 NVIDIA CPU+GPU超级芯片大升级!
NVIDIA CPU+GPU超级芯片大升级!
NVIDIA官方宣布了新一代GH200 Grace Hopper超级芯片平台,全球首发采用HBM3e高带宽内存,可满足世界上最复杂的生成式AI负载需求。
NVIDIA 2022年3月推出了Grace Hopper超级芯片,首次将CPU、GPU融合在一块主板上,不过直到今年5月份才量产。
其中,Grace CPU拥有72个Armv9 CPU核心、198MB缓存,支持1TB/s高带宽的LPDDR5X ECC内存,还支持PCIe 5.0。
Hopper GPU则采用台积电4nm定制工艺,800亿晶体管,集成18432个CUDA核心、576个Tenor核心、60MB二级缓存,支持6144-bit HBM高带宽内存,此前版本配备的是96GB HBM3。
双路配置的系统中,两颗新一代GH200超级芯片可带来144个CPU核心、8PFlops(8千万亿次浮点计算每秒) AI性能、282GB HBM3e内存,容量是现在的3.5倍,而高达10TB/s的带宽也是现在的3倍。
基于NVLink高速总线,GH200超级芯片还可以继续拓展互连,GPU可以访问全部的CPU内存,双路配置下总容量可达1.2TB。
NVIDIA没有透露采用的HBM3e来自哪家供应商,很可能是SK海力士。
首批基于GH200超级芯片的系统将在2024年第二季度出货。
顺带一提,AMD Instinct MI300A、MI300X AI加速器分别配备128GB、192GB HBM3,后者带宽超过5TB/s。
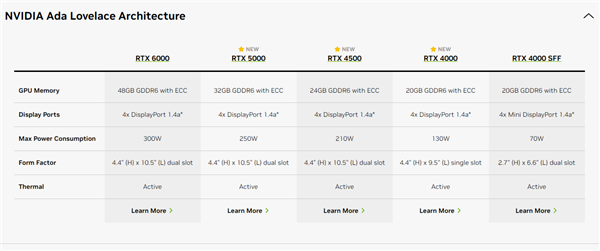
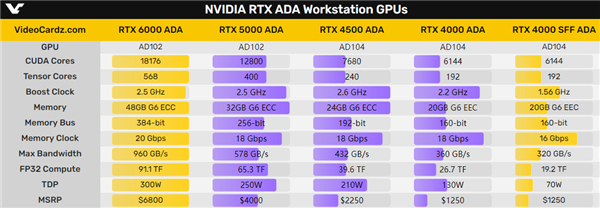
NVIDIA Ada Lovelace架构在桌面、笔记本游戏卡上已经布局完毕,如今在工作站上也圆满了。
今天,NVIDIA正式发布了RTX 5000 ADA、RTX 4500 ADA、RTX 4000 ADA三款新专业卡,加上此前的旗舰级RTX 6000 ADA、半高式RTX 4000 SFF ADA,高中低端都齐了。
RTX 6000 ADA旗舰卡为双插槽、单涡轮风扇设计,满血的AD102 GPU核心,配备18176个CUDA核心、568个Tensor核心,核心加速频率可达2.5GHz。
显存搭档384-bit 48GB GDDR6 ECC,等效频率20GHz,带宽为960GB/s,整卡功耗300W,四个DP 1.4a接口。
FP32浮点性能91.1TFlops(每秒91.1万亿次),价格高达6800美元,约合人民币4.90万元。
RTX 5000 ADA延续了老大哥的造型、AD102核心,精简到12800个CUDA核心、400个Tensor核心。
显存也砍到256-bit 32GB,频率18GHz,带宽降至578GB/s,功耗也来到250W。
浮点性能65.3TFlops,相当于旗舰卡的约72%,价格4000美元,约合人民币2.88元。
RTX 4500 ADA外观依然不变,但内部改成了AD104核心(跳过AD103),7680个CUDA核心、240个Tensor核心的规模与RTX 4070 Ti完全一致。
核心频率是全系列最高的2.6GHz,显存是192-bit 24GB GDDR6 ECC,频率18GHz,带宽432GB/s。
浮点性能39.6TFlops,价格2250美元,约合人民币1.62万元。
RTX 4000 ADA改成了单插槽设计,还是单个涡轮风扇,AD104核心,6144个CUDA核心、192个Tensor核心、160-bit 20GB GDDR6显存,接口四个mini DP 1.4a,这些都和SFF半完全一致。
不过核心频率从1.56GHz大幅提高到2.2GHz,显存频率也从16GHz提高到18GHz,浮点性能来到了26.7TFlops,功耗也从70W大幅增至130W。
价格倒是没变,还是1250美元,约合人民币9000元。
Boxx、戴尔、Lamdda、联想、惠普等将从今年秋天开始陆续推出搭载新卡的工作站,甚至有的会配备四块RTX 6000 ADA,总显存多达192GB。
审核编辑:刘清
-
晶体管
+关注
关注
77文章
9682浏览量
138079 -
缓存器
+关注
关注
0文章
63浏览量
11658 -
PCIe接口
+关注
关注
0文章
120浏览量
9702 -
GPU芯片
+关注
关注
1文章
303浏览量
5804 -
NVIDIA显卡
+关注
关注
0文章
15浏览量
3149
原文标题:NVIDIA CPU+GPU超级芯片大升级!史无前例282GB内存
文章出处:【微信号:hdworld16,微信公众号:硬件世界】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
NVIDIA 以太网加速 xAI 构建的全球最大 AI 超级计算机

【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】--全书概览
名单公布!【书籍评测活动NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架构分析
NVIDIA GB200超级芯片引领液冷散热新纪元
NVIDIA GB200 CPU+GPU超级芯片功耗达2700W
超级猛兽 GPU ?NVIDIA GeForce RTX 5090 基本频率接近 2.9 GHz

CPU渲染和GPU渲染优劣分析

进一步解读英伟达 Blackwell 架构、NVlink及GB200 超级芯片
利用NVIDIA组件提升GPU推理的吞吐
AI服务器异构计算深度解读

NVIDIA推出搭载GB200 Grace Blackwell超级芯片的NVIDIA DGX SuperPOD™
NVIDIA 推出 Blackwell 架构 DGX SuperPOD,适用于万亿参数级的生成式 AI 超级计算

深度解读Nvidia AI芯片路线图

Nvidia与AMD新芯片,突破PCIe瓶颈
为什么GPU比CPU更快?





 工商网监
工商网监
评论