 Linux内核时钟系统和定时器实现
Linux内核时钟系统和定时器实现
Linux 2.6.16之前,内核只支持低精度时钟,内核定时器的工作方式:
- 系统启动后,会读取时钟源设备(RTC, HPET,PIT…),初始化当前系统时间;
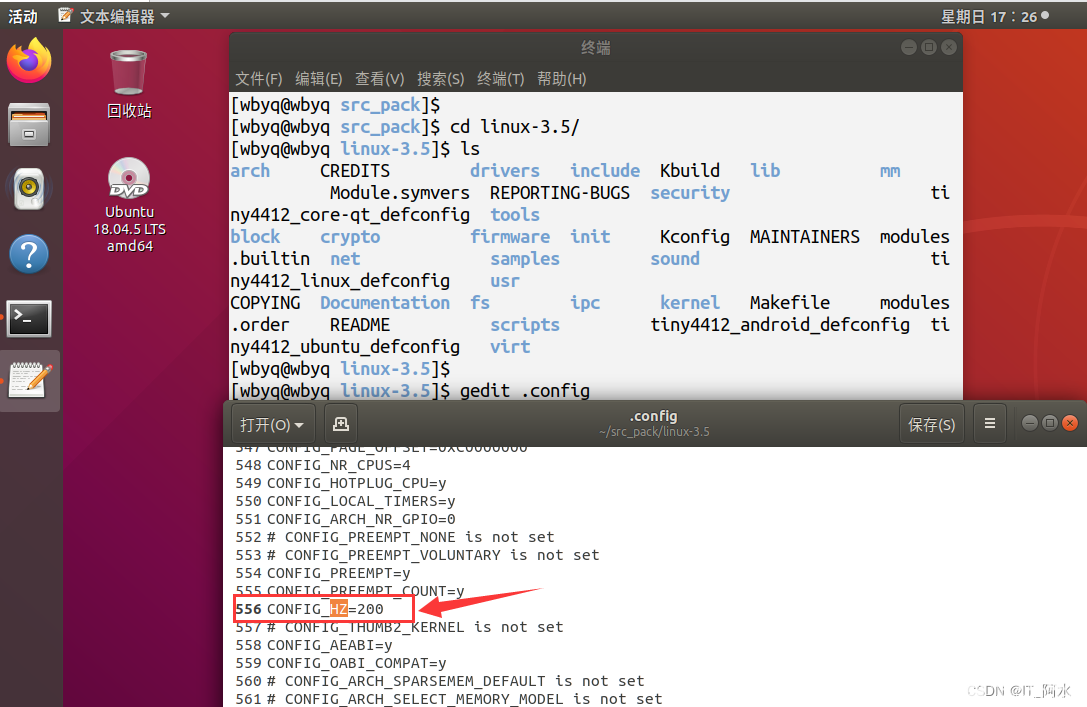
- 内核会根据HZ(系统定时器频率,节拍率)参数值,设置时钟事件设备,启动tick(节拍)中断。HZ表示1秒种产生多少个时钟硬件中断,tick就表示连续两个中断的间隔时间。在我电脑上,HZ=250, 一个tick = 1/HZ, 所以默认一个tick为4ms。
CONFIG_HZ=250
- 设置时钟事件设备后,时钟事件设备会定时产生一个tick中断,触发时钟中断处理函数,更新系统时钟,并检测timer wheel,进行超时事件的处理。
在上面工作方式下,Linux 2.6.16 之前,内核软件定时器采用timer wheel多级时间轮的实现机制,维护操作系统的所有定时事件。timer wheel的触发是基于系统tick周期性中断。
所以说这之前,linux只能支持ms级别的时钟,随着时钟源硬件设备的精度提高和软件高精度计时的需求,有了高精度时钟的内核设计。
Linux 2.6.16 ,内核支持了高精度的时钟,内核采用新的定时器hrtimer,其实现逻辑和Linux 2.6.16 之前定时器逻辑区别:
- hrtimer采用红黑树进行高精度定时器的管理,而不是时间轮;
- 高精度时钟定时器不在依赖系统的tick中断,而是基于事件触发。
旧内核的定时器实现依赖于系统定时器硬件定期的tick,基于该tick,内核会扫描timer wheel处理超时事件,会更新jiffies,wall time(墙上时间,现实时间),process的使用时间等等工作。
新的内核不再会直接支持周期性的tick,新内核定时器框架采用了基于事件触发,而不是以前的周期性触发。新内核实现了hrtimer(high resolution timer),hrtimer的设计目的,就是为了解决time wheel的缺点:
- 低精度;timer wheel只能支持ms级别的精度,hrtimer可以支持ns级别;
- Timer wheel与内核其他模块的高耦合性;
新内核的hrtimer的触发和设置不像之前在定期的tick中断中进行,而是动态调整的,即基于事件触发,hrtimer的工作原理:通过将高精度时钟硬件的下次中断触发时间设置为红黑树中最早到期的 Timer 的时间,时钟到期后从红黑树中得到下一个 Timer 的到期时间,并设置硬件,如此循环反复。
在高精度时钟模式下,操作系统内核仍然需要周期性的tick中断,以便刷新内核的一些任务。前面可以知道,hrtimer是基于事件的,不会周期性出发tick中断,所以为了实现周期性的tick中断(dynamic tick):系统创建了一个vwin tick 时钟的特殊 hrtimer,将其超时时间设置为一个tick时长,在超时回来后,完成对应的工作,然后再次设置下一个tick的超时时间,以此达到周期性tick中断的需求。
引入了dynamic tick,是为了能够在使用高精度时钟的同时节约能源,,这样会产生tickless 情况下,会跳过一些 tick。这里只是简单介绍,有兴趣可以读kernel源码。
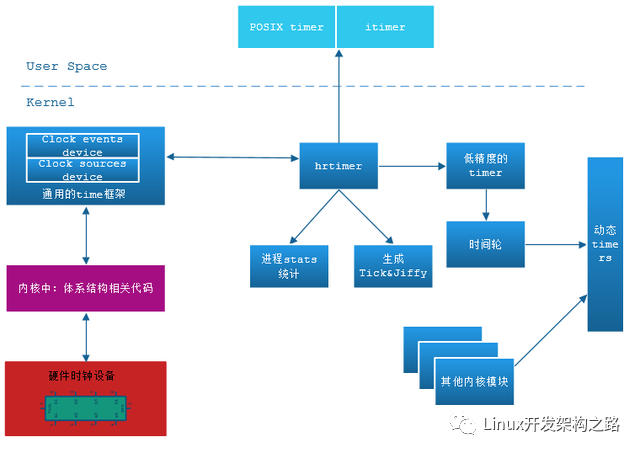
上图1是Linux 2.6.16以来内核定时器实现的结构,
新内核对相关的时间硬件设备进行了统一的封装,定义了主要有下面两个结构:
- 时钟源设备(closk source device):抽象那些能够提供计时功能的系统硬件,比如 RTC(Real Time Clock)、TSC(Time Stamp Counter),HPET,ACPI PM-Timer,PIT等。不同时钟源提供的精度不一样,现在pc大都是支持高精度模式(high-resolution mode)也支持低精度模式(low-resolution mode)。
- 时钟事件设备(clock event device):系统中可以触发 one-shot(单次)或者周期性中断的设备都可以作为时钟事件设备。
当前内核同时存在新旧timer wheel 和 hrtimer两套timer的实现,内核启动后会进行从低精度模式到高精度时钟模式的切换,hrtimer模拟的tick中断将驱动传统的低精度定时器系统(基于时间轮)和内核进程调度。
内核定时器系统增加了hrtimer之后,对于用户层开放的定时器相关接口基本都是通过hrtimer进行实现的,从内核源码可以看到:
* These timers are currently used for:
* - itimers
* - POSIX timers
* - nanosleep
* - precise in-kernel timing
*
2. 用户层定时器API接口
上面介绍完linux内核定时器的实现后,下面简单说一下,基于内核定时器实现的,对用户层开放的定时器API:间隔定时器itimer和POSIX定时器。
2.1 常见定时功能的API:sleep系列
在介绍itimer和POSIX定时器之前,我们先看看我们经常遇到过具有定时功能的库函数API接口:
sleep()
usleep()
nanosleep()
alarm:
alarm()函数可以设置一个定时器,在特定时间超时,并产生SIGALRM信号,如果不忽略或不捕捉该信号,该进程会被终止。
unsigned int alarm(unsigned int seconds);
return:0或到期剩余秒数
那么alarm在是如何实现的?Glibc中alarm是基于间隔定时器itimer来实现的(文章后面会说到itimer是基于hrtimer实现的)。如下alarm在库函数下的实现,alarm调用了setitimer系统调用:
alarm (seconds)
unsigned int seconds;
{
...
if (__setitimer (ITIMER_REAL, &new, &old) < 0)
return 0;
...
}
libc_hidden_def (alarm)
sleep:
sleep和alarm的功能类似,不过sleep会让进程挂起, 在定时器超时内核会产生SIGALRM信号,如果不忽略或不捕捉该信号,该进程会被终止。
那么sleep是如何实现的?Glibc的sleep实现如下:可见其实调用alarm实现的,在alarm的基础上注册了SIGALRM信号处理函数,用于在定时器到期时,捕获到信号,回到睡眠的地方。所以其实可以看出sleep就是对alarm的特化。
__sleep (unsigned int seconds)
{
...
struct sigaction act, oact;
...
//注册信号回调函数
act.sa_handler = sleep_handler;
act.sa_flags = 0;
act.sa_mask = oset;
if (sigaction (SIGALRM, &act, &oact) < 0)
return seconds;
...
//调用alarm API进行操作
remaining = alarm (seconds);
}
weak_alias (__sleep, sleep)
usleep:
usleep支持精度更高的微妙级别的定时操作,
{
struct timespec ts = { .tv_sec = (long int) (useconds / 1000000),
.tv_nsec = (long int) (useconds % 1000000) * 1000ul };
/* Note the usleep() is a cancellation point. But since we call
nanosleep() which itself is a cancellation point we do not have
to do anything here. */
return __nanosleep (&ts, NULL);
}
Bsd的usleep实现如下:
useconds_t useconds;
{
struct timeval delay;
delay.tv_sec = 0;
delay.tv_usec = useconds;
return __select (0, (fd_set *) NULL, (fd_set *) NULL, (fd_set *) NULL,
&delay);
}
nanosleep:
nanosleep()glibc的API是直接调用linux内核的nanosleep,内核的nanosleep采用了hrtimer进行实现。
alarm(), sleep()系列,以及后面的间隔定时器itimer都是基于SIGALRM信号进行触发的。所以它们是不能同时使用的。
2.2 间隔定时器itimer
间隔定时器的接口如下:
int getitimer(int which, struct itimerval *curr_value);
int setitimer(int which, const struct itimerval *new_value,
struct itimerval *old_value);
结构定义:
struct itimerval {
struct timeval it_interval; /* next value :间隔时间*/
struct timeval it_value; /* current value:到期时间*/
};
struct timeval {
time_t tv_sec; /* seconds */
s
可以通过调用上面两个API接口来设置和获取间隔定时器信息。系统为每个进程提供了3种itimer,每种定时器在不同时间域递减,当定时器超时,就会向进程发送一个信号,并且重置定时器。3种定时器的类型,如下表所示:

表1 参数which与定时器类型
在Linux 2.6.16 之前,itimer的实现是基于内核定时器timer wheel封装成的定时器接口。内核封装的定时器接口是提供给其他内核模块使用,也是其他定时器的基础。itimer通过内核定时器的封装,生成提供给用户层使用的接口setitimer和getitimer。内核定时器timer wheel提供的内核态调用接口为:可参考
del_timer()
init_timer()
在Linux 2.6.16 以来,itimer不再采用基于timer wheel的内核定时器进行实现。而是换成了高精度的内核定时器hrtimer进行实现。
如果定时器超时时,进程是处于运行状态,那么超时的信号会被立刻传送给该进程,否则信号会被延迟传送,延迟时间要根据系统的负载情况。所以这里有一个BUG:当系统负载很重的情况下,对于ITIMER_REAL定时器有可能在上一次超时信号传递完成前再次超时,这样就会导致第二次超时的信号丢失。
每个进程中同一种定时器只能使用一次。
该系统调用在POSIX.1-2001中定义了,但在POSIX.1-2008中已被废弃。所以建议使用POSIX定时器API(timer_gettime, timer_settime)代替。
函数alarm本质上设置的是低精确、非重载的ITIMER_REAL类定时器,它只能精确到秒,并且每次设置只能产生一次定时。函数setitimer 设置的定时器则不同,它们不但可以计时到微妙(理论上),还能自动循环定时。在一个Unix进程中,不能同时使用alarm和ITIMER_REAL类定时器。
下面是测试代码:
#include
#include
#include
void sig_handler(int signo)
{
std::cout<<"recieve sigal: "<}
int main()
{
signal(SIGALRM, sig_handler);
struct itimerval timer_set;
//启动时间(5s后启动)
timer_set.it_value.tv_sec = 5;
timer_set.it_value.tv_usec = 0;
//间隔定时器间隔:2s
timer_set.it_interval.tv_sec = 2;
timer_set.it_interval.tv_usec = 0;
if(setitimer(ITIMER_REAL, &timer_set, NULL) < 0)
{
std::cout<<"start timer failed..."< return 0;
}
int temp;
std::cin>>temp;
return 0;
};
<
2.3 POSIX定时器
POSIX定时器的是为了解决间隔定时器itimer的以下问题:
- 一个进程同一时刻只能有一个同一种类型(ITIMER_REAL, ITIMER_PROF, ITIMER_VIRT)的itimer。POSIX定时器在一个进程中可以创建任意多个timer。
- itimer定时器到期后,只能通过信号(SIGALRM,SIGVTALRM,SIGPROF)的方式通知进程,POSIX定时器到期后不仅可以通过信号进行通知,还可以使用自定义信号,还可以通过启动一个线程来进行通知。
- itimer支持us级别,POSIX定时器支持ns级别。
POSIX定时器提供的定时器API如下:
int timer_settime(timer_t timerid, int flags, const struct itimerspec *value, struct itimerspect *ovalue);
int timer_gettime(timer_t timerid,struct itimerspec *value);
int timer_getoverrun(timer_t timerid);
int timer_delete (timer_t timerid);
其中时间结构itimerspec定义如下:该结构和itimer的itimerval结构用处和含义类似,只是提供了ns级别的精度
{
struct timespec it_interval; // 时间间隔
struct timespec it_value; // 首次到期时间
};
struct timespec
{
time_t tv_sec //Seconds.
long tv_nsec //Nanoseconds.
};
it_value表示定时间经过这么长时间到时,当定时器到时候,就会将it_interval的值赋给it_value。如果it_interval等于0,那么表示该定时器不是一个时间间隔定时器,一旦it_value到期后定时器就回到未启动状态。
timer_create(clockid_t clock_id, struct sigevent *evp, timer_t *timerid)
创建一个POSIX timer,在创建的时候,需要指出定时器的类型,定时器超时通知机制。创建成功后通过参数返回创建的定时器的ID。
参数clock_id用来指定定时器时钟的类型,时钟类型有以下6种:
CLOCK_REALTIME:系统实时时间,即日历时间;
- CLOCK_MONOTONIC:从系统启动开始到现在为止的时间;
- CLOCK_PROCESS_CPUTIME_ID:本进程启动到执行到当前代码,系统CPU花费的时间;
- CLOCK_THREAD_CPUTIME_ID:本线程启动到执行到当前代码,系统CPU花费的时间;
- CLOCK_REALTIME_HR:CLOCK_REALTIME的细粒度(高精度)版本;
- CLOCK_MONOTONIC_HR:CLOCK_MONOTONIC的细粒度版本;
struct sigevent设置了定时器到期时的通知方式和处理方式等,结构的定义如下:
{
int sigev_notify; //设置定时器到期后的行为
int sigev_signo; //设置产生信号的信号码
union sigval sigev_value; //设置产生信号的值
void (*sigev_notify_function)(union sigval);//定时器到期,从该地址启动一个线程
pthread_attr_t *sigev_notify_attributes; //创建线程的属性
}
union sigval
{
int sival_int; //integer value
void *sival_ptr; //pointer value
}
如果sigevent传入NULL,那么定时器到期会产生默认的信号,对CLOCK_REALTIMER来说,默认信号就是SIGALRM,如果要产生除默认信号之外的其他信号,程序必须将evp->sigev_signo设置为期望的信号码。
如果几个定时器产生了同一个信号,处理程序可以用 sigev_value来区分是哪个定时器产生了信号。要实现这种功能,程序必须在为信号安装处理程序时,使用struct sigaction的成员sa_flags中的标志符SA_SIGINFO。
sigev_notify的值可取以下几种:
- SIGEV_NONE:定时器到期后什么都不做,只提供通过timer_gettime和timer_getoverrun查询超时信息。
- SIGEV_SIGNAL:定时器到期后,内核会将sigev_signo所指定的信号,传送给进程,在信号处理程序中,si_value会被设定为sigev_value的值。
- SIGEV_THREAD:定时器到期后,内核会以sigev_notification_attributes为线程属性创建一个线程,线程的入口地址为sigev_notify_function,传入sigev_value作为一个参数。
timer_settime(timer_t timerid, int flags, const struct itimerspec *value, struct itimerspect *ovalue)
创建POSIX定时器后,该定时器并没有启动,需要通过timer_settime()接口设置定时器的到期时间和周期触发时间。
flags字段标识到期时间是一个绝对时间还是一个相对时间。
# define TIMER_ABSTIME 1
如果flags的值为TIMER_ABSTIME,则value的值为一个绝对时间。否则,value为一个相对时间。
timer_getoverrun(timer_t timerid)
取得一个定时器的超限运行次数:有可能一个定时器到期了,而同一定时器上一次到期时产生的信号还处于挂起状态。在这种情况下,其中的一个信号可能会丢失。这就是定时器超限。程序可以通过调 用timer_getoverrun来确定一个特定的定时器出现这种超限的次数。定时器超限只能发生在同一个定时器产生的信号上。由多个定时器,甚至是那 些使用相同的时钟和信号的定时器,所产生的信号都会排队而不会丢失。
执行成功时,timer_getoverrun()会返回定时器初次到期与通知进程(例如通过信号)定时器已到期之间额外发生的定时器到期次数。举例来说,在我们之前的例子中,一个1ms的定时器运行了10ms,则此调用会返回9。如果超限运行的次数等于或大于DELAYTIMER_MAX,则此调用会返回DELAYTIMER_MAX。
执行失败时,此函数会返回-1并将errno设定会EINVAL,这个唯一的错误情况代表timerid指定了无效的定时器。
timer_delete (timer_t timerid)
删除一个定时器:一次成功的timer_delete()调用会销毁关联到timerid的定时器并且返回0。执行失败时,此调用会返回-1并将errno设定会 EINVAL,这个唯一的错误情况代表timerid不是一个有效的定时器。
POSIX定时器通过调用内核的posix_timer进行实现,但glibc对POSIX timer进行了一定的封装,例如如果POSIX timer到期通知方式被设置为 SIGEV_THREAD 时,glibc 需要自己完成一些辅助工作,因为内核无法在 Timer 到期时启动一个新的线程。
timer_create (clock_id, evp, timerid)
clockid_t clock_id;
struct sigevent *evp;
timer_t *timerid;
{
if (evp == NULL || __builtin_expect (evp->sigev_notify != SIGEV_THREAD, 1))
{
...
}
else
{
...
/* Create the helper thread. */
pthread_once (&__helper_once, __start_helper_thread);
...
}
...
}
可以看到 GLibc 发现用户需要启动新线程通知时,会自动调用 pthread_once 启动一个辅助线程(__start_helper_thread),用 sigev_notify_attributes 中指定的属性设置该辅助线程。
然后 glibc 启动一个普通的 POSIX Timer,将其通知方式设置为:SIGEV_SIGNAL | SIGEV_THREAD_ID。这样就可以保证内核在 timer 到期时通知辅助线程。通知的 Signal 号为 SIGTIMER,并且携带一个包含了到期函数指针的数据。这样,当该辅助 Timer 到期时,内核会通过 SIGTIMER 通知辅助线程,辅助线程可以在信号携带的数据中得到用户设定的到期处理函数指针,利用该指针,辅助线程调用 pthread_create() 创建一个新的线程来调用该处理函数。这样就实现了 POSIX 的定义。
3. 自定义定时器实现方案
在业务项目中,对于系统提供的定时器API往往很难满足我们的需求:
itimer在进程中每种timer类型(ITIMER_REAL, ITIMER_PROF, ITIMER_VIRT)只能使用一个,另外一点就是他是基于signal进行超时提醒,不仅和alarm,sleep这些api冲突,而且在业务代码中signal是个很不可控的机制,尽量都会减少使用。
POSIX定时器在itimer基础上进行了很大的改进,解决了itimer的不足,可以说POSIX定时器可以满足了业务很多的需求。
3.1 基于小根堆的定时器实现
小根堆定时器的实现方式,是最常见的一种实现定时器的方式。堆顶时钟保存最先到期的定时器,基于事件触发的定时器系统可以根据堆顶定时器到期时间,进行睡眠。基于周期性睡眠的定时器系统,每次只需遍历堆顶的定时器是否到期,即可。堆顶定时器超时后,继续调整堆,使其保持为小根堆并同时对堆顶定时器进行超时判断。
小根堆定时器在插入时的时间复杂度在O(lgn)(n为插入时定时器堆的定时器数量),定时器超时处理时调整堆的复杂度在所有定时器都超时情况下为:O(nlgn)。在一般情况下,小根堆的实现方式可满足业务的基本需求。
3.2 基于时间轮的定时器实现
定时器的实现方式有两种:一级时间轮和多级时间轮。
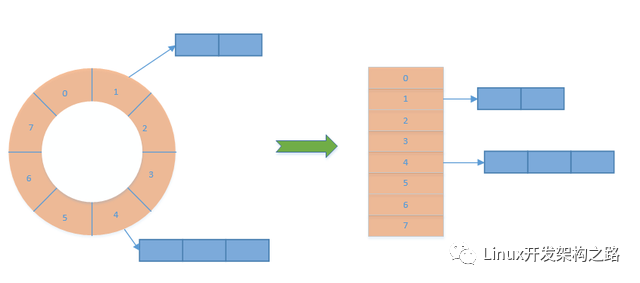
一级时间轮
一级时间轮如下图所示:一个轮子(数组实现),轮子的每个槽(spoke)后面会挂一个timer列表,表示当命中该spoke时,timer列表的所有定时器全部超时。
如果定时器轮的精度是1ms,那么spoke个数为2^10时,仅仅能够表示1s,2^20表示17.476min.
如果精度为1s,那么spoke个数为2^10时,能够表示17min,2^20表示12day.
所有这种一级时间轮的实现方式所带来的空间复杂度还是不小的。特别是在需要跨度比较长的定时器时。基于此,就出现了多级时间轮,也就是linux2.6.16之前内核所采用的定时器的实现方式。
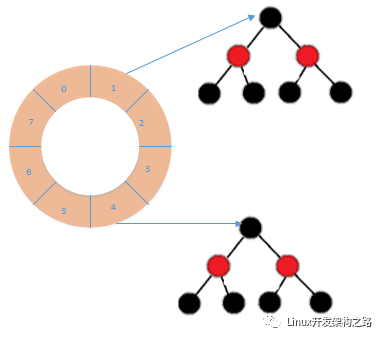
简单时间轮还有很多实现方式,此时时间轮的每个spoke的含义不再是时间精度,而是某个hashkey, 例如ACE当中采用的简单时间轮,轮子的含义:
( 触发时间 >> 分辨率的位数)&(spoke大小-1)
每个spoke所链接的timer列表可以采用很高效的multimap来实现,让timer的插入时间可以降到O(lgn),到期处理时间最坏为O(nlgn),n为每个spoke中的timer个数。
多级时间轮
多级时间轮的实现方式被比作经典的”水表实现方式”,一级时间轮只有一个进制,多级时间轮采用了不同的进制,最低级的时间轮每个spoke表示基本的时间精度,次级时间轮每个spoke表示的时间精度为最低级时间轮所能表示时间长度,依次类推。例如内核的时间轮采用5级时间轮,每一级时间轮spoke个数从低级到高级分别为:8,6,6,6,6,所能表达的时间长度为:2^6 * 2^6 * 2^6 * 2^6 * 2^8 = 2^32 ticks,在系统tick精度为10ms时,内核时间轮所能表示的时间跨度为42949672.96s,约为497天。
那么多级时间轮如何工作的呢:
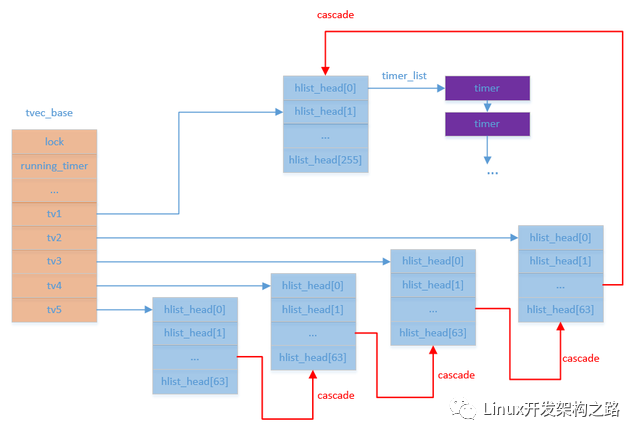
- Insert:
定时器的插入,首先都要根据定时器的超时时间与每级时间轮所能表示的时长进行比较,来觉得插入到那个轮子中,再根据当前轮子已走的索引,计算出待插入定时器在该轮子中应插入的spoke。
#define WHEEL_THRESHOLD_LEVEL_2 (0x01 << (8 + 6))
#define WHEEL_THRESHOLD_LEVEL_3 (0x01 << (8 + 2 * 6))
#define WHEEL_THRESHOLD_LEVEL_4 (0x01 << (8 + 3 * 6))
#define WHEEL_THRESHOLD_LEVEL_5 (0x01 << (8 + 4 * 6))
- Schedule:
多级时间轮定时器触发机制为周期性tick出发,每个tick到来,最低级的tv1的spoke index都会+1,如果该spoke中有timer,那么就处理该timer list中的所有超时timer。
- Cascade:
Cascade可以翻译成降级处理。每个tick到来,都只会去检测最低级的tv1的时间轮,因为多级时间轮的设计决定了最低级的时间轮永远保存这最近要超时的定时器。
多级时间轮最重要的一个处理流程就是cascade,当每一级(除了最高级)时间轮走到超出该级时间轮的范围时,就会触发上一级时间轮所在spoke+1的cascade过程,如果上一级时间轮也走出来时间轮的范围,也同样会触发cascade过程,这是一个递归过程。
在cascade过程中存在一种极限情况,所有的时间轮都会进行cascade处理,这个时候tv2, tv3, tv4, tv5的hlsit_head[0]都会发送变动,这个过程在定时数量比较大的情况下,会是一个比较耗时的处理流程。
-
参数
+关注
关注
11文章
1829浏览量
32194 -
定时器
+关注
关注
23文章
3246浏览量
114713 -
LINUX内核
+关注
关注
1文章
316浏览量
21644 -
时钟系统
+关注
关注
1文章
101浏览量
11715
发布评论请先 登录
相关推荐
Linux驱动开发-内核定时器
「正点原子Linux连载」第五十章Linux内核定时器实验
「正点原子Linux连载」第五十章Linux内核定时器实验
Linux和RTOS的时钟和定时器怎么使用
Linux下实时定时器的实现及应用
STM32基于cubeMX实现定时器点灯

SysTick 定时器
详细剖析Linux和RTOS(RT-Thread)的时钟和定时器的使用





 工商网监
工商网监
评论