广告制作:可以使用该方法生成预览或草图,以帮助制片人和广告商确定最终的场景和效果。
交互式虚拟现实应用:可以使用该方法生成虚拟现实场景,如虚拟旅游、虚拟展览等。
视频编辑和后期制作:可以使用该方法生成缺失的镜头或补充一些场景,以帮助编辑和后期制作人员完成工作。
6. 结论
这一部分主要介绍了在用户研究和消融实验方面的结果,以及将该方法扩展到长视频生成的有效性。在用户研究中,本文与其他竞争方法进行了比较,并让参与者根据视频质量、时间连贯性和文本对齐等三个方面选择更好的合成视频。结果表明,本文的方法在所有三个方面都表现出了强大的优势。在消融实验中,本文进一步评估了完全跨帧交互和交错帧平滑器的效果,并发现它们都对视频生成的质量和连续性产生了重要影响。最后,本文还展示了如何将该方法扩展到长视频生成,通过引入分层采样器实现了高效的处理,使得该方法可以在低端硬件上生成高质量的长视频。
责任编辑:彭菁
-
数据
+关注
关注
8文章
7002浏览量
88937 -
视频
+关注
关注
6文章
1942浏览量
72883 -
模型
+关注
关注
1文章
3226浏览量
48804
原文标题:ControlVideo: 可控的Training-free的文本生成视频
文章出处:【微信号:GiantPandaCV,微信公众号:GiantPandaCV】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

受控文本生成模型的一般架构及故事生成任务等方面的具体应用





 工商网监
工商网监
评论