 下载量超300w的ChatGLM-6B再升级:8-32k上下文,推理提速42%
下载量超300w的ChatGLM-6B再升级:8-32k上下文,推理提速42%
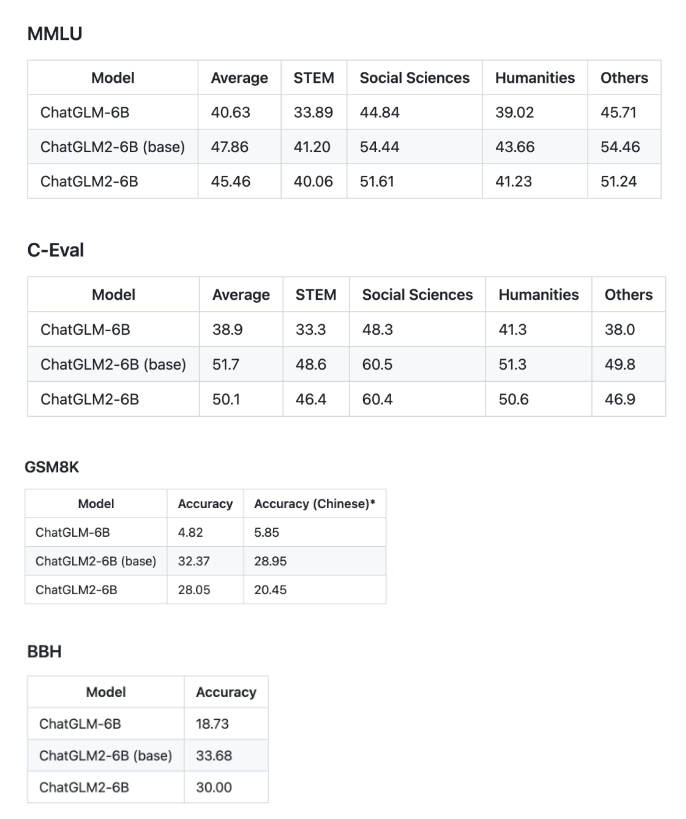
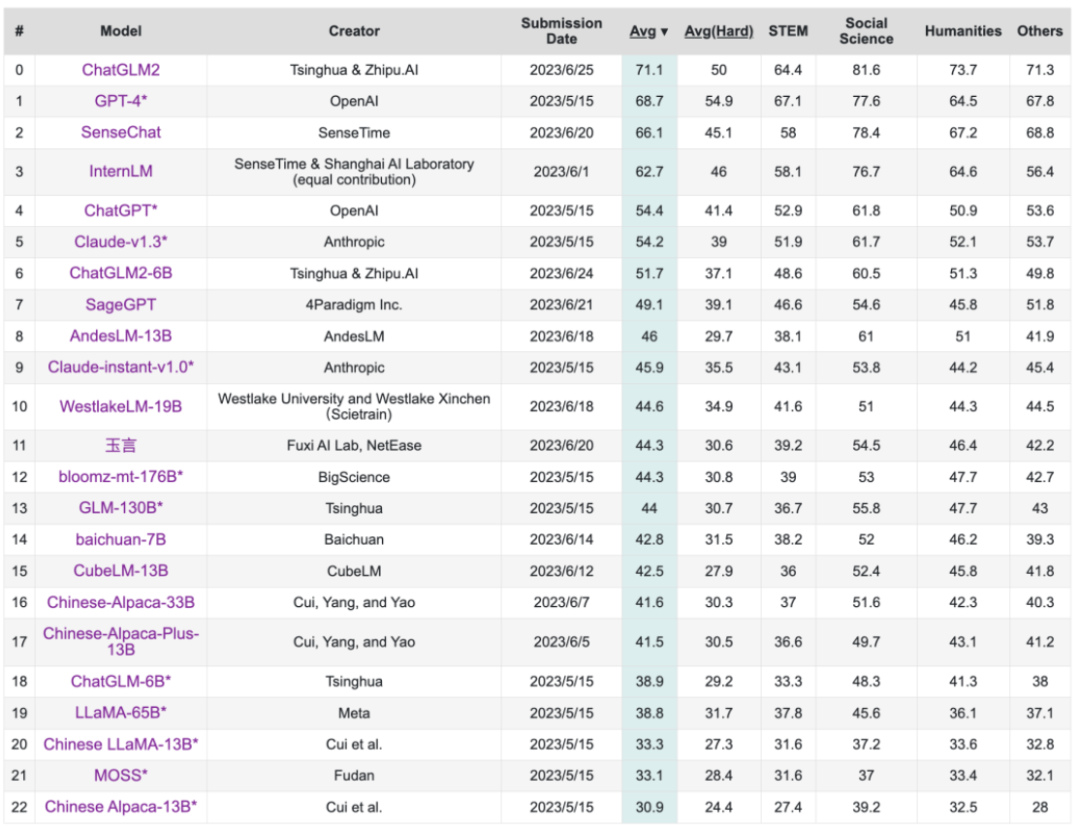
GLM 技术团队宣布再次升级 ChatGLM-6B,发布 ChatGLM2-6B。ChatGLM-6B 于 3 月 14 日发布,截至 6 月 24 日在 Huggingface 上的下载量已经超过 300w。 截至 6 月 25 日,ChatGLM2 模型在主要评估 LLM 模型中文能力的 C-Eval 榜单中以 71.1 的分数位居 Rank 0;ChatGLM2-6B 模型则以 51.7 的分数位居 Rank 6,是榜单上排名最高的开源模型。
ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性:
更强大的性能:基于 ChatGLM 初代模型的开发经验,全面升级了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 GLM 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,评测结果显示,相比于初代模型,ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
更长的上下文:基于 FlashAttention 技术,项目团队将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。但当前版本的 ChatGLM2-6B 对单轮超长文档的理解能力有限,我们会在后续迭代升级中着重进行优化。
更高效的推理:基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
更开放的协议:ChatGLM2-6B 权重对学术研究完全开放,在获得官方的书面许可后,亦允许商业使用。
评测结果
以下为 ChatGLM2-6B 模型在 MMLU (英文)、C-Eval(中文)、GSM8K(数学)、BBH(英文) 上的测评结果。
推理性能
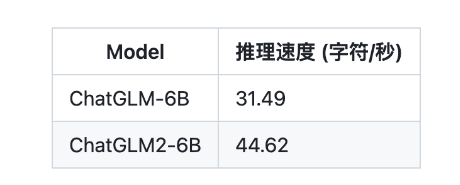
ChatGLM2-6B 使用了 Multi-Query Attention,提高了生成速度。生成 2000 个字符的平均速度对比如下
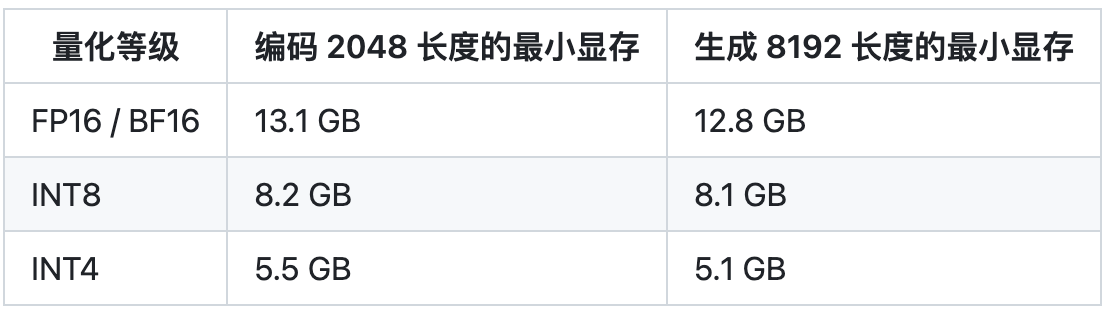
Multi-Query Attention 同时也降低了生成过程中 KV Cache 的显存占用,此外,ChatGLM2-6B 采用 Causal Mask 进行对话训练,连续对话时可复用前面轮次的 KV Cache,进一步优化了显存占用。因此,使用 6GB 显存的显卡进行 INT4 量化的推理时,初代的 ChatGLM-6B 模型最多能够生成 1119 个字符就会提示显存耗尽,而 ChatGLM2-6B 能够生成至少 8192 个字符。
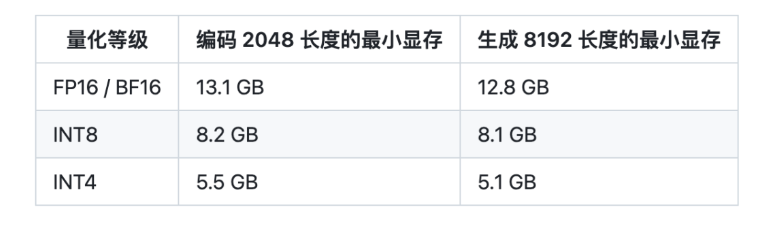
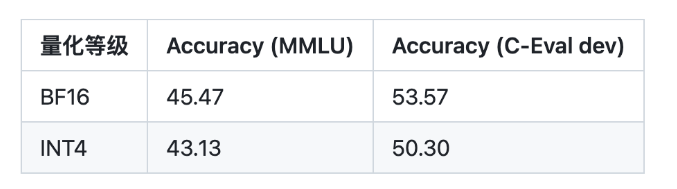
项目团队也测试了量化对模型性能的影响。结果表明,量化对模型性能的影响在可接受范围内。
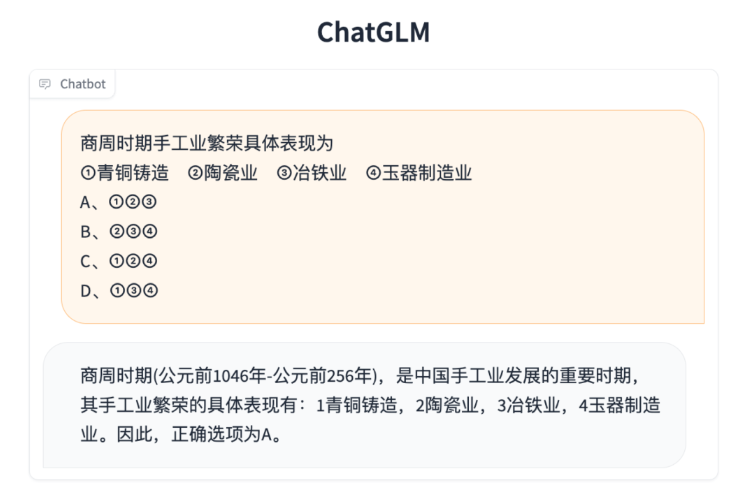
示例对比
相比于初代模型,ChatGLM2-6B 多个维度的能力都取得了提升,以下是一些对比示例。 数理逻辑


知识推理

长文档理解


-
开源
+关注
关注
3文章
3309浏览量
42470 -
模型
+关注
关注
1文章
3226浏览量
48806 -
数据集
+关注
关注
4文章
1208浏览量
24688
原文标题:下载量超300w的ChatGLM-6B再升级:8-32k上下文,推理提速42%
文章出处:【微信号:OSC开源社区,微信公众号:OSC开源社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
UCC28063EVM-723 300W交错式PFC预调节器手册

UCC28060EVM 300W交错式PFC预调节器手册
SystemView上下文统计窗口识别阻塞原因
chatglm2-6b在P40上做LORA微调
大联大推出基于Innoscience产品的300W电源适配器方案

鸿蒙Ability Kit(程序框架服务)【应用上下文Context】
PMP31052.1-汽车类四开关、大于 300W 降压/升压 PCB layout 设计
编写一个任务调度程序,在上下文切换后遇到了一些问题求解
STM32L4R5VGT6 flash超512K时,无法下载的原因?
TC397收到EVAL_6EDL7141_TRAP_1SH 3上下文管理EVAL_6EDL7141_TRAP_1SH错误怎么解决?
ISR的上下文保存和恢复是如何完成的?
三步完成在英特尔独立显卡上量化和部署ChatGLM3-6B模型
ChatGLM3-6B在CPU上的INT4量化和部署





 工商网监
工商网监
评论