 现代数据中心SmartNIC/DPU的演变过程
现代数据中心SmartNIC/DPU的演变过程
随着传统IDC向云数据中心转型,数据中心网络架构开始不断演进,三层架构正过渡到Spine - Leaf架构。为了更好地利用数据中心的 CPU 资源,公有云提供商采用了多租户模式。云平台需要为每个租户提供防火墙、IPsec-VPN、微分段、加解密等网络服务,以隔离和保护其流量免受威胁。
在某些数据中心中,专门的中央设备负责执行这些网络服务功能,数据包必须多次穿越数据中心网络,造成了一定的流量瓶颈。现代数据中心正在尝试将安全和网络功能放置到更靠近工作负载的位置,以获得更好的性能,这就是SmartNIC/DPU 出现的原因之一。
云数据中心架构
三层架构
许多传统数据中心采用三层架构,包括核心路由器、汇聚路由器和接入交换机。核心路由器通常是大型模块化路由器,具有非常高的带宽和高级路由功能。汇聚路由器是中间层路由器,具有更高的上行链路速度。服务器与接入交换机(也称为 TOR交换机)相连,如下所示。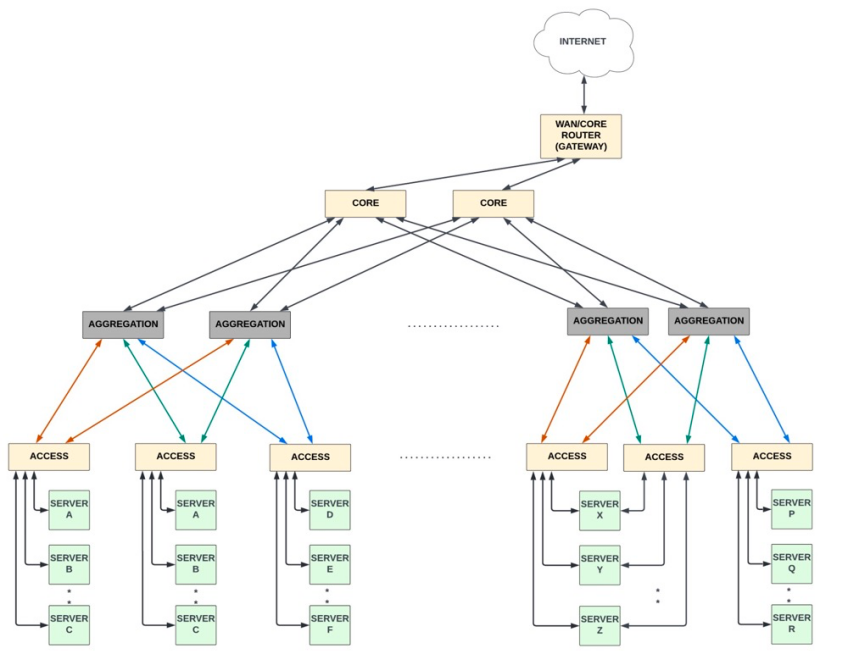
当大部分流量是南北向流量时,三层架构的工作效果很好:流量从数据中心外部进入,流经汇聚、接入交换机到服务器,然后再向北离开数据中心。大多数数据包每条路都会经过三个网络设备。
随着虚拟化技术的发展,单个服务器上可以承载多个虚拟机,再加上微服务的普及,东西向流量(服务器到服务器的通信)出现爆炸式增长。三层架构并不适合东西向流量的模式,服务器到服务器的通信必须经过两次访问、汇聚和/或核心设备(具体取决于目标服务器的位置),这导致延迟大大增加。此外,由于接入交换机仅与一小部分汇聚交换机通信,因此任何一个交换机的故障都会导致带宽的显着减少。
两层或Spine-Leaf架构
Spine-Leaf架构只有两层,每个Leaf设备连接到每个Spine设备。由于任意连接,这些设备需要高端口密度。这种架构在现代云数据中心中很受欢迎,因为密集的Spine-Leaf连接可以很好地支持东西向的流量模式。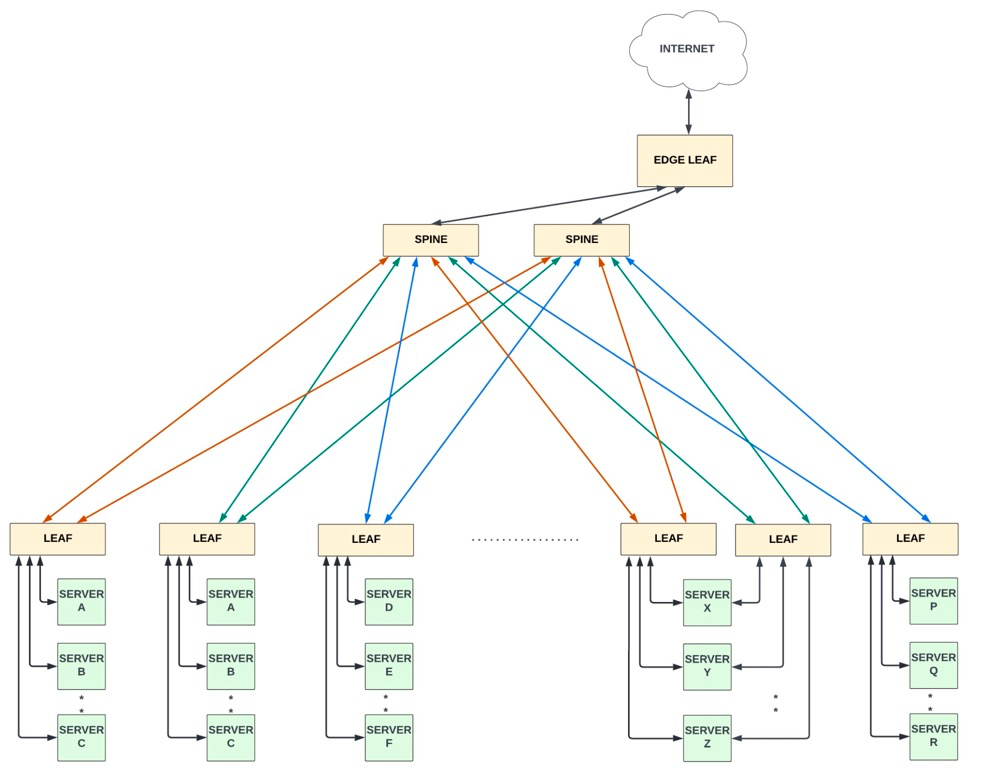
Spine通常与Leaf交换机有直接连接 (40Gbps - 400Gbps) 。Leaf交换机充当此拓扑中的传统 TOR 交换机,它们具有 20-50 个端口连接到机架中的服务器,以及多个上行链路 (40Gbps-400Gbps) 连接到所有Spine设备。 这种架构有以下几个优点:
两台服务器之间的东西向流量最多有四个跃点 (host-leaf-spine-leaf-host),这有助于减少总体延迟和功耗。
简化了中间层,与三层相比,拓扑中的网络设备更少。
可以独立添加Leaf和Spine设备,以增加网络容量,有时被称为“横向扩展”架构。
服务器虚拟化
为了更好地利用数据中心的 CPU 资源,公有云提供商采用了多租户模式,即服务器中 CPU 的计算能力在多个系统、应用程序和/或企业用户(租户)之间共享。尽管资源是共享的,但租户彼此之间互不干涉,且租户数据由服务器软件完全分开保存。多租户可以降低云计算硬件成本。
云服务提供商需要确保每个租户的数据安全,计算资源在租户之间公平共享,以及防止"嘈杂邻居"效应(其中一个或几个客户端/应用程序消耗大部分接口和计算带宽)。
主机服务器中的多租户通常通过服务器虚拟化来实现。服务器虚拟化是通过软件应用程序(如VMware Vsphere Hypervisor)将物理服务器划分为多个独立的虚拟机的过程。每个虚拟机都包含应用程序、操作系统和内核。服务器虚拟化允许每个虚拟机充当唯一的物理设备,但虚拟机依赖其专用的操作系统(OS),每个OS都会占用额外的CPU、RAM和存储服务器。
在过去几年中,云提供商和企业开始转向另一种共享服务器资源的方法——容器。容器是轻量级的操作系统级虚拟化,容器与宿主机共享硬件资源及操作系统,可以实现资源的动态分配。微服务是一种软件架构模型,其中应用程序被分解为多个具有明确定义的接口和操作的单个功能模块(微服务)。微服务链接在一起以创建“可插入”应用程序。在容器中运行微服务是现代数据中心使用计算资源的最有效方式之一。
虚拟机和容器化微服务不仅增加了主机之间的流量模式,还增加了主机内虚拟机和容器之间的流量模式。所有这些主机间和主机内的流量都需要进行交换/路由和保护,这都增加了服务器 CPU 的负担。
Spine/Leaf通信
在虚拟化之前,一台服务器只有一个 MAC 和一个 IP 地址。服务器虚拟化后,每个虚拟机或容器至少有一个 MAC 和一个 IP 地址。
如果Spine-Leaf交换机在第 2 层 (L2) 中转发流量,那么每个交换机都需要学习网络中的每个 MAC 地址,包括服务器上所有虚拟机的 MAC 地址。一台典型服务器中通常有 60-80 个虚拟机,每个机架大约有 40 台物理服务器,大约有 20 个机架,这意味着每个Spine交换机中有 64K个 MAC 表条目。
在 L2 转发中,当目的地未知或未被获知时,网络设备应将数据包泛洪到与其相连的所有端口,这可能会导致环路和数据包风暴。为了避免这种情况,可以使用生成树协议 (STP) 对VLAN 段内的网络拓扑修剪并创建树状拓扑。但STP 会阻塞冗余路径,减少可用链路的数量。
但是,如果Spine-Leaf通信位于第 3 层 (L3),则Spine交换机只需为每个子网(Leaf交换机和与其关联的服务器)使用 IP 转发,而无需学习所有的MAC 地址。
当Leaf交换机到服务器的通信是在二层时,Leaf交换机只需要了解其本地虚拟机的 MAC 地址。此外,ECMP可用于在Spine/Leaf之间通过多个并行链路(多路径)发送流量,从而更好地利用带宽,并且具有更好的弹性。
由于以上种种原因,L3 转发是Spine交换机和Leaf交换机之间的普遍选择。
云数据中心的另一个关键需求是能够在不更改MAC和IP地址的情况下将虚拟机从一台物理服务器移动到另一台物理服务器。
如果所有虚拟机都位于一个平面以太网中,那么MAC 移动是可行的。在Spine/Leaf和host之间进行L2转发,可以使用VLAN创建多个网段,并且特定网段内的虚拟机可以自由移动。但是,由于只有 4K个VLAN,基于 VLAN 的分段无法很好地扩展,也印证了L2 转发不是首选。
这就是 VXLAN 发挥作用的地方。VXLAN隧道协议将以太网帧封装在IP/UDP数据包中,可以创建跨物理 L3 网络的虚拟化 L2 子网。每个 L2 子网均由 24 位 的VNI唯一标识。执行 VXLAN Encap/Decap 的实体(如主机或网络设备中的hypervisor等软件应用程序)称为 VTEP(VXLAN 隧道端点)。VTEP的服务器端位于二层桥接域,网络端是IP网络。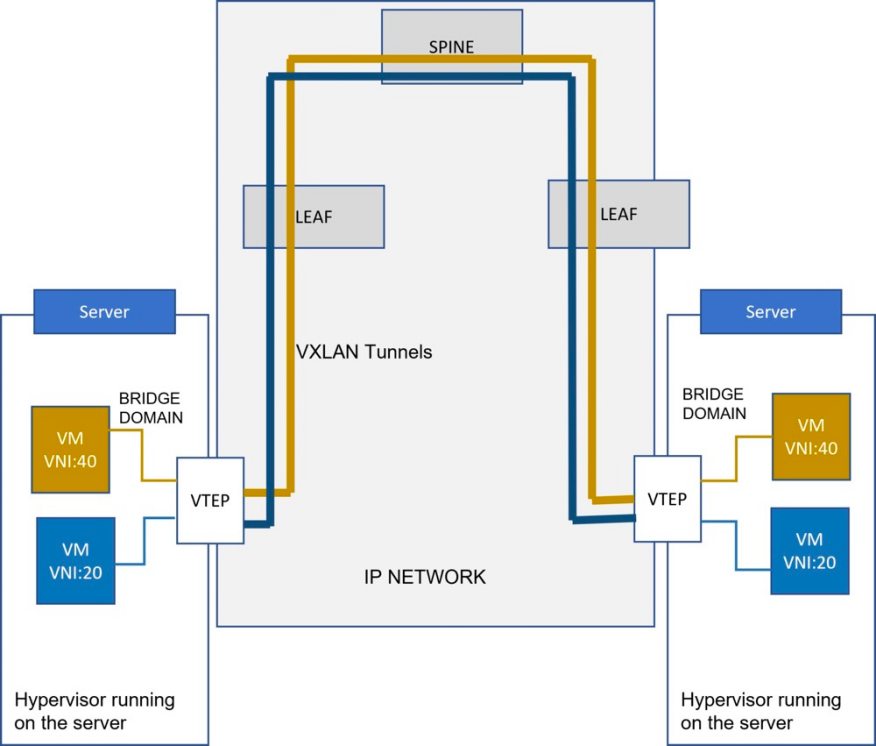
VXLAN 报头中的 24 位 VNI 转换为 1600 万个 VNI 子网,这可以在 IP 底层网络之上构建大规模虚拟以太网Overlay 网络。还有其他Overlay 协议,如 NVGRE,也能实现类似的结果,但相对而言VXLAN 是一个流行的选择。
SmartNIC的兴起
上文在传统三层网络架构向二层网络架构的转变中,提到了服务器虚拟化和容器化的种种优势,但虚拟机依赖其专用的操作系统(OS),每个OS都会占用额外的CPU、RAM和存储服务器。此外,使用分布式服务模型,网络和安全功能也需要在虚拟机/容器之间的所有流量上运行,这会给服务器 CPU 资源带来压力,CPU 可能会使用 30% 的内核来实现这些功能。
CPU作为服务器中最昂贵的组件,理想情况下,我们希望CPU的所有能力都用来单独运行应用程序软件,而不是用来处理网络、安全或存储功能,也就是所谓的基础设施功能。
这就是SmartNIC出现的原因之一。
NIC 是一种网络接口卡,通过以太网接口接收来自网络的数据包,并将其发送到服务器 CPU,反之亦然。NIC通过PCIe接口连接到服务器CPU,以线路速率将数据包传输到 CPU 或从 CPU 传输出来。随后,NIC开始添加硬件加速(使用 ASIC 或 FPGA),以减轻服务器 CPU 对基本数据包处理功能的负担。
事实证明,把服务器从基础设施功能处理中剥离出来可以节省大量成本,因此,越来越多的此类功能开始进入NIC。S
martNIC一词是指那些使用定制 ASIC/FPGA 或基于 SOC 的硬件加速,将 CPU能力从基础网络功能中释放出来的NIC。
x16 接口的 PCIe 插槽的功率预算约为 75 瓦,这限制了用于加速的硬件设备的功耗。虽然基于FPGA的解决方案开发时间更快,但很难满足75W的功耗要求。
另外,在SOC 中使用处理器内核进行加速/卸载的方法无法获得良好的性能,因为处理器内核无法以足够快的速度处理数据平面流量,以跟上 >100Gbps 以太网流量。
因此,许多供应商都在提供带有 ASIC 的混合解决方案,ASIC具有数据平面处理器内核(用于处理难以在硬件中实现的复杂网络功能)和可编程硬件加速器以及传统的数据包处理卸载。这些设备通常被称为 DPU 或数据处理单元,DPU 还拥有自己的控制/管理平面。
在某些配置中,DPU 可以集成为Leaf交换机的一部分,或者作为Leaf交换机和传统 NIC 之间的转换器。但最常见的配置是将 DPU 作为 NIC 的一部分集成到服务器组中。
DPU是Smartest NIC?
DPU 中的典型子系统和接口如下图所示:
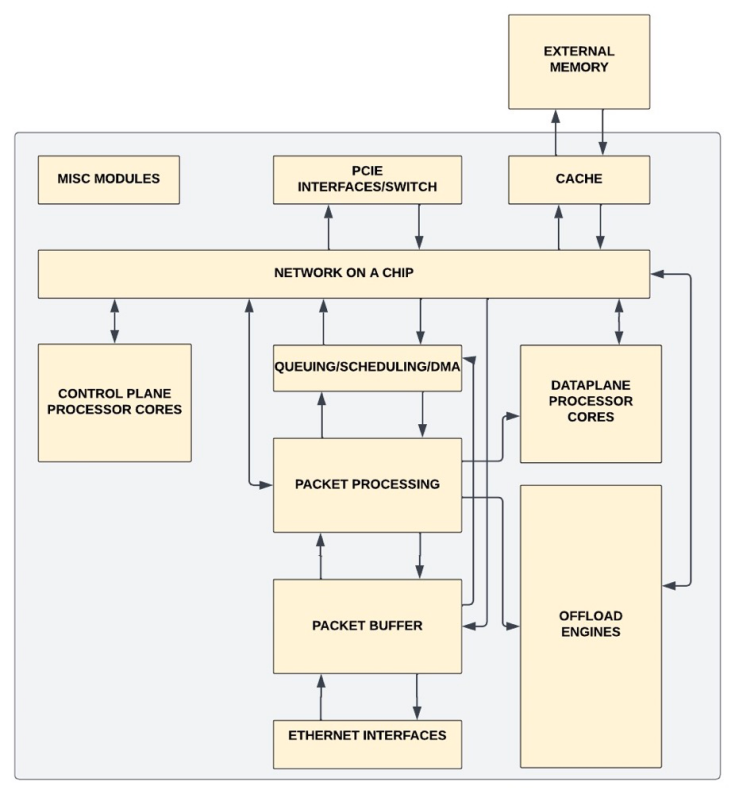
以太网接口
通常至少有两个端口,且每个端口为 25Gbps 至 200Gbps(有些供应商在开发 400Gbps)。每个以太网接口都连接到 MAC/PCS 子系统,以提取数据包提取并在第2层检查数据包完整性。
与主机之间的 PCIe 接口
通常是Gen3/4/5接口。可能有多个 PCIe 接口,一些接口与 CPU 通信,另一些接口与 SSD/GPU 通信。在设计PCIe 接口到CPU的整体带宽时,应保证能处理来自以太网接口的全部流量,以在不拥塞的情况下到达 CPU。
在具有许多虚拟机的高度虚拟化服务器中,依赖hypervisor向所有虚拟机提供连接会增加 CPU 的开销。SR-IOV 标准允许单个NIC在hypervisor软件中显示为多个虚拟NIC(每个虚拟机一个)。它允许不同的虚拟机共享单个 PCIe 接口,而无需在hypervisor中使用虚拟交换机。PCIe complex支持 SR-IOV 所需的 PF/VF。
实现此功能的 DPU 负责在数据包处理引擎中的虚拟机(Open vSwitch) 之间进行切换。
数据包转发
DPU 通常具有复杂的数据包转发管道,支持所有 L2/L3 转发功能。因此,非常需要有一个可编程的数据平面。P4 是转发平面编程的首选语言,它可用于定义可编程和固定功能网络处理单元中的数据平面行为。
除了支持基本的L2/L3转发之外,在卸载引擎和/或处理器内核的帮助下,数据包转发逻辑还可以支持多种功能。具体实施情况因供应商而异。
Overlay支持:DPU 可以作为 VXLAN 隧道端点 (VTEP),从服务器hypervisor卸载此功能。它可以支持VXLAN和其他Overlay协议的Inline封装/解封装。该逻辑在数据包处理引擎中实现。
TCP 基本功能
TCP 校验和卸载
CP 报头有一个校验和字段,DPU 可以计算校验和并将错误标记给 CPU。
TCP 分段卸载
CPU 可以将大数据块与报头模板一起发送给 DPU。DPU 对数据包进行分段,并在每个分段中添加以太网/IP 和 TCP 报头。
TCP Large Receive Offload
DPU 可以收集单个流的多个 TCP 报文,并将它们发送到 CPU,以便 CPU 不必处理许多小报文。
Receive Side scaling
DPU 可以通过对五元组进行哈希来确定数据包的流。属于不同流的数据包可以到达 CPU 的不同内核。这减少了单个 CPU 线程上的负载。
流表
在基于流的转发中,主机 (CPU) 或 DPU 的控制平面处理器对前几个报文进行报头检测。之后,处理器将流记录到流表中。然后,相同流中的其余报文可以通过流表查找来处理,使用的流标识字段是通过哈希L2/IP报头和外部封装报头形成的。
这可以显着提高某些应用程序的性能,因为查找流表比全面检查和评估每个数据包要快得多。流表由数百万个条目组成,存储在外部存储器中。
安全功能
DPU 支持多种功能,以验证和保护不同应用程序之间的流量。
加密/解密
DPU 支持 VPN 终端,可对加密的VPN流量进行在线加/解密和IPsec认证。
防火墙/ACL
现代数据中心依赖于分布式防火墙,防火墙可以通过数据平面处理器内核或卸载引擎来加速。不同的DPU 具有不同的防火墙功能。通常,厂商提供静态数据包过滤、访问控制列表 (ACL) 和 NAT。
TLS 加密/解密
传输层安全 (TLS) 对应用层流量进行加密,使黑客无法窃听/篡改敏感信息。它运行在 TCP 之上,最初用于加密 HTTP 会话——Web 应用程序和服务器之间的流量。最近,许多运行在 TCP 上的应用程序也开始使用 TLS 来实现端到端安全。TLS 也可以运行在 UDP 之上,称为 DTLS协议。某些 DPU 提供代理 TCP/TLS 服务,用于终止 TCP 会话、解密 TLS 加密流量,以及在将流量发送到主机处理器之前对其进行身份验证。TCP/TLS 卸载通常通过专用硬件和处理器内核的组合来完成。
控制平面的处理器内核
DPU 具有一组运行 Linux 的 ARM 内核,用于运行控制(包括 Open vSwitch 控制平面)和管理协议。
Cross-Bar或NoC
提供内存和缓存的连接,并保持缓存一致。
QoS/流量整形
NIC 接收托管不同在虚拟机/容器中不同应用程序的流量,并且需要支持 QoS。DPU 支持多个队列和优先级,并支持从这些队列进行调度的复杂调度算法,还支持流量整形以减少传出流量的突发性。
DMA 引擎
DMA 引擎可以在DPU和主机内存之间发起内存传输。
存储功能
随着计算资源的解耦,存储解耦在数据中心也得到了大力支持。许多云提供商正在将存储与计算分离,以降低基础设施成本、减少需要支持的服务器配置数量,并能够为数据密集型 AI/ML 应用程序提供灵活的存储资源。
存储服务器是一组存储设备(主要是NVMe SSD),充当逻辑池,可以分配给网络上的任何服务器。存储服务器中的远程 SSD 和 CPU 之间的文件和块数据传输发生在承载数据包流量的同一个Spine-Leaf网络上。
NVMe over Fabric 和 NVMe over TCP 是流行的协议,可以使用以太网和 TCP/IP Underlay在数据中心网络上使用 NVMe 传输数据。DPU 通常通过实施硬件加速引擎来支持对远程存储服务器的访问,硬件加速引擎可以启动这些协议来读/写 SSD。
此外,DPU 还支持 RDMA over IP (RoCE) 卸载、数据压缩/解压缩(以减少通过网络传输到 SSD 设备的数据量)和确保安全的数据加密/解密。
负载均衡器
负载均衡器将应用程序流量分配到多个虚拟机/容器(运行应用程序),以支持多个并发用户。比如谷歌地图APP可能托管在谷歌数据中心的许多服务器上,当用户在地图上查询路线时,根据服务器上的负载,每个查询可能会转到不同的服务器。
负载均衡器对第 4 层(TCP/UDP 报头)和/或第 5-7 层(应用程序数据)中的字段进行哈希处理,以查找可用服务器的表,并使用策略分配应用程序流量。实际的实现比这个描述复杂得多,是通过卸载引擎实现的。
DPU 的未来
所有云提供商都在大力投资定制DPU的开发工作,并过渡到基于 DPU 的智能NIC,以降低基础设施成本,并提供更好的吞吐量/性能。
目前,这些 DPU 尚未广泛渗透到企业客户中,它们比标准NIC要贵很多,并且在编程NIC 软件时涉及工程工作。对于公有云提供商来说,由于其数据中心规模庞大,在所有服务器上分摊的工程工作量并不显著。但对于中小企业客户来说,将更多的标准化特性卸载到 DPU 和完全可编程的数据平面架构可以帮助简化开发工作。
随着云软件和 DPU 硬件团队之间更紧密的交互(硬件和软件的共同设计),会发现更多从卸载到DPU中受益的功能。此外,DPU未来有可能完全解耦云资源,并将 CPU/GPU/GPGPU 降级为与DPU连接的劳动力。
原文链接: https://www.linkedin.com/pulse/evolution-smartnicsdpus-modern-data-centers-sharada-yeluri?trk=public_post-content_share-article
审核编辑:刘清
-
交换机
+关注
关注
21文章
2637浏览量
99528 -
路由器
+关注
关注
22文章
3728浏览量
113701 -
Mac
+关注
关注
0文章
1104浏览量
51458 -
虚拟机
+关注
关注
1文章
914浏览量
28160 -
VLAN通信
+关注
关注
0文章
18浏览量
5635
原文标题:现代数据中心SmartNIC/DPU 的演变
文章出处:【微信号:SDNLAB,微信公众号:SDNLAB】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
buck电路原理图讲解 buck电路的演变过程
《数据处理器:DPU编程入门》读书笔记
数据中心的建设也看重风水
【视频分享】降压电路的演变过程
数据中心是什么
英伟达DPU的过“芯”之处
【书籍评测活动NO.23】数据处理器:DPU编程入门
什么是DPU?
定位技术的演变过程
如何构建基于DPU的SmartNIC

探究DPU的缘起,DPU提升数据中心算力的三种方式
DPU处理器在数据中心的作用是什么?
buck电路的演变过程





 工商网监
工商网监
评论