 SENSORO 支撑百万级传感器的延时队列
SENSORO 支撑百万级传感器的延时队列
文/升哲科技刘鹏
摘要:本文主要描述升哲科技在打造物联智慧城市平台过程中关于如何实现延时队列服务的技术选型经验、延时队列服务的架构设计以及延时队列的底层细节实现原理。
背景
升哲科技是一家物联网与人工智能领域的国家高新技术企业、独角兽企业。
要打造物联智慧城市平台,在业务中涉及到各种延时任务的需求,例如设备定时空气开关,定时更新设备状态,定时提醒等等,基于这些需求,需要一个可靠、实时、海量的延时队列服务作为基础设施。
那么延时队列是什么呢?延时队列不同于消息队列按照先入先出(FIFO)的顺序来消费,而是根据消息指定时间延时消费。延时队列的使用在我们日常应用也非常多,比如:
· 在电商平台购物,在30分钟内没有支付自动取消订单;
· 待处理的工单超过1天未处理,二次发送提醒。
以上场景往往都需要延时队列实现。
早期延时队列的实现采用了数据库扫表方式,服务定期查询到期的任务,再通过Kafka来中转消息。当任务量小,延时精度要求低时扫表方式还能应对,然而随着业务增长、任务数量不断增多,延时时间精度要求也变高,扫表的方式已经无法满足我们的业务,于是我们开始探索新的技术方案来支撑百万级任务的延时队列。
延时队列的设计目标
1.高可用:多副本部署,保证服务不出现单点故障;
2.可扩展:可随着业务量增长来扩容,同时生产消费的请求延时也要低;
3.兼容旧接口,保证旧的服务不需要做任何修改;
4.消息传递可靠,至少保证一次送达。
技术选型
在开源社区已经存在一些解决方案:
| 方案 | 描述 |
| Beanstalkd | Beanstalkd C语言实现,我们团队主要采用Golang和Java,二次开发有难度,beanstalkd不支持集群部署,高可用无法保证。 |
| RabbitMQ延时队列 | RabbitMQ提供了延时队列插件,需要单独开启插件使用,其原理是通过死信队列实现。 |
NSQ | NSQ开源延时队列,NSQ支持延时队列。 |
DelayQueue延时队列 | JDK中提供了一组实现延时队列的API,位于Java.util.concurrent包下DelayQueue。 |
时间轮算法 | 时间轮是一个算法,在 Netty、Akka、Quartz、ZooKeeper、Kafka等组件中都有使用,适合做统一调度器。 |
| Redis Sorted Set 利用它的score属性,启用一个线程轮询,根据score获取超时的数据,然后触发超时操作。 |
考虑到运维难度和可扩展性,最终我们选择了开源项目Lmstfy作为基础来进行二次开发,选择Lmstfy的原因如下:
● 无状态服务,使用Redis来持久化,Redis的高可用方案已经非常成熟,在公/私有云都有Paas服务可使用;
● 支持扩容,可以配置多个Redis集群;
● 提供Java/Go/Rust/PHP客户端,监控面板完善;
● 采用Golang开发,高并发性能优秀,也方便后续二次开发。
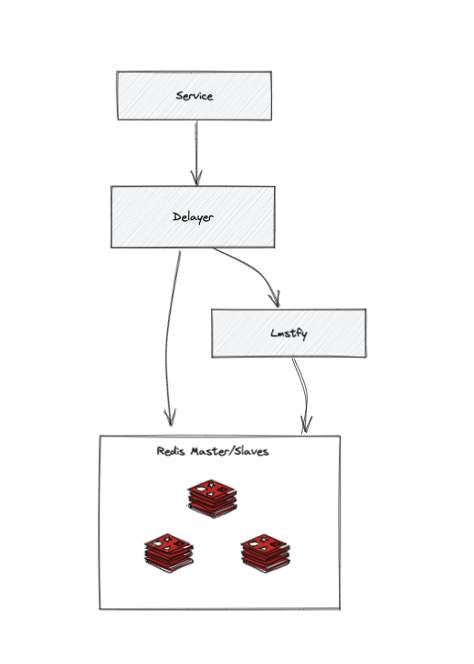
整体架构设计
1.Delayer:无状态服务,提供给业务服务调用,兼容旧接口,在Delayer这一层直接操作Redis实现了任务删除和更新任务等等功能;
2.Lmstfy:无状态服务,提供延时队列基础服务,底层实现采用;
3.Redis Sentinel集群:保证Redis发生故障时自动主备切换。
基础概念
● namespace -用于隔离业务,也可以通过配置namespace绑定不同的Redis集群;
● queue -队列,用区分同一业务不同消息类型;
● job -业务定义的业务,主要包含以下几个属性:
○ id:任务 ID,全局唯一;
○ delay:任务延时下发时间,单位是秒;
○ tries:任务最大重试次数,tries = N表示任务会最多下发 N次;
○ ttr(time to run):任务预期执行时间,超过 ttr则认为任务消费失败,触发任务自动重试。
数据存储
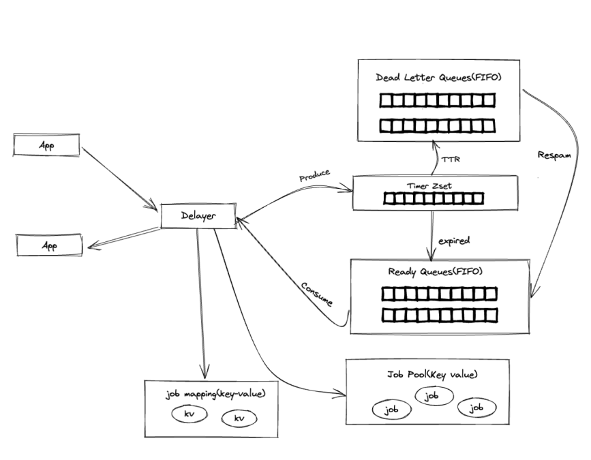
Lmstfy的 Redis存储由四部分组成:
● Timer:使用ZSET结构来存储延时任务,Score即任务的到期时间来排序;
● Ready queue - 使用LIST结构,存储已经到期的延时任务,实现FIFO消费;
● Deadletter-使用LIST结构,消费失败(重试次数到达上限)的任务,可以手动重新放回到队列;
● Job pool– string类型,存储消息meta信息;
● Job mapping - string -存储应用自定义id和job的关联关系。
创建任务
创建任务会生成一个Job ID, Job ID包括写入时间戳、随机数和延时时长,然后将任务的meta信息写入Redis,Key为 j/{namespace}/queue/{id},当任务延时时间(delay)= 0,(实时消息队列我们使用Kafka)表示不需要延时则直接写到 Ready Queue(List),当延时时间(delay) = n(n > 0),表示需要延时,将延时加上当前系统时间作为绝对时间戳写到 Timer(sorted set),Timer的实现是利用 ZSET根据绝对时间戳进行排序,再由一个goroutine定期轮询将到期的任务通过 redis lua script来将数据转移到 Ready Queue(List)中。
任务消费
支持延时的任务队列本质上是两个数据结构的结合: Ready Queue(LIST)和 Sorted Set。
Sorted Set用来实现延时的部分,将任务按照到期时间戳升序存储,随后定期将到期的任务迁移至 Ready Queue(LIST)。
任务的具体内容只会存储一份在 Job pool里面,其他的如 Ready Queue只是存储Job id,这样可以节省内存空间。
任务更新和删除
Lmstfy本身不支持删除和更新,我们在Delayer层中在创建任务同时在Redis中创建了一个Mapping Key,客户端可以自定一个ID关联到Job id,Delayer提供了删除和更新(先删除再创建)API,我们业务还需要支持多次执行的功能,在处理Job Ack时根据任务参数重新插入队列,结合我们二次开发整体结构如下:
性能表现
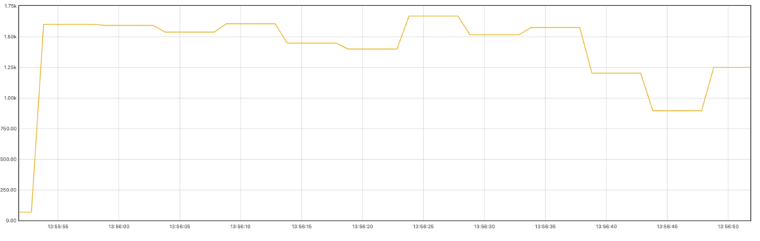
通过本地限定1核CPU压测生产消息数据如下:
200万任务量占内存600MB+,其中包括mapping key导致key数量翻倍。
以下是单核CPU的环境下压测结果,任务创建可高达1500TPS:
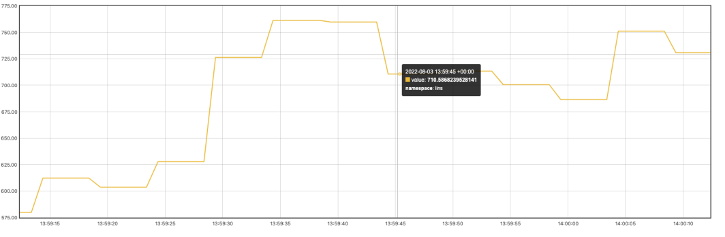
延时任务到期时间比较分散的情况下,消费表现如下接800TPS:
总结
封装lmstfy的方案已足够支撑当前的使用场景,但还是有一些不足之处,比如:
● 在Delayer中操作Redis中的任务,无法保证原子性;
● 任务创建和消费另外会多一次网络请求,产生不必要的开销;
● 无法支持循环任务;
● Lmstfy采用HTTP协议,无法发挥更好性能。
未来,我们计划融合两个服务,完善任务CRUD功能,减少网络开销,并采用GRPC来替换HTTP协议通讯。
-
大数据
+关注
关注
64文章
8882浏览量
137392 -
智慧城市
+关注
关注
21文章
4261浏览量
97264
发布评论请先 登录
相关推荐
纳芯微发布两款车规级压力传感器新品
霍尔传感器测电压会有延时吗
车载传感器主要有哪些传感器
长光辰芯发布亿级像素CMOS图像传感器GMAX64104
TMP275-Q1汽车级±0.75°C温度传感器数据表







 工商网监
工商网监
评论