 基于Corundum架构的100G RDMA网卡设计
基于Corundum架构的100G RDMA网卡设计
三年前的2020年5月12日,我们分享了一篇有关100G开源网卡的文章《【干货】寻找开源100G NIC Corundum中的隐藏BUG等。大概两年前,我们决定基于开源的Corundum架构研制100G RDMA网卡,终于目前有了稳定的一版,以下是详细介绍,欢迎大家留言讨论指导。
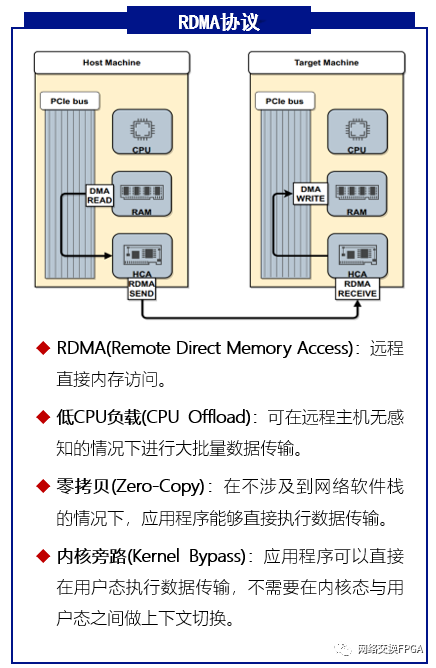
传统TCP/IP技术处理数据包需通过操作系统和其他软件层,导致数据在系统内存、处理器缓存和网络控制器缓存间频繁复制,增加了服务器CPU和内存的负担,特别是在网络带宽、处理器速度与内存带宽不匹配时,网络延迟会进一步加剧。RDMA技术通过将数据处理从CPU旁路并卸载到硬件上来实现低时延和高带宽特性。
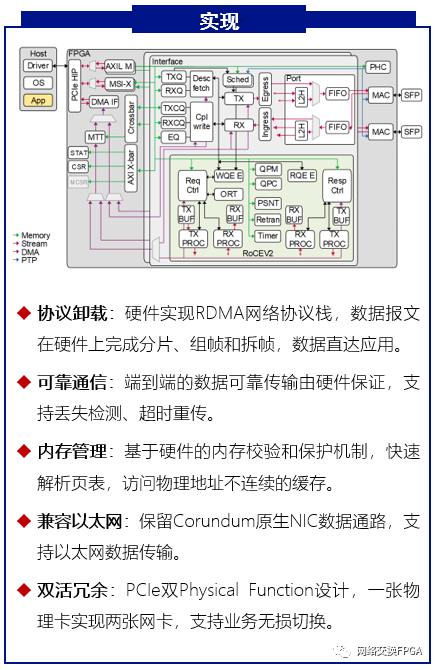
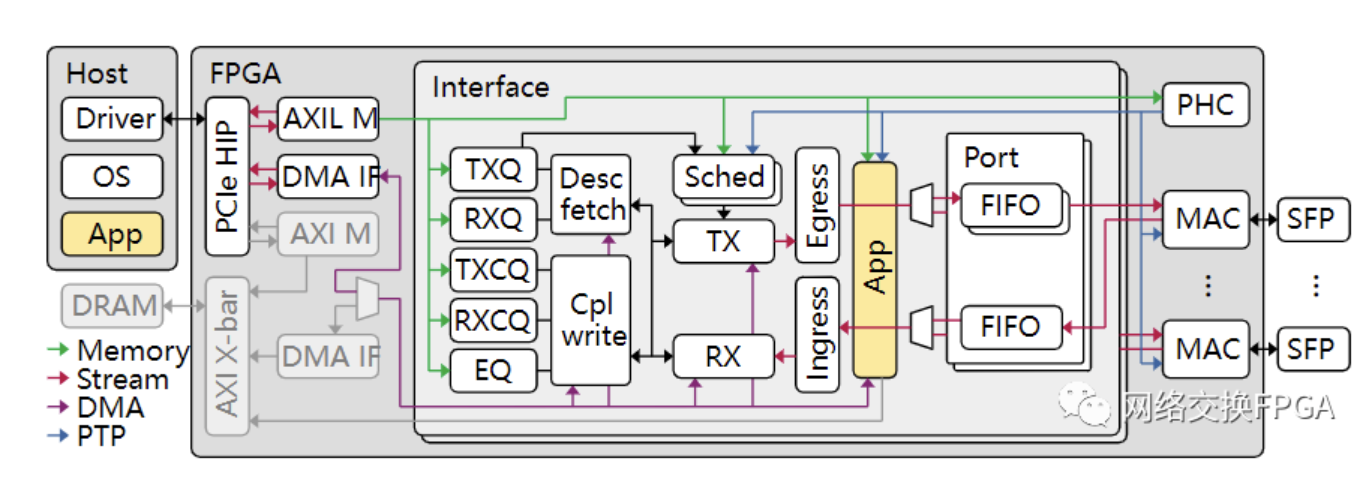
基于这一研究背景,介绍一种具备RDMA功能的FPGA网卡实现方案—RNIC 。本方案以Corundum开源高性能原型平台为基础, 实现了100Gbps的RoCE v2网络协议栈卸载加速;在保留Corundum原生PCIe DMA引擎等组件的基础上,通过精准的拆分设计、逻辑耦合和路径复用,将RoCE v2网络协议栈嵌入以太网网卡设计。方案支持单边RDMA READ和RDMA WRITE操作、双边SEND/RECV操作以及立即数操作,提供Back-to-N的重传机制保障数据传输完整性的同时提供了可达256的Outstanding能力, 并支持基于DCQCN算法的拥塞控制机制为本方案在数据中心等场景的大规模部署提供保障。实测RNIC能够实现低至4us左右的硬件端到端延迟以及高达96Gbps的吞吐量。
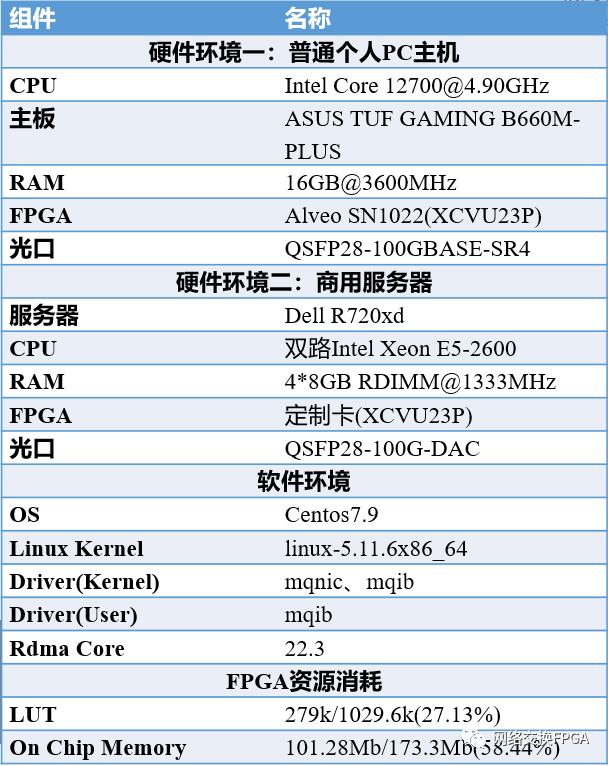
我们实现的100G RDMA网卡具体指标和性能如下:


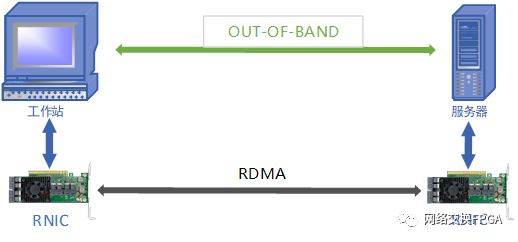
测试场景及拓扑连接图如下。
TCP测试结果如下。
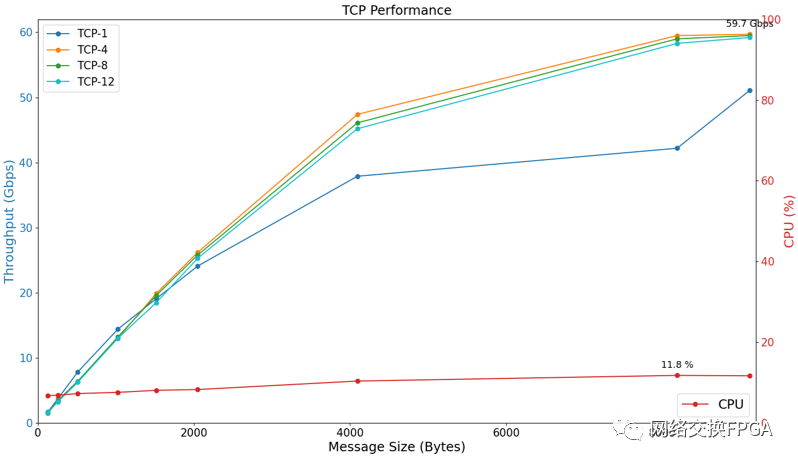
TCP性能表现:实测在Linux系统环境下,端到端连接拓扑,当MTU=9214B,不进行多核优化时,本方案的iperf TCP带宽可达59.7G bps;CPU占用率为12%左右 ; TCP/IP协议普遍延迟在100–200微秒之间。
TCP测试分析:性能开销集中在内核协议栈的系统调用、内存拷贝、协议处理与中断处理等方面。这些开销占用了大量的CPU 资源,增加了数据延迟。
RDMA测试结果如下。
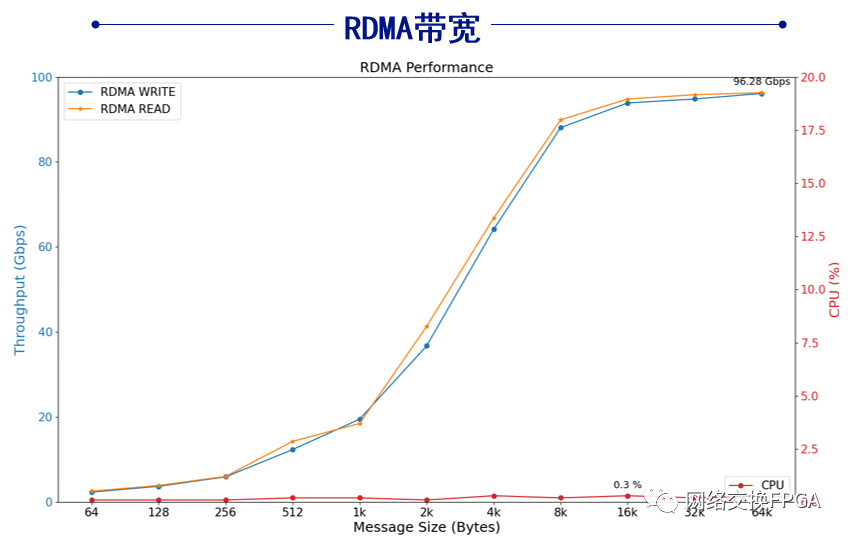
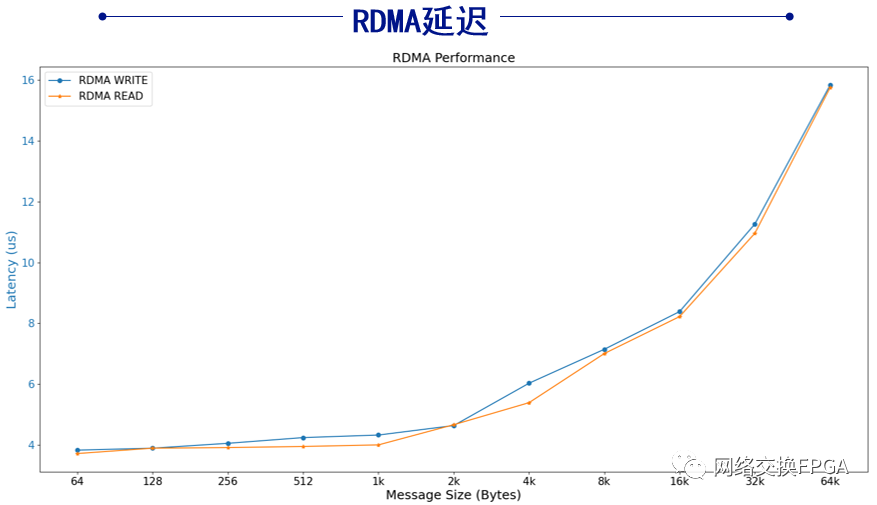
RDMA性能表现:在Linux系统环境下,相同测试拓扑,使用配套驱动程序和应用程序发送RDMA命令进行测试。本方案的RDMA网卡实测单边RDMA语义读写带宽可达96.28G bps;CPU占用率不超过0.3%;硬件端到端读写延迟低至4us左右。
RDMA测试分析:当消息大小大于8KB时,系统吞吐量可以逼近满带宽,当消息较小时,吞吐量会显著降低。原因一方面是数据帧帧头开销占比上升导致有效带宽下降,另一方面在于硬件设计无法支撑更高的消息速率。时延会随消息大小出现近似线性的增长,最大的延迟花费在PCIe链路和网络链路上,硬件的处理开销占比很小。
对比以太网和RDMA的测试结果可知,在相同的硬件条件下,使用RDMA技术的网卡可以拥有更高的网络带宽和更低的传输时延,对于云服务、数据中心等具有高吞吐量的网络业务需求场景,RDMA技术更能满足实际需要,能充分解放处理器资源,提高带宽,降低成本。
下面视频详细介绍实际测试情况:
我们未来有很多工作要做,如添加我们之前做的P4可编程的工作(【Verilog开源】一种用于智能网卡或可编程交换机的,支持P4语言的高性能开源解析器的设计),突破Corundum架构限制支持百万QP对和提升小包性能,进一步优化流量控制、拥塞管理和负载均衡等问题,进一步的提高数据中心网络的数据传输速率和稳定性。
-
内存
+关注
关注
8文章
3019浏览量
74000 -
网卡
+关注
关注
4文章
307浏览量
27374 -
Verilog
+关注
关注
28文章
1351浏览量
110073 -
开源
+关注
关注
3文章
3309浏览量
42470 -
RDMA
+关注
关注
0文章
77浏览量
8945
原文标题:基于Corundum架构的100G RDMA网卡
文章出处:【微信号:HXSLH1010101010,微信公众号:FPGA技术江湖】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
解密100G QSFP28光模块种类、解决方案
100G光模块专题:100G光模块概述、优点和应用
什么是100G光模块?介绍:100G光模块标准、参数、优势
100G AOC有源光缆和100G高速线缆有什么区别?
什么是100G SR4光模块?100G SR4有哪些特性、优点和应用?
数据中心100G QSFP28光模块优势
如何实现100G光传送网?
光通信主流100G光模块浅析
普通电脑换上Xilinx Alveo U50 100G网卡传文件会有多快
如何选择最适合自己的RDMA网卡
开源100 Gbps NIC Corundum环境的搭建
100G DSFP网卡+100G DSFP AOC解决方案
25G/100G网卡选购指南
寻找开源100G NIC Corundum中的隐藏BUG





 工商网监
工商网监
评论