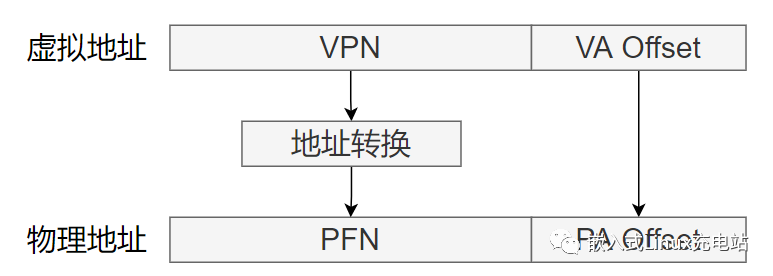
 虚拟内存到物理地址的转换
虚拟内存到物理地址的转换
处理器根据页表基地址控制寄存器TTBCR和虚拟地址来判断使用哪个页表基地址寄存器,是TTBR0还是TTBR1。(一个基值是内核的,一个用户态的)
页表基地址寄存器中存放着一级页表的基地址。
处理器根据虚拟地址的bit[31:20]作为索引值()4K页表,在一级页表中找到页表项。一级页表一共有4 096个页表项。
第一级页表的表项中存放有二级页表的物理基地址。处理器将虚拟地址的
bit[19:12]作为索引值,在二级页表中找到相应的页表项。二级页表有256个页表项(2^12 * 2^8 * 4kb(2^12)==》32位)。
二级页表的页表项里存放有 4KB 页的物理基地址,加上最后的VA 12位,因此处理器就完成了页表的查询和翻译工作。(将整个4MB分成了4096份256份4KB) (这就是为什么内存越大,页表项也得越大,不然页表项的内存就变大的) (表项存的是基地址,而虚拟内存放的都是索引)

图 7.4 所示为 4KB 映射的一级页表的表项,bit[1:0]表示一个页映射的表项,bit[31:10]指向二级页表的物理基地址。
4KB是2^12
64位的ARM 一般常用的是48,那么只剩36位(其他的位干啥了呢,记住这个问题哈哈哈)
这里还是讨论32位
一级页表4KB页表--》4GB/4KB---》2^20个页表项---》32位地址4Byte--》那么这个页表需要4MB的连续内存
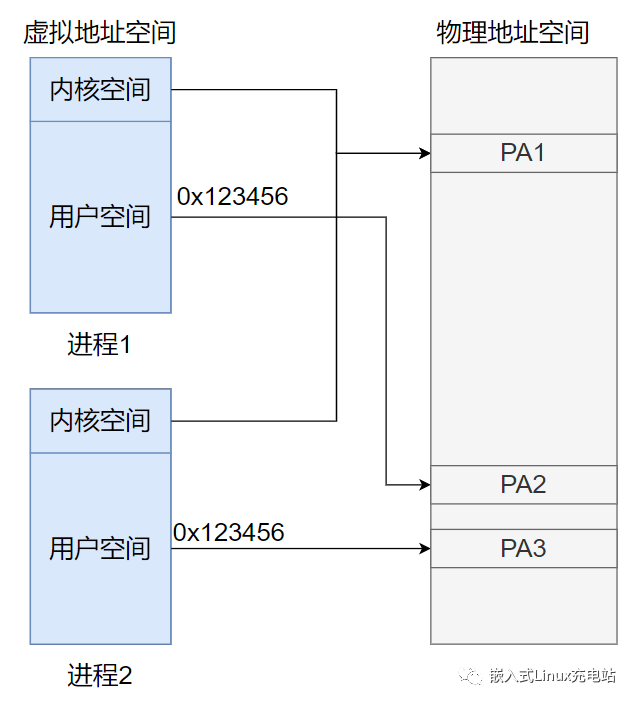
下图展示两个进程以及各自的页表和物理内存的对应关系图,这里假定页大小是4K,32位地址总线进程地址空间大小为(2^32)4G,这时候页表项有 4G /4K = 1048576个,每个页表项为一个地址,占用4字节,1048576 * 4(B) /1024(M) =4M,也就是说一个程序啥都不干,页表大小就得占用4M。
如果每个页表项都存在对应的映射地址那也就算了,但是,绝大部分程序仅仅使用了几个页,也就是说,只需要几个页的映射就可以了,如下图,进程1的页表,只用到了0,1,1024三个页,剩下1048573页表项是空的,这就造成了巨大的浪费,为了避免内存浪费,计算机系统开发人员想出了一个方案,多级页表。

我们先看下图,这是一个两级页表,对应上图中的进程1。先计算下两级页表的内存占用情况。
一级页表占用= 1024 * 4 B= 4K,
2级页表占用 = (1024 * 4 B) * 2 = 8K。
总共的占用情况是 12K,相比一级页表 4M,节省了99.7%的内存占用。
我们来看下两级页表为啥能够节省这么大的内存空间,相比于上图单级页表中一对一的关系,两级页表中的一级页表项是一对多的关系,这里是1:1024,这样就需要 1048576 / 1024 = 1024 个一级页表项。相当于把上图的单级页表分成1024份。一级页表项PTE0表示虚拟地址页 0 1023,PTE1表示虚拟地址页10242047。
如果对应的1024个虚拟地址页存在任意一个真实的映射,则一级页表项指向一个二级页表项,二级页表项和虚拟地址页一一对应,在上图中,进程1的虚拟页0,1,1024存在映射,0,1虚拟页属于这里的PTE0,1024属于PTE1。一级页表项中如果为null,表示对应的1024个虚拟页没有使用,所以就不需要二级页表了,节省了空间。
当然,如果虚拟地址页完全映射的话,多级页表的占用=一级页表项(1024 * 4B) + 二级页表项(1024 * 1024 * 4B) = 4M +4K,比单级映射多了4K,不过这种情况基本上没有可能,因为进程的地址空间很少有完全映射的情况。正是因为省却了大量未映射的页表项使得页表的空间大幅减少。

其实这个差异就是我以前一来就把全部的虚拟页表和物理页表建立了映射关系,那我这个页表就需要4M。
现在我将这个4M的页表分成了1024份,需要几份就申请创建几份页表,而不是一来就把所有的页表都和物理页面挂上钩。
然后分成了这1024个,我需要在抽象一层4kb的页表去指向这1024个页表各自的基地址。
因为从物理内存层面一层一层的提到最上层的时候,也方便我们对于这个虚拟地址的组成:
一级页表索引+二级页表索引+VA(每次页表的内容都是下一基的基地址) (这个图片稍微有点理想,一般都是4096 + 256的组合,而不是1014 +
1024的组合,不过大概这个道理就行)
那几个特殊的位是内存的属性。这个后面再补充。这个是ARM硬件架构上针对安全内存、设备内存的一些位。
-
处理器
+关注
关注
68文章
19259浏览量
229647 -
寄存器
+关注
关注
31文章
5336浏览量
120224 -
Linux
+关注
关注
87文章
11292浏览量
209318 -
内存
+关注
关注
8文章
3019浏览量
74001 -
物理地址
+关注
关注
0文章
7浏览量
6241
发布评论请先 登录
相关推荐
鸿蒙内核源码分析:物理地址的映射
PIC32在编写汇编程序和自定义链接器文件时位置地址是物理地址还是虚拟地址?
物理内存和虚拟内存之间的转换
虚拟内存与物理地址有哪些区别
物理地址到虚拟地址的转换步骤
RT-Thread smart内存虚拟地址到物理地址的转换是一个什么样的流程
鸿蒙内核中虚拟地址与物理地址之间是如何映射的
Linux虚拟地址空间和物理地址空间的关系





 工商网监
工商网监
评论