 KUKA机器人ASCII码的运用
KUKA机器人ASCII码的运用
ASCII 表
分类 编程技术
ASCII(发音:,American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统。它主要用于显示现代英语,而其扩展版本延伸美国标准信息交换码则可以部分支持其他西欧语言,并等同于国际标准ISO/IEC 646。
| DEC | OCT | HEX | BIN | 缩写/符号 | HTML实体 | 描述 |
|---|---|---|---|---|---|---|
| 0 | 000 | 00 | 00000000 | NUL | � | Null char (空字符) |
| 1 | 001 | 01 | 00000001 | SOH | � | Start of Heading (标题开始) |
| 2 | 002 | 02 | 00000010 | STX | � | Start of Text (正文开始) |
| 3 | 003 | 03 | 00000011 | ETX | � | End of Text (正文结束) |
| 4 | 004 | 04 | 00000100 | EOT | � | End of Transmission (传输结束) |
| 5 | 005 | 05 | 00000101 | ENQ | � | Enquiry (请求) |
| 6 | 006 | 06 | 00000110 | ACK | � | Acknowledgment (收到通知) |
| 7 | 007 | 07 | 00000111 | BEL | � | Bell (响铃) |
| 8 | 010 | 08 | 00001000 | BS | � | Back Space (退格) |
| 9 | 011 | 09 | 00001001 | HT | Horizontal Tab (水平制表符) | |
| 10 | 012 | 0A | 00001010 | LF | Line Feed (换行键) | |
| 11 | 013 | 0B | 00001011 | VT | � | Vertical Tab (垂直制表符) |
| 12 | 014 | 0C | 00001100 | FF | Form Feed (换页键) | |
| 13 | 015 | 0D | 00001101 | CR | Carriage Return (回车键) | |
| 14 | 016 | 0E | 00001110 | SO | � | Shift Out / X-On (不用切换) |
| 15 | 017 | 0F | 00001111 | SI | � | Shift In / X-Off (启用切换) |
| 16 | 020 | 10 | 00010000 | DLE | � | Data Line Escape (数据链路转义) |
| 17 | 021 | 11 | 00010001 | DC1 | � | Device Control 1 (设备控制1) |
| 18 | 022 | 12 | 00010010 | DC2 | � | Device Control 2 (设备控制2) |
| 19 | 023 | 13 | 00010011 | DC3 | � | Device Control 3 (设备控制3) |
| 20 | 024 | 14 | 00010100 | DC4 | � | Device Control 4 (设备控制4) |
| 21 | 025 | 15 | 00010101 | NAK | � | Negative Acknowledgement (拒绝接收) |
| 22 | 026 | 16 | 00010110 | SYN | � | Synchronous Idle (同步空闲) |
| 23 | 027 | 17 | 00010111 | ETB | � | End of Transmit Block (传输块结束) |
| 24 | 030 | 18 | 00011000 | CAN | � | Cancel (取消) |
| 25 | 031 | 19 | 00011001 | EM | � | End of Medium (介质中断) |
| 26 | 032 | 1A | 00011010 | SUB | � | Substitute (替补) |
| 27 | 033 | 1B | 00011011 | ESC | � | Escape (溢出) |
| 28 | 034 | 1C | 00011100 | FS | � | File Separator (文件分割符) |
| 29 | 035 | 1D | 00011101 | GS | � | Group Separator (分组符) |
| 30 | 036 | 1E | 00011110 | RS | � | Record Separator (记录分离符) |
| 31 | 037 | 1F | 00011111 | US | � | Unit Separator (单元分隔符) |
| 32 | 040 | 20 | 00100000 | Space (空格) | ||
| 33 | 041 | 21 | 00100001 | ! | ! | Exclamation mark |
| 34 | 042 | 22 | 00100010 | " | " | Double quotes |
| 35 | 043 | 23 | 00100011 | # | # | Number |
| 36 | 044 | 24 | 00100100 | $ | $ | Dollar |
| 37 | 045 | 25 | 00100101 | % | % | Procenttecken |
| 38 | 046 | 26 | 00100110 | & | & | Ampersand |
| 39 | 047 | 27 | 00100111 | ’ | ' | Single quote |
| 40 | 050 | 28 | 00101000 | ( | ( | Open parenthesis |
| 41 | 051 | 29 | 00101001 | ) | ) | Close parenthesis |
| 42 | 052 | 2A | 00101010 | * | * | Asterisk |
| 43 | 053 | 2B | 00101011 | + | + | Plus |
| 44 | 054 | 2C | 00101100 | , | , | Comma |
| 45 | 055 | 2D | 00101101 | - | - | Hyphen |
| 46 | 056 | 2E | 00101110 | . | . | Period, dot or full stop |
| 47 | 057 | 2F | 00101111 | / | / | Slash or divide |
| 48 | 060 | 30 | 00110000 | 0 | 0 | Zero |
| 49 | 061 | 31 | 00110001 | 1 | 1 | One |
| 50 | 062 | 32 | 00110010 | 2 | 2 | Two |
| 51 | 063 | 33 | 00110011 | 3 | 3 | Three |
| 52 | 064 | 34 | 00110100 | 4 | 4 | Four |
| 53 | 065 | 35 | 00110101 | 5 | 5 | Five |
| 54 | 066 | 36 | 00110110 | 6 | 6 | Six |
| 55 | 067 | 37 | 00110111 | 7 | 7 | Seven |
| 56 | 070 | 38 | 00111000 | 8 | 8 | Eight |
| 57 | 071 | 39 | 00111001 | 9 | 9 | Nine |
| 58 | 072 | 3A | 00111010 | : | : | Colon |
| 59 | 073 | 3B | 00111011 | ; | ; | Semicolon |
| 60 | 074 | 3C | 00111100 | < | < | Less than |
| 61 | 075 | 3D | 00111101 | = | = | Equals |
| 62 | 076 | 3E | 00111110 | > | > | Greater than |
| 63 | 077 | 3F | 00111111 | ? | ? | Question mark |
| 64 | 100 | 40 | 01000000 | @ | @ | At symbol |
| 65 | 101 | 41 | 01000001 | A | A | Uppercase A |
| 66 | 102 | 42 | 01000010 | B | B | Uppercase B |
| 67 | 103 | 43 | 01000011 | C | C | Uppercase C |
| 68 | 104 | 44 | 01000100 | D | D | Uppercase D |
| 69 | 105 | 45 | 01000101 | E | E | Uppercase E |
| 70 | 106 | 46 | 01000110 | F | F | Uppercase F |
| 71 | 107 | 47 | 01000111 | G | G | Uppercase G |
| 72 | 110 | 48 | 01001000 | H | H | Uppercase H |
| 73 | 111 | 49 | 01001001 | I | I | Uppercase I |
| 74 | 112 | 4A | 01001010 | J | J | Uppercase J |
| 75 | 113 | 4B | 01001011 | K | K | Uppercase K |
| 76 | 114 | 4C | 01001100 | L | L | Uppercase L |
| 77 | 115 | 4D | 01001101 | M | M | Uppercase M |
| 78 | 116 | 4E | 01001110 | N | N | Uppercase N |
| 79 | 117 | 4F | 01001111 | O | O | Uppercase O |
| 80 | 120 | 50 | 01010000 | P | P | Uppercase P |
| 81 | 121 | 51 | 01010001 | Q | Q | Uppercase Q |
| 82 | 122 | 52 | 01010010 | R | R | Uppercase R |
| 83 | 123 | 53 | 01010011 | S | S | Uppercase S |
| 84 | 124 | 54 | 01010100 | T | T | Uppercase T |
| 85 | 125 | 55 | 01010101 | U | U | Uppercase U |
| 86 | 126 | 56 | 01010110 | V | V | Uppercase V |
| 87 | 127 | 57 | 01010111 | W | W | Uppercase W |
| 88 | 130 | 58 | 01011000 | X | X | Uppercase X |
| 89 | 131 | 59 | 01011001 | Y | Y | Uppercase Y |
| 90 | 132 | 5A | 01011010 | Z | Z | Uppercase Z |
| 91 | 133 | 5B | 01011011 | [ | [ | Opening bracket |
| 92 | 134 | 5C | 01011100 | Backslash | ||
| 93 | 135 | 5D | 01011101 | ] | ] | Closing bracket |
| 94 | 136 | 5E | 01011110 | ^ | ^ | Caret - circumflex |
| 95 | 137 | 5F | 01011111 | _ | _ | Underscore |
| 96 | 140 | 60 | 01100000 | ` | ` | Grave accent |
| 97 | 141 | 61 | 01100001 | a | a | Lowercase a |
| 98 | 142 | 62 | 01100010 | b | b | Lowercase b |
| 99 | 143 | 63 | 01100011 | c | c | Lowercase c |
| 100 | 144 | 64 | 01100100 | d | d | Lowercase d |
| 101 | 145 | 65 | 01100101 | e | e | Lowercase e |
| 102 | 146 | 66 | 01100110 | f | f | Lowercase f |
| 103 | 147 | 67 | 01100111 | g | g | Lowercase g |
| 104 | 150 | 68 | 01101000 | h | h | Lowercase h |
| 105 | 151 | 69 | 01101001 | i | i | Lowercase i |
| 106 | 152 | 6A | 01101010 | j | j | Lowercase j |
| 107 | 153 | 6B | 01101011 | k | k | Lowercase k |
| 108 | 154 | 6C | 01101100 | l | l | Lowercase l |
| 109 | 155 | 6D | 01101101 | m | m | Lowercase m |
| 110 | 156 | 6E | 01101110 | n | n | Lowercase n |
| 111 | 157 | 6F | 01101111 | o | o | Lowercase o |
| 112 | 160 | 70 | 01110000 | p | p | Lowercase p |
| 113 | 161 | 71 | 01110001 | q | q | Lowercase q |
| 114 | 162 | 72 | 01110010 | r | r | Lowercase r |
| 115 | 163 | 73 | 01110011 | s | s | Lowercase s |
| 116 | 164 | 74 | 01110100 | t | t | Lowercase t |
| 117 | 165 | 75 | 01110101 | u | u | Lowercase u |
| 118 | 166 | 76 | 01110110 | v | v | Lowercase v |
| 119 | 167 | 77 | 01110111 | w | w | Lowercase w |
| 120 | 170 | 78 | 01111000 | x | x | Lowercase x |
| 121 | 171 | 79 | 01111001 | y | y | Lowercase y |
| 122 | 172 | 7A | 01111010 | z | z | Lowercase z |
| 123 | 173 | 7B | 01111011 | { | { | Opening brace |
| 124 | 174 | 7C | 01111100 | | | | | Vertical bar |
| 125 | 175 | 7D | 01111101 | } | } | Closing brace |
| 126 | 176 | 7E | 01111110 | ~ | ~ | Equivalency sign (tilde) |
| 127 | 177 | 7F | 01111111 | � | Delete |
ASCII 来历
ASCII 由电报码发展而来。第一版标准发布于1963年 ,1967年经历了一次主要修订[5][6],最后一次更新则是在1986年,至今为止共定义了128个字符;其中33个字符无法显示(一些终端提供了扩展,使得这些字符可显示为诸如笑脸、扑克牌花式等8-bit符号),且这33个字符多数都已是陈废的控制字符。控制字符的用途主要是用来操控已经处理过的文字。在33个字符之外的是95个可显示的字符。用键盘敲下空白键所产生的空白字符也算1个可显示字符(显示为空白)。
可显示字符
可显示字符编号范围是32-126(0x20-0x7E),共95个字符。
控制字符
ASCII控制字符的编号范围是0-31和127(0x00-0x1F和0x7F),共33个字符。
为什么非弄这么个东西呢
在计算机中,任何数据都以二进制的形式存储。
然后很明显地,我们没法用这个东西去真正意义上的存个字母"a"进去,因为再怎么说二进制数最后只能落实成数而不是文本。
这就好像电报一样,电报只能发送电信号,无论如何也不可能发送一个手写的字母"a",但是我们又需要用这东西传递信息,那么如果我们想用电报表示文本,那就只能对每一个文本进行编码(Encoding)。
于是才有了类似于摩斯电码等等电报编码的方式,这些编码的目的就是把文本转换成数值信号。
"A"→⋅−
那么对于ASCII也是同理,他是一种把字符编码成二进制的方式:
a→(0110 0001)B=97
因为只有转换成二进制数才能被计算机存储和发送。
当然ASCII只是一种编码方式而已,当然还有其他的编码方式。
KUKA的使用:
| Character | CHAR |
1 个字符 ASCII 字符 示例:"A"; "1"; "q" |
DEF MY_PROG( )
DECL CHAR name[10]
name="OKAY"
给数组的前 4 个元素赋值。这相当于:
name[1] = "O"
name[2] = "K"
name[3] = "A"
name[4] = "Y"
(一个 CHAR 变量始终只能含有 1 个 ASCII 字符。)
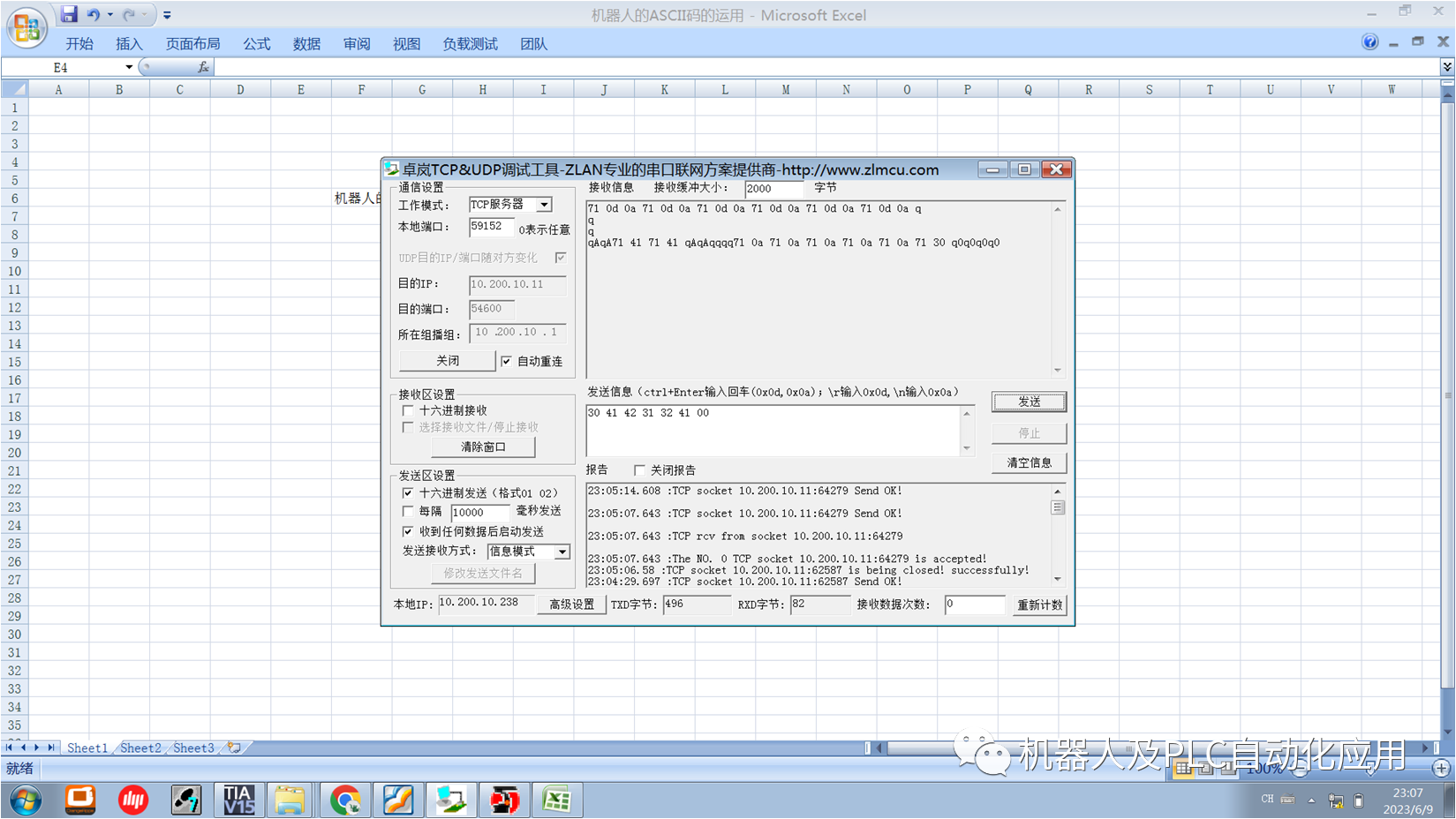
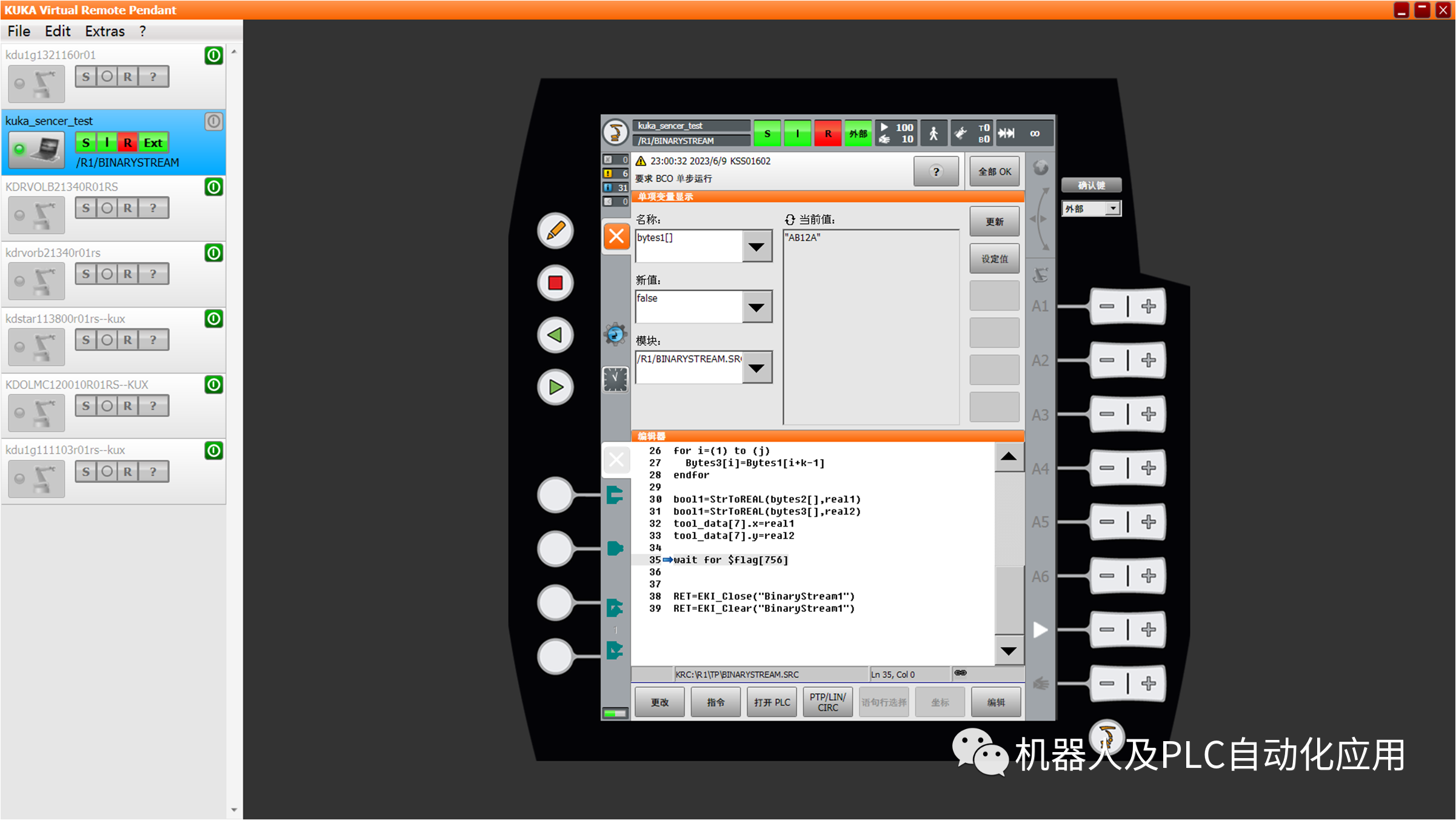
ENUM常量的内部值以ASCII表示法传输。相应的号码被转移:
DECL ENUM_TYP E
CWRITE(HANDLE,SW_T,MW_T,"%d",E)
整数变量VI的值以十进制和十六进制ASCII表示法传输。第一个CWRITE状态传输字符123。第二个CWRITE语句传输字符7B。
INT VI
VI=123
CWRITE(HANDLE,SW_T,MW_T,"%d",VI)
CWRITE(HANDLE,SW_T,MW_T,"%x",VI)
审核编辑:汤梓红
-
机器人
+关注
关注
211文章
28379浏览量
206906 -
计算机
+关注
关注
19文章
7488浏览量
87846 -
ASCII
+关注
关注
5文章
172浏览量
35089 -
KUKA
+关注
关注
3文章
217浏览量
16516
原文标题:KUKA 机器人关于机器人的ASCII码的运用6.16 完善ASCII对照表
文章出处:【微信号:gh_a8b121171b08,微信公众号:机器人及PLC自动化应用】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
KUKA机器人问题解答
库卡KUKA机器人四种启动方式介绍
KUKA库卡机器人伺服驱动器相关型号举例
KUKA焊接机器人伺服电机常见故障及维修处理
工业机器人组成结构相关资料分享
库卡机器人MGV电源模块维修
机器人系统与控制需求简介
没有有前辈用LabVIEW控制kuka机器人c2的经验?通讯是怎么做到的?
KUKA机器人相关分类及型号一览
关于KUKA机器人ASCII码的运用






 工商网监
工商网监
评论