 探索ChatGLM2在算能BM1684X上INT8量化部署,加速大模型商业落地
探索ChatGLM2在算能BM1684X上INT8量化部署,加速大模型商业落地
1. 背景介绍
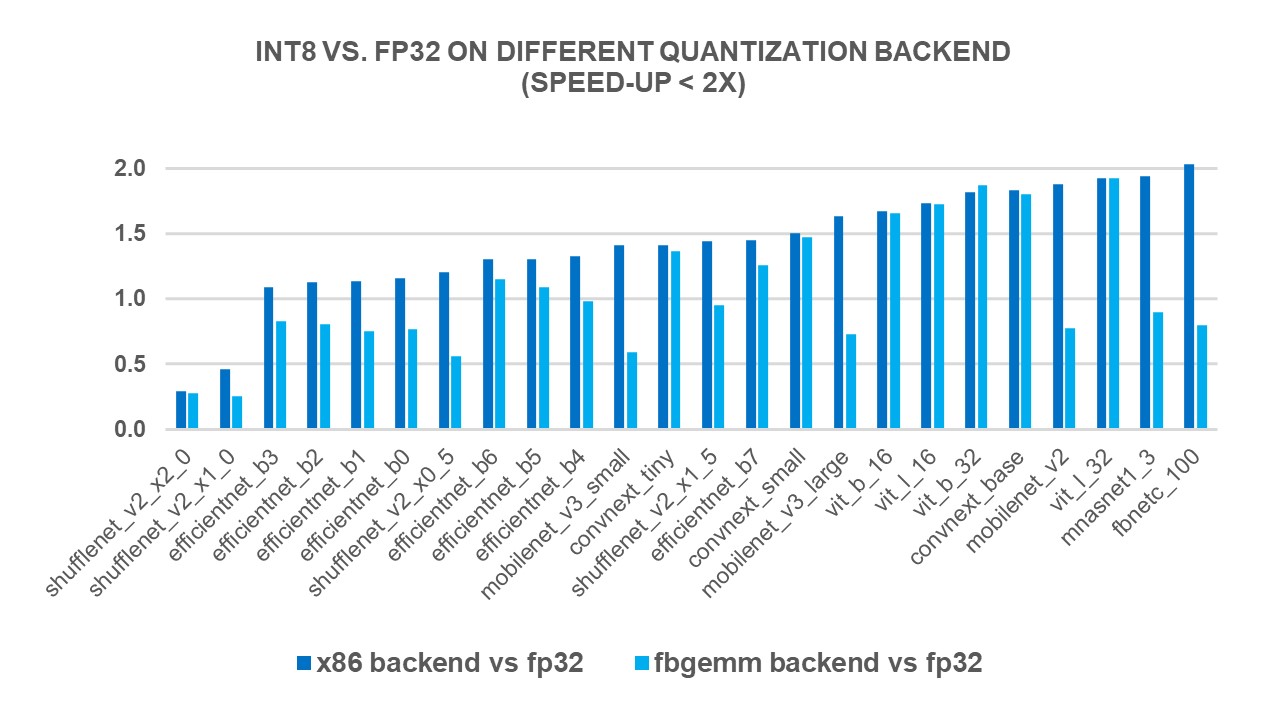
在2023年7月时我们已通过静态设计方案完成了ChatGLM2-6B在单颗BM1684X上的部署工作,量化模式F16,模型大小12GB,平均速度约为3 token/s,详见《算丰技术揭秘|探索ChatGLM2-6B模型与TPU部署》。为了进一步提升模型的推理效率与降低存储空间,我们对模型进行了INT8量化部署,整体性能提升70%以上,模型大小降低到6.4GB,推理速度达到6.67 token/s。
2. 量化方案
首先TPU-MLIR原有的INT8量化方案并不适合直接应用于LLM。主要是因为无论PTQ的校准或者QAT的训练对于LLM来说成本过高,对LLM的一轮PTQ的校准可能就需要1-2天时间;另外就是量化带来的误差在LLM上无法收敛,最终会导致模型精度大量损失。
在量化方案上我们沿用了ChatGLM2使用的W8A16策略,即只对GLMBlock中LinearLayer的权重进行per-channel量化存储,在实际运算时仍将其反量化回F16进行运算。因为LLM中Linear Layer权重数值间差异非常小,对INT8量化较为友好,所以量化过后的结果与F16计算结果在余弦相似度上仍然能保持99%以上,精度上几乎可以做到0损失。
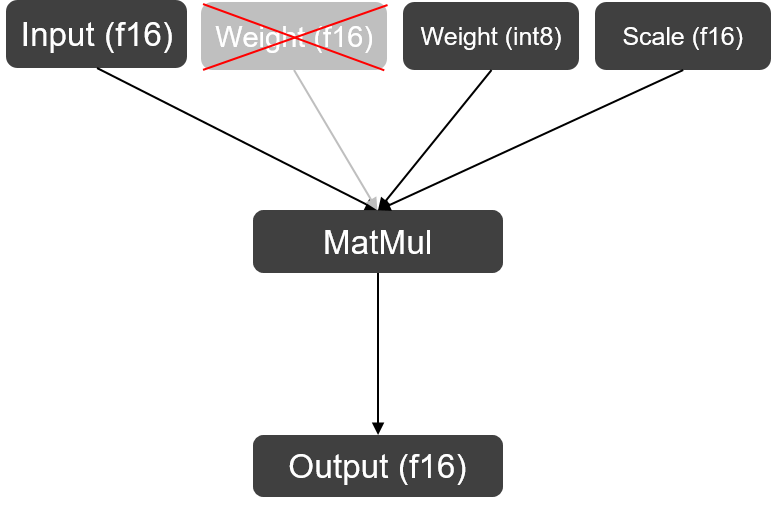 W8A16 MatMul
W8A16 MatMul
3. TPU-MLIR实现
在Top到Tpu层的lowering阶段,编译器会自动搜寻模型中右矩阵输入为权重,且该矩阵维数为2的MatMul,将其替换为W8A16MatMul算子。此处主要是为了与左右矩阵都为Acitvation的MatMul算子区分开(mm, bmm与linear layer在编译器中会被统一转换为MatMul算子)。以ChatGLM2中其中一个MatMul算子为例:L = (max_lengthx4096xf16), R = (4096x27392xf16),量化后的权重由原来的214MB降为107MB,额外产生的Scale (4096xf16)只占了0.008MB的存储空间,基本上可以达到减半的效果。算子替换源码与权重量化源码可在TPU-MLIR仓库中查看。
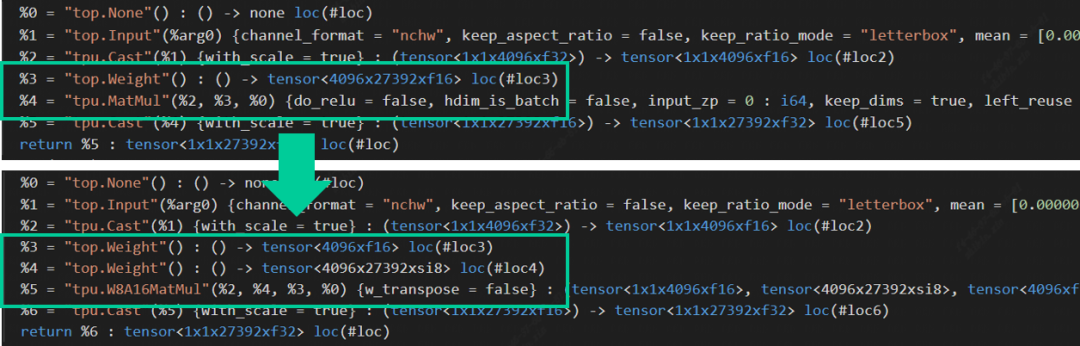 Op Replacement in TPU-MLIR
Op Replacement in TPU-MLIR
4. 后端性能提升原理
前一节介绍的量化只实现了存储空间减半的效果,而性能提升主要在于W8A16MatMul后端算子的实现。如果对TPU架构不熟悉可通过TPU原理介绍(1)和TPU原理介绍(2)两期视频了解(可关注b站“算能开发者”进行观看)。按照算能当前的TPU架构,W8A16的计算过程主要分为5个步骤:
1. 从Global Memory中加载数据到Local Memory
2. 将INT8权重Cast为F16
3. 与Scale数据相乘完成反量化操作
4. 与Input Activation进行矩阵乘运算
5. 将计算结果存储回Global Memory
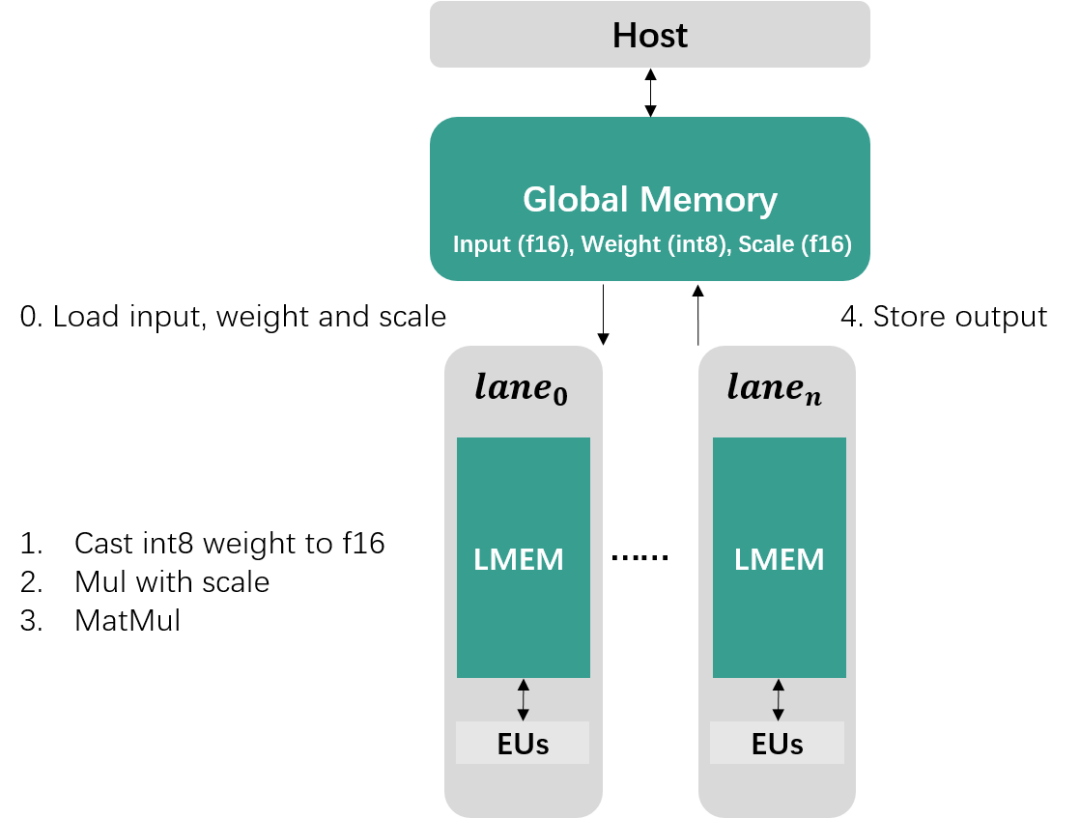 W8A16Matmul Computation on TPU
W8A16Matmul Computation on TPU
因为Local Memory空间有限,对于大型数据通常需要进行切分,分批对数据进行加载、运算与存储。为了提升效率,通常我们会利用GDMA与BDC指令并行,同时进行数据搬运与运算操作,所以Local Mmeory大致需要被需要被划分为两部分区域,同一个循环内一个区域用于数据运算,另一个区域存储上一循环计算好的结果以及加载下一循环需要用到的数据,如下图所示。
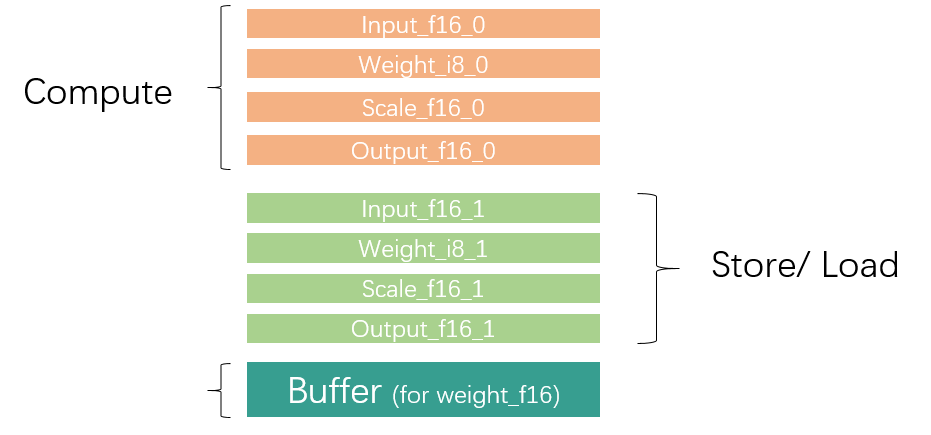 Local Memory Partition
Local Memory Partition
矩阵乘等式如下:
当矩阵乘运算中左矩阵数据量较小时,性能瓶颈主要在于右矩阵的数据加载上,即数据加载时间远比数据运算时间要长很多。W8A16通过量化能够将右矩阵的数据搬运总量缩小为原来的一半,而且额外多出的Cast与Scale运算时间可以被数据搬运时间覆盖住,因此并不会影响到整体runtime,如下图所示。
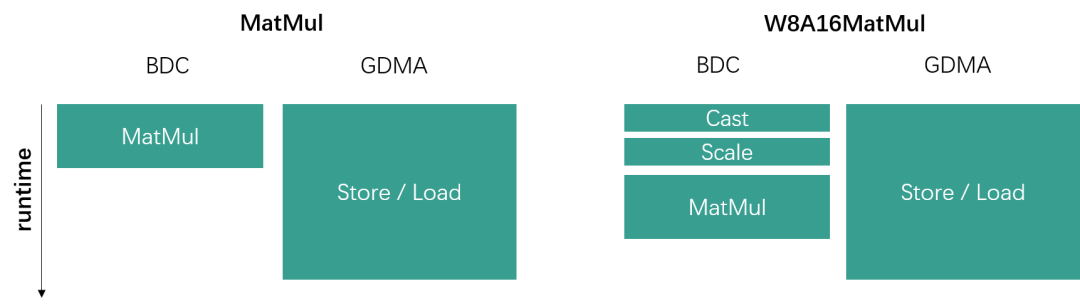 GDMA and BDC parallel
GDMA and BDC parallel
总而言之,从后端角度来说,当越小,越大时,W8A16带来的性能提升收益越大。
从LLM的角度来看,我们以ChatGLM2为例,一次推理的完整流程分为一轮prefill与多轮decode。在prefill阶段,基于我们当前的静态设计方案,输入词向量会被补位为当前模型所支持的最大文本长度max_length (e.g., 512, 1024, 2048)。而decode阶段则固定只取前一轮生成的一个token作为输入。
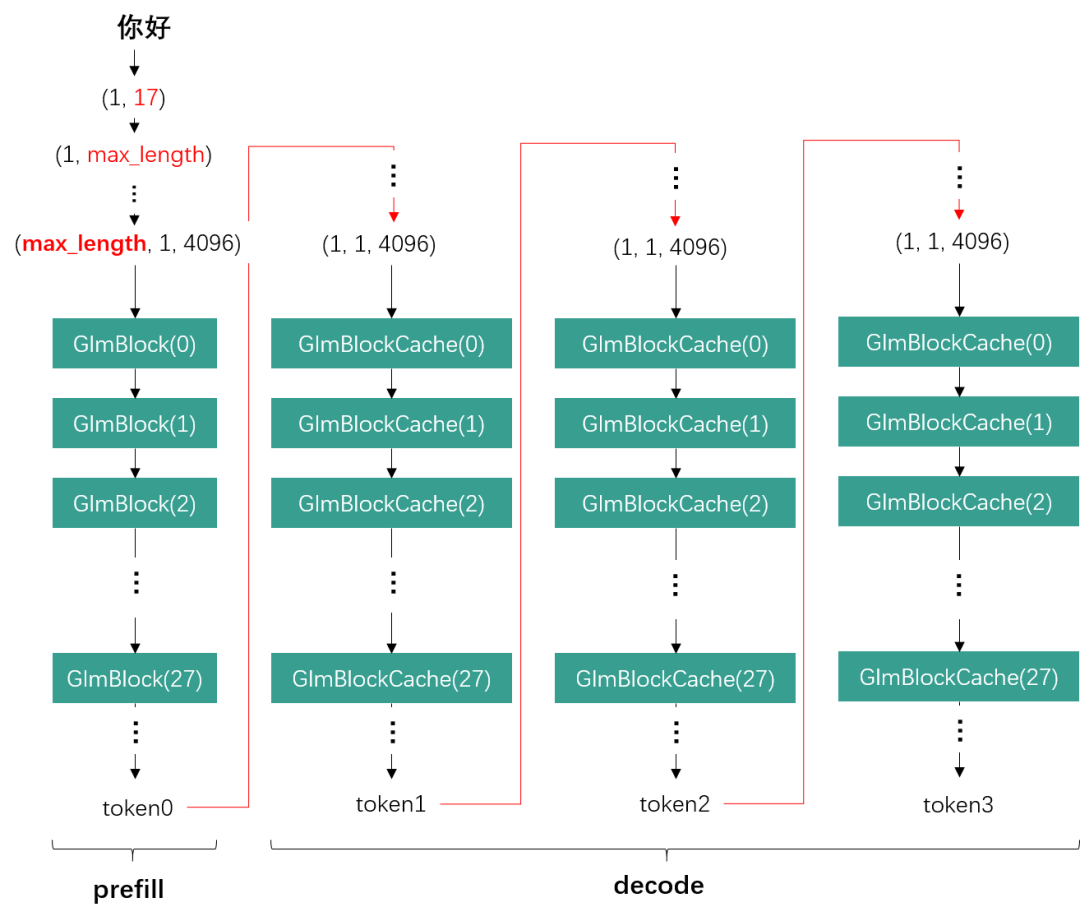 ChatGLM2 Inference
ChatGLM2 Inference
因此max_length越长,GLMBlock接收的输入数据量越大,Linear Layer的也就越大,这就会导致W8A16的性能提升越有限。而decode阶段始终保持为1,此时W8A16就能带来明显的性能提升。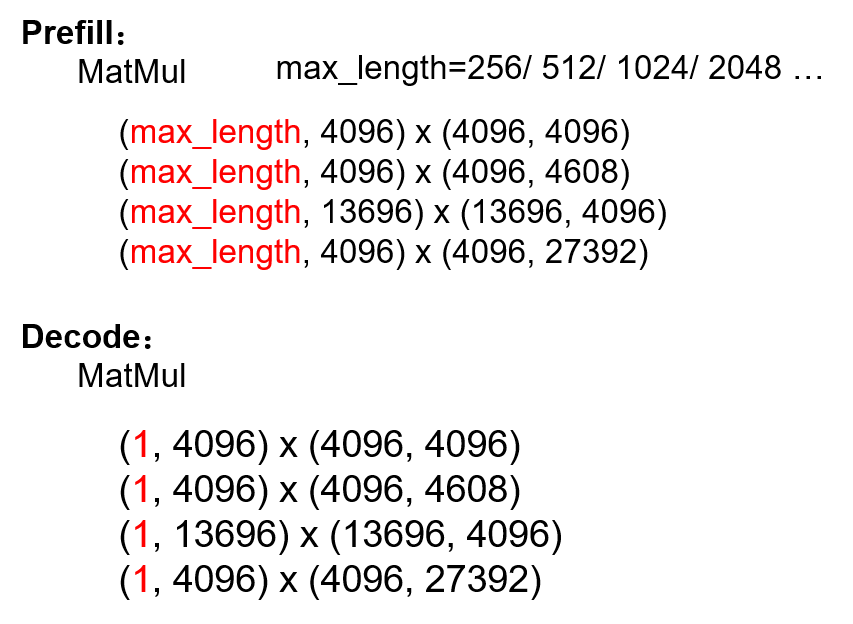 MatMuls in ChatGLM2 prefill and decode phase
MatMuls in ChatGLM2 prefill and decode phase
5. 效果展示
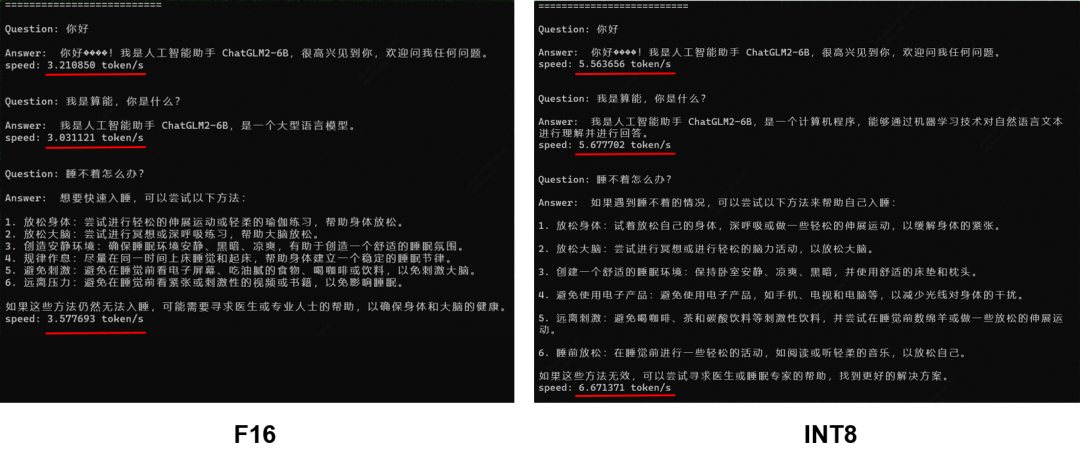
将W8A16量化应用于ChatGLM2-6B后,整体性能如下所示:
- 性能:整体性能得到70%以上的提升
- 精度:与F16下的回答略有不同,但答案正确性仍然可以保证
- 模型大小:由12GB降为6.4GB
 Result Comparison
Result Comparison
- 模型
+关注
关注
1文章
3003浏览量
48223 - 编译器
+关注
关注
1文章
1594浏览量
48862 - LLM
+关注
关注
0文章
244浏览量
274
发布评论请先登录
相关推荐
【算能RADXA微服务器试用体验】+ GPT语音与视觉交互:2,图像识别
esp-dlint8量化模型数据集评估精度下降的疑问求解?
产品应用 | 小盒子跑大模型!英码科技基于算能BM1684X平台实现大模型私有化部署

bm1684运行demo报错怎么解决?
256Tops算力!CSA1-N8S1684X算力服务器

【算能RADXA微服务器试用体验】Radxa Fogwise1684XMini 规格
yolov5量化INT8出错怎么处理?
ChatGLM3-6B在CPU上的INT4量化和部署
【爱芯派 Pro 开发板试用体验】在爱芯派部署ChatGLM3(一)
Yolo系列模型的部署、精度对齐与int8量化加速
走向边缘智能,美格智能携手阿加犀成功在高算力AI模组上运行一系列大语言模型

INT8量化常见问题的解决方案
本地化ChatGPT?Firefly推出基于BM1684X的大语言模型本地部署方案





 工商网监
工商网监
评论