 数据库分区、分库和分表
数据库分区、分库和分表
今天先说说数据库的数据分区,分库以及分表的内容吧!
数据库分区、分库和分表
数据库分区、分库和分表是针对大型数据库系统的优化策略。它们的主要目的是提高数据库的性能和可靠性,以满足不断增长的数据存储需求。
数据库分区
将一个大型数据库分成多个逻辑部分,每个部分被称为一个分区。每个分区可以独立进行管理和维护,使得数据库系统的可扩展性和可用性得到了提高。
水平分区和垂直分区是数据库分区的两种主要方式,其主要存在如下的区别:
- 水平分区是将一个大表按照某个条件(如按照时间、地理位置等)分成多个小表,每个小表中包含相同的列,但是行数不同。在选择水平分区的分区键时,需要考虑数据的访问模式和数据的增长模式。例如按照时间分区可以提高历史数据的查询效率,按照地理位置分区可以提高地理数据的查询效率。水平分区的优点是可以提高数据的查询效率和并发处理能力,缺点是可能会导致数据的冗余和数据的一致性问题。
- 垂直分区是将一个大表按照列的不同将其分成多个小表,每个小表中包含相同的行,但是列数不同。选择垂直分区的分区键时,可将经常一起查询的列分到同一个分区中可以提高查询效率,将经常被更新的列分到单独的分区中也可以提高更新效率。垂直分区的优点是可以减少数据的冗余,提高数据的查询效率,也可能会导致数据的一致性问题。
水平分区栗子:
CREATE TABLE mytable (
id SERIAL PRIMARY KEY,
data TEXT,
created_at TIMESTAMP WITH TIME ZONE
)
PARTITION BY RANGE (created_at);
CREATE TABLE mytable_2021_01 PARTITION OF mytable
FOR VALUES FROM ('2021-01-01') TO ('2021-02-01');
CREATE TABLE mytable_2021_02 PARTITION OF mytable
FOR VALUES FROM ('2021-02-01') TO ('2021-03-01');
CREATE TABLE mytable_2021_03 PARTITION OF mytable
FOR VALUES FROM ('2021-03-01') TO ('2021-04-01');
-- 创建更多的分区表,每个表代表一个月份
垂直分区栗子:
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(50) NOT NULL,
gender VARCHAR(10) NOT NULL,
age INTEGER NOT NULL,
address VARCHAR(200) NOT NULL,
phone VARCHAR(20) NOT NULL
);
CREATE TABLE users_name_gender (
id INTEGER PRIMARY KEY REFERENCES users(id),
name VARCHAR(50) NOT NULL,
gender VARCHAR(10) NOT NULL
);
CREATE VIEW users_info AS
SELECT users.id, users_name_gender.name, users_name_gender.gender, users.age, users.address, users.phone
FROM users
JOIN users_name_gender ON users.id = users_name_gender.id;
数据库分表
将一个大型表分成多个小型表,每个表被称为一个分表。每个分表可以独立进行管理和维护,使得数据库系统的可扩展性和可用性得到了提高。同时,分表还可以提高数据库系统的查询速度和并发处理能力,降低数据冲突和死锁的发生概率。
分表的复杂性就比分区大多了,需要业务逻辑的配合才可以。
数据库分表的方式有以下几种:
- 垂直分表:按照列的业务逻辑将表拆分成多个表,每个表包含一部分列。这种方式适用于表中某些列的访问频率较低,或者某些列的数据量较大,可以将这些列独立成一个表,从而提高查询性能和并发能力。
- 水平分表:按照行的业务逻辑将表拆分成多个表,每个表包含部分行数据。这种方式适用于表中数据量较大,或者访问频率较高的行可以分散到多个表中,从而减少单个表的数据量,提高查询性能和并发能力。
- 分区表:按照某个特定的规则将表分成多个逻辑上的部分,每个部分称为一个分区。分区可以按照时间、范围、哈希等方式进行划分。这种方式适用于表中数据量较大,或者访问频率较高的数据可以按照某个规则分散到多个分区中,从而提高查询性能和并发能力。
- 组合分表:将垂直分表、水平分表和分区表结合起来使用,可以根据具体的业务需求和数据特点进行灵活的组合,从而达到最优的性能和可扩展性。
举栗子:
假设有一个订单表,包含订单号、用户ID、下单时间、订单金额等字段,数据量较大,需要进行分表操作。
- 垂直分表:将订单表按照列的业务逻辑进行拆分,可以将订单金额独立成一个表,每个表包含订单号、用户ID、下单时间和订单金额。
- 水平分表:将订单表按照行的业务逻辑进行拆分,可以按照用户ID进行拆分,将同一个用户的订单分散到多个表中,每个表包含订单号、下单时间和订单金额。
- 分区表:将订单表按照时间进行分区,可以按照下单时间的年份、月份或日期进行分区,每个分区包含一段时间内的订单数据。
- 组合分表:可以将垂直分表、水平分表和分区表结合起来使用,例如按照用户ID进行水平分表,再按照下单时间进行分区,每个分区包含一个用户在一段时间内的订单数据
数据库分库
将一个大型数据库分成多个小型数据库,每个数据库被称为一个分库。每个分库可以独立进行管理和维护,使得数据库系统的可扩展性和可用性得到了提高。同时,分库还可以提高数据库系统的并发处理能力,降低数据冲突和死锁的发生概率。
- 垂直分库:
垂直分库是指将一张表按照列的业务逻辑划分成多个表,每个表只包含部分列。这种方式适用于某些列经常被查询,而其他列很少被查询的情况。垂直分库的优点是可以将数据分散到不同的物理节点上,从而提高查询效率和可用性。在 PostgreSQL 中,可以使用视图或表继承来实现垂直分库。
- 水平分库:
水平分库是指将一张表按照行的业务逻辑划分成多个表,每个表包含部分行。这种方式适用于数据量很大,单个节点无法存储全部数据的情况。水平分库的优点是可以将数据分散到多个物理节点上,从而提高查询效率和可用性。在实现水平分库时,可以使用分片键将数据分散到不同的节点上,同时需要考虑数据的一致性和事务处理等问题。
分库的常见实现方式
- 数据库代理:通过在客户端和数据库之间插入代理层,将请求分发到不同的数据库节点上。
- 分布式事务协议:通过协议实现分布式事务的一致性,保证数据的正确性。
- 分片键路由:通过分片键将数据分散到不同的节点上,同时需要考虑数据的一致性和事务处理等问题。
- 数据库复制:将数据复制到多个节点上,提高查询效率和可用性。
什么时候分库
- 单台DB的存储空间不够时。
- 随着查询量的增加单台数据库服务器已经没办法支撑业务扩展。
总的来说,数据库分区、分库和分表的目的都是为了提高数据库系统的性能和可靠性,使得它能够更好地应对不断增长的数据存储需求。
-
存储
+关注
关注
13文章
4296浏览量
85795 -
服务器
+关注
关注
12文章
9123浏览量
85318 -
数据库
+关注
关注
7文章
3794浏览量
64351 -
视图
+关注
关注
0文章
140浏览量
6575
发布评论请先 登录
相关推荐
基于聚类分析分库策略的社交网络数据库查询性能与数据迁移
数据库瓶颈及分库分表示例
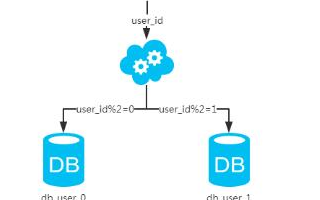
优化MySQL数据库中朴实无华的分表和花里胡哨的分库
数据库优化最有效的方式是什么?
数据库数据恢复-数据库文件被删除/分区被格式化的SQL SERVER数据恢复方案
分库分表后复杂查询的应对之道:基于DTS实时性ES宽表构建技术实践





 工商网监
工商网监
评论