 JVM运行时数据区之堆内存
JVM运行时数据区之堆内存
阅读前思考
说一下 JVM 运行时数据区吧,都有哪些区?分别是干什么的?
Java8 的内存分代改进
举例栈溢出的情况?
调整栈大小,就能保存不出现溢出吗?
分配的栈内存越大越好吗?
垃圾回收是否会涉及到虚拟机栈?
方法中定义的局部变量是否线程安全?
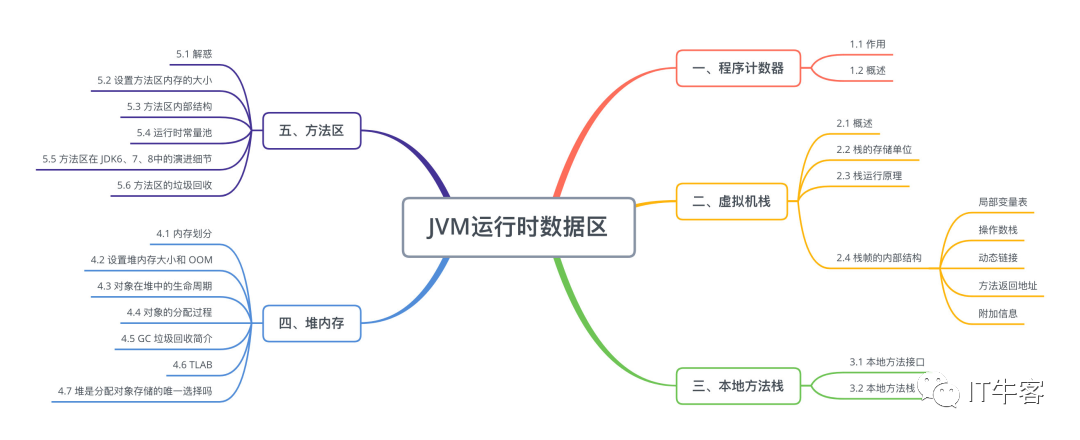
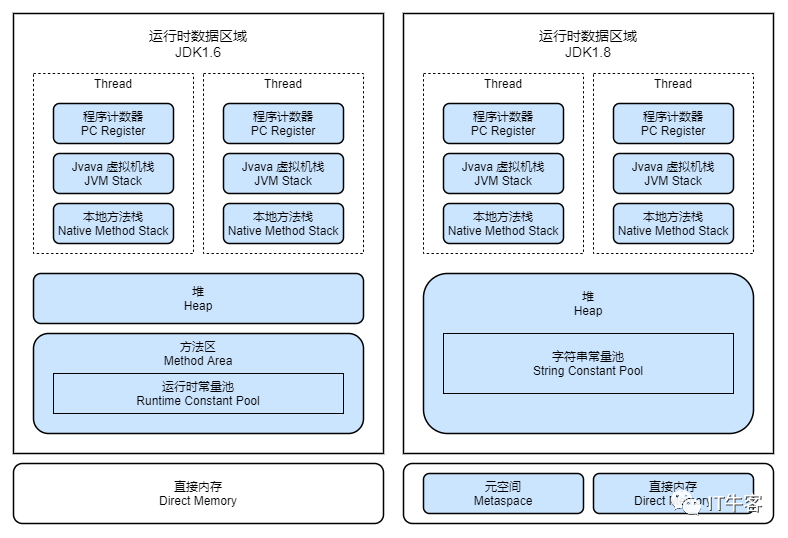
运行时数据区
内存是非常重要的系统资源,是硬盘和CPU的中间仓库及桥梁,承载着操作系统和应用程序的实时运行。JVM 内存布局规定了 Java 在运行过程中内存申请、分配、管理的策略,保证了 JVM 的高效稳定运行。不同的 JVM 对于内存的划分方式和管理机制存在着部分差异。
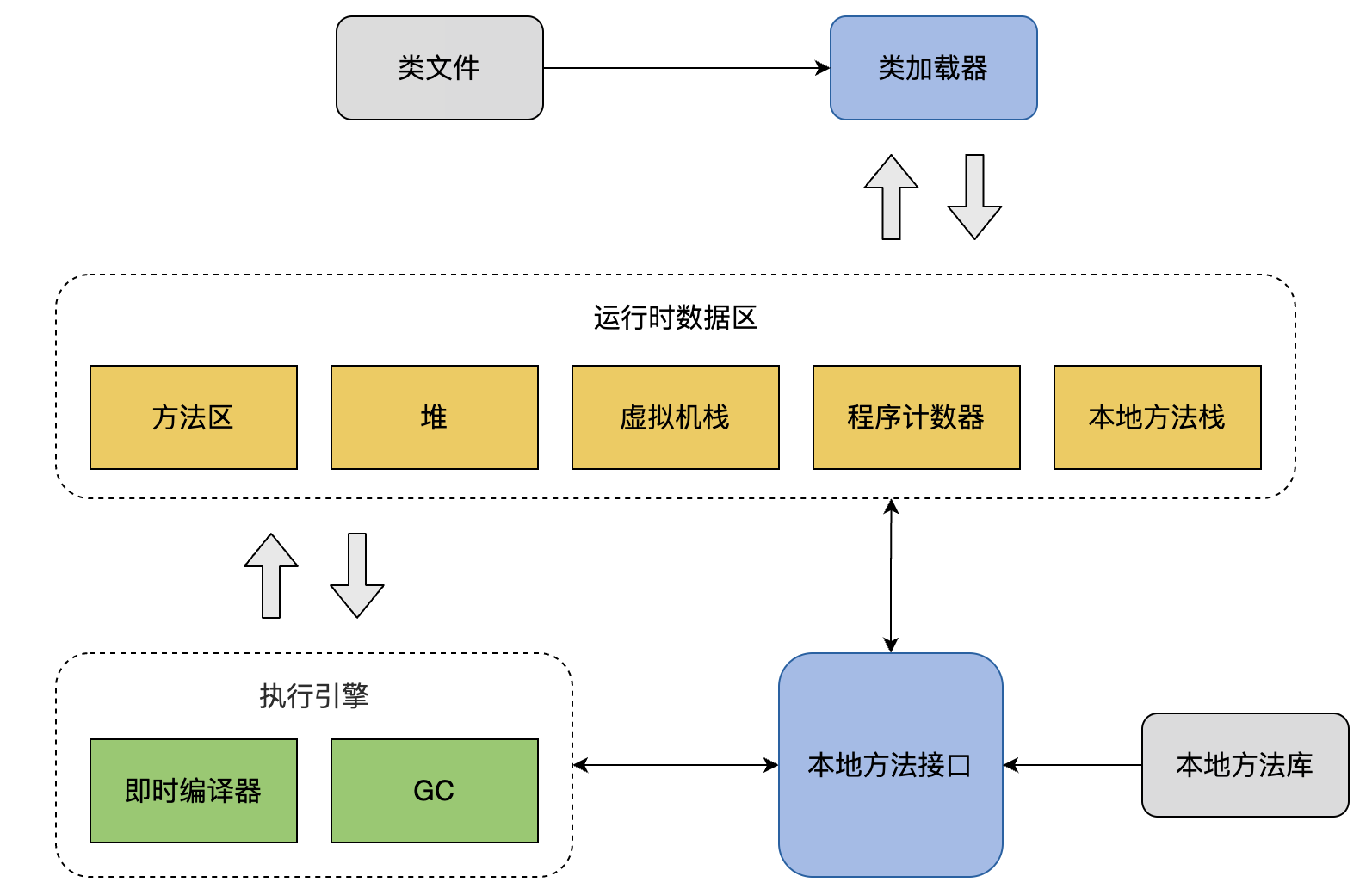
下图是 JVM 整体架构,中间部分就是 Java 虚拟机定义的各种运行时数据区域。
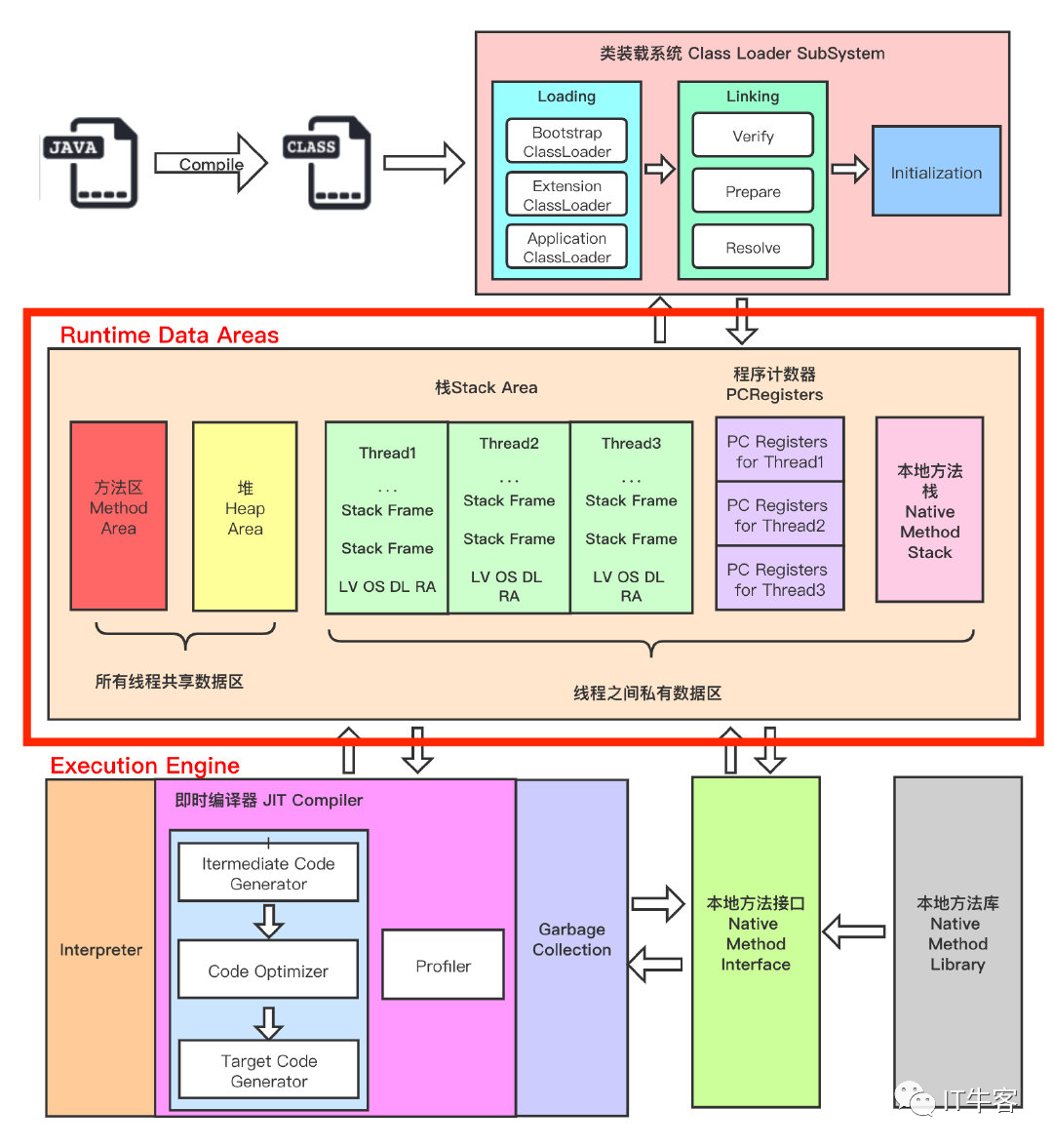
Java 虚拟机定义了若干种程序运行期间会使用到的运行时数据区,其中有一些会随着虚拟机启动而创建,随着虚拟机退出而销毁。另外一些则是与线程一一对应的,这些与线程一一对应的数据区域会随着线程开始和结束而创建和销毁。
线程私有:程序计数器、栈、本地栈
线程共享:堆、堆外内存(永久代或元空间、代码缓存)
四、堆内存
内存划分
对于大多数应用,Java 堆是 Java 虚拟机管理的内存中最大的一块,被所有线程共享。此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例以及数据都在这里分配内存。
为了进行高效的垃圾回收,虚拟机把堆内存逻辑上划分成三块区域(分代的唯一理由就是优化 GC 性能):
新生带(年轻代):新对象和没达到一定年龄的对象都在新生代
老年代(养老区):被长时间使用的对象,老年代的内存空间应该要比年轻代更大
元空间(JDK1.8 之前叫永久代):像一些方法中的操作临时对象等,JDK1.8 之前是占用 JVM 内存,JDK1.8 之后直接使用物理内存
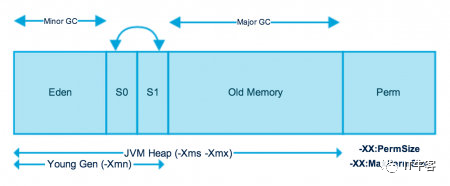
Java 虚拟机规范规定,Java 堆可以是处于物理上不连续的内存空间中,只要逻辑上是连续的即可,像磁盘空间一样。实现时,既可以是固定大小,也可以是可扩展的,主流虚拟机都是可扩展的(通过-Xmx和-Xms控制),如果堆中没有完成实例分配,并且堆无法再扩展时,就会抛出OutOfMemoryError异常。
年轻代 (Young Generation)
年轻代是所有新对象创建的地方。当填充年轻代时,执行垃圾收集。这种垃圾收集称为Minor GC。年轻一代被分为三个部分——伊甸园(Eden Memory)和两个幸存区(Survivor Memory,被称为from/to或s0/s1),默认比例是81
大多数新创建的对象都位于 Eden 内存空间中
当 Eden 空间被对象填充时,执行Minor GC,并将所有幸存者对象移动到一个幸存者空间中
Minor GC 检查幸存者对象,并将它们移动到另一个幸存者空间。所以每次,一个幸存者空间总是空的
经过多次 GC 循环后存活下来的对象被移动到老年代。通常,这是通过设置年轻一代对象的年龄阈值来实现的,然后他们才有资格提升到老一代
老年代(Old Generation)
旧的一代内存包含那些经过许多轮小型 GC 后仍然存活的对象。通常,垃圾收集是在老年代内存满时执行的。老年代垃圾收集称为 主GC(Major GC),通常需要更长的时间。
大对象直接进入老年代(大对象是指需要大量连续内存空间的对象)。这样做的目的是避免在 Eden 区和两个Survivor 区之间发生大量的内存拷贝
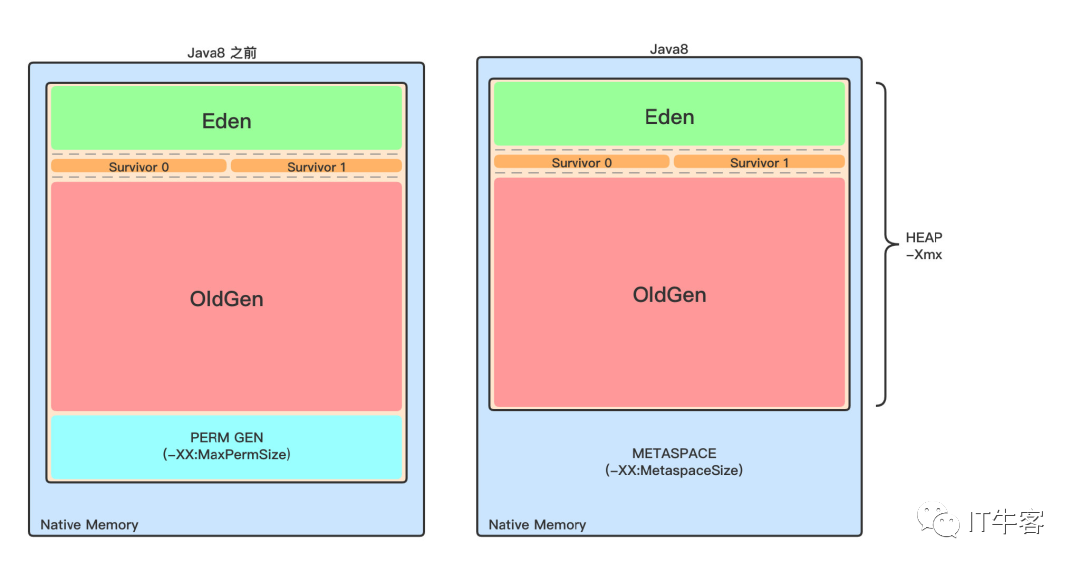
元空间
不管是 JDK8 之前的永久代,还是 JDK8 及以后的元空间,都可以看作是 Java 虚拟机规范中方法区的实现。
虽然 Java 虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫 Non-Heap(非堆),目的应该是与 Java 堆区分开。
所以元空间放在后边的方法区再说。
设置堆内存大小和 OOM
Java 堆用于存储 Java 对象实例,那么堆的大小在 JVM 启动的时候就确定了,我们可以通过-Xmx和-Xms来设定
-Xmx用来表示堆的起始内存,等价于-XX:InitialHeapSize
-Xms用来表示堆的最大内存,等价于-XX:MaxHeapSize
如果堆的内存大小超过-Xms设定的最大内存, 就会抛出OutOfMemoryError异常。
我们通常会将-Xmx和-Xms两个参数配置为相同的值,其目的是为了能够在垃圾回收机制清理完堆区后不再需要重新分隔计算堆的大小,从而提高性能
默认情况下,初始堆内存大小为:电脑内存大小/64
默认情况下,最大堆内存大小为:电脑内存大小/4
可以通过代码获取到我们的设置值,当然也可以vwin OOM:
publicstatic void main(String[] args) { //返回 JVM 堆大小 long initalMemory = Runtime.getRuntime().totalMemory() / 1024 /1024; //返回 JVM 堆的最大内存 long maxMemory = Runtime.getRuntime().maxMemory() / 1024 /1024; System.out.println("-Xms : "+initalMemory + "M"); System.out.println("-Xmx : "+maxMemory + "M"); System.out.println("系统内存大小:" + initalMemory * 64 / 1024 + "G"); System.out.println("系统内存大小:" + maxMemory * 4 / 1024 + "G"); }
查看 JVM 堆内存分配
在默认不配置 JVM 堆内存大小的情况下,JVM 根据默认值来配置当前内存大小
默认情况下新生代和老年代的比例是 1:2,可以通过–XX:NewRatio来配置
新生代中的Eden:From Survivor:To Survivor的比例是81,可以通过-XX:SurvivorRatio来配置
若在 JDK 7 中开启了-XX:+UseAdaptiveSizePolicy,JVM 会动态调整 JVM 堆中各个区域的大小以及进入老年代的年龄
此时–XX:NewRatio和-XX:SurvivorRatio将会失效,而 JDK 8 是默认开启-XX:+UseAdaptiveSizePolicy
在 JDK 8中,不要随意关闭-XX:+UseAdaptiveSizePolicy,除非对堆内存的划分有明确的规划
每次 GC 后都会重新计算 Eden、From Survivor、To Survivor 的大小
计算依据是GC过程中统计的GC时间、吞吐量、内存占用量
java -XX:+PrintFlagsFinal -version | grep HeapSize uintx ErgoHeapSizeLimit = 0 {product} uintx HeapSizePerGCThread = 87241520 {product} uintx InitialHeapSize := 134217728 {product} uintx LargePageHeapSizeThreshold = 134217728 {product} uintx MaxHeapSize := 2147483648 {product} java version "1.8.0_211" Java(TM) SE Runtime Environment (build 1.8.0_211-b12) Java HotSpot(TM) 64-Bit Server VM (build 25.211-b12, mixed mode)
jmap -heap 进程号
对象在堆中的生命周期
在 JVM 内存模型的堆中,堆被划分为新生代和老年代
新生代又被进一步划分为Eden区和Survivor区,Survivor 区由From Survivor和To Survivor组成
当创建一个对象时,对象会被优先分配到新生代的 Eden 区
此时 JVM 会给对象定义一个对象年轻计数器(-XX:MaxTenuringThreshold)
当 Eden 空间不足时,JVM 将执行新生代的垃圾回收(Minor GC)
JVM 会把存活的对象转移到 Survivor 中,并且对象年龄 +1
对象在 Survivor 中同样也会经历 Minor GC,每经历一次 Minor GC,对象年龄都会+1
如果分配的对象超过了-XX:PetenureSizeThreshold,对象会直接被分配到老年代
对象的分配过程
为对象分配内存是一件非常严谨和复杂的任务,JVM 的设计者们不仅需要考虑内存如何分配、在哪里分配等问题,并且由于内存分配算法和内存回收算法密切相关,所以还需要考虑 GC 执行完内存回收后是否会在内存空间中产生内存碎片。
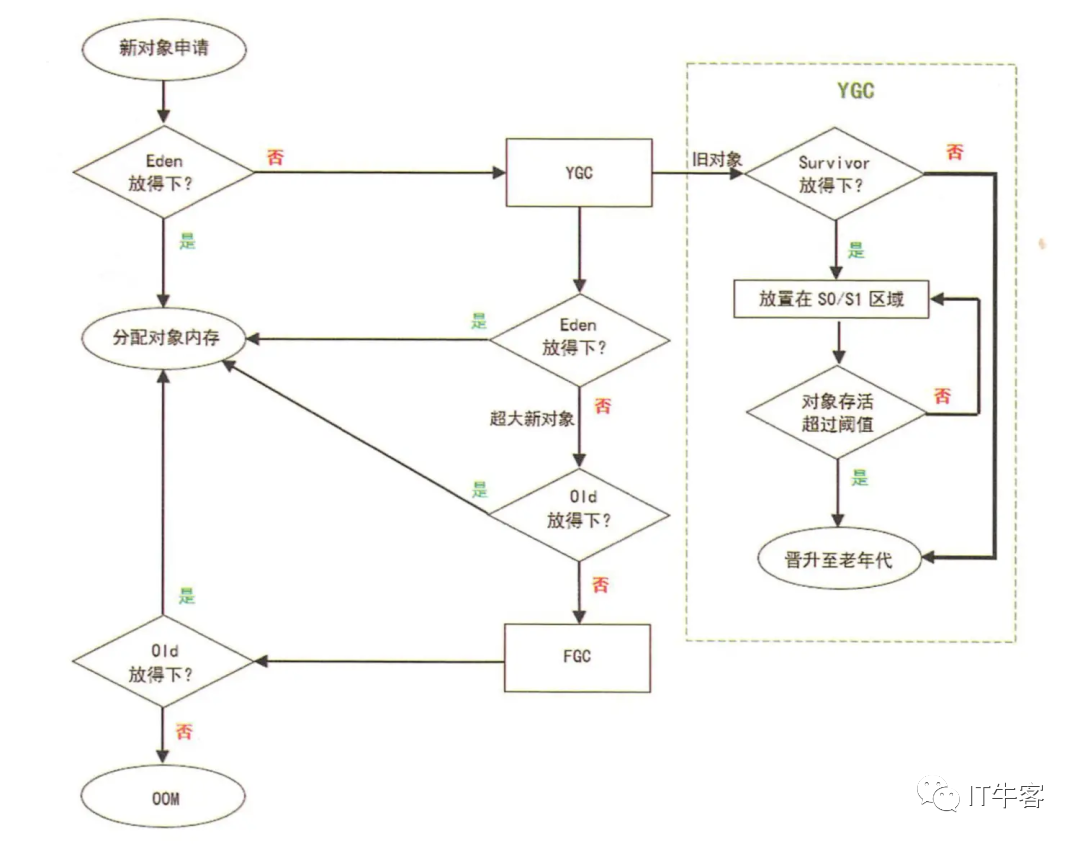
new 的对象先放在伊甸园区,此区有大小限制
当伊甸园的空间填满时,程序又需要创建对象,JVM 的垃圾回收器将对伊甸园区进行垃圾回收(Minor GC),将伊甸园区中的不再被其他对象所引用的对象进行销毁。再加载新的对象放到伊甸园区
然后将伊甸园中的剩余对象移动到幸存者 0 区
如果再次触发垃圾回收,此时上次幸存下来的放到幸存者 0 区,如果没有回收,就会放到幸存者 1 区
如果再次经历垃圾回收,此时会重新放回幸存者 0 区,接着再去幸存者 1 区
什么时候才会去养老区呢?默认是 15 次回收标记
在养老区,相对悠闲。当养老区内存不足时,再次触发 Major GC,进行养老区的内存清理
若养老区执行了 Major GC 之后发现依然无法进行对象的保存,就会产生 OOM 异常
GC 垃圾回收简介
Minor GC、Major GC、Full GC
JVM 在进行 GC 时,并非每次都对堆内存(新生代、老年代;方法区)区域一起回收的,大部分时候回收的都是指新生代。
针对 HotSpot VM 的实现,它里面的 GC 按照回收区域又分为两大类:部分收集(Partial GC),整堆收集(Full GC)
部分收集:不是完整收集整个 Java 堆的垃圾收集。其中又分为:
目前只有 G1 GC 会有这种行为
目前,只有 CMS GC 会有单独收集老年代的行为
很多时候 Major GC 会和 Full GC 混合使用,需要具体分辨是老年代回收还是整堆回收
新生代收集(Minor GC/Young GC):只是新生代的垃圾收集
老年代收集(Major GC/Old GC):只是老年代的垃圾收集
混合收集(Mixed GC):收集整个新生代以及部分老年代的垃圾收集
整堆收集(Full GC):收集整个 Java 堆和方法区的垃圾
TLAB
什么是 TLAB (Thread Local Allocation Buffer)?
从内存模型而不是垃圾回收的角度,对 Eden 区域继续进行划分,JVM 为每个线程分配了一个私有缓存区域,它包含在 Eden 空间内
多线程同时分配内存时,使用 TLAB 可以避免一系列的非线程安全问题,同时还能提升内存分配的吞吐量,因此我们可以将这种内存分配方式称为快速分配策略
OpenJDK 衍生出来的 JVM 大都提供了 TLAB 设计
为什么要有 TLAB ?
堆区是线程共享的,任何线程都可以访问到堆区中的共享数据
由于对象实例的创建在 JVM 中非常频繁,因此在并发环境下从堆区中划分内存空间是线程不安全的
为避免多个线程操作同一地址,需要使用加锁等机制,进而影响分配速度
尽管不是所有的对象实例都能够在 TLAB 中成功分配内存,但 JVM 确实是将 TLAB 作为内存分配的首选。
在程序中,可以通过-XX:UseTLAB设置是否开启 TLAB 空间。
默认情况下,TLAB 空间的内存非常小,仅占有整个 Eden 空间的 1%,我们可以通过-XX:TLABWasteTargetPercent设置 TLAB 空间所占用 Eden 空间的百分比大小。
一旦对象在 TLAB 空间分配内存失败时,JVM 就会尝试着通过使用加锁机制确保数据操作的原子性,从而直接在 Eden 空间中分配内存。
堆是分配对象存储的唯一选择吗
随着 JIT 编译期的发展和逃逸分析技术的逐渐成熟,栈上分配、标量替换优化技术将会导致一些微妙的变化,所有的对象都分配到堆上也渐渐变得不那么“绝对”了。——《深入理解 Java 虚拟机》
逃逸分析
逃逸分析(Escape Analysis)是目前 Java 虚拟机中比较前沿的优化技术。这是一种可以有效减少 Java 程序中同步负载和内存堆分配压力的跨函数全局数据流分析算法。通过逃逸分析,Java Hotspot 编译器能够分析出一个新的对象的引用的使用范围从而决定是否要将这个对象分配到堆上。
逃逸分析的基本行为就是分析对象动态作用域:
当一个对象在方法中被定义后,对象只在方法内部使用,则认为没有发生逃逸。
当一个对象在方法中被定义后,它被外部方法所引用,则认为发生逃逸。例如作为调用参数传递到其他地方中,称为方法逃逸。
例如:
public static StringBuffer craeteStringBuffer(String s1, String s2) { StringBuffer sb = new StringBuffer(); sb.append(s1); sb.append(s2); return sb; }
StringBuffer sb是一个方法内部变量,上述代码中直接将sb返回,这样这个 StringBuffer 有可能被其他方法所改变,这样它的作用域就不只是在方法内部,虽然它是一个局部变量,称其逃逸到了方法外部。甚至还有可能被外部线程访问到,譬如赋值给类变量或可以在其他线程中访问的实例变量,称为线程逃逸。
上述代码如果想要StringBuffer sb不逃出方法,可以这样写:
public static String createStringBuffer(String s1, String s2) { StringBuffer sb = new StringBuffer(); sb.append(s1); sb.append(s2); return sb.toString(); }
不直接返回 StringBuffer,那么 StringBuffer 将不会逃逸出方法。
参数设置:
在 JDK 6u23 版本之后,HotSpot 中默认就已经开启了逃逸分析
如果使用较早版本,可以通过-XX"+DoEscapeAnalysis显式开启
开发中使用局部变量,就不要在方法外定义。
使用逃逸分析,编译器可以对代码做优化:
栈上分配:将堆分配转化为栈分配。如果一个对象在子程序中被分配,要使指向该对象的指针永远不会逃逸,对象可能是栈分配的候选,而不是堆分配
同步省略:如果一个对象被发现只能从一个线程被访问到,那么对于这个对象的操作可以不考虑同步
分离对象或标量替换:有的对象可能不需要作为一个连续的内存结构存在也可以被访问到,那么对象的部分(或全部)可以不存储在内存,而存储在 CPU寄存器
JIT 编译器在编译期间根据逃逸分析的结果,发现如果一个对象并没有逃逸出方法的话,就可能被优化成栈上分配。分配完成后,继续在调用栈内执行,最后线程结束,栈空间被回收,局部变量对象也被回收。这样就无需进行垃圾回收了。
常见栈上分配的场景:成员变量赋值、方法返回值、实例引用传递
代码优化之同步省略(消除)
线程同步的代价是相当高的,同步的后果是降低并发性和性能
在动态编译同步块的时候,JIT 编译器可以借助逃逸分析来判断同步块所使用的锁对象是否能够被一个线程访问而没有被发布到其他线程。如果没有,那么 JIT 编译器在编译这个同步块的时候就会取消对这个代码的同步。这样就能大大提高并发性和性能。这个取消同步的过程就叫做同步省略,也叫锁消除。
public void keep() { Object keeper = new Object(); synchronized(keeper) { System.out.println(keeper); } }
如上代码,代码中对 keeper 这个对象进行加锁,但是 keeper 对象的生命周期只在keep()方法中,并不会被其他线程所访问到,所以在 JIT编译阶段就会被优化掉。优化成:
public void keep() { Object keeper = new Object(); System.out.println(keeper); }
代码优化之标量替换
标量(Scalar)是指一个无法再分解成更小的数据的数据。Java 中的原始数据类型就是标量。
相对的,那些的还可以分解的数据叫做聚合量(Aggregate),Java 中的对象就是聚合量,因为其还可以分解成其他聚合量和标量。
在 JIT 阶段,通过逃逸分析确定该对象不会被外部访问,并且对象可以被进一步分解时,JVM 不会创建该对象,而会将该对象成员变量分解若干个被这个方法使用的成员变量所代替。这些代替的成员变量在栈帧或寄存器上分配空间。这个过程就是标量替换。
通过-XX:+EliminateAllocations可以开启标量替换,-XX:+PrintEliminateAllocations查看标量替换情况。
public static void main(String[] args) { alloc(); } private static void alloc() { Point point = new Point(1,2); System.out.println("point.x="+point.x+"; point.y="+point.y); } class Point{ private int x; private int y; }
以上代码中,point 对象并没有逃逸出alloc()方法,并且 point 对象是可以拆解成标量的。那么,JIT 就不会直接创建 Point 对象,而是直接使用两个标量 int x ,int y 来替代 Point 对象。
private static void alloc() { int x = 1; int y = 2; System.out.println("point.x="+x+"; point.y="+y); }
代码优化之栈上分配
我们通过 JVM 内存分配可以知道 JAVA 中的对象都是在堆上进行分配,当对象没有被引用的时候,需要依靠 GC 进行回收内存,如果对象数量较多的时候,会给 GC 带来较大压力,也间接影响了应用的性能。为了减少临时对象在堆内分配的数量,JVM 通过逃逸分析确定该对象不会被外部访问。那就通过标量替换将该对象分解在栈上分配内存,这样该对象所占用的内存空间就可以随栈帧出栈而销毁,就减轻了垃圾回收的压力。
总结:
关于逃逸分析的论文在1999年就已经发表了,但直到JDK 1.6才有实现,而且这项技术到如今也并不是十分成熟的。
其根本原因就是无法保证逃逸分析的性能消耗一定能高于他的消耗。虽然经过逃逸分析可以做标量替换、栈上分配、和锁消除。但是逃逸分析自身也是需要进行一系列复杂的分析的,这其实也是一个相对耗时的过程。
一个极端的例子,就是经过逃逸分析之后,发现没有一个对象是不逃逸的。那这个逃逸分析的过程就白白浪费掉了。
虽然这项技术并不十分成熟,但是他也是即时编译器优化技术中一个十分重要的手段。
审核编辑:汤梓红
- cpu
+关注
关注
68文章
10645浏览量
208770 - 内存
+关注
关注
8文章
2857浏览量
73375 - JVM
+关注
关注
0文章
155浏览量
12166 - 虚拟机
+关注
关注
1文章
881浏览量
27734 - 线程
+关注
关注
0文章
500浏览量
19572
原文标题:运行时数据区
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先登录
相关推荐
Java内存模型及原理分析
jvm内存溢出故障排查
jvm内存模型和内存结构
jvm哪些区域会发生oom
jvm运行时内存区域划分
jvm管理的内存包括哪几个运行时数据内存
jvm内存区域由哪几部分组成
jvm内存区域中,哪一块是属于线程共享
jvm配置堆内存初始值参数
weblogicjvm参数配置
weblogic设置jvm内存大小
eclipse设置jvm内存大小
从原理聊JVM(一):染色标记和垃圾回收算法





 工商网监
工商网监
评论