 从原理到代码理解语言模型训练和推理,通俗易懂,快速修炼LLM
从原理到代码理解语言模型训练和推理,通俗易懂,快速修炼LLM
今天分享一篇博客,介绍语言模型的训练和推理,通俗易懂且抓住本质核心,强烈推荐阅读。
标题:Language Model Training and Inference: From Concept to Code
作者:CAMERON R. WOLFE
原文:
https://cameronrwolfe.substack.com/p/language-model-training-and-inference
要理解大语言模型(LLM),首先要理解它的本质,无论预训练、微调还是在推理阶段,核心都是next token prediction,也就是以自回归的方式从左到右逐步生成文本。
什么是token?
token是指文本中的一个词或者子词,给定一句文本,送入语言模型前首先要做的是对原始文本进行tokenize,也就是把一个文本序列拆分为离散的token序列
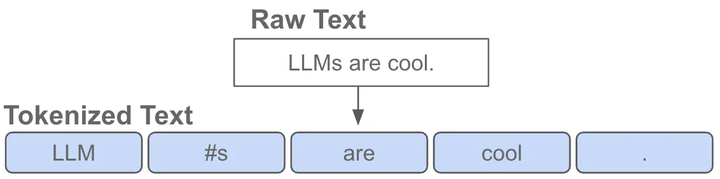
其中,tokenizer是在无标签的语料上训练得到的一个token数量固定且唯一的分词器,这里的token数量就是大家常说的词表,也就是语言模型知道的所有tokens。
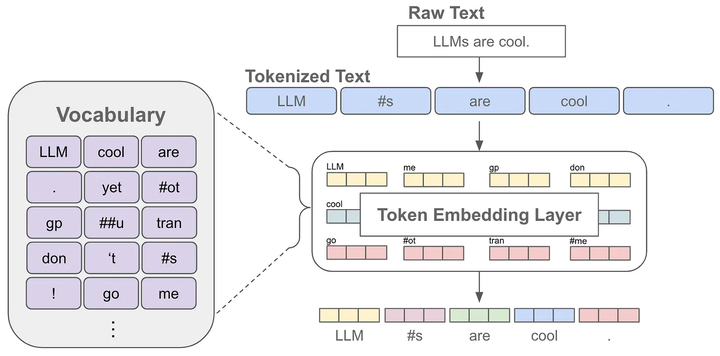
当我们对文本进行分词后,每个token可以对应一个embedding,这也就是语言模型中的embedding层,获得某个token的embedding就类似一个查表的过程
我们知道文本序列是有顺序的,而常见的语言模型都是基于注意力机制的transformer结构,无法自动考虑文本的前后顺序,因此需要手动加上位置编码,也就是每个位置有一个位置embedding,然后和对应位置的token embedding进行相加
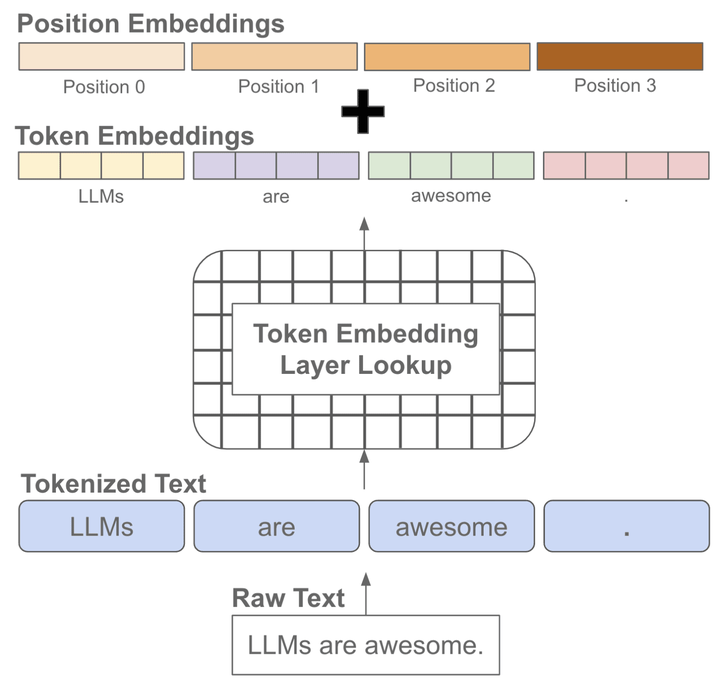
在模型训练或推理阶段大家经常会听到上下文长度这个词,它指的是模型训练时接收的token训练的最大长度,如果在训练阶段只学习了一个较短长度的位置embedding,那模型在推理阶段就不能够适用于较长文本(因为它没见过长文本的位置编码)
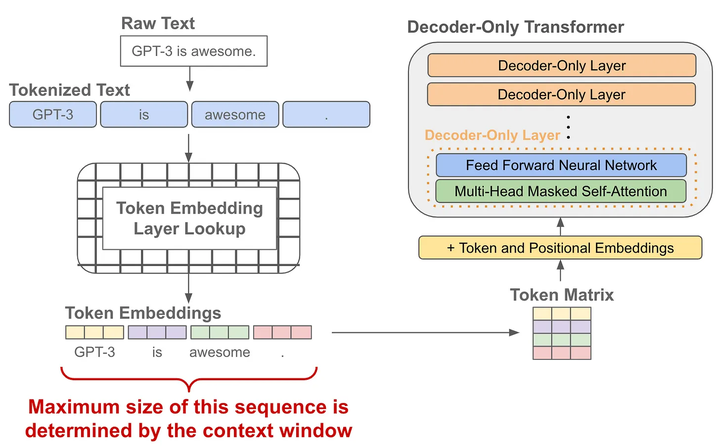
语言模型的预训练
当我们有了token embedding和位置embedding后,将它们送入一个decoder-only的transofrmer模型,它会在每个token的位置输出一个对应的embedding(可以理解为就像是做了个特征加工)
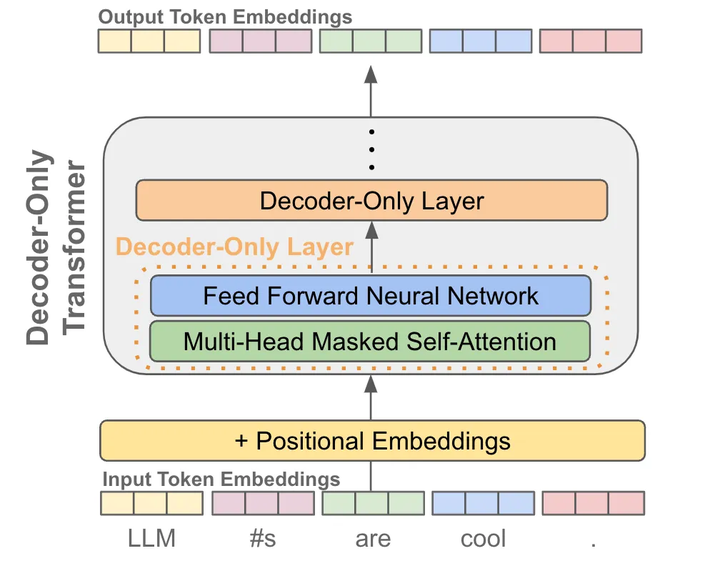
有了每个token的一个输出embedding后,我们就可以拿它来做next token prediction了,其实就是当作一个分类问题来看待:
首先我们把输出embedding送入一个线性层,输出的维度是词表的大小,就是让预测这个token的下一个token属于词表的“哪一类”
为了将输出概率归一化,需要再进行一个softmax变换
训练时就是最大化这个概率使得它能够预测真实的下一个token
推理时就是从这个概率分布中采样下一个token
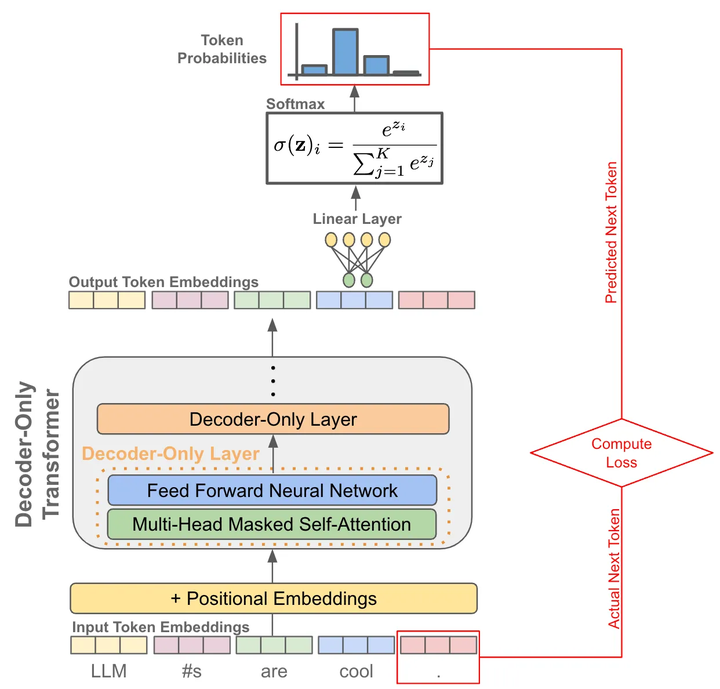
训练阶段:因为有causal自注意力的存在,我们可以一次性对一整个句子每个token进行下一个token的预测,并计算所有位置token的loss,因此只需要一forward
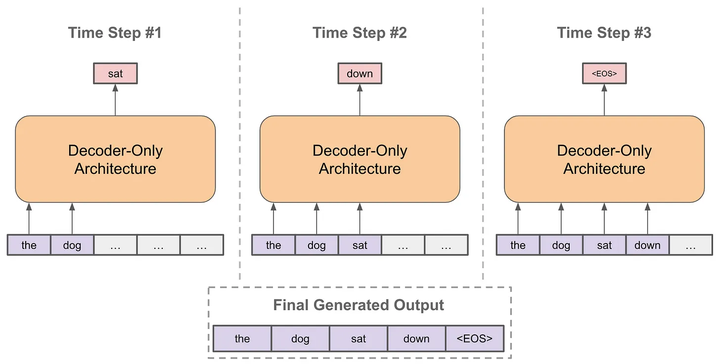
推理阶段:以自回归的方式进行预测
每次预测下一个token
将预测的token拼接到当前已经生成的句子上
再基于拼接后的句子进行预测下一个token
不断重复直到结束
其中,在预测下一个token时,每次我们都有一个概率分布用于采样,根据不同场景选择采样策略会略有不同,不然有贪婪策略、核采样、Top-k采样等,另外经常会看到Temperature这个概念,它是用来控制生成的随机性的,温度系数越小越稳定。
代码实现
下面代码来自项目https://github.com/karpathy/nanoGPT/tree/master,同样是一个很好的项目,推荐初学者可以看看。
对于各种基于Transformer的模型,它们都是由很多个Block堆起来的,每个Block主要有两个部分组成:
Multi-headed Causal Self-Attention
Feed-forward Neural Network结构的示意图如下:
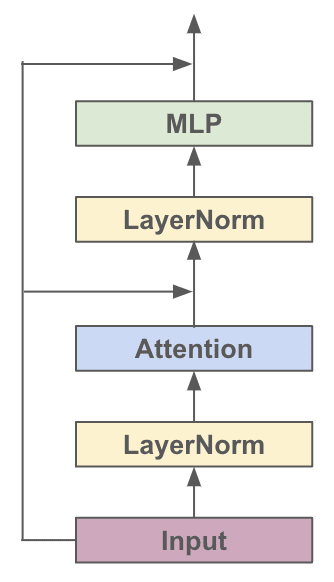
看图搭一下单个Block
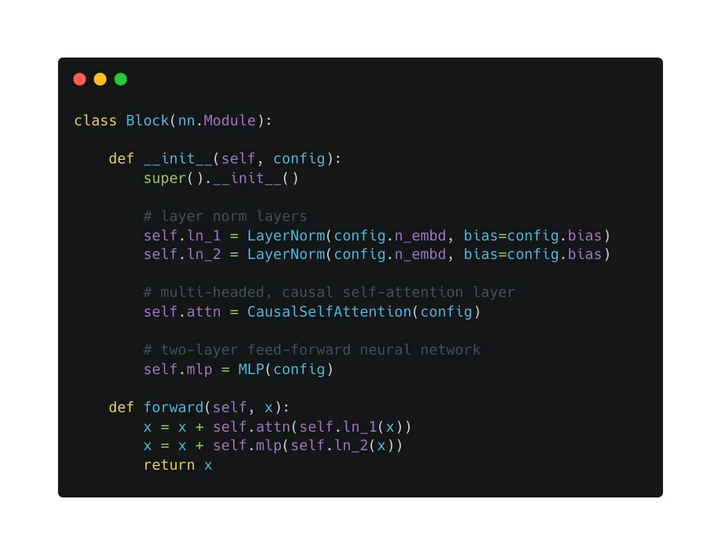
然后看下一整个GPT的结构
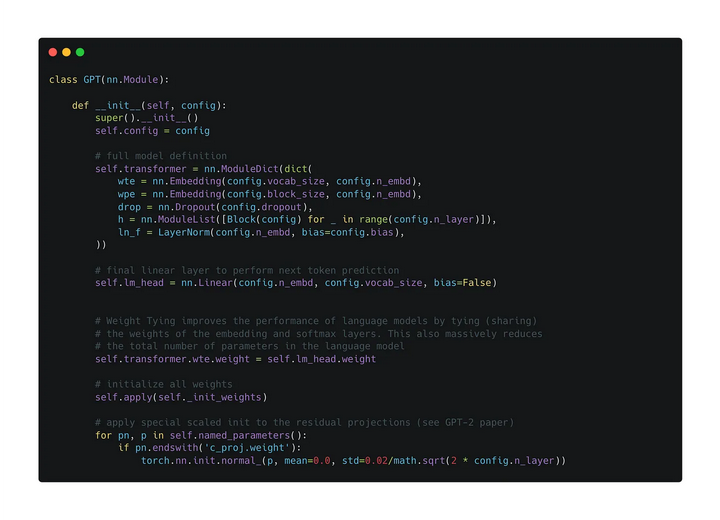
主要就是两个embedding层(token、位置)、多个block、一些额外的dropout和LayerNorm层,以及最后用来预测下一个token的线性层。说破了就是这么简单。
这边还用到了weight tying的技巧,就是最后一层用来分类的线性层的权重和token embedding层的权重共享。
接下来重点来关注一下训练和推理的forward是如何进行的,这能帮助大家更好的理解原理。
首先需要构建token embedding和位置embedding,把它们叠加起来后过一个dropout,然后就可以送入transformer的block中了。
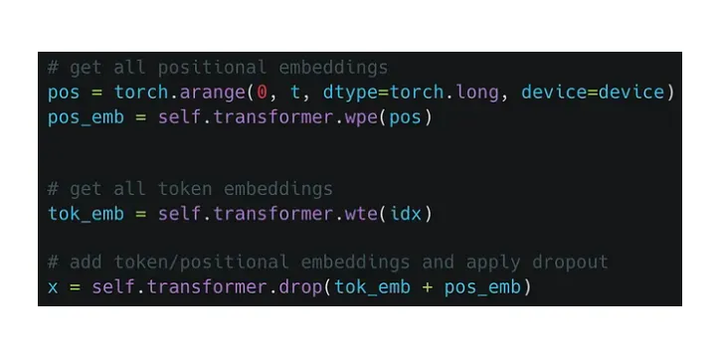
需要注意的是经过transforemr block后出来的tensor的维度跟之前是一样的。拿到每个token位置对应的输出embedding后,就可以通过最后的先行层进行分类,然后用交叉熵损失来进行优化。

再看一下完整的过程,其中只需要将输入左移一个位置就可以作为target了
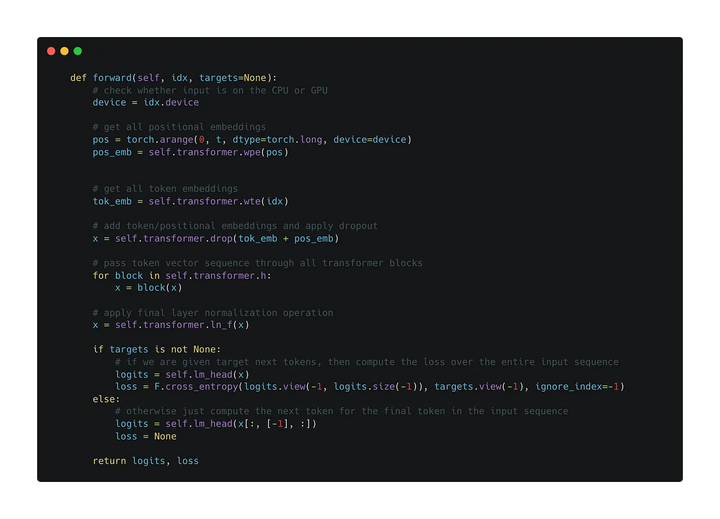
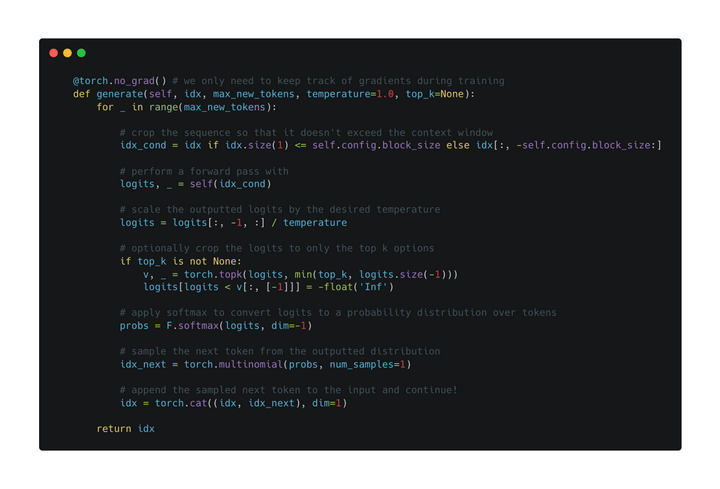
接下来看推理阶段:
根据当前输入序列进行一次前向传播
利用温度系数对输出概率分布进行调整
通过softmax进行归一化
从概率分布进行采样下一个token
拼接到当前句子并再进入下一轮循环
-
语言模型
+关注
关注
0文章
485浏览量
10193 -
LLM
+关注
关注
0文章
246浏览量
277
原文标题:从原理到代码理解语言模型训练和推理,通俗易懂,快速修炼LLM
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
通俗易懂的PID教程
通俗易懂之电子称开发导航篇

通俗易懂的讲解FFT的让你快速了解FFT
大型语言模型(LLM)的自定义训练:包含代码示例的详细指南
2023年大语言模型(LLM)全面调研:原理、进展、领跑者、挑战、趋势
大语言模型(LLM)快速理解






 工商网监
工商网监
评论