 列存储索引的空间使用
列存储索引的空间使用
01、列存储的特点
02、列存储的物理实现
03、列存储索引
04、列存储索引的空间使用
传统的存储数据的方式是逐行存储(Row Store),每一个Page存储多行数据,而列存储(Column Store)把数据表中的每一列单独存储在Page集合中,这意味着,Page集合中存储的是某一列的数据,而不是一行的所有列的数据。
列存储索引适合于数据仓库中,主要执行大容量数据加载和只读查询,与传统面向行的存储方式相比,使用列存储索引存储可最多提高 10 倍查询性能 ,与使用非压缩数据大小相比,可提供多达 7 倍数据压缩率 。列存储索引使用用“批处理执行模式”的模式,这与行存储使用的逐行数据读取模式对比,性能大幅提升。
列存储索引主要在下面三个特性上提升查询的性能:
行存储使用逐行处理模式,每次只处理一行数据;而列存储索引使用批处理模式,每次处理一批数据行。
行存储是逐行存储(Row Store),每一个Page存储多行数据,而列存储(Column Store)把数据表中的每一列单独存储在Page集合中,这意味着,Page集合中存储的是某一列的数据,而不是一行中所有列的数据。在读取数据时,行存储把一行的所有列都加载到内存,即使有些列根本不会用到;而列存储只把需要的列加载到内存中,不需要的列不会被加载到内存中。
列存储索引自动对数据进行压缩处理,由于同一行的数据具有很高的相似性,压缩率很高,数据读取更快速。
一般情况下,数据仓库的查询语句只会查询少数几个列的数据,其他列的数据不需要加载到内存中,这就使得列存储特别适合用于数据仓库中。
01、列存储的特点
为什么列存储能够大幅度提高数据的查询性能呢?要回答这个问题,首先必须明白SQL Server引擎是怎样读取数据的。在读取数据时,SQL Server每次都把所需数据所在的整个Page读取到内存中,Page是数据读取的最小单位。如果采用行存储,每一个Page都存储所有列的数据,每行的Size决定了单个Page能够存储的数据行数量。
我们可以粗略计算一下,如果一个数据行有10列,每列的平均Size是10B,一行的Size是100B,那么单个Page最多存储80行(8060B/100B);如果采用列存储模式,那么单个Page可以存储806行(8060B/10B)。就单个Page存储的数据行数量而言,列存储是行存储的10倍,SQL Server引擎把一个Page读取到内存中,能够获取的数据行数量成10倍增加。
因此,采用列存储模式时,每一个Page能够存储更多的数据行。在加载列存储数据时,SQL Server只需要消耗少量的IO,就能把某一列的全部数据加载到缓存中。当从列很多的大表中读取几个列时,相比传统的行存储(Row Store)模式,列存储(Column Store)能够成千上万倍地提高数据的读取速度和查询性能。
基于 Spring Boot + MyBatis Plus + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
项目地址:https://github.com/YunaiV/ruoyi-vue-pro
视频教程:https://doc.iocoder.cn/video/
02、列存储的物理实现
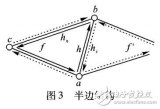
数据表(堆,B-Tree)以行存储模式存储数据,而列存储索引以列存储模式存储数据,行存储和列存储的示例图:
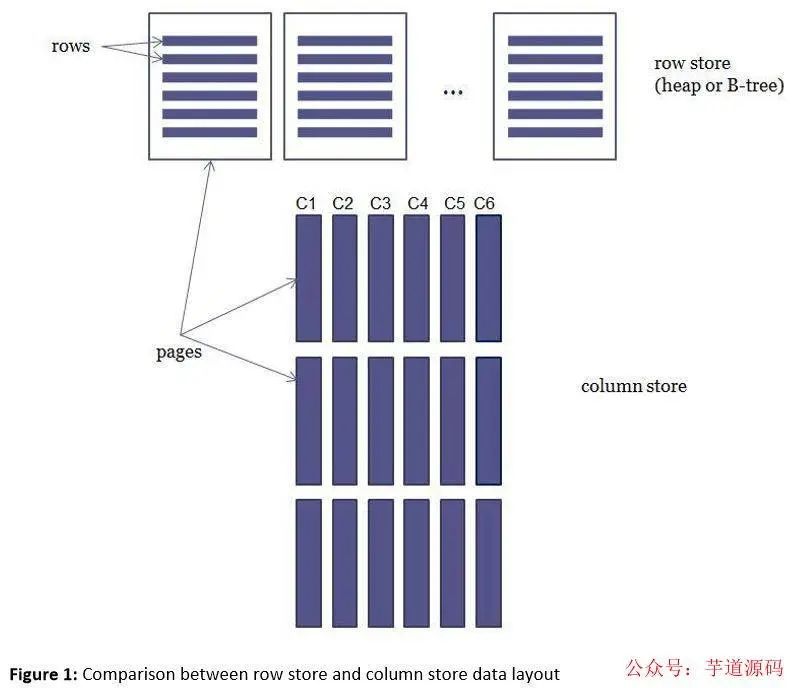
1,列存储的优点
对于列存储,列C1…C6 存储在不同的Page组中,列存储的有点是:
列存储是把每一列都单独存储在Pages集合中,对于行存储,哪怕只从数据表中选择(select)一列,SQL Server引擎都把整个数据行所在的Page读取到内存中,而使用列存储索引,仅仅需要把select子句指定的列读取到内存,不需要的列不会被读取;因此,如果一个查询请求只需要从少量的几个列中获得数据,列存储能够大幅度提高查询性能;
由于单个数据列的数据冗余度更高,因此同一列的数据更容易被压缩存储,单个Page存储更多的数据;
缓存命中率提高,这是因为同一列的数据被高度压缩,常用的Page被频繁访问而变得异常活跃,Buffer Manager把活跃的数据页缓存到内存中,不常用的Page被换出(Page Out)。
更高级的查询执行技术,列存储模式读取数据使用的是批处理模式(Batch Processing Mode),相对于传统的行处理技术,查询性能更高。
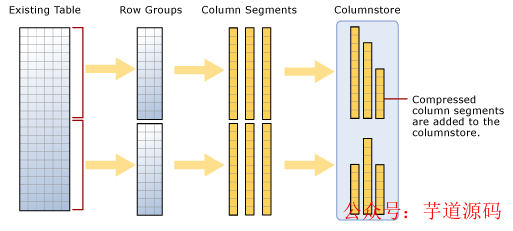
2,列存储模式的物理实现
SQL Server引擎分三步实现列存储:
step1,列存储索引先把数据表的所有数据行分组,每个分组也称作行组(Row Groups)。
step2,在每个行组中,每列的所有数据行构成一个列段(Column Segment),简称段。
step3,对每个段进行压缩处理和编码,每个段都单独存储在列存储索引中。
3,编码和压缩
列存储使用两种编码类型:基于字典(dictionary based)和基于值(value based),使用Vertipaq压缩数据。
字典编码是把唯一值编入字典,每一个唯一值都匹配一个序号,而序号用于索引字典,通过存储序号来压缩数据。如果数据表中存在大量的重复值,那么使用字典编码压缩率高。
值编码用于整数类型,或小数类型,编码的原理是把Value的范围按照比例缩小或增大,并使用一个指数(exponent)来表示比例。如果整数(integer) 或小数(decimal)的值分布集中,那么使用基于值(value-based)编码方法进行压缩非常高效。
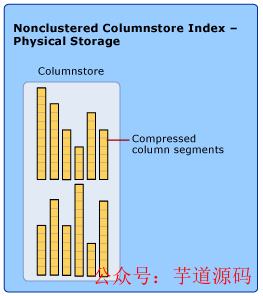
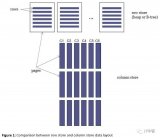
列存储索引的物理存储如下图所示:
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
项目地址:https://github.com/YunaiV/yudao-cloud
视频教程:https://doc.iocoder.cn/video/
03、列存储索引
SQL Server 2012开始引入列存储模式,用户通过创建列存储索引(Column Store Index)来体验列存储模式带来的性能提升。而列存储模式非常适用于星型连接(Star- Join)类型的聚合查询,所谓星型连接(Star-Join)的聚合查询是指对一个大表(Large Table)和多个小表(Little Table)进行连接,并对Large Table 进行聚合查询。在数据库仓库中,是指事实表和维度表的连接。
在大表上创建列存储索引,SQL Server 引擎将充分使用批处理模式(Batch processing mode)来执行星型查询,获取更高的查询性能。
典型的Star- Join的聚合查询类似于下面的示例脚本:
selectlt.Grouping_Columns, AggregationFunction(bt.Columns) fromdbo.LittleTableltwith(nolock) innerjoindbo.BitTablebtwith(nolock) onlt.Int_Col1=bt.Int_col1 where.... groupbylt.Grouping_Columns
在SQL Server 2012中,只能创建非聚集的列存储索引,由于列存储索引的每一列都有独立的存储空间(Page Set),因此,列存储索引会包含数据表的所有列,这样,每一个数据列都会被索引到。但是,并不是每一列都能获得的相同的性能提升,这是因为,列存储使用的压缩算法对于具有大量重复值的字符或数值的数据,压缩效率更高。对于列存储索引而言,查询性能的提升很大程度上依赖列数据的高度压缩,这会大幅减少存储该列数据所占用的数据页(Data Page),进而大幅减少把数据加载到内存所耗费的内存和时间。
CREATE[NONCLUSTERED]COLUMNSTOREINDEXindex_name
ONschema_name.table_name(column[,...n])
[WITH(DROP_EXISTING={ON|OFF}|MAXDOP=max_degree_of_parallelism)]
[ONpartition_scheme_name(column_name)|filegroup_name]
一旦表上创建了非聚集的列存储索引,基础表就变成只读的(read-only),不能对基础表做任何更新(insert,update,delete 或merge)操作,如果需要修改数据,那么,首先要禁用列存储索引,然后更新数据,最后重建列存储索引:
ALTERINDEXmycolumnstoreindexONmytableDISABLE; --updatemytable-- ALTERINDEXmycolumnstoreindexonmytableREBUILD
由于创建或重建列存储索引是IO密集型资源,十分耗费内存资源,因此必须在系统空闲的情况下,更新数据。
04、列存储索引的空间使用
列存储索引首先把数据分组,然后每个行组中的每个列构成一个段(Segment),每段都是单独存储的,列存储索引占用的存储空间的大小是由所有段占用的硬盘空间的加和。
系统视图:sys.column_store_segments 提供每个段的数据信息,每个段都是每个行组中的一列的数据的集合,例如,如果一个列存储索引分为10个行组,每个行组有15个数据列,那么,该视图将返回150个段。
selecti.object_id ,object_name(i.object_id)asobject_name ,i.nameasindex_name ,i.type_descasindex_type ,col_name(i.object_id,ic.column_id)asindex_column_name ,sum(s.row_count)asrow_count ,sum(s.on_disk_size)/1024/1024ason_disk_size_mb fromsys.column_store_segmentss innerjoinsys.partitionsp ons.partition_id=p.partition_id innerjoinsys.indexesi onp.object_id=i.object_id andp.index_id=i.index_id innerjoinsys.index_columnsic oni.object_id=ic.object_id andi.index_id=ic.index_id ands.column_id=ic.index_column_id groupbyi.object_id ,i.index_id ,i.name ,i.type_desc ,ic.column_id orderbyi.object_id ,i.name ,index_column_name
可以看出,列存储索引中每个段占用的硬盘空间是很少的,加载到内存所需要耗费的时间,IO次数和内存资源也是很少的,再配上性能更高的批处理模式,所以,列存储能够大幅度提高数据的查询性能,特别是对星型聚合的查询。
责任编辑:彭菁
-
数据
+关注
关注
8文章
7002浏览量
88937 -
存储
+关注
关注
13文章
4296浏览量
85796 -
内存
+关注
关注
8文章
3019浏览量
74000
原文标题:为什么列存储能够大幅度提高数据的查询性能?
文章出处:【微信号:芋道源码,微信公众号:芋道源码】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
rtthread编译后如何查看堆栈空间使用情况?
6678中CACHE的空间使用问题
用的28035.对ram空间使用的大小有影响吗?
基于轨道约束的空间目标球面网络索引构建方法
一种新的面向列存储的压缩方法
基于多维动态空间索引的显式曲面拓扑重建算法






 工商网监
工商网监
评论