 联合学习使得跨企业管理复杂的人工智能工作流更加容易
联合学习使得跨企业管理复杂的人工智能工作流更加容易
在工作流程中利用人工智能的企业面临的主要挑战之一是管理支持大规模培训和部署机器学习( ML )模型所需的基础设施。为此,NVIDIA FLARE平台提供了一个解决方案:联合学习,使得跨企业管理复杂的人工智能工作流变得更加容易。
NVIDIA FLARE 2.3.0 是 NVIDIA 联合学习平台的最新版本,其中包含了令人兴奋的新功能和增强功能,如:
使用基础设施作为代码的多云支持( IaC )
自然语言处理( NLP )示例,包括 BERT 和 GPT-2
用于分离数据和标签的拆分学习
这篇文章详细介绍了这些功能,并探讨了它们如何帮助您的组织提升人工智能工作流程,并通过机器学习获得更好的结果。
多云部署
有了这个版本,您现在可以使用 IaC 无缝管理您的多云基础设施,利用不同云提供商的优势,并分配您的工作负载以提高效率和可靠性。 IaC 使您能够自动化基础设施的管理和部署,从而节省时间并降低人为错误的风险。 NVIDIA FLARE 2.3.0 支持在 Microsoft Azure 和 AWS 云上进行自动部署。
要在云中部署 NVIDIA FLARE,请使用 NVIDIA FLARE CLI 命令创建基础结构、部署和启动 Dashboard UI、FL Server 和 FL Client。要在云中创建和部署 NVIDIA FLARE,请按照NVIDIA FLARE 启动套件,由 NVIDIA FLARE 资源调配过程生成并分发给服务器和客户端的签名软件包。
/start.sh --cloud azure | aws /start.sh --cloud azure | aws nvflare dashboard --cloud azure | aws
这些命令将创建资源组、网络、安全、计算运行时实例等(作为代码的基础结构),并将 NVIDIA FLARE 客户端或服务器部署到新创建的虚拟机( VM )。每个启动工具包都包含可独立部署的 FLARE 服务器或客户端的唯一配置。这让用户可以灵活地在 prem 或混合云服务提供商(例如 AWS 上的服务器以及 Azure 和/或 AWS 上的客户端)上进行部署,以实现简单的混合多云配置。
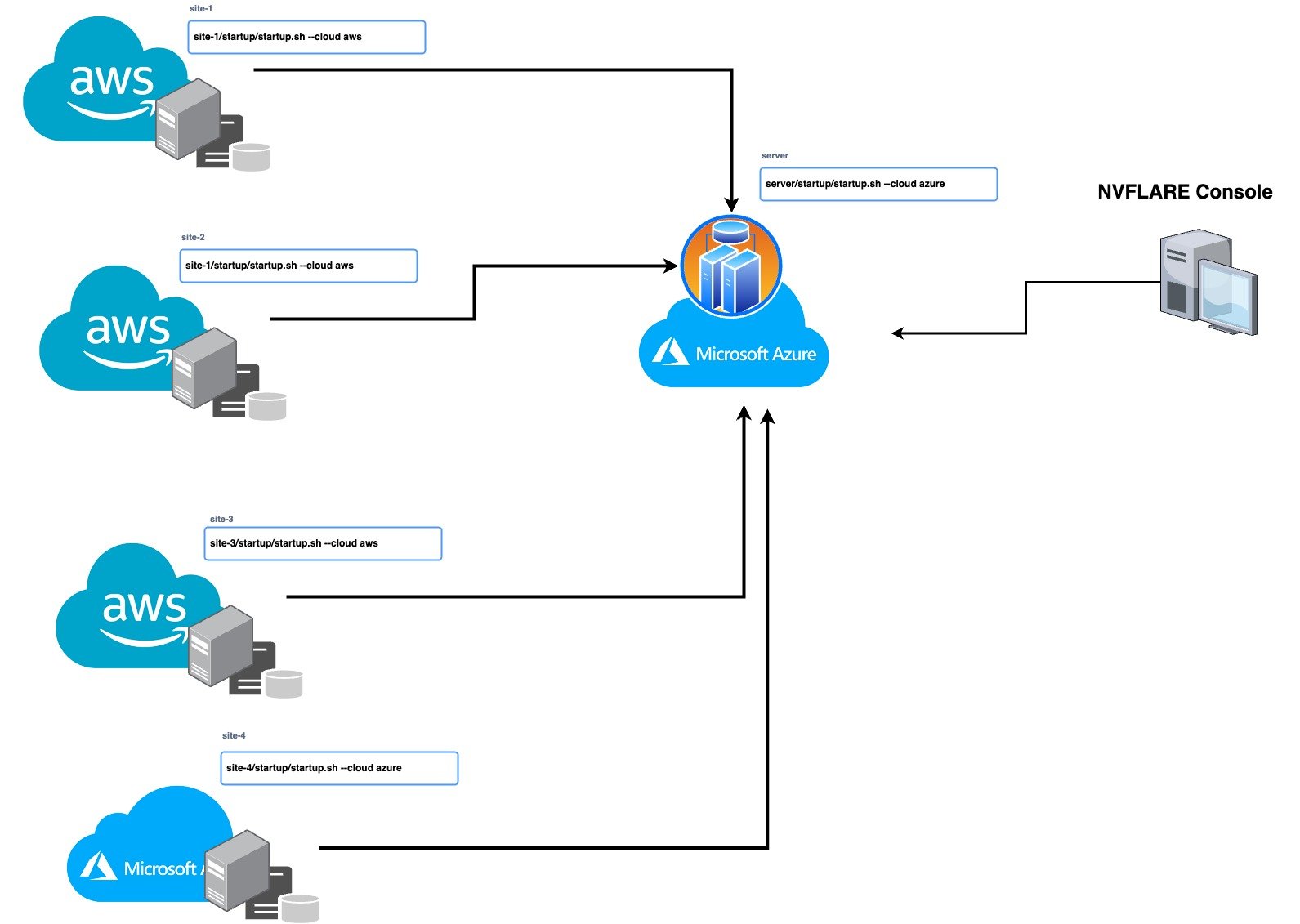 图 1 。用于设置多云部署的 NVIDIA FLARE 单行 CLI 命令
图 1 。用于设置多云部署的 NVIDIA FLARE 单行 CLI 命令
LLM 和联合学习
Large language models(LLM)正在开启多个行业的新可能性,比如医疗保健中的药物发现。要了解更多详情,请参见NVIDIA BioNeMo Service 建立生成式 AI 管道以进行药物发现。
在 LLM 培训中利用联合学习有许多好处,包括:
保护数据隐私:模型可以在数据不离开前提的情况下进行训练。即使在同一个组织中,数据位于世界不同地区的不同部门,这一点也可能很重要。例如,考虑到不同的国家隐私法,可能不可能将存储在欧洲和中国的数据复制到一个集中的数据湖中。
避免数据移动:即使不关心隐私,将大量数据从一个位置复制到另一个位置也需要时间和金钱。
利用数据多样性:当不同的站点具有不同类型的数据时,通过联合学习训练模型可以利用这种数据多样性来改进全局模型。
实现任务多样性:具有各种任务的培训模式可以促进模型性能。这也可以通过联合学习来实现。
计算成本分布:培训 LLM 需要大量资源,而且成本可能很高。要找到一个拥有足够计算资源的机构来完成这项任务是很有挑战性的。通过联合学习,可以利用来自多个位置的计算资源来训练所有参与者共享的模型。
训练并行性:联合学习通过横向数据拆分和将模型的不同层拆分到不同位置,实现了模型训练的数据和模型并行性。
为了说明这些功能,NVIDIA FLARE 2.3.0 引入了带有 GPT-2(Generative Pretrained transformer 2)和 BERT(Bidirectional Encoder Representations from transformers)模型的 NLP 命名实体识别(NER)示例。要了解更多详情,请访问 GitHub 上的 NVIDIA/NVFlare。参数高效调优和相关工作正在进行中,为未来的版本提供更多 LLM 模型示例。
联邦 NLP
NVIDIA FLARE 能够支持具有不同主干模型的各种 NLP 任务,例如 NER 、文本分类和语言生成。
本次发布的重点是使用 NCBI 疾病数据集进行命名实体识别(NER)应用,该数据集包含生物医学研究论文的摘要,并附有疾病提及,通常用于生物医学领域的 NER 模型的基准测试。更多详情,请参阅NCBI 疾病语料库:疾病名称识别和概念归一化的资源。
NER 的任务包括识别文本中的命名实体,并将其分类到预定义的类别中。在 NCBI 疾病数据集的情况下,目标是识别和捕获疾病提及。
为了解决 NER 任务, NVIDIA FLARE 示例探讨了两种流行型号 BERT 和 GPT-2 的使用。 BERT 是一种基于预训练 transformer 的模型,广泛用于各种 NLP 任务,包括 NER 。 GPT-2 是另一个基于 transformer 的模型,主要用于语言生成,但也可以针对 NER 进行微调。
BERT 基本无上限模型和 GPT-2 模型分别有 1 . 1 亿个和 1 . 24 亿个参数。模型中参数的数量是其大小和复杂性的指示。具有更多参数的较大模型往往会学习数据中更复杂的关系。然而,与较小的模型相比,它们也需要更多的计算资源和更长的训练时间。
即将发布的版本将包括对更大的十亿参数模型和其他任务的支持。
拆分学习
Split learning是一种技术,可以让多方在各自的数据集上协作训练机器学习模型,而无需相互共享原始数据。该模型分为两个或多个部分,每个部分都可以在其中一个参与方上运行。
与传统的 ML 方法相比,这种方法有几个优点,尤其是在数据隐私是主要问题的情况下。与联合学习一样,分离学习从不在各方之间共享原始数据。这意味着敏感信息可以保密,同时使各方能够获得见解并从合作中受益。
NVIDIA FLARE 2.3.0 版本演示了一个分布式学习的示例,其中数据和标签可以分别存放在两个不同的站点上。通过将模型的一部分放在一个站点上,并向另一个站点发送激活/嵌入以计算损失,可以实现数据和模型的保护。您可以在 CIFAR10 分割学习示例 中查看这项技术。
开始使用 NVIDIA FLARE 2 . 3 . 0
NVIDIA FLARE 2.3.0 可以帮助您快速部署到多云环境中,探索 LLM 的 NLP 示例,并展示拆分学习功能。通过将这些功能融入工作流程,可以节省时间、提高准确性、降低风险,从而促进人工智能工作流程的实施。
-
NVIDIA
+关注
关注
14文章
4978浏览量
102987 -
人工智能
+关注
关注
1791文章
47183浏览量
238247
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论