 四足机器人走着走着突然断了一条腿,还能继续前进吗?
四足机器人走着走着突然断了一条腿,还能继续前进吗?
四足机器人走着走着突然断了一条腿,还能继续前进吗?
来自谷歌和密歇根大学的最新成果,给出了非常肯定的答案。
他们发明的一种叫做AutoRobotics-Zero (ARZ)的搜索算法,既不靠大模型,也不用神经网络,可以让机器人一旦遇到剧烈的环境变化,就立刻自动更改行动策略。
譬如断腿照样走:

相比之下,别的神经网络方法还是这样婶儿的(手动狗头):

这个方法非常令人耳目一新。

机器人再也不怕被忽悠瘸了
具体如何实现?
让机器人断腿继续走的秘密
快速适应环境变化是机器人部署到现实世界中非常重要的一项技能。
但目前常用的循环神经网络(RNN)技术存在策略单一、重参数化导致推理时间长、可解释性差等问题。
为此,作者直接“另起炉灶”,基于AutoML Zero技术开发了这项全新的四足机器人环境自适应策略:AutoRobotics-Zero (ARZ)。
关于,不熟悉的朋友再了解一下:
它是2020年诞生的一种“从零开始的自动机器学习”算法,出自谷歌大脑Quoc V.Le大神等人之手,仅使用基本数学运算为基础,它就能从一段空程序开始,自动发现解决机器学习任务的计算机程序。
在此,作者也将各种机器人行动策略表示为程序,而非神经网络,并仅使用基本的数学运算作为构建块,从头开始演化出可适应性策略及其初始参数。

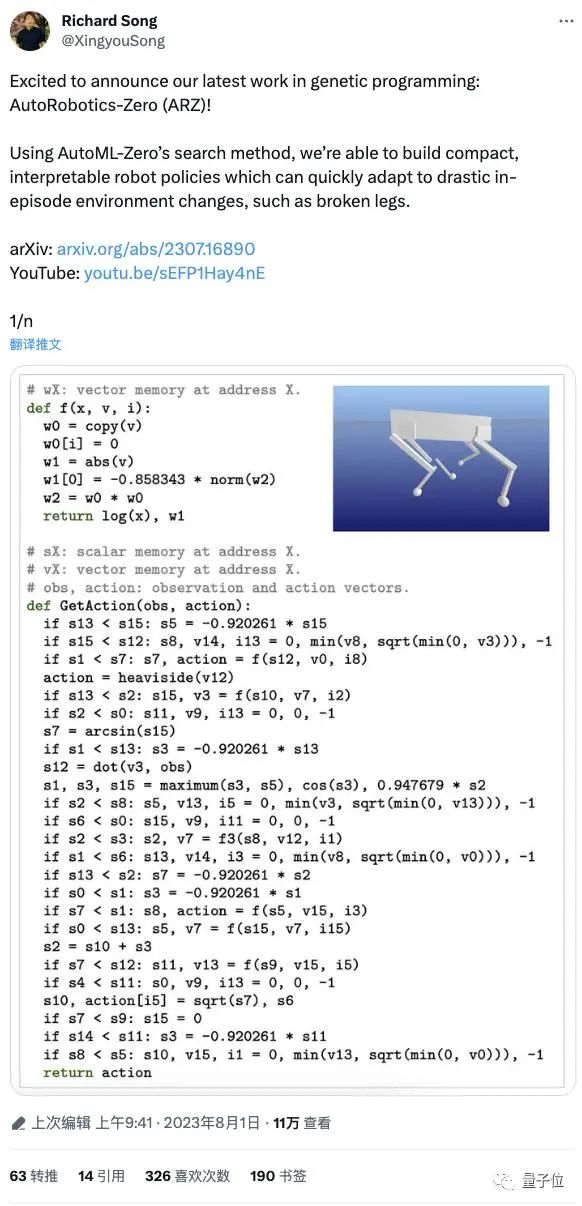
随着不断的进化,该方法能够发现控制程序(即Python代码,如下图所示),从而在与环境互动的同时,利用感觉运动经验来微调策略参数或改变控制逻辑(也就是当随机分支在随机时间突然中断时运行新的分支)。最终就可以在不断变化的环境下实现自适应。

具体而言,ARZ的算法由两个核心函数组成:StartEpisode()和GetAction(),前者在机器人与环境交互的每个阶段开始时就开始运行,后者负责调整内存状态(因为策略被表示为作用于虚拟内存的线性寄存器)和代码修改。
在进化搜索上,ARZ则采用两种控制算法:负责多目标搜索的非支配排序遗传算法II(NSGA-II)和负责单目标搜索的正则化进化算法(RegEvo)。
如下图所示进化控制算法的评估过程,单目标进化搜索使用平均情节奖励作为算法的适应度,而多目标搜索优化了两个适应度指标:平均奖励(第一个返回值)和每次episode的平均步数(第二个返回值)。

以及作者介绍,为了预测动态环境中给定情况下的最佳行动,策略必须能够将当前情况与过去的情况和行动进行比较。
因此,ARZ所有策略都被设计为“有状态的”,即内存内容在一个事件的时间步长内是持续存在的,由此才得以完成自适应。
此外,有所不同的是,该方法还去掉了原始AutoML Zero技术中的监督学习模式,最终无需明确接收任何监督输入(如奖励信号)就可以让进化程序在整个生命周期内进行调整。
比神经网络更有效
作者用宇树科技的“莱卡狗”(Laikago)四足机器人vwin 器在模拟环境中进行了效果测试。
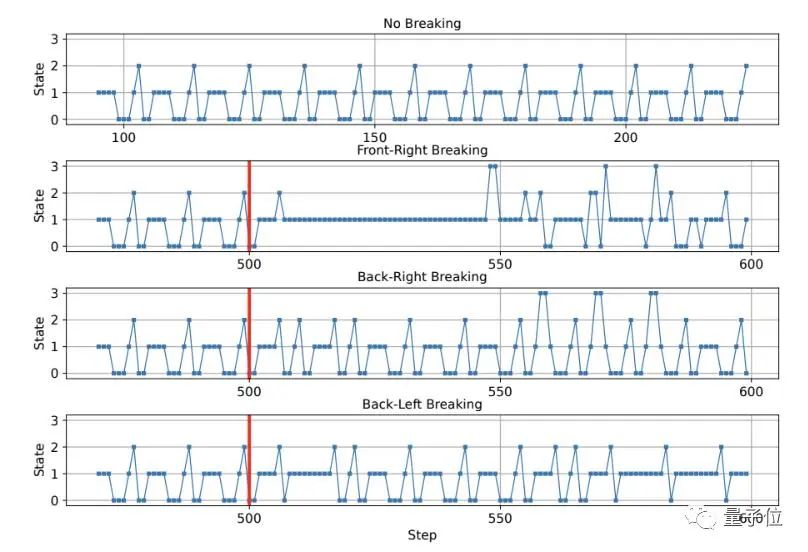
最终,只有ARZ可以进化出在随机断腿情况下保持向前运动和避免摔倒的自适应策略。

相比之下,进行了全面超参数调整并使用最先进强化学习方法完成训练的MLP和LSTM基线都失败了:
要么不具有鲁棒性,不能每次都成功;

要么一次都没有成功过。

需要注意的,这还是在ARZ使用的参数和FLOPS比MLP和LSTM都少得多的情况下。
下图则是统计数据:只要任何一列中的reward<400就表示该腿的大多数测试都以摔倒告终。
我们可以再次看到,除了ARZ,只有MLP方法能够在右后腿成功一次。

除了以上这些,ARZ还显现出了目前的RNN技术都做不到的可解释性。
如图所示,它在断腿案例中发现的各种策略可以都符号化为如下表示:
最后,除了机器人断腿走路,ARZ还可以在“具有随机倾斜轨道的cartpole系统”中自动保持平衡。

论文地址:
https://arxiv.org/abs/2307.16890
— 完 —
-
机器人
+关注
关注
211文章
28379浏览量
206906 -
神经网络
+关注
关注
42文章
4771浏览量
100707 -
大模型
+关注
关注
2文章
2423浏览量
2637
原文标题:机器人也不怕被忽悠瘸了
文章出处:【微信号:tjrobot,微信公众号:天津机器人】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论