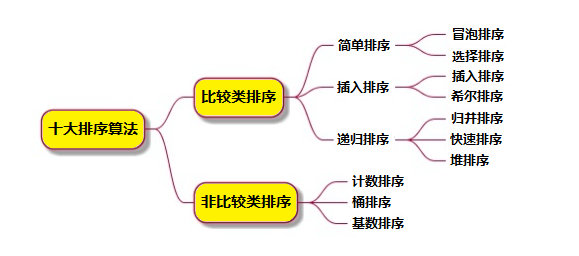
 常见排序算法分类
常见排序算法分类
本文将通过动态演示+代码的形式系统地总结十大经典排序算法。
排序算法
算法分类 —— 十种常见排序算法可以分为两大类:
- 比较类排序:通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlogn),因此也称为非线性时间比较类排序。
- 非比较类排序:不通过比较来决定元素间的相对次序,它可以突破基于比较排序的时间下界,以线性时间运行,因此也称为线性时间非比较类排序。
算法复杂度
| 排序算法 | 平均时间复杂度 | 最差时间复杂度 | 空间复杂度 | 数据对象稳定性 |
|---|---|---|---|---|
| 冒泡排序 | O(n2) | O(n2) | O(1) | 稳定 |
| 选择排序 | O(n2) | O(n2) | O(1) | 数组不稳定、链表稳定 |
| 插入排序 | O(n2) | O(n2) | O(1) | 稳定 |
| 快速排序 | O(n*log2n) | O(n2) | O(log2n) | 不稳定 |
| 堆排序 | O(n*log2n) | O(n*log2n) | O(1) | 不稳定 |
| 归并排序 | O(n*log2n) | O(n*log2n) | O(n) | 稳定 |
| 希尔排序 | O(n*log2n) | O(n2) | O(1) | 不稳定 |
| 计数排序 | O(n+m) | O(n+m) | O(n+m) | 稳定 |
| 桶排序 | O(n) | O(n) | O(m) | 稳定 |
| 基数排序 | O(k*n) | O(n2) | 稳定 |
1. 冒泡排序
算法思想:
- (1)比较相邻的元素。如果第一个比第二个大,就交换它们两个;
- (2)对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数;
- (3)针对所有的元素重复以上的步骤,除了最后一个;
- (4)重复步骤1~3,直到排序完成。
代码:
void bubbleSort(int a[], int n)
{
for(int i =0 ; i< n-1; ++i)
{
for(int j = 0; j < n-i-1; ++j)
{
if(a[j] > a[j+1])
{
int tmp = a[j] ; //交换
a[j] = a[j+1] ;
a[j+1] = tmp;
}
}
}
}
2. 选择排序
算法思想:
- (1)在未排序序列中找到最小(大)元素,存放到排序序列的起始位置;
- (2)从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末;
- (3)以此类推,直到所有元素均排序完毕;
代码:
void selectionSort(int arr[], int n) {
int minIndex, temp;
for (int i = 0; i < n - 1; i++) {
minIndex = i;
for (var j = i + 1; j < n; j++) {
if (arr[j] < arr[minIndex]) { // 寻找最小的数
minIndex = j; // 将最小数的索引保存
}
}
temp = arr[i];
arr[i] = arr[minIndex];
arr[minIndex] = temp;
}
for (int k = 0; i < n; i++) {
printf("%d ", arr[k]);
}
}
3. 插入排序
算法思想:
- (1)从第一个元素开始,该元素可以认为已经被排序;
- (2)取出下一个元素,在已经排序的元素序列中从后向前扫描;
- (3)如果该元素(已排序)大于新元素,将该元素移到下一位置;
- (4)重复步骤3,直到找到已排序的元素小于或者等于新元素的位置;
- (5)将新元素插入到该位置后;
- (6)重复步骤2~5。
代码:
void print(int a[], int n ,int i){
cout< ":";
for(int j= 0; j< 8; j++){
cout< " ";
}
cout<
算法分析:插入排序在实现上,通常采用in-place排序(即只需用到O(1)的额外空间的排序),因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
4. 快速排序
快速排序的基本思想是通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
算法思想:
- (1)选取第一个数为基准
- (2)将比基准小的数交换到前面,比基准大的数交换到后面
- (3)递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序
代码:
void QuickSort(vector< int >& v, int low, int high) {
if (low >= high) // 结束标志
return;
int first = low; // 低位下标
int last = high; // 高位下标
int key = v[first]; // 设第一个为基准
while (first < last)
{
// 将比第一个小的移到前面
while (first < last && v[last] >= key)
last--;
if (first < last)
v[first++] = v[last];
// 将比第一个大的移到后面
while (first < last && v[first] <= key)
first++;
if (first < last)
v[last--] = v[first];
}
//
v[first] = key;
// 前半递归
QuickSort(v, low, first - 1);
// 后半递归
QuickSort(v, first + 1, high);
}
5. 堆排序
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子节点的键值或索引总是小于(或者大于)它的父节点。
算法思想:
- (1)将初始待排序关键字序列(R1,R2….Rn)构建成大顶堆,此堆为初始的无序区;
- (2)将堆顶元素R[1]与最后一个元素R[n]交换,此时得到新的无序区(R1,R2,……Rn-1)和新的有序区(Rn),且满足R[1,2…n-1]<=R[n];
- (3)由于交换后新的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R1,R2,……Rn-1)调整为新堆,然后再次将R[1]与无序区最后一个元素交换,得到新的无序区(R1,R2….Rn-2)和新的有序区(Rn-1,Rn)。不断重复此过程直到有序区的元素个数为n-1,则整个排序过程完成。
代码:
#include
#include
using namespace std;
// 堆排序:(最大堆,有序区)。从堆顶把根卸出来放在有序区之前,再恢复堆。
void max_heapify(int arr[], int start, int end) {
//建立父节点指标和子节点指标
int dad = start;
int son = dad * 2 + 1;
while (son <= end) { //若子节点在范围内才做比较
if (son + 1 <= end && arr[son] < arr[son + 1]) //先比较两个子节点指标,选择最大的
son++;
if (arr[dad] > arr[son]) //如果父节点大于子节点代表调整完成,直接跳出函数
return;
else { //否则交换父子內容再继续子节点与孙节点比較
swap(arr[dad], arr[son]);
dad = son;
son = dad * 2 + 1;
}
}
}
void heap_sort(int arr[], int len) {
//初始化,i从最后一个父节点开始调整
for (int i = len / 2 - 1; i >= 0; i--)
max_heapify(arr, i, len - 1);
//先将第一个元素和已经排好的元素前一位做交换,再从新调整(刚调整的元素之前的元素),直到排序完成
for (int i = len - 1; i > 0; i--) {
swap(arr[0], arr[i]);
max_heapify(arr, 0, i - 1);
}
}
int main() {
int arr[] = { 3, 5, 3, 0, 8, 6, 1, 5, 8, 6, 2, 4, 9, 4, 7, 0, 1, 8, 9, 7, 3, 1, 2, 5, 9, 7, 4, 0, 2, 6 };
int len = (int) sizeof(arr) / sizeof(*arr);
heap_sort(arr, len);
for (int i = 0; i < len; i++)
cout < < arr[i] < < ' ';
cout < < endl;
return 0;
}