 PVT++:通用的端对端预测性目标跟踪框架
PVT++:通用的端对端预测性目标跟踪框架
本文提出通用的端对端预测性跟踪框架PVT++,旨在解决目标跟踪的部署时的延迟问题。多种预训练跟踪器在PVT++框架下训练后“在线”跟踪效果大幅提高,某些情况下甚至取得了与“离线”设定相当的效果。

PVT++ 论文:https://arxiv.org/abs/2211.11629 代码:https://github.com/Jaraxxus-Me/PVT_pp
引言
单目标跟踪(SOT)是计算机视觉领域研究已久的问题。给定视频第一帧目标的初始位置与尺度,目标跟踪算法需要在后续的每一帧确定初始目标的位置与尺度。将这类视觉方法部署在机器人上可以实现监测、跟随、自定位以及避障等智能应用。大多数目标跟踪算法的研究与评估都基于“离线”假设,具体而言,算法按照(离线)视频的帧号逐帧处理,得出的结果与对应帧相比以进行准确率/成功率计算。
然而,这一假设在机器人部署中通常是难以满足的,因为算法本身的延迟在机器人硬件上不可忽视,当算法完成当前帧时,世界已经发生了变化,导致跟踪器输出的结果与实际世界的目标当前状态不匹配。换言之,如图二(a) 所示,由于算法的延迟总存在(即使算法达到实时帧率),输出的结果“过时”是不可避免的。
这一思想起源于ECCV2020 “Towards Streaming Perception”。
由于机载算力受限,平台/相机运动剧烈,我们发现这一问题在无人机跟踪中尤为严重,如图一所示,相比“离线”评估,考虑算法延迟的“在线”评估可能使得其表现大幅下降。
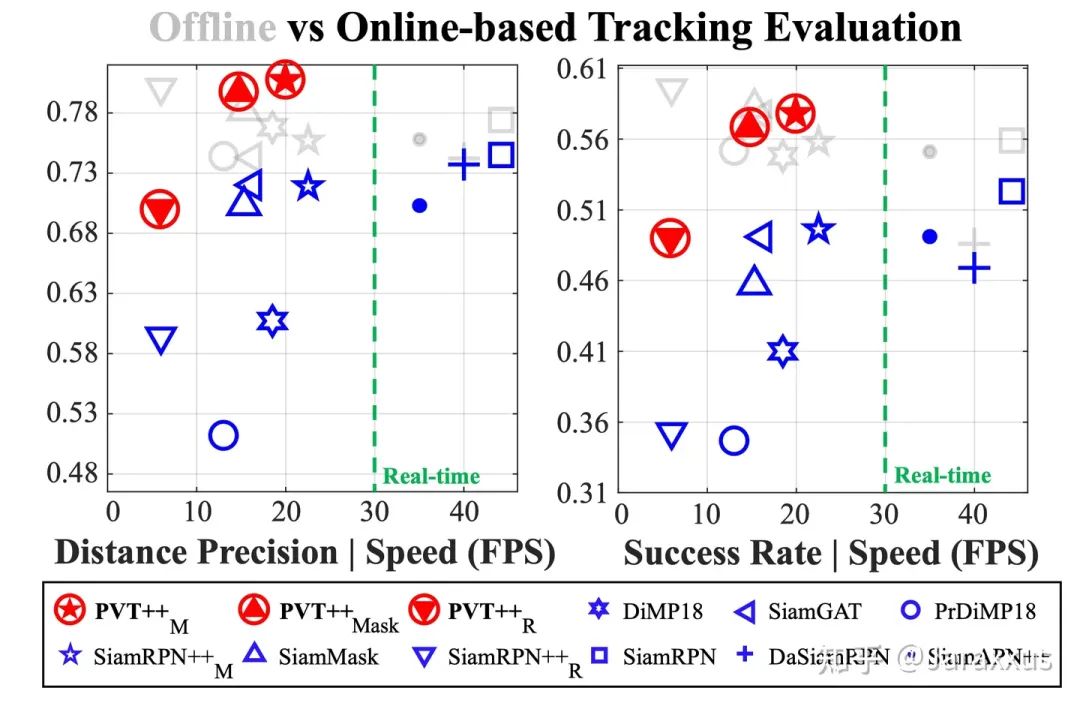
图一. “离线”评估与“在线”评估中各个跟踪器的表现以及PVT++在“在线”跟踪中的效果。灰色图标代表离线评估,蓝色图标代表相同方法在线评估,红色图标代表相同方法使用PVT++转换为预测性跟踪器。
如图二(b)所示,为解决这一问题,预测性跟踪器需要提前预测世界未来的状态,以弥补算法延迟导致的滞后性。
这一理论详见ECCV2020 “Towards Streaming Perception”以及我们过往的工作“Predictive Visual Tracking (PVT)"。
而与以往的在跟踪器后使用卡尔曼滤波的方法不同,在本文中,我们从跟踪器能提供的视觉特征出发,研发了端对端的预测性目标跟踪框架(PVT++)。我们的PVT++有效利用了预训练跟踪器可提供的视觉特征并可从数据中学习目标运动的规律,进而做出更准确的运动预测。
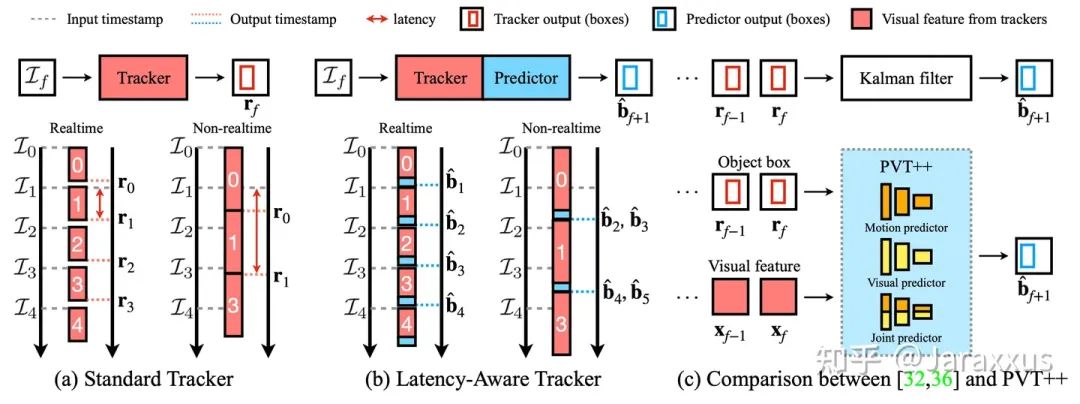
图二. (a) 常规的跟踪器有延迟,所以结果总是滞后的。(b) 预测性跟踪提前预测世界的状态,弥补延迟带来的滞后性。(c) 与基于卡尔曼滤波的方法不同,我们的PVT++有效利用了跟踪器自带的视觉特征并可从数据中学习运动的规律,进而做出更准确的预测。
PVT++是一个通用的可学习框架,能适用不同类型的跟踪器,如图一所示,在某些场景下,使用PVT++后甚至能取得与“离线”评估相当的“在线”结果。
贡献
我们研发了端对端的预测性目标跟踪框架PVT++,该通用框架适用于不同类型的跟踪器并能普遍带来大幅效果提升。
为实现“从数据中发现目标运动的规律”,我们提出了相对运动因子,有效解决了PVT++的泛化问题。
为引入跟踪器已有的视觉特征实现稳定预测,我们设计了辅助分支 和 联合训练机制,不仅有效利用了跟踪器的视觉知识而且节省了计算资源。
除了PVT++方法,我们还提出了能够进一步量化跟踪器性能的的 新型评估指标 e-LAE,该指标不仅实现了考虑延迟的评估,而且可以区分实时的跟踪器。
方法介绍
为了将整个问题用严谨的数学公式成体系地定义出来,我们花了很多时间反复打磨PVT++的方法部分叙述,然而不可避免符号偏多结构也比较复杂(被reviewer们多次吐槽...),读起来有些晦涩难懂容易lost,在此仅提供一些我intuitive的想法,以方便读者能够更快理解文章的核心思想。
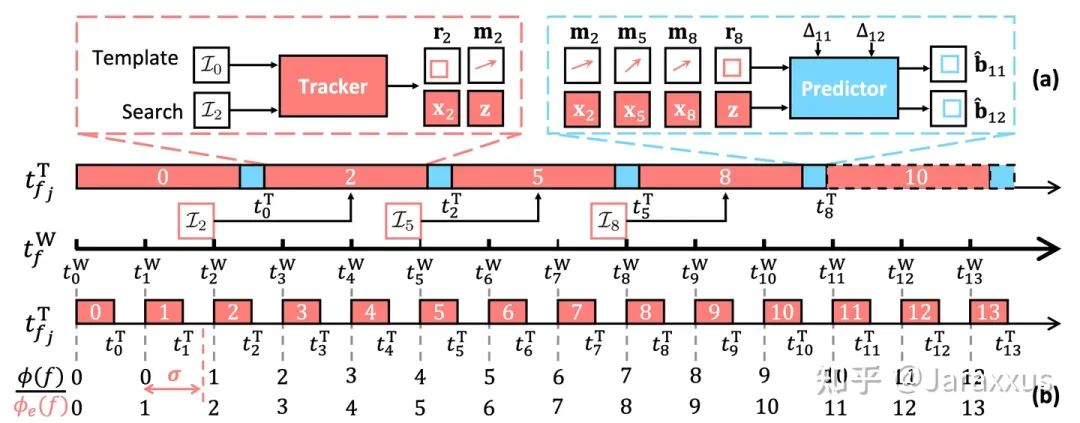
图三. (a) PVT++宏观框架与 (b) e-LAE评估指标
e-LAE评估指标
与“离线”设定不同,“在线”跟踪(LAE)依照算法实际部署的情况设计,具体而言,其遵循以下两条原则:

类似的评估方式最早被提出于ECCV2020 “Towards Streaming Perception”,在以前的研究PVT中,我们针对跟踪算法做了上述调整。
然而,这样的评估方式有一个缺陷,假设算法速度快于世界帧率(例如图三下方的算法时间戳),无论算法有多快,评估时的算法滞后永远是一帧。换言之,假设有两个精度一样的跟踪器A与B,A的速度>B>世界帧率,那么这样的评估指标得到的A,B的结果是一样的,这样以来,LAE便无法将实时跟踪器的速度纳入评估中,无法对实时跟踪器进行有效比较。

基于e-LAE,我们在机器人平台AGX Xavier上进行了众多跟踪器详尽的实验,涉及17个跟踪器,三个数据集,详见原文图五,e-LAE可以区分一些精度接近而速度有一些差距的实时跟踪器,如HiFT与SiamAPN++(原文Remark 2)。我们正在进一步检查所有结果,最终确认后也会将评估的原始结果开源。
PVT++
无论算法的速度有多快,其延迟总存在,故而我们设计了端对端预测性跟踪框架弥补延迟。如图三 (a) 所示,PVT++的结构非常直观简单,跟踪器模块即普通的已有的(基于深度学习的)跟踪算法,预测器接受跟踪器输出的历史运动m ,跟踪器的历史视觉特征x,y,以及预设的落后帧数Δ作为输入,输出未来帧的目标位置。
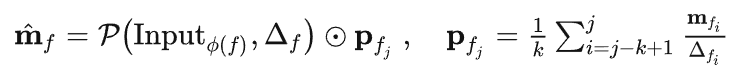
PVT++的结构看上去虽然简单直观,但使用离线数据训练这一套框架使之协助在线无人机跟踪并非易事,其独道之处在于以下三点:
相对运动因子:我们发现训练PVT++会遇到一个核心问题,训练集与测试集的域差距。试想,如果用于训练PVT++的数据来自VID,LaSOT,GOT10k这些目标运动尺度较小,方向速度较规律的数据集,PVT++自然会尝试拟合这些运动规律而难以泛化到目标运动更复杂,尺度更大的无人机跟踪场景。为了解决这一问题,我们将PVT++的训练目标改为学习/拟合特殊设计的相对运动因子,即原文公式(4):
这里pfj可以简单理解为过去几帧的平均速度,在左侧的公式中,我们可以先假设目标是匀速运动的,即未来帧的相对位置变化正比于未来帧的时间间隔和平均速度,此后我们的神经网络只需要在这一假设上做出调整即为未来的真实运动。这一设计也就使得预测器需要学习的东西是“相对于匀速运动假设的偏差值”,即相对运动因子,而非绝对的运动值。我们发现这一预测目标在大多数时候与目标的绝对运动是无关的,故而训练出的网络也就不易拟合训练集中的绝对运动,有着更好的泛化性。这一设计是PVT++能work的核心原因。预测器输出的相对运动会用于后续设计与真值的L1损失作为训练损失函数。
轻量化预测器结构:另一个问题是,预测器本身必须足够轻量才能避免预测模块引入额外的延迟,否则会导致整个系统失效。为此,我们设计了轻量有效的网络架构,包含encoder - interaction - decoder三部分,并能兼容运动轨迹信息与视觉特征,具体如图四,其中大多数网络层都可以有着非常小的通道数以实现极低的延迟(详见原文表3)。此外,我们预测器的设计也最大程度上复用了跟踪器能提供的视觉特征,因此节省了提取视觉特征所需要的计算资源。
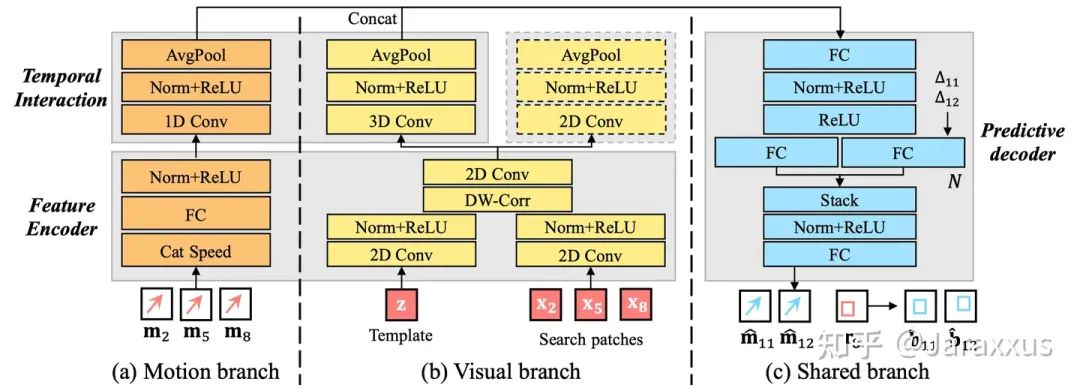
图四. PVT++中预测器的轻量化网络架构。
如何有效利用跟踪器已有的视觉特征:最后,为了使轻量的预测器做出稳健的预测,我们设计了一系列训练策略使得参数量很少的预测器有效利用(较大型)预训练跟踪器的能提供的鲁棒视觉表征。具体而言,我们发现以下两点设计尤为重要:
辅助分支:预测器的视觉分支(图四(b))需要当前的相对运动信息作为监督信号(图四的虚线框部分)才能用于预测未来的运动。详见原文5.3节。
联合训练:在训练PVT++时,跟踪器模块需要在早期的训练epoch中以较小的学习率联合预测器一起训练,进而使视觉特征既适用跟踪器做定位,又适合预测器做预测。详见附录B中的训练设定与我们的开源代码。
更多关于方法的细节介绍欢迎大家参考我们的原文(p.s.,我们的附录B提供了一个符号表辅助阅读...)
实验部分
全文的实验设计包括e-LAE的评估(原文图五)与PVT++的效果、分析两部分,在这里着重介绍PVT++有关的实验。
设置
为了公平比较基线跟踪器,PVT++采用与他们训练相同的LaSOT+GOT10k+VID作为训练集(均为视频)(实际上仅用VID也可以取得较好效果,详见附录L)。具体而言,我们直接加载了跟踪器原作者提供的模型参数作为我们的跟踪器模块,再使用离线数据训练PVT++。
评估时我们使用了四个无人机跟踪权威数据集DTB70,UAVDT,UAV20L以及UAV123,广泛验证了PVT++的泛化性。
整体效果
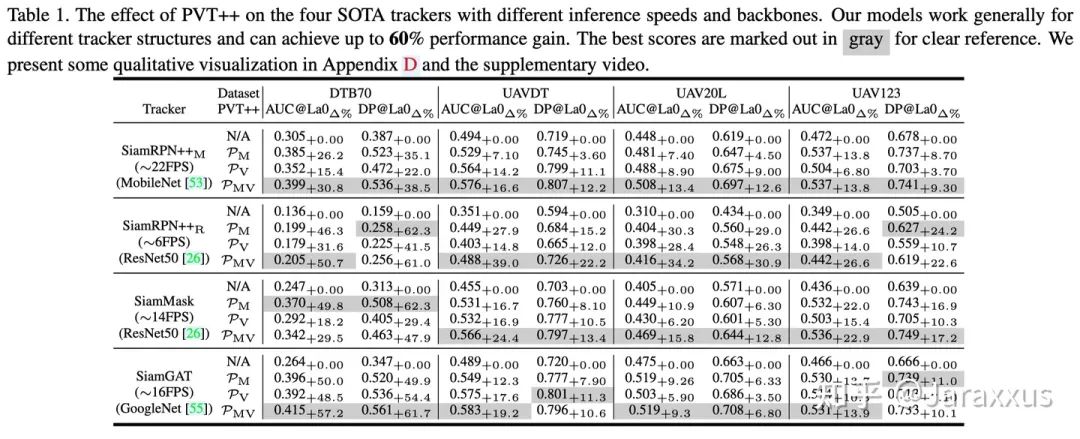
表一
PVT++的整体效果如表一所示,我们共将四个跟踪器转化为了预测性跟踪器,在四个无人机跟踪数据集中,PVT++能起到广泛而显著的效果。可以发现PVT++在某些场景下能达到超过60%的提升,甚至与跟踪器的离线效果相当。另外我们也发现并不是所有的情况下视觉信息都是有效可靠的,例如在DTB70中,仅用PVT++的motion分支也可以起到一定的效果。
消融实验
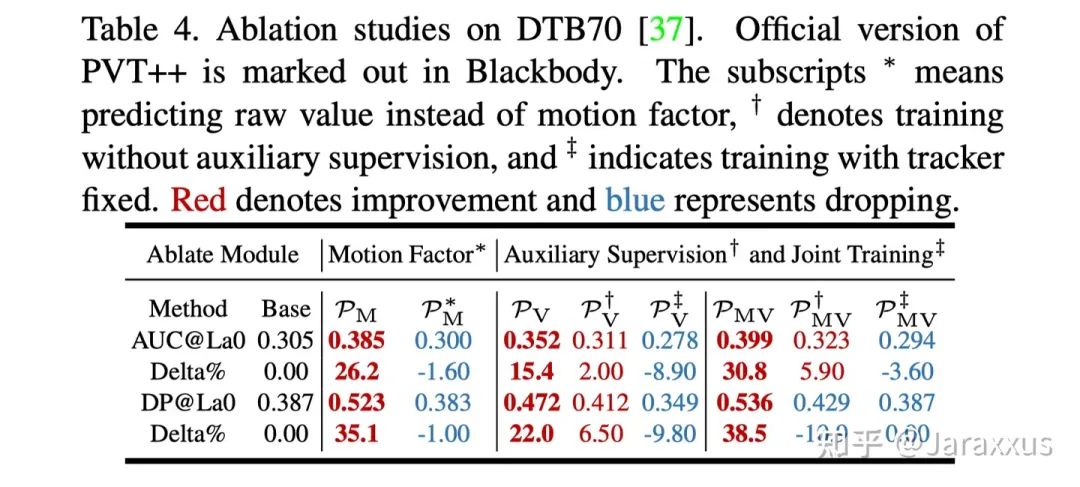
这里着重展示一下消融实验表四,如果不预测相对运动因子而是直接用绝对运动的值作为预测目标(和损失函数设计),预测器完全不work,甚至会引入负面影响。当引入视觉特征以后,辅助分支的监督和联合训练都是必要的,其中联合训练的重要性更大。
与其他方法对比
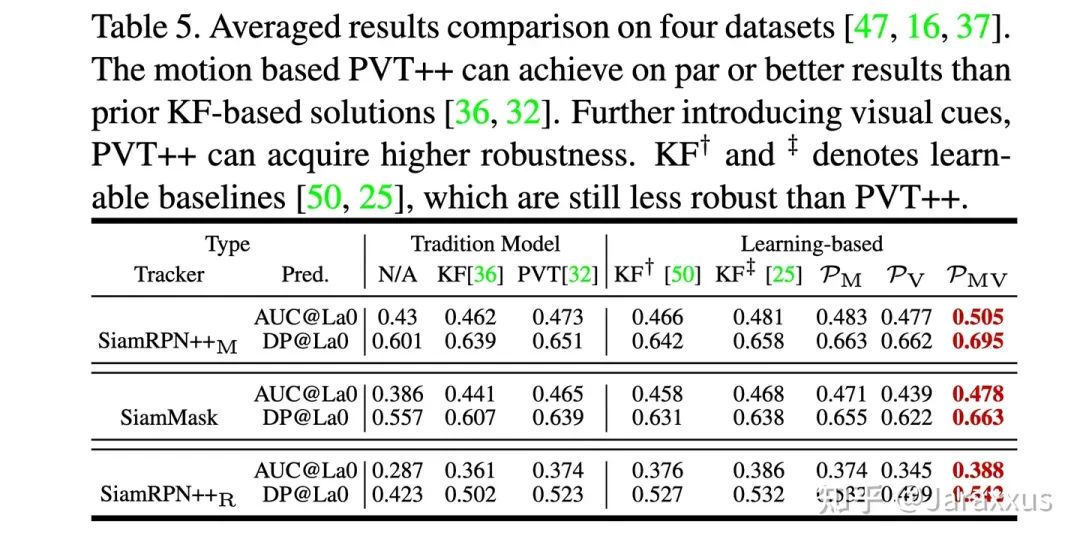
表五
如表五,我们尝试了直接在跟踪器后加入卡尔曼滤波(即沿用ECCV2020 “streaming”的思想)以及我们之前双滤波(PVT)的方案,并且在审稿人的建议下设计了可学习的基线方法(具体而言,我们将卡尔曼滤波中的噪声项作为可学习参数)。这些方法都没有利用跟踪器已有的视觉特征,所以综合效果差于联合了运动与视觉特征的PVT++。
可视化
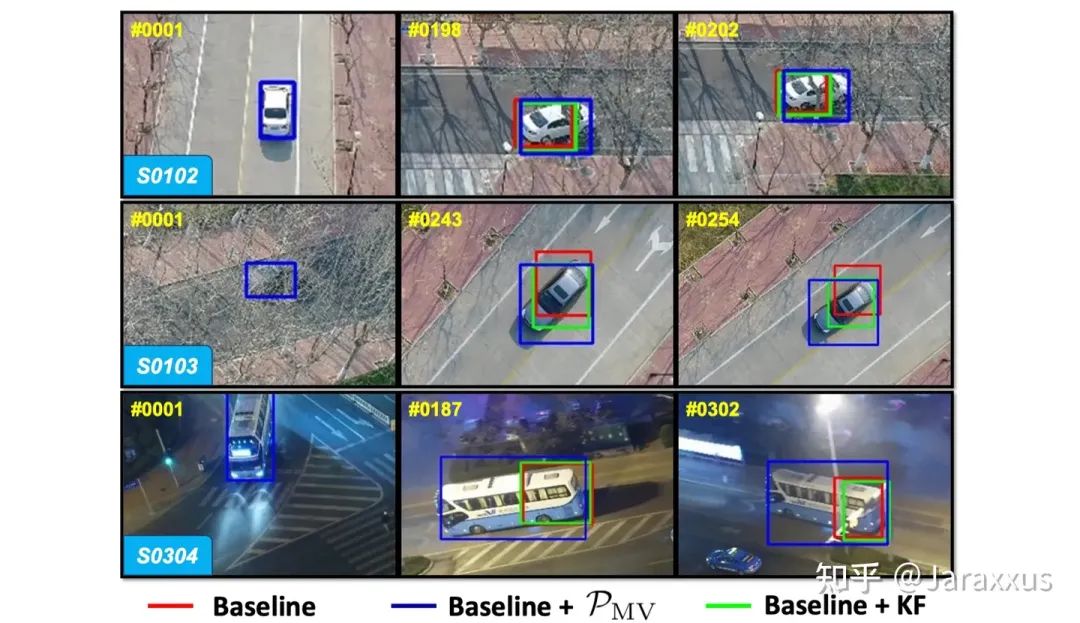
图五. PVT++与卡尔曼滤波的可视化对比
在图五中的三个序列中,我们发现卡尔曼滤波预测器很难处理目标平面内旋转以及无人机视角变化的情况,在这些挑战中,引入视觉信息进行目标尺度预测是尤为有效的。
另外本文也进行了更为详尽的实验,如属性分析、与其他运动预测方法(如NEXT)的对比、PVT++作用在最新的基于transformer的跟踪器等,欢迎大家参阅我们的附录。
局限性与讨论
PVT++的局限性在于两点:
预测器使用的视觉特征并不总是鲁棒,我们发现在DTB70这类目标运动速度很快导致图片模糊/目标出视野,但目标运动本身很规律的数据集中其实单靠运动分支就可以起到很好的效果。
训练策略有些复杂,特别是联合训练时跟踪器模块在早期epoch用较小学习率微调这一些细节我们尝试了很多次实验才发现。
e-LAE的局限性在于可复现性与平台依赖性:
由于这套在线评估系统与算法的实际延迟紧密相关,而延迟又与硬件平台的状态有关,我们发现甚至同一型号的硬件上的同一实验结果也会略有不同(就是说甚至同一台AGX放久了好像也会稍微慢一点....)。我们已经尝试在同一硬件上集中多次运行以尽可能降低硬件的不稳定性带来的影响并会将原始结果开源以方便大家复现结果。另外我们也提供了一个“vwin ”AGX硬件的脚本,可以将硬件上统计的延迟时间直接使用(而不是每次都一定要在机器人硬件上运行),详见我们的开源代码。
预测性“在线”目标跟踪依然是一个相当困难的研究问题,可能并不是增大数据量/模型参数量能轻易解决的,仍有着较大的提升空间。现在视觉领域正快速涌现一批批“奇观”,在线延迟也potentially有着其他的解决方案值得研究。譬如最近有一篇比较出圈的工作叫OmniMotion,我们能不能依赖点的correspondence,考虑从目标上每个point的运动规律出发,推理物体local到global的未来运动?这样也许能实现比PVT++更出彩的效果。
另外将算法延迟问题引入如今大火的一些foundation model研究中也是有意思的方向。譬如SAM和DINOv2的视觉特征是不是比ImageNet pre-train的ResNet更适合做视觉运动预测?如果是的话又该怎么处理这些超大规模预训练出的视觉特征?或许可以从TrackAnything入手研究。
致谢
PVT++是我本科期间的最后一项工作,算得上是本科的收官之作了,虽然看上去没有很fancy的cv概念,工程量也很大,但我个人非常喜欢,可能是我近三年实验上最扎实的工作了,当时发现相对运动因子和联合训练带来巨大的提升那种欣喜和意外是难以言喻的。该工作从第一次讨论(2022年初)到如今中稿已经是整整一年半,期间磕磕碰碰遇到了不少锐评,困难,与坎坷(差点就打算永远挂在arvix上了quqqq),附录甚至在多轮审稿中修修补补到了Appendix M(都快够一个正文了就是说><)。非常感谢在此期间合作的子渊,杰哥,一鸣大哥,三位老师,以及CMU的朋友们每次耐心的讨论修改与对我的鼓励支持。
本文初稿完成于2022年暑期,是我和子渊上半年在上海期智研究院与赵行老师合作的项目。MARS Lab是一个氛围很好的实验室,大家有着可靠的强大实力却又都温和而谦虚,可谓志同道合。我不久前回国在云锦路西岸也受了老师同学们很多照顾,讨论产生了不少idea,非常期待未来可能的合作交流。22年春季正值上海疫情严峻,非常感谢当时研究院的老师、同学们提供的帮助。我们主要受 ECCV2020 “Towards Streaming Perception” 启发,我们的代码基于目标跟踪知名开源库 pysot,在此向有关的作者、开发者们致以诚挚的谢意。
-
算法
+关注
关注
23文章
4607浏览量
92820 -
框架
+关注
关注
0文章
403浏览量
17474 -
目标跟踪
+关注
关注
2文章
88浏览量
14881
原文标题:ICCV 2023 | 涨点!PVT++:通用的端对端预测性目标跟踪框架
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
无线传感网多簇头协助的目标跟踪(二)
基于kalman预测和自适应模板的目标相关跟踪研究

基于KCFSE结合尺度预测的目标跟踪方法

机器人目标跟踪
采用带有transformer的端到端框架获取对应集合结果

DIMP:Learning Discriminative Model Prediction for Tracking 学习判别模型预测的跟踪
利用TRansformer进行端到端的目标检测及跟踪
PowerBEV的高效新型端到端框架基于流变形的后处理方法

理想汽车自动驾驶端到端模型实现

ZETA端智能✖红牛:助力国际饮料巨头实现生产设备预测性维护






 工商网监
工商网监
评论