 NeurIPS 2023 | 扩散模型解决多任务强化学习问题
NeurIPS 2023 | 扩散模型解决多任务强化学习问题
扩散模型(diffusion model)在 CV 领域甚至 NLP 领域都已经有了令人印象深刻的表现。最近的一些工作开始将 diffusion model 用于强化学习(RL)中来解决序列决策问题,它们主要利用 diffusion model 来建模分布复杂的轨迹或提高策略的表达性。
但是, 这些工作仍然局限于单一任务单一数据集,无法得到能同时解决多种任务的通用智能体。那么,diffusion model 能否解决多任务强化学习问题呢?我们最近提出的一篇新工作——“Diffusion Model is an Effective Planner and Data Synthesizer for Multi-Task Reinforcement Learning”,旨在解决这个问题并希望启发后续通用决策智能的研究:

论文链接:
https://arxiv.org/abs/2305.18459

背景
数据驱动的大模型在 CV 和 NLP 领域已经获得巨大成功,我们认为这背后源于模型的强表达性和数据集的多样性和广泛性。基于此,我们将最近出圈的生成式扩散模型(diffusion model)扩展到多任务强化学习领域(multi-task reinforcement learning),利用 large-scale 的离线多任务数据集训练得到通用智能体。 目前解决多任务强化学习的工作大多基于 Transformer 架构,它们通常对模型的规模,数据集的质量都有很高的要求,这对于实际训练来说是代价高昂的。基于 TD-learning 的强化学习方法则常常面临 distribution-shift 的挑战,在多任务数据集下这个问题尤甚,而我们将序列决策过程建模成条件式生成问题(conditional generative process),通过最大化 likelihood 来学习,有效避免了 distribution shift 的问题。

方法
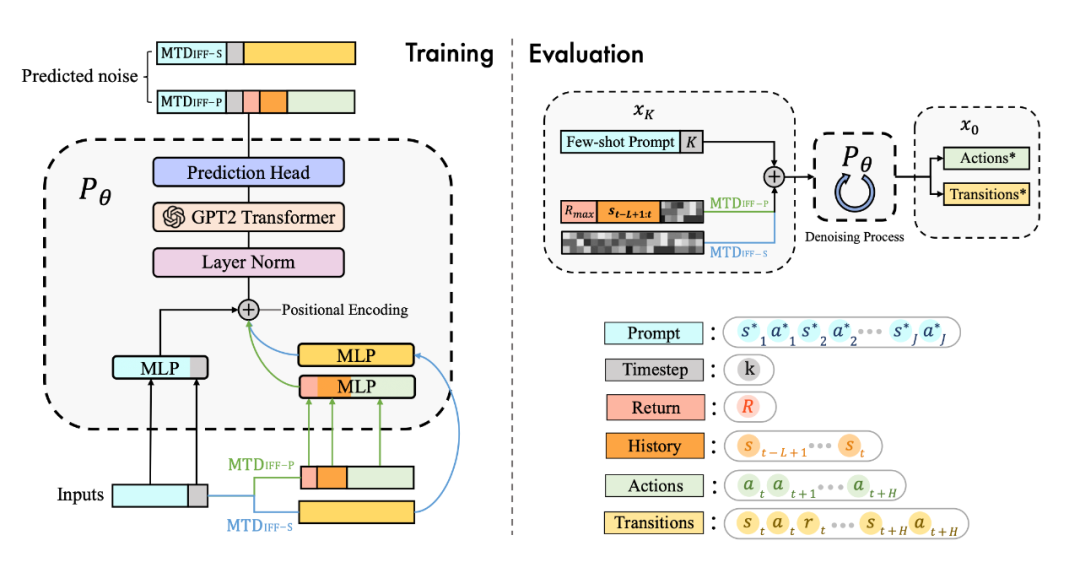
具体来说,我们发现 diffusion model 不仅能很好地输出 action 进行实时决策,同样能够建模完整的(s,a,r,s')的 transition 来生成数据进行数据增强提升强化学习策略的性能,具体框架如图所示:
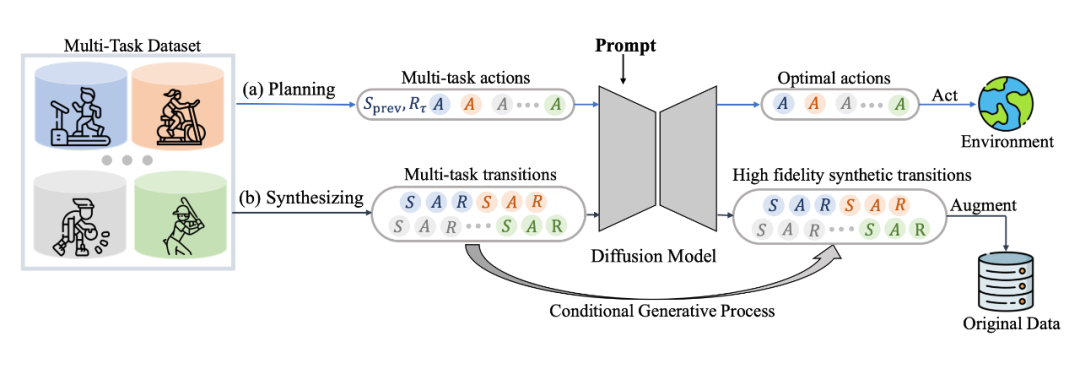
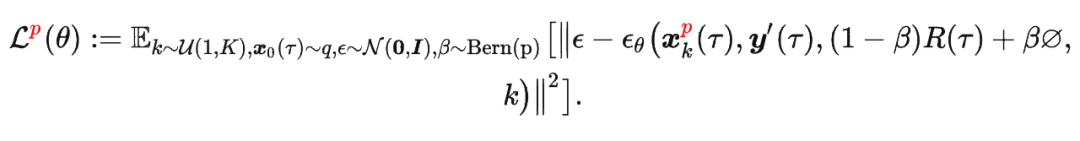 其中
其中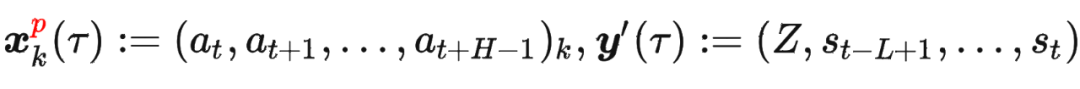 是轨迹的标准化累积回报, 是 Demonstration Prompt,可以表示为:
是轨迹的标准化累积回报, 是 Demonstration Prompt,可以表示为:

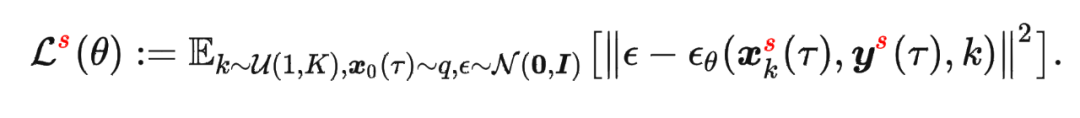 其中
其中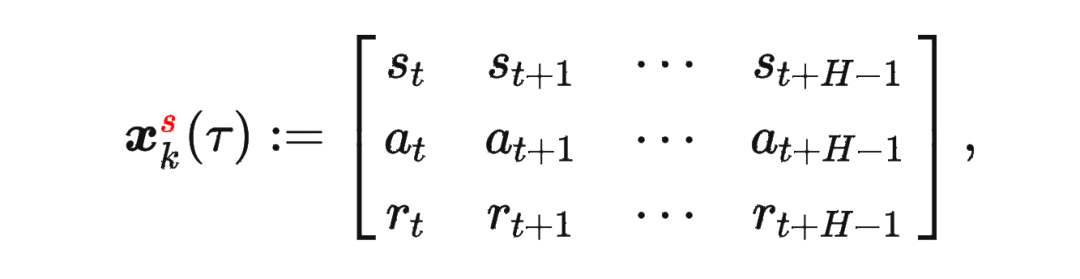
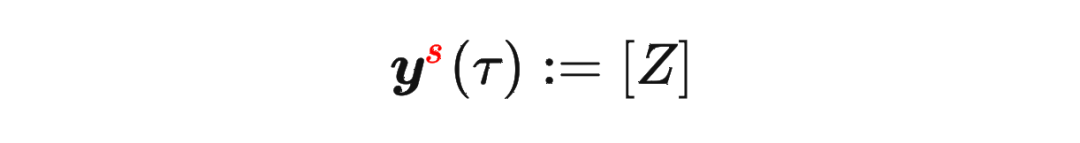

模型结构
为了更好地建模多任务数据,并且统一多样化的输入数据,我们用 transformer 架构替换了传统的 U-Net 网络,网络结构图如下:

实验
我们首先在 Meta-World MT50 上开展实验并与 baselines 进行比较,我们在两种数据集上进行实验,分别是包含大量专家数据,从 SAC-single-agent 中的 replay buffer 中收集到的 Near-optimal data(100M);以及从 Near-optimal data 中降采样得到基本不包含专家数据的 Sub-optimal data(50M)。实验结果如下:
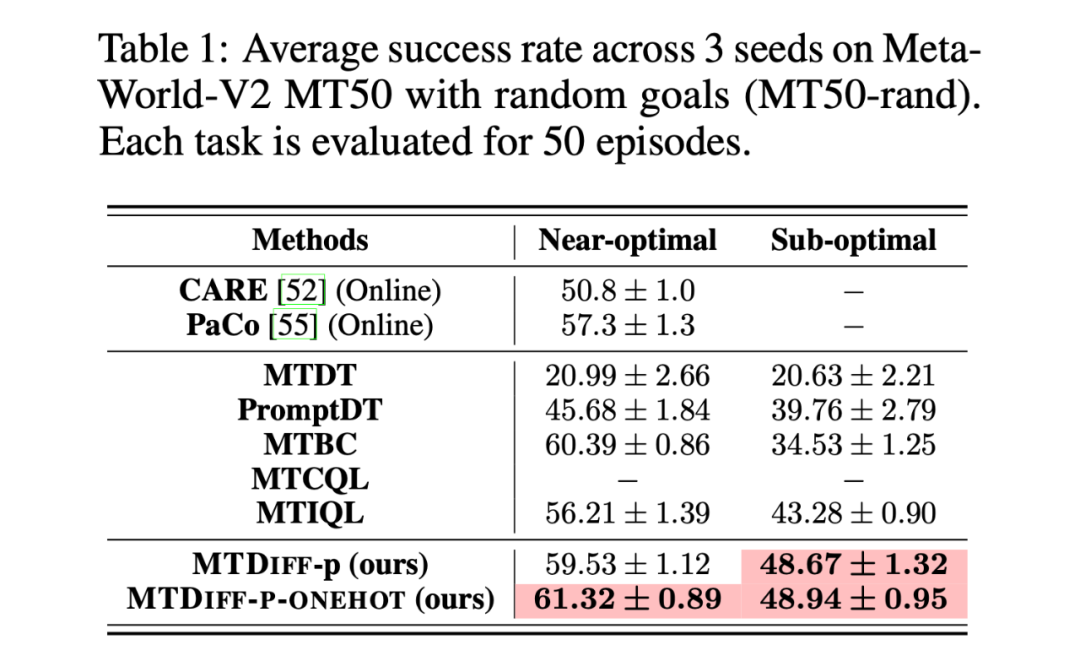
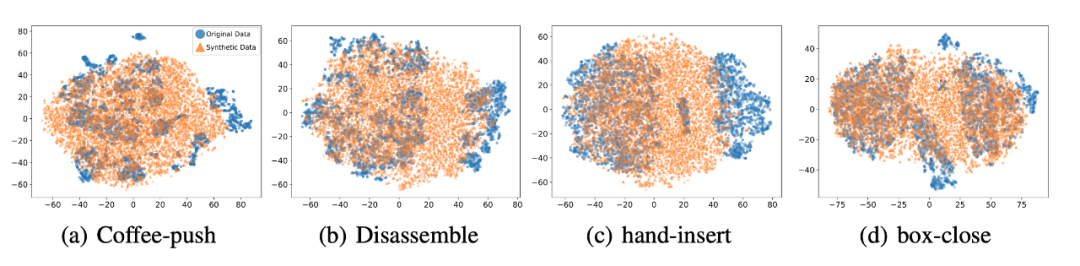
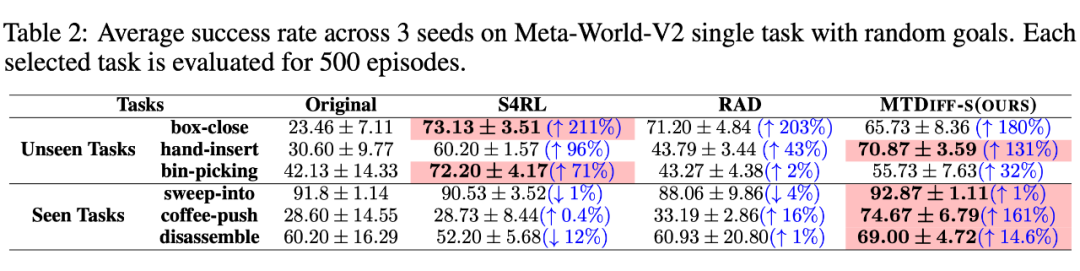 我们选取 45 个任务的 Near-optimal data 训练 ,从表中我们可以观察到在 见过的任务上,我们的方法均取得了最好的性能。甚至给定一段 demonstration prompt, 能泛化到没见过的任务上并取得较好的表现。我们选取四个任务对原数据和 生成的数据做 T-SNE 可视化分析,发现我们生成的数据的分布基本匹配原数据分布,并且在不偏离的基础上扩展了分布,使数据覆盖更加全面。
我们选取 45 个任务的 Near-optimal data 训练 ,从表中我们可以观察到在 见过的任务上,我们的方法均取得了最好的性能。甚至给定一段 demonstration prompt, 能泛化到没见过的任务上并取得较好的表现。我们选取四个任务对原数据和 生成的数据做 T-SNE 可视化分析,发现我们生成的数据的分布基本匹配原数据分布,并且在不偏离的基础上扩展了分布,使数据覆盖更加全面。

总结
我们提出了一种基于扩散模型(diffusion model)的一种新的、通用性强的多任务强化学习解决方案,它不仅可以通过单个模型高效完成多任务决策,而且可以对原数据集进行增强,从而提升各种离线算法的性能。我们未来将把 迁移到更加多样、更加通用的场景,旨在深入挖掘其出色的生成能力和数据建模能力,解决更加困难的任务。同时,我们会将 迁移到真实控制场景,并尝试优化其推理速度以适应某些需要高频控制的任务。
原文标题:NeurIPS 2023 | 扩散模型解决多任务强化学习问题
文章出处:【微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表德赢Vwin官网
网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
物联网
+关注
关注
2909文章
44556浏览量
372734
原文标题:NeurIPS 2023 | 扩散模型解决多任务强化学习问题
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
浙大、微信提出精确反演采样器新范式,彻底解决扩散模型反演问题
随着扩散生成模型的发展,人工智能步入了属于 AIGC 的新纪元。扩散生成模型可以对初始高斯噪声进行逐步去噪而得到高质量的采样。当前,许多应用都涉及扩

蚂蚁集团收购边塞科技,吴翼出任强化学习实验室首席科学家
近日,专注于模型赛道的初创企业边塞科技宣布被蚂蚁集团收购。据悉,此次交易完成后,边塞科技将保持独立运营,而原投资人已全部退出。 与此同时,蚂蚁集团近期宣布成立强化学习实验室,旨在推动大模型强化
如何使用 PyTorch 进行强化学习
强化学习(Reinforcement Learning, RL)是一种机器学习方法,它通过与环境的交互来学习如何做出决策,以最大化累积奖励。PyTorch 是一个流行的开源机器学习库,

谷歌AlphaChip强化学习工具发布,联发科天玑芯片率先采用
近日,谷歌在芯片设计领域取得了重要突破,详细介绍了其用于芯片设计布局的强化学习方法,并将该模型命名为“AlphaChip”。据悉,AlphaChip有望显著加速芯片布局规划的设计流程,并帮助芯片在性能、功耗和面积方面实现更优表现。
通过强化学习策略进行特征选择
来源:DeepHubIMBA特征选择是构建机器学习模型过程中的决定性步骤。为模型和我们想要完成的任务选择好的特征,可以提高性能。如果我们处理的是高维数据集,那么选择特征就显得尤为重要。

【大语言模型:原理与工程实践】核心技术综述
的具体需求,这通常需要较少量的标注数据。
多任务学习和迁移学习:
LLMs利用在预训练中积累的知识,可以通过迁移学习在相关任务上快速适应
发表于 05-05 10:56
【大语言模型:原理与工程实践】揭开大语言模型的面纱
Transformer架构,利用自注意力机制对文本进行编码,通过预训练、有监督微调和强化学习等阶段,不断提升性能,展现出强大的语言理解和生成能力。
大语言模型的涌现能力,是指随着模型规模的增长,展现出
发表于 05-04 23:55
名单公布!【书籍评测活动NO.30】大规模语言模型:从理论到实践
个文本质量对比模型,用于对有监督微调模型对于同一个提示词给出的多个不同输出结果进行质量排序。这一阶段的难点在于如何限定奖励模型的应用范围及如何构建训练数据。
强化学习阶段 ,根据数十万
发表于 03-11 15:16
深度学习在时间序列预测的总结和未来方向分析
2023年是大语言模型和稳定扩散的一年,时间序列领域虽然没有那么大的成就,但是却有缓慢而稳定的进展。Neurips、ICML和AAAI等会议都有transformer结构(BasisF
一文详解Transformer神经网络模型
Transformer模型在强化学习领域的应用主要是应用于策略学习和值函数近似。强化学习是指让机器在与环境互动的过程中,通过试错来学习最优的
发表于 02-20 09:55
•1.4w次阅读

谷歌推出AI扩散模型Lumiere
近日,谷歌研究院重磅推出全新AI扩散模型Lumiere,这款模型基于谷歌自主研发的“Space-Time U-Net”基础架构,旨在实现视频生成的一次性完成,同时保证视频的真实性和动作连贯性。
图解大模型RLHF系列之:人人都能看懂的PPO原理与源码解读
回想一下我们对NLP任务做强化学习(RLHF)的目的:我们希望给模型一个prompt,让模型能生成符合人类喜好的response。再回想一下gpt模

基于DiAD扩散模型的多类异常检测工作
现有的基于计算机视觉的工业异常检测技术包括基于特征的、基于重构的和基于合成的技术。最近,扩散模型因其强大的生成能力而闻名,因此本文作者希望通过扩散模型将异常区域重构成正常。






 工商网监
工商网监
评论