 基于多曝光图像生成的低照度图像增强方法
基于多曝光图像生成的低照度图像增强方法
低照度图像会使很多计算机视觉算法的鲁棒性降低,严重影响机器人领域的许多视觉任务,如自动驾驶、图像识别以及目标追踪等。为获取具有更多细节信息以及更大动态范围的增强图像,提出了一种基于多曝光图像生成的低照度图像增强方法。该方法通过分析真实拍摄的多曝光图像,发现不同曝光时长的图像的像素值之间存在线性关系,使得正交分解的思想可以应用于多曝光图像生成。多曝光图像是根据物理成像机制生成的,与真实拍摄图像更为相近。在将原图分解得到光照不变量和光照分量后,通过设计自适应算法生成不同的光照分量,再与光照不变量合成可以得到多曝光图像。最后利用多曝光图像融合方法获取具有更大动态范围的增强图像。该融合结果与输入图像保持一致,最终的增强图像可有效保留原始图像的色彩,自然度高。在真实拍摄的低照度图像公开数据集上进行了实验并与现有先进算法进行对比,结果表明,本文方法得到的增强图像与参考图像之间的结构相似性提高了2.1%,特征相似性提高了4.6%,增强图像与参考图像更接近且自然度更高。
在低光照条件下或相机曝光时间不足的情况下拍摄的图像称为低照度图像。低照度图像通常具有低亮度、低对比度以及结构信息模糊的特点,这给很多机器人视觉任务带来了困难,如低照度图像的人脸识别、目标跟踪[1]、自动驾驶[2]、特征提取[3]等任务。低照度图像的增强方法不仅可以改善图像的视觉效果,还可以提高后续机器人视觉任务算法的鲁棒性,具有重要的实际应用价值。
根据是否需要依赖大量的数据进行训练,目前已有的低照度图像增强算法可以分为传统方法和基于深度学习的方法两类。在传统的低照度图像增强方法中,基于直方图的方法[4-5]通过调整图像的直方图来提高图像的对比度,达到增强低照度图像的目的,这类方法简单高效,但缺乏物理机制,常常导致图像的过增强或欠增强,并且图像的噪声也会被明显地放大。基于Retinex理论[6]的方法先通过将图像分解得到光照分量和反射分量,再分别进行增强。Wang等[7]设计了一个低通滤波器将图像分解为反射图像和光照图像,并使用一个双对数变换对图像进行增强来平衡自然度和图像细节。Guo等[8]先对低照度图像的RGB三通道取最大值得到一个初始的光照图像,再通过结构先验信息来修正初始光照,使用伽马校正法调整图像亮度,再将调整后的光照图像与反射图像合成得到最终的增强结果。Ren等[9]提出了一种抑制噪声的序列评估模型来分别估计光照分量和反射分量,在这种噪声抑制的序列分解过程中,对每个分量进行空间平滑并巧妙地利用权重矩阵来抑制噪声和提高对比度,最后将估计得到的反射分量与伽马校正后的光照分量合并得到增强图像,最终达到低照度增强联合去噪的目的。
基于深度学习的方法[10-13]通过对大量数据的训练,在低照度图像增强上取得了很好的效果。Lore等[10]最先提出了一个用于对比度增强和噪声消除的深度自动编码器来增强低照度图像。Wei等[11]将Retinex模型和深度神经网络结合用于低照度图像增强中。Jiang等[12]利用生成式对抗网络实现了低照度图像增强模型,该模型无需使用配对的训练数据进行训练。Guo等[13]将低照度图像增强任务转换为一项具有深度网络的特定曲线估计任务。这些基于深度学习的方法的训练过程通常需要耗费大量的时间和计算资源。并且这些方法的效果在很大程度上取决于训练数据,不准确的参考图像会影响训练结果,比如在真实拍摄的正常光照图像中,由于光照不均匀可能存在局部高光照区域过曝光或局部低光照区域欠曝光的问题。
在低照度图像增强中,不均匀的光照也是一个需要解决的问题。对于局部低照度图像来说,将图像亮度提升过高会导致图像的高光照区域过曝光,而亮度提升不足又无法将低光照区域的图像细节信息展示出来。得益于拍照设备的进步,可以固定拍照设备并在短时间内获取不同曝光时长的图像,并将拍摄所得的一组图像融合得到具有更大动态范围的图像。Wang等[14]在YUV色彩空间中设计了一种基于边缘信息保留的平滑多尺度曝光融合算法,可以同时保留场景中高光照区域和低光照区域中的细节,为了弥补融合过程中丢失的细节信息,设计了一个矢量场构造算法从矢量字段中提取可见的图像细节,且该方法可避免图像融合过程中出现的颜色失真。图像融合的方法虽然可以有效地提高图像动态范围,但需要预先获取一组不同曝光时长的图像,无法对单张低照度图像增强。拍摄动态场景或拍摄时相机发生抖动都会使得所拍摄的图像对准困难,进而导致融合结果中存在伪影。
为了将图像融合的方法应用到低照度图像增强中达到提高图像动态范围的目的,需要先根据单张图像生成一组用于融合的信息。目前已有一些方法将图像融合的思想用于低照度图像增强。其中,Fu等[15]先通过一种基于形态学闭合的光照估计算法将图像分解得到光照图像和反射图像,再分别使用Sigmoid函数和自适应直方图均衡化算法对照明图像进行处理得到亮度提升后的光照图像和对比度增强的光照图像,将两个增强后的光照图像进行融合再与反射图像合成得到最终的增强图像。Cai等[16]采集了589组多曝光图像,并用13种已有的方法对多曝光图像进行融合,选取最优结果作为参考图像,设计了一个卷积神经网络在这个数据集上进行训练,最终得到一个低照度图像增强器。基于图像融合的单张低照度图像增强方法有效解决了图像融合需要多张曝光图像作为输入图像的问题,但Fu等[15]和Cai等[16]的方法仍然存在缺乏物理机制的问题。
针对目前方法存在的问题,本文提出了一个基于多曝光图像生成的低照度图像增强方法。首先从物理成像机制出发,分析了曝光图像之间的关系,发现不同曝光时长的图像之间存在与阴影和非阴影图像之间相似形式的关系。基于此,首次提出将正交分解方法[17]用于多曝光图像融合,即使用正交分解的方法将图像分解得到光照分量与光照不变量,通过改变光照分量生成具有不同曝光时长的图像。再利用图像融合的方法将生成图像融合得到具有高动态范围的图像。由于生成的图像与真实拍摄的图像比较接近,融合所得的增强图像自然度也保持得很好。同时,由单张图像生成的多曝光图像是逐像素对应的,融合结果不存在伪影,也解决了拍摄多曝光图像时相机需要固定的问题。并且,本文方法无需依赖大量的数据进行训练,具有很好的通用性。
2 多曝光图像的生成与低照度图像增强
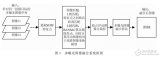
本文方法主要包含3个部分:(1)图像正交分解。将原图分解得到一个光照分量和一个光照不变量。(2)多曝光图像生成。通过改变光照分量的大小生成多曝光光照分量,并将其与原始光照不变量合成,得到多曝光图像;(3)多曝光图像融合。将多曝光图像融合,得到最终增强后的图像。图 1所示为本文算法框架。
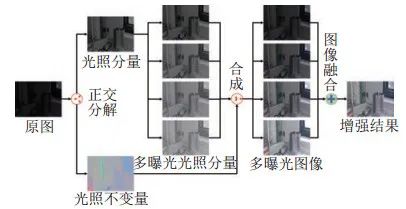
图 1算法框架
2.1
多曝光图像之间的线性关系
通过实验发现,在光照和相机参数固定的情况下所拍摄的不同曝光度的图像之间存在线性关系,如图 2所示,图 2(a)为一组不同曝光时长下拍摄的色板图像,图 2(b)分别展示了RGB三通道在不同曝光度下色板中24个颜色的真实像素值与拟合线,绿色圆圈代表了真实像素值,红色实线代表拟合线,像素值均为伽马校正前的RGB像素值,横坐标代表前4张色板图像的像素值,纵坐标代表第5张色板图像的像素值。
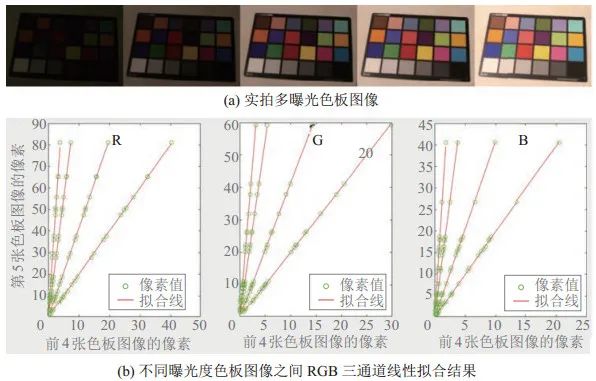
图 2实拍多曝光图像的像素间的线性关系
图 2中所示的线性关系可以表达为
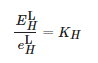
(1)
其中E 和e 分别代表长曝光时间和短曝光时间的像素值,H 代表R、G、B三个通道,L代表伽马校正前的情形,KH为不同曝光下的像素之间的比值。由于3个通道的KH的拟合值大小近似,故在本文中,设置KR=KG=KB。
2.2
图像正交分解
对式(1)中的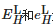 进行伽马校正后可以得到:
进行伽马校正后可以得到:
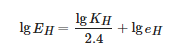
(2)
这与同一物体在阴影区域和非阴影区域中的像素所展示出的RGB三通道之间的关系[18]有相似的表达形式。
与文[17]中相似,由式(1)可以得到:
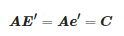
(3)
其中
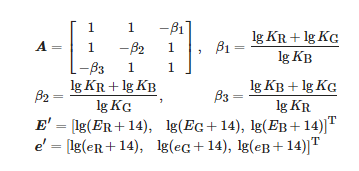
C可以由像素值计算得到。
对图像中任一像素,像素值为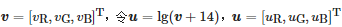 ,由式(3)可得:
,由式(3)可得:
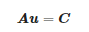
(4)
本课题组首次在文[17]中提出正交分解方法,如式(5)所示:
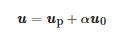
(5)
其中u0为方程(4)的自由解,满足Au0=0 ,∥u0∥=1 ,up是方程(4)满足up⊥u0的唯一特解。图像的任意一个像素所对应的up与α 均可通过图像的像素值计算得到。图 3所示为阴影图像中与多曝光图像中正交分解的示意图。通过线性代数可知自由解u0只与KH相关:在阴影图像中,KH为只受光照条件影响的参数;在多曝光图像中,KH为只受不同曝光时间下入射光影响的参数。而特解up垂直于自由解u0意味着特解up与自由解u0互相独立正交,即特解up具有光照不变性质。这意味着,对于一个给定的像素,无论该像素点在何种曝光时间下拍摄,在对该点的像素值进行正交分解后都可得到一个垂直于自由解且不受不同曝光时间下入射光影响的唯一特解up,而α 的大小则体现了光照的变化。整张图像的up组成了光照不变量,整张图像的α 组成了光照分量。
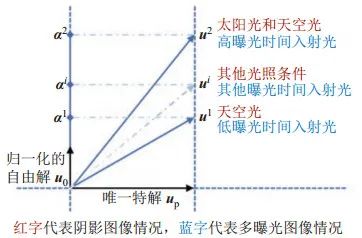
图 3阴影图像与多曝光图像中的正交分解示意图
2.3
自适应生成多曝光图像
在得到原图的光照不变量与光照分量后,对光照分量进行增强或减弱即可得到具有不同曝光时长的光照分量:
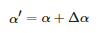
(6)
其中Δα 为光照增量,通过控制Δα 的大小,即可得到不同曝光时长的光照分量。再通过式(7)即可生成不同曝光时长的图像:
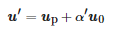
(7)
最后根据式(8)对u′ 变换得到相应RGB空间内的像素值,其中13×1表示3×1 维的全1矩阵。
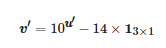
(8)
图 4所示为一组真实拍摄的多曝光图像和通过控制Δα 的大小生成的多曝光图像,生成图像均为通过将实拍图 1作为原始图像生成所得。从图中可以看出,生成图像与实拍图像之间的差异随着生成图像与原始图像之间的亮度差的增大而增大。

图 4一组实拍多曝光图像与生成的多曝光图像
为了自动地生成具有不同曝光时长的多曝光图像,设计了自适应生成多曝光图像的算法,可以根据原图的亮度自动选择光照增量Δα 的大小,并生成N 张不同曝光时长的图像。
将图像中任一像素(像素值v=[vR,vG,vB]T的亮度定义如下:
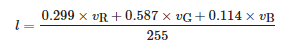
(9)
整张图像的亮度L如下:
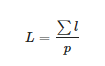
(10)
其中p 代表整个图像的像素总数。
记N张生成图像所对应的光照增量为Δαi,i= 1,2,⋯,N ,首先确定其中最小的光照增量Δα1和最大的光照增量ΔαN,之后在Δα1到ΔαN之间根据式(11)均匀生成N个光照增量:
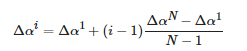
(11)
当L<0.3 时,只生成光照分量增大的图像,即令最小的光照增量Δα1=0 。根据式(12)求最大的光照增量ΔαN :
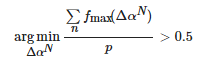
(12)
其中,
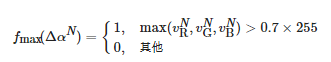
(13)
其中,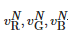 分别代表原像素在光照分量增加了ΔαN 之后的R、G、B三通道的像素值。
分别代表原像素在光照分量增加了ΔαN 之后的R、G、B三通道的像素值。
由于生成图像与原图之间的光照增量越大,所生成的图像与真实的不同曝光图像之间的误差越大,故当ΔαN>1.2 时,令ΔαN=1.2 。
当L>0.3 时,既生成光照分量增大的图像,也生成光照分量减小的图像。ΔαN的获取方式与当L<0.3 时的方式相同。根据式(14)求Δα1 :
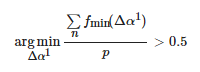
(14)
其中,

(15)
其中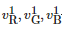 分别代表原像素在光照分量增加了Δα1之后的R、G、B三通道的像素值。当Δα1<−0.5时,令Δα1=−0.5 。
分别代表原像素在光照分量增加了Δα1之后的R、G、B三通道的像素值。当Δα1<−0.5时,令Δα1=−0.5 。
本文中设置N= 5,图 5所示为一组自适应生成的多曝光图像。从图中可以看出,生成图 5在低光照区域的雕塑上得到了显著增强,但在高光照区域(即窗外场景中)过曝光;而在生成图 3中,高光照区域得到了合适的曝光,但低光照区域欠曝光。上述现象说明vwin 自然拍摄生成的不同曝光图像无法同时恰当地展示出高光照区域和低光照区域的图像信息。

图 5一组自适应生成的多曝光图像
2.4
多曝光图像融合
为了得到更大动态范围的增强图像,本文采用多尺度曝光融合方法[14]将多曝光图像融合生成最终的增强图像。与该方法利用拍摄所得的一组多曝光图像进行融合不同,本文将单张图像自适应生成的N 张不同曝光图像用于融合,实现了对单张低照度图像的增强,并且可以有效避免拍摄动态场景或相机抖动所带来的伪影问题。具体算法如下:
(1) 根据原图通过2.3节中的方法生成N 张多曝光图像Qk(k=1,2,⋯,N ),本文中设置 N= 5。
(2) 将Qk(k=1,2,⋯,N ),从RGB颜色空间转换到YUV颜色空间得到 Ik(k=1,2,⋯,N )。
(3) 根据式(16)计算多曝光图像的加权图:
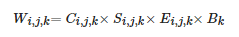
(16)
其中i,j 代表像素位置,C、S、E和B分别代表根据对比度、饱和度、曝光时长以及图像亮度计算得到的权重,具体计算方法参考文[14]。为使得权重的和为1,对Wij,k归一化得到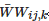 。
。
(4) 对Ik和分别建立拉普拉斯金字塔和高斯金字塔得到 ,n 代表金字塔的层数,与文[14]相同,n=⌊log2min(h,w)⌋−2 ,h 和w 分别代表图像的行数和列数,⌊⋅⌋ 为向下取整符号。
,n 代表金字塔的层数,与文[14]相同,n=⌊log2min(h,w)⌋−2 ,h 和w 分别代表图像的行数和列数,⌊⋅⌋ 为向下取整符号。
(5) 对1到n−1 层金字塔根据式(17)进行融合:
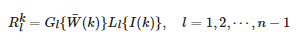
(17)
(6) 对第n层金字塔根据式(18)进行融合:
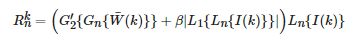
(18)
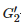 代表高斯滤波器,用于平滑
代表高斯滤波器,用于平滑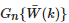 ,当k= 1,2时,令β=1.5 ;当k=3,4,5 时,令β=0 。
,当k= 1,2时,令β=1.5 ;当k=3,4,5 时,令β=0 。
(7) 由下式得到最终的低照度图像增强结果:
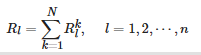
(19)
3 实验结果与分析
3.1
参数设置
为了确定生成多曝光图像张数N与算法性能之间的关系,在LOL数据集[11]的500张图像上对本文算法进行测试,并采用3个评价指标对N取不同值时的增强结果进行评价,如图 6所示。
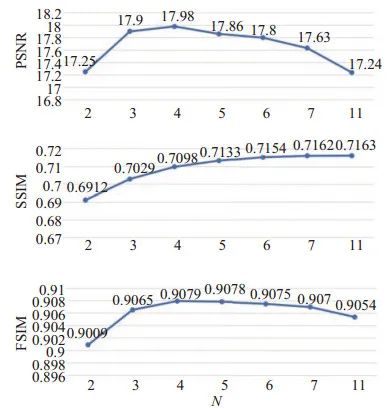
图 6参数N的选择与LOL数据集上的评价结果
峰值信噪比(PSNR)、结构相似性(SSIM)和特征相似性(FSIM)[19]这3个全参考的评价指标,均为值越大说明增强效果越好。从图 6中可以看出,指标PSNR先是随着N的增大而提高,在 N= 4时达到最大,之后随着N的增大而降低,这是因为当 N太小时输入信息不足,而当N太大时融合结果中的噪声会被放大,指标PSNR反而会降低;指标SSIM随着 N的增大而提高,这是因为当输入图像增多,提供的信息也随之增多,融合所得结果的结构也越清晰;指标FSIM在N= 2时较低,在N> 2时N的取值对指标FSIM影响不大。综合考虑这3个指标,本文中将N设置为5。
3.2
公开数据集上的对比实验
本节分别从主观恢复效果和客观评价指标2个方面,对本文方法与5个代表性的低照度增强方法在2个公开数据集的测试集上进行对比。其中,NPE方法[7]、LIME方法[8]、JED方法[9]为传统方法,RetinexNet方法[11]和ZeroDCE++方法[13]为基于深度学习的方法。LOL数据集[11]的测试集包含15组图像,其中低照度图像和参考图像均为相机拍摄所得。MIT数据集[20]的测试集包含500组图像,其中低照度图像为相机拍摄所得,参考图像为由5位摄影师(A/B/C/D/E)利用软件手动调整所得,本文采用摄影师C的调整结果作为参考图像,并将图像转为400×400像素大小的PNG格式图像用于测试。图 7展示了LOL测试集[11]上的低照度图像增强结果,图 8和图 9分别展示了MIT测试集[20]上的室外和室内低照度图像增强结果。从图 7可以看出,本文方法的增强结果与参考图像最为接近,说明本文方法的增强结果最接近真实拍摄图像。NPE方法[7]成功提升了图像的亮度,且增强了图像的饱和度,使得图像色彩更鲜明,但是在一些情况下会存在颜色失真的问题,如在图 9(a)的恢复结果中脸部皮肤泛红,在图 9(b)的恢复结果中黑色衣服发白。
LIME方法[8]同样成功提升了图像的亮度,且图像的对比度得到了增强,但存在局部高光照区域过增强的问题,如在图 9(e)的恢复结果中,脸部由于过增强得到了过曝光的增强结果。JED方法[9]的增强结果中图像亮度略低于其他方法,且去噪算法导致恢复图像存在过平滑现象而缺失细节纹理信息。RetinexNet方法[11]的增强结果很好地突出了图像的结构信息,但是增强图像与真实拍摄图像的风格差异较大,存在不自然的问题。ZeroDCE++方法[13]同样存在增强结果的风格变化问题,如图 8(b)和图 9中所示,ZeroDCE++方法[13]的增强结果发白。与以上方法相比,本文方法的增强结果对原始色彩的保持更好,与真实拍摄图像的颜色更接近,且能够成功地将高光照区域和低光照区域的图像信息同时展现在增强结果中,没有对高光照区域过增强导致过曝光。

图 7LOL测试数据集[11]上低照度图像的增强结果

图 8MIT测试数据集[20]上室外低照度图像的增强结果

图 9MIT测试数据集[20]上室内低照度图像的增强结果
为了定量评价本文方法的增强效果,采用全参考的评价指标PSNR、SSIM和FSIM[19]对各个方法的增强结果进行评价。其中PSNR越大,说明增强结果与参考图像在像素值上越接近;SSIM越大,说明增强结果与参考图像在结构上越接近;FSIM越大,说明增强结果与参考图像在特征上越接近。
表 1给出了LOL测试集[11]上不同方法的定量评价结果,表 2给出了MIT测试集[20]上不同方法的定量评价结果。其中最优的指标值以红色表示,次优的指标值以蓝色表示。从表 1可以看出,本文方法在LOL测试集[11]上3个评价指标均最优,即本文方法得到了与真实拍摄图像最为接近的增强结果。从表 2可以看出,本文方法在MIT测试集[20]上SSIM和FSIM均取得最优结果,PSNR取得了次优的结果,说明本文方法的增强结果与手工调整的参考图像在结构和特征上最为接近。
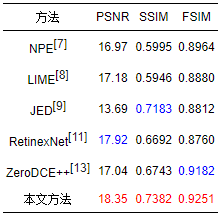
表 1LOL测试集[11]上的定量评价结果
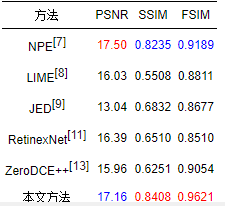
表 2MIT测试集[20]上的定量评价结果
3.3
多曝光融合实验分析
本节首先对本文所生成的多曝光图像与固定相机拍摄的多曝光图像在融合增强性能方面进行了对比,效果如图 10所示。其中图 10(a)(b)为固定相机后拍摄的具有不同曝光时长的图像,图 10(c)为本文方法将图 10(a)作为输入图像得到的增强结果,图 10(d)为将图 10(a)(b)作为输入图像融合得到的结果。从图中可以看出,本文方法增强结果图 10(c)的对比度好于实拍多曝光图像的融合结果图 10(d),并且从红框放大区域可以看出,本文方法结果的清晰度要更高。从图 10(d)的黄框中可以看到,由于拍摄到动态场景(骑摩托车的人)而在融合中产生了伪影,但此问题在本文方法的结果中则不存在。

图 10本文方法与实拍多曝光图像融合结果对比
其次,对本文生成的多曝光图像融合结果与单一增加曝光结果进行了图像增强效果对比,如图 11所示。在仅仅增加曝光量的实验结果中,原图像中光照低的部分(如建筑)得到了明显的增强,但原图像中光照高的部分(如天空和灯)则由于过曝光而丢失了原有图像的信息,在多曝光融合的结果中,则成功将低光照和高光照部分的信息同时保留,说明本文方法可以在有效提高图像亮度的同时得到具有更大动态范围的增强结果。

图 11多曝光融合结果与增加曝光结果对比
4 结论
提出了一个基于多曝光图像生成的低照度图像增强方法。该方法基于物理机制,根据单张低照度图像生成多曝光图像,实现了单张图像的低照度增强,其效果优于一些现有的单张低照度图像增强方法以及多张曝光图像融合的方法。本文提出的根据单张低照度图像进行增强的方式,可有效避免伪影的产生,与使用多张曝光图像进行融合的方式相比具有更好的通用性。
审核编辑:刘清
-
机器人
+关注
关注
211文章
28379浏览量
206913 -
低通滤波器
+关注
关注
14文章
474浏览量
47387 -
RGB
+关注
关注
4文章
798浏览量
58461 -
计算机视觉
+关注
关注
8文章
1698浏览量
45974 -
自动驾驶
+关注
关注
784文章
13784浏览量
166383
原文标题:基于多曝光图像生成的低照度图像增强
文章出处:【微信号:机器视觉沙龙,微信公众号:机器视觉沙龙】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于Matlab的图像增强与复原技术在SEM图像中的应用

运动相机的多曝光图像融合技术
基于Retinex图像增强
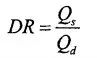
一种全新的遥感图像描述生成方法

一种基于改进的DCGAN生成SAR图像的方法

基于图像的数据增强方法发展现状综述


基于差分卷积神经网络的低照度车牌图像增强网络






 工商网监
工商网监
评论