 SPDK在虚拟化场景下的使用方法
SPDK在虚拟化场景下的使用方法
一.概述
随着越来越多公有云服务提供商采用SPDK技术作为其高性能云存储的核心技术之一,intel推出的SPDK技术备受业界关注。本篇博文就和大家一起探索SPDK。
什么是SPDK?为什么需要它?
SPDK(全称Storage Performance Development Kit),提供了一整套工具和库,以实现高性能、扩展性强、全用户态的存储应用程序。它是继DPDK之后,intel在存储领域推出的又一项颠覆性技术,旨在大幅缩减存储IO栈的软件开销,从而提升存储性能,可以说它就是为了存储性能而生。
为便于大家理解,我们先介绍一下SPDK在虚拟化场景下的使用方法,以给大家一些直观的认识。
- DPDK的编译与安装
SPDK使用了DPDK中一些通用的功能和机制,因此首先需要下载DPDK的源码并完成编译和安装:
[root@linux:~/DPDK]# make
[root@linux:~/DPDK]# make install (默认安装到/usr/local,包括.a库文件和头文件)
- SPDK的编译
[root@linux:~/SPDK]# make
编译成功后,我们在spdk/app/vhost目录下可以看到一个名为vhost的可执行文件,它就是SPDK在虚拟化场景下为虚拟机模拟程序qemu提供的存储转发服务,借此为虚拟机用户带来高性能的虚拟磁盘。
- 大页内存配置
SPDK vhost进程和qemu进程通过大页共享虚拟机可见内存,因此需要进行一些大页的配置和调整:
- 可通过设置/sys/kernel/mm/hugepages/hugepages-xxx/nr_hugepages来调整大页数量(xxx通常为2M或1G)
- qemu使用挂载到/dev/hugepages目录下的hugetlbfs来使用大页内存,可在挂载参数中指定大页大小,如mount -t hugetlbfs -o pagesize=1G nodev /dev/hugepages
- vhost配置与启动
[root@linux:~/SPDK]# app/vhost/vhost -S /var/tmp -m 0x3 -c etc/spdk/rootw.conf
vhost命令执行过程中,是一个常驻的服务进程;-S参数指定了socket文件的生成的目录,每个虚拟磁盘(vhost-blk)或虚拟存储控制器(vhost-scsi)都会在该目录下产生一个socket文件,以便qemu程序与vhost进程建立连接;-m参数指定了vhost进程中的轮循线程所绑定的物理CPU核,例如0x3代表在0号和1号核上各绑定一个轮循线程;-c参数指定了vhost进程所需的配置文件,例如这里我通过内存设备(SPDK中称之为Malloc设备)提供了一个vhost-blk磁盘:
[root@linux:
/SPDK]# cat etc/spdk/rootw.conf/SPDK]#
[root@linux:
[Malloc]NumberOfLuns 1 #创建一个内存设备,默认名称为Malloc0
LunSizeInMB 128 #该内存设备大小为128M
BlockSize 4096 #该内存设备块大小为4096字节
[VhostBlk0]Name vhost.2 #创建一个vhost-blk设备,名称为vhost.2
Dev Malloc0 #该设备后端对应的物理设备为Malloc0
Cpumask 0x1 #将该设备绑定到0号核的轮循线程上
- 虚拟机启动与验证
vhost进程启动后,我们就可以拉起qemu进程来启动一个新虚拟机,qemu进程的命令行参数如下(重点关注与SPDK vhost相关部分):
-m 1G -object memory-backend-file,id=mem,size=1G,mem-path=/dev/hugepages,share=on -numa node,memdev=mem
-drive file=/mnt/centos.qcow2,format=qcow2,id=virtio-disk0,cache=none,aio=native -device virtio-blk-pci,drive=virtio-disk0,id=blk0
-chardev socket,id=char_rootw,path=/var/tmp/vhost.2 -device vhost-user-blk-pci,id=blk_rootw,chardev=char_rootw
-vnc 0.0.0.0:0
通过上述启动参数,我们可以看出:
- vhost进程和qemu进程通过大页方式共享虚拟机可见的所有内存(原因我们将在深入分析时讨论)
- qemu在配置vhost-user-blk-pci设备时,只需要指定vhost生成的socket文件即可(-S参数指定的路径后拼接上设备名称)
虚拟机启动成功后,我们通过vnc工具登陆虚拟机,执行lsblk命令可以查看到vda和vdb两个virtio-blk块设备,表明vhost后端已成功生效。这里要说明一下,qemu中配置的virtio-blk-pci设备、vhost-user-blk-pci设备或vhost-blk-pci设备,在虚拟机内部均呈现为virtio-blk-pci设备,因此在虚拟机中采用相同的virtio-blk-pci和virtio-blk驱动进行使能,如此一来不同的后端实现技术在虚拟机内部均采用一套驱动,可以减少驱动的开发和维护工作量。
如何实现SPDK?
SPDK能实现高性能,得益于以下三个关键技术:
- 全用户态,它把所有必要的驱动全部移到了用户态,避免了系统调用的开销并真正实现内存零拷贝
- 轮循模式,针对高速物理存储设备,采用轮循的方式而非中断通知方式判断请求完成,大大降低时延并减少性能波动
- 无锁机制,在IO路径上避免采用任何锁机制进行同步,降低时延并提升吞吐量
下面我们将深入到SPDK的实现细节,去看看这些关键点分别是如何提升性能的。
- 整体架构
首先,我们来了解一下SPDK内部的整体组件架构:
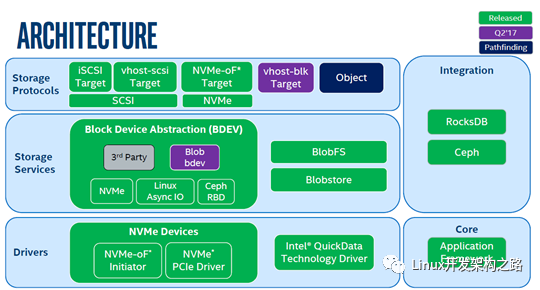
SPDK整体分为三层:
- 存储协议层(Storage Protocols),指SPDK支持存储应用类型。iSCSI Target对外提供iSCSI服务,用户可以将运行SPDK服务的主机当前标准的iSCSI存储设备来使用;vhost-scsi或vhost-blk对qemu提供后端存储服务,qemu可以基于SPDK提供的后端存储为虚拟机挂载virtio-scsi或virtio-blk磁盘;NVMF对外提供基于NVMe协议的存储服务端。注意,图中vhost-blk在spdk-18.04版本中已实现,后面我们主要基于此版本进行代码分析。
- 存储服务层(Storage Services),该层实现了对块和文件的抽象。目前来说,SPDK主要在块层实现了QoS特性,这一层整体上还是非常薄的。
- 驱动层(drivers),这一层实现了存储服务层定义的抽象接口,以对接不同的存储类型,如NVMe,RBD,virtio,aio等等。图中把驱动细分成两层,和块设备强相关的放到了存储服务层,而把和硬件强相关部分放到了驱动层。
- 深入数据面
接下来我们将以SPDK前端配置成vhost-blk、后端配置成NVMe SSD场景为例,来分析整个数据面流程。我们将分两部分完成数据面的分析:
- IO栈对比与线程模型
- IO流程代码解析
- 深入管理面
管理面流程比数据面要复杂得多,也无趣得多。因此我们在分析完数据面流程之后,再回头看看数据面中涉及的各个对象分别是如何被创建和初始化的,这样更利于我们理解这样做的目的,也不会一下子就被这些复杂的流程吓住而无法坚持往下分析。
整个管理面功能包含vhost启动初始化和通过rpc动态管理两个部分,这里我们主要讨化启动初始化,根据启动时的先后顺序,分为
- reactor线程初始化
- bdev子系统初始化
- vhost子系统初始化
- vhost客户端(qemu)连接请求处理
【SPDK】二、IO栈对比与线程模型
这里我们以SPDK前端配置成vhost-blk、后端配置成NVMe SSD场景为例,来分析SPDK的IO栈和线程模型。
IO栈对比与时延分析
我们先来对比一下qemu使用普通内核NVMe驱动和使用SPDK vhost时IO栈的差别,如下图所示:

编辑切换为居中
添加图片注释,不超过 140 字(可选)
无论使用传统内核NVMe驱动,还是使用vhost,虚拟机内部的IO处理流程都是一样的:IO请求下发时需要从用户态应用程序中切换到内核态,并穿过文件系统和virtio-blk驱动后,才能借助IO环(IO Ring)将请求信息传递给虚拟设备进行处理;虚拟设备处理完成后,以中断方式通知虚拟机,虚拟机内进过驱动和文件系统的回调后,最终唤醒应用程序返回用户态继续执行业务逻辑。在intel Xeon E5620@2.4GHz服务器上的测试结果表明,虚拟机内部的请求下发与响应处理总时延约15us。
针对传统内核NVMe驱动,qemu进程中io线程负责处理虚拟机下发的IO请求:它通过virtio backend从IO环中取出请求,并将请求通过系统调用传递给内核块层和NVMe驱动层进行处理,最后由NVMe驱动将请求通过Queue Pair(类似IO环)交由物理NVMe控制器进行处理;NVMe控制器处理完成后以物理中断方式通知qemu io线程,由它将响应放入虚拟机IO环中并以虚拟中断通知虚拟机请求完成。在此我们看到,qemu中总共的处理时延约15us,而NVMe硬件(华为ES3000 NVMe SSD)上的处理时延才10us(读请求)。
针对SPDK vhost,qemu进程不参与IO请求的处理(仅在初始化时起作用),所有虚拟机下发的IO请求均由vhost进程处理。vhost进程以轮循的方式不断从IO环中取出请求(意味着虚拟机下发IO请求时,不用通知虚拟设备),对于取出的每个请求,vhost将其以任务方式交给bdev抽象层进行处理;bdev根据后端设备的类型来选择不同的驱动进行处理,例如对于NVMe设备,将使用用户态的NVMe驱动在用户空间完成对Queue Pair的操作。vhost进程同样会轮循物理NVMe设备的Queue Pair,如果有响应例会立刻进行处理,而无须等待物理中断。vhost在处理NVMe响应过程中,会向虚拟机IO环中添加响应,并以虚拟中断方式通知虚拟机。我们可以看到,vhost中绝大部分操作都是在用户态完成的(中断通知虚拟机时会进入内核态通过KVM模块完成),各层时延均非常短,app和bdev抽象层约2us,NVMe用户态驱动约2us。
因此,端到端时延对比来看,我们可以发现传统NVMe IO栈的总时延约40us,而SPDK用户态NVMe IO栈时延不到30us,时延上有25%以上的优化。另一方面,在吞吐量(IOPS)方面,如果我们给virtio-blk设备配置多队列(确保虚拟机IO压力足够),并在后端NVMe设备不成为瓶颈的前提下,传统NVMe IO栈在单个qemu io线程处理时,最多能达到20万IOPS,而SPDK vhost在单线程处理时可达100万IOPS,同等CPU开销下,吞吐量上有5倍以上的性能提升。传统NVMe IO栈在处理多队列模型时,相比单队列模型,减少了线程间通知开销,一次通知可以处理多个IO请求,因此多队列相比单队列模型会有较大的IOPS提升;而vhost得益于全用户态及轮循模式,进一步减少了内核切换和通知开销,带来了吞吐量的大幅提升。
线程模型分析
在了解了SPDK的IO栈之后,我们进一步来分析一下vhost进程的线程模型,如下图所示。图中示例场景为,一台服务器上插了一张NVMe SSD卡,卡上划分了三个namespace;三个namespace分别配给了三台虚拟机的vhost-user-blk-pci设备。
vhost进程启动时可以配置多个轮循线程(reactor),每个线程绑定一个物理CPU。在示例场景下,我们假设配置了两个轮循线程reactor_0和reactor_1,分别对应物理CPU0和物理CPU1。每配置一个vhost-blk设备时,同样要为该设备绑定物理核,并且只能绑定到一个物理核上,例如这里我们假设vm1的vhost-blk设备绑定到CPU0,vm2和vm3绑定到CPU1。那么reactor_0将轮循vm1中vhost-blk的IO环,reactor_1将依次轮循vm2和vm3的IO环。
vhost线程在操作相同NVMe控制器下的namespace时,不同的vhost线程会申请不同的IO Channel(实际对应NVMe Queue Pair,作用类似虚拟机IO环),并且每个线程都会轮循各自申请的IO Channel中的响应消息。例如图中reactor_0会向NVMe控制器申请QueuePair1,并在轮循过程中注册对该QueuePair的poller函数(负责从中取响应);reactor_1则会向NVMe控制器申请QueuePair2并轮循该QueuePair。如此一来,就能提升对后端NVMe设备的并发访问度,充分发挥物理设备的吞吐量优势。
综上所述,
- 每个vhost线程都会轮循若干个vhost设备的IO环(一个vhost设备无论有多少个环,都只会在一个线程中处理),并且会向有操作述求的物理存储控制器(例如NVMe控制器、virtio-blk控制器、virtio-scsi控制器等)申请一个独立的IO Channel(IO环可以理解为对前端虚拟机呈现的一个IO Channel)并对其进行轮循。
- 无论是前端虚拟机IO环,还是后端IO Channel,都只会在一个vhost线程中被轮循,因此这就避免了多线程并发操作同一个对象,可以通过无锁的方式操作IO环或IO Channel。
- 针对前端虚拟机来说,一个vhost设备无论有多少个环,都只会在一个vhost线程中处理。这种设计上的约束虽说可以简化实现,但也带来了吞吐量性能扩展上的限制,即一个vhost设备在后端物理存储非瓶颈的前提下,最高的IOPS为100万。因此我们可以考虑将vhost的多个IO环拆分到多个vhost线程中处理,进一步提升吞吐量。
【SPDK】三、IO流程代码解析
在分析SPDK数据面代码之前,需要我们对qemu中实现的IO环以及virtio前后端驱动的实现有所了解(后续我计划出专门的博文来介绍qemu)。这里我们仍以SPDK前端配置vhost-blk,后端对接NVMe SSD为例(有关NVMe驱动涉及较多规范细节,这里也不作过于深入的讨论,感兴趣的读者可以结合NVMe规范展开阅读)进行分析。
总流程
前文在分析SPDK IO栈时已经大致分析了IO处理的调用层次,在此我们进一步打开内部实现细节,更细致地分析一下IO处理流程:
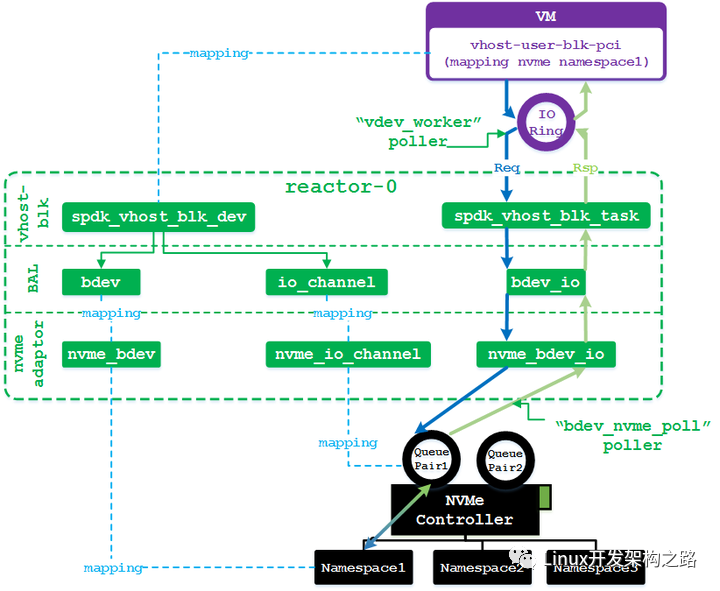
首先,从虚拟机视角来说,它看到的是一个virtio-blk-pci设备,该pci设备内部包含一条virtio总线,其上又连接了virtio-blk设备。qemu在对虚拟机用户呈现这个virtio-blk-pci设备时,采用的具体设备类型是vhost-user-blk-pci(这是virtio-blk-pci设备的一种后端实现方式。另外两种是:vhost-blk-pci,由内核实现后端;普通virtio-blk-pci,由qemu实现后端处理),这样便可与用户态的SPDK vhost进程建立连接。SPDK vhost进程内部对于虚拟机所见的virtio-blk-pci设备也有一个对象来表示它,这就是spdk_vhost_blk_dev。该对象指向一个bdev对象和一个io channel对象,bdev对象代表真正的后端块存储(这里对应NVMe SSD上的一个namespace),io channel代表当前线程访问存储的独立通道(对应NVMe SSD的一个Queue Pair)。这两个对象在驱动层会进一步扩展新的成员变量,用来表示驱动层可见的一些详细信息。
其次,当虚拟机往IO环中放入IO请求后,便立刻被vhost进程中的某个reactor线程轮循到该请求(轮循过种中执行函数为vdev_worker)。reactor线程取出请求后,会将其映成一个任务(spdk_vhost_blk_task)。对于读写请求,会进一步走到bdev层,将任务封状成一个bdev_io对象(类似内核的bio)。bdev_io继续往驱动层递交,它会扩展为适配具体驱动的io对象,例如针对NVMe驱动,bdev_io将扩展成nvme_bdev_io对象。NVMe驱动会根据nvme_bdev_io对象中的请求内容在当前reactor线程对应的QueuePair中生成一个新的请求项,并通知NVMe控制器有新的请求产生。
最后,当物理NVMe控制器完成IO请求后,会往QueuePair中添加IO响应。该响应信息也会很快被reactor线程轮循到(轮循执行函数为bdev_nvme_poll)。reactor取出响应后,根据其id找到对应的nvme_bdev_io,进一步关联到对应的bdev_io,再调用bdev_io中的记录的回调函数。vhost-blk下发请求时注册的回调函数为blk_request_complete_cb,回调参数为当前的spdk_vhost_blk_task对象。在blk_request_complete_cb中会往虚拟机IO环中放入IO响应,并通过虚拟中断通知虚拟机IO完成。
IO请求下发流程代码解析
vhost进程通过vdev_worker函数以轮循方式处理虚拟机下发的IO请求,调用栈如下:
2 -process_vq()
3 |-spdk_vhost_vq_avail_ring_get()
4 -process_blk_request()
5 |-blk_iovs_setup()
6 -spdk_bdev_readv()/spdk_bdev_writev()
7 -spdk_bdev_io_submit()
8 -bdev->fn_table->submit_request()
下面我们先来分析一下vhost-blk层的具体代码实现:
spdk/lib/vhost/vhost-blk.c:
2 static int
3 vdev_worker(void *arg)
4 {
5 /* arg在注册轮循函数时指定,代表当前操作的vhost-blk对象 */
6 struct spdk_vhost_blk_dev *bvdev = arg;
7 uint16_t q_idx;
8
9 /* vhost-blk对象bvdev中含有一个抽象的spdk_vhost_dev对象,其内部记录所有vhost_dev类别对象
10 均含有的公共内容,max_queues代表当前vhost_dev对象共有多少个IO环,virtqueue[]数组记录了
11 所有的IO环信息 */
12 for (q_idx = 0; q_idx < bvdev->vdev.max_queues; q_idx++) {
13 /* 根据IO环的个数,依次处理每个环中的请求 */
14 process_vq(bvdev, &bvdev->vdev.virtqueue[q_idx]);
15 }
16
17 ...
18
19 }
20
21 /* 处理IO环中的所有请求 */
22 static void
23 process_vq(struct spdk_vhost_blk_dev *bvdev, struct spdk_vhost_virtqueue *vq)
24 {
25 struct spdk_vhost_blk_task *task;
26 int rc;
27 uint16_t reqs[32];
28 uint16_t reqs_cnt, i;
29
30 /* 先给出一些关于IO环的知识:
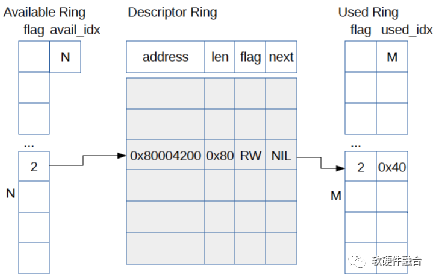
31 (1) 简单来说,每个IO环分成descriptor数组、avail数组和used数组三个部分,数组元素个数均为环的最大请求个数。
32 (2) descriptor数组元素代表一段虚拟机内存,每个IO请求至少包含三段,请求头部段、数据段(至少一个)和响应段。
33 请求头部包含请求类型(读或写)、访问偏移,数据段代表实际的数据存放位置,响应段记录请求处理结果。一般来说,
34 每个IO请求在descriptor中至少要占据三个元素;不过当配置了indirect特性后,一个IO请求只占用一项,只不过
35 该项指向的内存段又是一个descriptor数组,该数组元素个数为IO请求实际所需内存段。
36 (3) avail数组用来记录已下发的IO请求,数组元素内容为IO请求在descriptor数组中的下标,该下标可作为请求的id。
37 (4) used数组用来记录已完成的IO响应,数组元素内容同样为IO在descritpror数组中的下标。
38 */
39
40 /* 从IO环的avail数组中中取出一批请求,将请求id放入reqs数组中;每次将环取空或者最多取32个请求 */
41 reqs_cnt = spdk_vhost_vq_avail_ring_get(vq, reqs, SPDK_COUNTOF(reqs));
42 ...
43
44 /* 依次对reqs数组中的请求进行处理 */
45 for (i = 0; i < reqs_cnt; i++) {
46 ...
47
48 /* 以请求id作为下标,找到对应的task对象。注,初始化时,会按IO环的最大请求个数来申请tasks数组 */
49 task = &((struct spdk_vhost_blk_task *)vq->tasks)[reqs[i]];
50 ...
51
52 bvdev->vdev.task_cnt++; /* 作统计计数 */
53
54 task->used = true; /* 代表tasks数组中该项正在被使用 */
55 task->iovcnt = SPDK_COUNTOF(task->iovs); /* iovs数组将来会记录IO请求中数据段的内存映射信息 */
56 task->status = NULL; /* 将来指向IO响应段,用来给虚拟机返回IO处理结果 */
57 task->used_len = 0;
58
59 /* 将IO环中请求的详细信息记录到task中,并递交给bdev层处理 */
60 rc = process_blk_request(task, bvdev, vq);
61 ...
62 }
63 }
64
65 static int
66 process_blk_request(struct spdk_vhost_blk_task *task, struct spdk_vhost_blk_dev *bvdev,
67 struct spdk_vhost_virtqueue *vq)
68 {
69 const struct virtio_blk_outhdr *req;
70 struct iovec *iov;
71 uint32_t type;
72 uint32_t payload_len;
73 int rc;
74
75 /* 将IO环descriptor数组中记录的请求内存段(以gpa表示,即Guest Physical Address)映成vhost进程中的
76 虚拟地址(vva, vhost virtual address),并保存到task的iovs数组中 */
77 if (blk_iovs_setup(&bvdev->vdev, vq, task->req_idx, task->iovs, &task->iovcnt, &payload_len)) {
78 ...
79 }
80
81 /* 第一个请求内存段为请求头部,即struct virtio_blk_outhdr,记录请求类型、访问位置信息 */
82 iov = &task->iovs[0];
83 ...
84 req = iov->iov_base;
85
86 /* 最后一个请求内存段用来保存请求处理结果 */
87 iov = &task->iovs[task->iovcnt - 1];
88 ...
89 task->status = iov->iov_base;
90
91 /* 除去一头一尾,中间的请求内存段为数据段 */
92 payload_len -= sizeof(*req) + sizeof(*task->status);
93 task->iovcnt -= 2;
94
95 type = req->type;
96
97 switch (type) {
98 case VIRTIO_BLK_T_IN:
99 case VIRTIO_BLK_T_OUT:
100
101 /* 对于读写请求,调用bdev读写接口,并注册请求完成后的回调函数为blk_request_complete_cb */
102 if (type == VIRTIO_BLK_T_IN) {
103 task->used_len = payload_len + sizeof(*task->status);
104 rc = spdk_bdev_readv(bvdev->bdev_desc, bvdev->bdev_io_channel,
105 &task->iovs[1], task->iovcnt, req->sector * 512,
106 payload_len, blk_request_complete_cb, task);
107 } else if (!bvdev->readonly) {
108 task->used_len = sizeof(*task->status);
109 rc = spdk_bdev_writev(bvdev->bdev_desc, bvdev->bdev_io_channel,
110 &task->iovs[1], task->iovcnt, req->sector * 512,
111 payload_len, blk_request_complete_cb, task);
112 } else {
113 SPDK_DEBUGLOG(SPDK_LOG_VHOST_BLK, "Device is in read-only mode!n");
114 rc = -1;
115 }
116 break;
117 case VIRTIO_BLK_T_GET_ID:
118 ...
119 break;
120 default:
121 ...
122 return -1;
123 }
124
125 return 0;
126 }
127
128 static int
129 blk_iovs_setup(struct spdk_vhost_dev *vdev, struct spdk_vhost_virtqueue *vq, uint16_t req_idx,
130 struct iovec *iovs, uint16_t *iovs_cnt, uint32_t *length)
131 {
132 struct vring_desc *desc, *desc_table;
133 uint16_t out_cnt = 0, cnt = 0;
134 uint32_t desc_table_size, len = 0;
135 int rc;
136
137 /* 从IO环descriptor数组中获取请求对应的所有内存段信息,并映射成vva地址 */
138 rc = spdk_vhost_vq_get_desc(vdev, vq, req_idx, &desc, &desc_table, &desc_table_size);
139 ...
140
141 while (1) {
142 ...
143 len += desc->len;
144
145 out_cnt += spdk_vhost_vring_desc_is_wr(desc);
146
147 rc = spdk_vhost_vring_desc_get_next(&desc, desc_table, desc_table_size);
148 if (rc != 0) {
149 ...
150 return -1;
151 } else if (desc == NULL) {
152 break;
153 }
154 }
155
156 ...
157
158 *length = len;
159 *iovs_cnt = cnt;
160 return 0;
161 }
162
163 int
164 spdk_vhost_vq_get_desc(struct spdk_vhost_dev *vdev, struct spdk_vhost_virtqueue *virtqueue,
165 uint16_t req_idx, struct vring_desc **desc, struct vring_desc **desc_table,
166 uint32_t *desc_table_size)
167 {
168
169 *desc = &virtqueue->vring.desc[req_idx];
170
171 if (spdk_vhost_vring_desc_is_indirect(*desc)) {
172 assert(spdk_vhost_dev_has_feature(vdev, VIRTIO_RING_F_INDIRECT_DESC));
173 *desc_table_size = (*desc)->len / sizeof(**desc);
174
175 /* 将IO环中记录的gpa地址转换成vhost的虚拟地址,qemu和vhost之间的内存映射关系管理我们将在管理面分析时讨论 */
176 *desc_table = spdk_vhost_gpa_to_vva(vdev, (*desc)->addr, sizeof(**desc) * *desc_table_size);
177 *desc = *desc_table;
178 if (*desc == NULL) {
179 return -1;
180 }
181
182 return 0;
183 }
184
185 *desc_table = virtqueue->vring.desc;
186 *desc_table_size = virtqueue->vring.size;
187
188 return 0;
189 }
接着,我们看一下bdev层对IO请求的处理,以读请求为例:
spdk/lib/bdev/bdev.c:
2 spdk_bdev_readv(struct spdk_bdev_desc *desc, struct spdk_io_channel *ch,
3 struct iovec *iov, int iovcnt,
4 uint64_t offset, uint64_t nbytes,
5 spdk_bdev_io_completion_cb cb, void *cb_arg)
6 {
7 uint64_t offset_blocks, num_blocks;
8
9 ...
10
11 /* 将字节转换成块进行实际的IO操作 */
12 return spdk_bdev_readv_blocks(desc, ch, iov, iovcnt, offset_blocks, num_blocks, cb, cb_arg);
13 }
14
15 int spdk_bdev_readv_blocks(struct spdk_bdev_desc *desc, struct spdk_io_channel *ch,
16 struct iovec *iov, int iovcnt,
17 uint64_t offset_blocks, uint64_t num_blocks,
18 spdk_bdev_io_completion_cb cb, void *cb_arg)
19 {
20 struct spdk_bdev *bdev = desc->bdev;
21 struct spdk_bdev_io *bdev_io;
22 struct spdk_bdev_channel *channel = spdk_io_channel_get_ctx(ch);
23
24 /* io channel是一个线程强相关对象,不同的线程对应不同的channel,
25 这里spdk_bdev_channel包含一个线程独立的缓存池,先从中申请bdev_io内存(免锁),
26 如果申请不到,再到全局的mempool中申请内存 */
27 bdev_io = spdk_bdev_get_io(channel);
28 ...
29
30 /* 将接口参数记录到bdev_io中,并继续递交 */
31 bdev_io->ch = channel;
32 bdev_io->type = SPDK_BDEV_IO_TYPE_READ;
33 bdev_io->u.bdev.iovs = iov;
34 bdev_io->u.bdev.iovcnt = iovcnt;
35 bdev_io->u.bdev.num_blocks = num_blocks;
36 bdev_io->u.bdev.offset_blocks = offset_blocks;
37 spdk_bdev_io_init(bdev_io, bdev, cb_arg, cb);
38
39 spdk_bdev_io_submit(bdev_io);
40 return 0;
41 }
42
43 static void
44 spdk_bdev_io_submit(struct spdk_bdev_io *bdev_io)
45 {
46 struct spdk_bdev *bdev = bdev_io->bdev;
47
48 if (bdev_io->ch->flags & BDEV_CH_QOS_ENABLED) { /* 开启了bdev的qos特性时走该流程 */
49 ...
50 } else {
51 _spdk_bdev_io_submit(bdev_io); /* 直接递交 */
52 }
53 }
54
55 static void
56 _spdk_bdev_io_submit(void *ctx)
57 {
58 struct spdk_bdev_io *bdev_io = ctx;
59 struct spdk_bdev *bdev = bdev_io->bdev;
60 struct spdk_bdev_channel *bdev_ch = bdev_io->ch;
61 struct spdk_io_channel *ch = bdev_ch->channel; /* 底层驱动对应的io channel */
62 struct spdk_bdev_module_channel *module_ch = bdev_ch->module_ch;
63
64 bdev_io->submit_tsc = spdk_get_ticks();
65 bdev_ch->io_outstanding++;
66 module_ch->io_outstanding++;
67 bdev_io->in_submit_request = true;
68 if (spdk_likely(bdev_ch->flags == 0)) {
69 if (spdk_likely(TAILQ_EMPTY(&module_ch->nomem_io))) {
70 /* 不同的驱动在生成bdev对象时会注册不同的fn_table,这里将调用驱动注册的submit_request函数 */
71 bdev->fn_table->submit_request(ch, bdev_io);
72 } else {
73 bdev_ch->io_outstanding--;
74 module_ch->io_outstanding--;
75 TAILQ_INSERT_TAIL(&module_ch->nomem_io, bdev_io, link);
76 }
77 } else if (bdev_ch->flags & BDEV_CH_RESET_IN_PROGRESS) {
78 ...
79 } else if (bdev_ch->flags & BDEV_CH_QOS_ENABLED) {
80 ...
81 } else {
82 ...
83 }
84 bdev_io->in_submit_request = false;
85 }
最后,我们来看一下bdev的NVMe驱动的处理逻辑:
spdk/lib/bdev/bdev_nvme.c:
2 .destruct = bdev_nvme_destruct,
3 .submit_request = bdev_nvme_submit_request,
4 .io_type_supported = bdev_nvme_io_type_supported,
5 .get_io_channel = bdev_nvme_get_io_channel,
6 .dump_info_json = bdev_nvme_dump_info_json,
7 .write_config_json = bdev_nvme_write_config_json,
8 .get_spin_time = bdev_nvme_get_spin_time,
9 };
10
11 static void
12 bdev_nvme_submit_request(struct spdk_io_channel *ch, struct spdk_bdev_io *bdev_io)
13 {
14 int rc = _bdev_nvme_submit_request(ch, bdev_io);
15
16 if (spdk_unlikely(rc != 0)) {
17 if (rc == -ENOMEM) {
18 spdk_bdev_io_complete(bdev_io, SPDK_BDEV_IO_STATUS_NOMEM);
19 } else {
20 spdk_bdev_io_complete(bdev_io, SPDK_BDEV_IO_STATUS_FAILED);
21 }
22 }
23 }
24
25 static int
26 _bdev_nvme_submit_request(struct spdk_io_channel *ch, struct spdk_bdev_io *bdev_io)
27 {
28 /* 将ch扩展成具体的nvme_io_channel,其对应一个queue parir */
29 struct nvme_io_channel *nvme_ch = spdk_io_channel_get_ctx(ch);
30 if (nvme_ch->qpair == NULL) {
31 /* The device is currently resetting */
32 return -1;
33 }
34
35 switch (bdev_io->type) {
36
37 /* 针对读写请求,会将bdev_io扩展成nvme_bdev_io请求后,再将请求内容填入io channel
38 对应的queue pair中,并通知物理硬件处理 */
39 case SPDK_BDEV_IO_TYPE_READ:
40 spdk_bdev_io_get_buf(bdev_io, bdev_nvme_get_buf_cb,
41 bdev_io->u.bdev.num_blocks * bdev_io->bdev->blocklen);
42 return 0;
43
44 case SPDK_BDEV_IO_TYPE_WRITE:
45 return bdev_nvme_writev((struct nvme_bdev *)bdev_io->bdev->ctxt,
46 ch,
47 (struct nvme_bdev_io *)bdev_io->driver_ctx,
48 bdev_io->u.bdev.iovs,
49 bdev_io->u.bdev.iovcnt,
50 bdev_io->u.bdev.num_blocks,
51 bdev_io->u.bdev.offset_blocks);
52 ...
53 default:
54 return -EINVAL;
55 }
56
57 return 0;
58 }
详细的NVMe请求处理不在本文的讨论范围内,感兴趣的读者可以自行深入分析。
IO响应返回流程代码解析
reactor线程通过bdev_nvme_poll函数获知已完成的NVMe响应,最终会调用bdev层的spdk_bdev_io_complete来处理响应:
spdk/lib/bdev/bdev.c:
2 spdk_bdev_io_complete(struct spdk_bdev_io *bdev_io, enum spdk_bdev_io_status status)
3 {
4 ...
5 bdev_io->status = status;
6
7 ...
8 _spdk_bdev_io_complete(bdev_io);
9 }
10
11 static inline void
12 _spdk_bdev_io_complete(void *ctx)
13 {
14 struct spdk_bdev_io *bdev_io = ctx;
15
16 ...
17
18 /* 如果请求执行成功,则更新一些统计信息 */
19 if (bdev_io->status == SPDK_BDEV_IO_STATUS_SUCCESS) {
20 switch (bdev_io->type) {
21 case SPDK_BDEV_IO_TYPE_READ:
22 bdev_io->ch->stat.bytes_read += bdev_io->u.bdev.num_blocks * bdev_io->bdev->blocklen;
23 bdev_io->ch->stat.num_read_ops++;
24 bdev_io->ch->stat.read_latency_ticks += (spdk_get_ticks() - bdev_io->submit_tsc);
25 break;
26 case SPDK_BDEV_IO_TYPE_WRITE:
27 bdev_io->ch->stat.bytes_written += bdev_io->u.bdev.num_blocks * bdev_io->bdev->blocklen;
28 bdev_io->ch->stat.num_write_ops++;
29 bdev_io->ch->stat.write_latency_ticks += (spdk_get_ticks() - bdev_io->submit_tsc);
30 break;
31 default:
32 break;
33 }
34 }
35
36 /* 调用上层注册回调,这里将回到vhost-blk的blk_request_complete_cb */
37 bdev_io->cb(bdev_io, bdev_io->status == SPDK_BDEV_IO_STATUS_SUCCESS, bdev_io->caller_ctx);
38 }
39 spdk/lib/vhost/vhost_blk.c:
40
41 static void
42 blk_request_complete_cb(struct spdk_bdev_io *bdev_io, bool success, void *cb_arg)
43 {
44 struct spdk_vhost_blk_task *task = cb_arg;
45
46 spdk_bdev_free_io(bdev_io); /* 释放bdev_io */
47 blk_request_finish(success, task);
48 }
49
50 static void
51 blk_request_finish(bool success, struct spdk_vhost_blk_task *task)
52 {
53 *task->status = success ? VIRTIO_BLK_S_OK : VIRTIO_BLK_S_IOERR;
54
55 /* 往虚拟机中放入响应并以虚拟中断方式通知虚拟机IO完成 */
56 spdk_vhost_vq_used_ring_enqueue(&task->bvdev->vdev, task->vq, task->req_idx,
57 task->used_len);
58
59 /* 释放当前task,实际就是将task->used置为false */
60 blk_task_finish(task);
61 }
至此,整个IO流程已经分析完毕,可见SPDK对IO的处理还是非常简洁的,这便是高性能的基石。
【SPDK】四、reactor线程
reactor线程是SPDK中负责实际业务处理逻辑的单元,它们在vhsot服务启动时创建,直到服务停止。目前还不支持reactor线程的动态增减。
reactor线程总流程
我们顺着vhost进程的代码执行顺序来看看总体流程:
2
3 int
4 main(int argc, char *argv[])
5 {
6 struct spdk_app_opts opts = {};
7 int rc;
8
9 /* 首先进行参数解析,解析后的结果保存于opts中 */
10
11 vhost_app_opts_init(&opts);
12
13 if ((rc = spdk_app_parse_args(argc, argv, &opts, "f:S:",
14 vhost_parse_arg, vhost_usage)) !=
15 SPDK_APP_PARSE_ARGS_SUCCESS) {
16 exit(rc);
17 }
18
19 ...
20
21 /* 接着根据配置文件指明的物理核启动reactors线程(主线程最终也成为一个reactor)。
22 这些reactors线程会执行轮循函数,直到外部将服务状态置为退出 */
23
24 /* Blocks until the application is exiting */
25 rc = spdk_app_start(&opts, vhost_started, NULL, NULL);
26
27 /* 所有reactor线程退出后,进行资源清理 */
28 spdk_app_fini();
29
30 return rc;
31 }
上述整体流程中最为重要的便是spdk_app_start函数,该函数内部调用了DPDK关于系统CPU、内存、PCI设备管理等通用性服务代码,这里我们尽可能以理解其功能为主而不做深入的代码分析:
2
3 int
4 spdk_app_start(struct spdk_app_opts *opts, spdk_event_fn start_fn,
5 void *arg1, void *arg2)
6 {
7 struct spdk_conf *config = NULL;
8 int rc;
9 struct spdk_event *app_start_event;
10
11 ...
12
13 /* 将配置文件中的内容导入到config对象中 */
14 config = spdk_app_setup_conf(opts->config_file);
15 ...
16 spdk_app_read_config_file_global_params(opts);
17
18 ...
19
20 /* 调用DPDK系统服务:
21 (1)通过内核sysfs获取物理CPU信息,并通过配置文件指定的运行核,在各个核上启动服务线程;
22 各服务线程启动后因为在等待主线程给它们发送需要执行的任务而处于睡眠状态;
23 (2)基于大页内存创建内存池以供其它模块使用;
24 (3)初始化PCI设备枚举服务,可以实现类似内核的设备发现及驱动初始化流程。SPDK基于此并借
25 助内核uio或vfio驱动实现全用户态的PCI驱动 */
26 /* 完成DPDK的初始化后,SPDK会建立一张由vva(vhost virtual address)到pa(physical address)
27 的内存映射表g_vtophys_map。每当有新的内存映射到vhost中时,都需要调用spdk_mem_register在该
28 表中注册新的映射关系。设计该表的原因是当SPDK向物理设备发送DMA请求时,需要向设备提供pa而非vva */
29 if (spdk_app_setup_env(opts) < 0) {
30 ...
31 }
32
33 /* 这里为reactors分配相应的内存 */
34 /*
35 * If mask not specified on command line or in configuration file,
36 * reactor_mask will be 0x1 which will enable core 0 to run one
37 * reactor.
38 */
39 if ((rc = spdk_reactors_init(opts->max_delay_us)) != 0) {
40 ...
41 }
42
43 ...
44
45 /* 设置一些全局变量 */
46 memset(&g_spdk_app, 0, sizeof(g_spdk_app));
47 g_spdk_app.config = config;
48 g_spdk_app.shm_id = opts->shm_id;
49 g_spdk_app.shutdown_cb = opts->shutdown_cb;
50 g_spdk_app.rc = 0;
51 g_init_lcore = spdk_env_get_current_core();
52 g_app_start_fn = start_fn;
53 g_app_start_arg1 = arg1;
54 g_app_start_arg2 = arg2;
55 app_start_event = spdk_event_allocate(g_init_lcore, start_rpc, (void *)opts->rpc_addr, NULL);
56
57 /* 初始化SPDK的各个子系统,如bdev、vhost均为子系统。但这里需注意一点,此处仅是产生了一个初始化事件,事件的处理要在
58 reactor线程正式进入轮循函数后才开始 */
59 spdk_subsystem_init(app_start_event);
60
61 /* 从此处开始,各个线程(包括主线程)开始执行_spdk_reactor_run,线程名也正式变更为reactor_X;
62 直到所有线程均退出_spdk_reactor_run后,主线程才会返回 */
63 /* This blocks until spdk_app_stop is called */
64 spdk_reactors_start();
65
66 return g_spdk_app.rc;
67 ...
68 }
再看一下spdk_reactors_start:
2
3 void
4 spdk_reactors_start(void)
5 {
6 struct spdk_reactor *reactor;
7 uint32_t i, current_core;
8 int rc;
9
10 g_reactor_state = SPDK_REACTOR_STATE_RUNNING;
11 g_spdk_app_core_mask = spdk_cpuset_alloc();
12
13 /* 针对主线程之外的其它核上的线程,通过发送通知使它们开始执行_spdk_reactor_run */
14 current_core = spdk_env_get_current_core();
15 SPDK_ENV_FOREACH_CORE(i) {
16 if (i != current_core) {
17 reactor = spdk_reactor_get(i);
18 rc = spdk_env_thread_launch_pinned(reactor->lcore, _spdk_reactor_run, reactor);
19 ...
20 }
21 spdk_cpuset_set_cpu(g_spdk_app_core_mask, i, true);
22 }
23
24 /* 主线程也会执行_spdk_reactor_run */
25 /* Start the master reactor */
26 reactor = spdk_reactor_get(current_core);
27 _spdk_reactor_run(reactor);
28
29 /* 主线程退出后会等待其它核上的线程均退出 */
30 spdk_env_thread_wait_all();
31
32 /* 执行到此处,说明vhost服务进程即将退出 */
33 g_reactor_state = SPDK_REACTOR_STATE_SHUTDOWN;
34 spdk_cpuset_free(g_spdk_app_core_mask);
35 g_spdk_app_core_mask = NULL;
36 }
轮循函数_spdk_reactor_run
通过对vhost代码流程的分析,我们看到vhost中所有线程最终都会调用_spdk_reactor_run,该函数是一个死循环,由此实现轮循逻辑:
spdk/lib/event/reactor.c:
2 _spdk_reactor_run(void *arg)
3 {
4 struct spdk_reactor *reactor = arg;
5 struct spdk_poller *poller;
6 uint32_t event_count;
7 uint64_t idle_started, now;
8 uint64_t spin_cycles, sleep_cycles;
9 uint32_t sleep_us;
10 uint32_t timer_poll_count;
11 char thread_name[32];
12
13 /* 重新命名线程名,reactor_[核号] */
14 snprintf(thread_name, sizeof(thread_name), "reactor_%u", reactor->lcore);
15
16 /* 创建SPDK线程对象:
17 (1)线程间通过_spdk_reactor_send_msg发送消息,本质是向接收方的event队列中添加事件;
18 (2)线程通过_spdk_reactor_start_poller和_spdk_reactor_stop_poller启动和停止poller;
19 (3)IO Channel等线程相关对象也会记录到线程对象中 */
20 if (spdk_allocate_thread(_spdk_reactor_send_msg,
21 _spdk_reactor_start_poller,
22 _spdk_reactor_stop_poller,
23 reactor, thread_name) == NULL) {
24 return -1;
25 }
26
27 /* spin_cycles代表最短轮循时间 */
28 spin_cycles = SPDK_REACTOR_SPIN_TIME_USEC * spdk_get_ticks_hz() / SPDK_SEC_TO_USEC;
29 /* sleep_cycles代表最长睡眠时间 */
30 sleep_cycles = reactor->max_delay_us * spdk_get_ticks_hz() / SPDK_SEC_TO_USEC;
31 idle_started = 0;
32 timer_poll_count = 0;
33
34 /* 轮循的死循环正式开始 */
35 while (1) {
36 bool took_action = false;
37
38 /* 首先,每个reactor线程通过DPDK的无锁队列实现了一个事件队列;这里从事件队列中取出事件并调用事件
39 的处理函数。例如,vhost的子系统的初始化即是在spdk_subsystem_init中产生了一个verify事件并
40 添加到主线程reactor的事件队列中,该事件处理函数为spdk_subsystem_verify */
41 event_count = _spdk_event_queue_run_batch(reactor);
42 if (event_count > 0) {
43 took_action = true;
44 }
45
46 /* 接着,每个reactor线程从active_pollers链表头部取出一个poller并调用其fn函数。poller代表一次
47 具体的处理动作,例如处理某个vhost_blk设备的所有IO环中的请求,又或者处理后端NVMe某个queue
48 pair中的所有响应 */
49 poller = TAILQ_FIRST(&reactor->active_pollers);
50 if (poller) {
51 TAILQ_REMOVE(&reactor->active_pollers, poller, tailq);
52 poller->state = SPDK_POLLER_STATE_RUNNING;
53 poller->fn(poller->arg);
54 if (poller->state == SPDK_POLLER_STATE_UNREGISTERED) {
55 free(poller);
56 } else {
57 poller->state = SPDK_POLLER_STATE_WAITING;
58 TAILQ_INSERT_TAIL(&reactor->active_pollers, poller, tailq);
59 }
60 took_action = true;
61 }
62
63 /* 最后,reactor线程还实现了定时器逻辑,这里判断是否有定时器到期;如果确有定时器到期则执行其回调并将
64 其放到定时器队列尾部 */
65 if (timer_poll_count >= SPDK_TIMER_POLL_ITERATIONS) {
66 poller = TAILQ_FIRST(&reactor->timer_pollers);
67 if (poller) {
68 now = spdk_get_ticks();
69
70 if (now >= poller->next_run_tick) {
71 TAILQ_REMOVE(&reactor->timer_pollers, poller, tailq);
72 poller->state = SPDK_POLLER_STATE_RUNNING;
73 poller->fn(poller->arg);
74 if (poller->state == SPDK_POLLER_STATE_UNREGISTERED) {
75 free(poller);
76 } else {
77 poller->state = SPDK_POLLER_STATE_WAITING;
78 _spdk_poller_insert_timer(reactor, poller, now);
79 }
80 took_action = true;
81 }
82 }
83 timer_poll_count = 0;
84 } else {
85 timer_poll_count++;
86 }
87
88 /* 下面的逻辑主要用来决定轮循线程是否可以睡眠一会 */
89
90 if (took_action) {
91 /* We were busy this loop iteration. Reset the idle timer. */
92 idle_started = 0;
93 } else if (idle_started == 0) {
94 /* We were previously busy, but this loop we took no actions. */
95 idle_started = spdk_get_ticks();
96 }
97
98 /* Determine if the thread can sleep */
99 if (sleep_cycles && idle_started) {
100 now = spdk_get_ticks();
101 if (now >= (idle_started + spin_cycles)) { /* 保证轮循线程最少已执行了spin_cycles */
102 sleep_us = reactor->max_delay_us;
103
104 poller = TAILQ_FIRST(&reactor->timer_pollers);
105 if (poller) {
106 /* There are timers registered, so don't sleep beyond
107 * when the next timer should fire */
108 if (poller->next_run_tick < (now + sleep_cycles)) {
109 if (poller->next_run_tick <= now) {
110 sleep_us = 0;
111 } else {
112 sleep_us = ((poller->next_run_tick - now) *
113 SPDK_SEC_TO_USEC) / spdk_get_ticks_hz();
114 }
115 }
116 }
117
118 if (sleep_us > 0) {
119 usleep(sleep_us);
120 }
121
122 /* After sleeping, always poll for timers */
123 timer_poll_count = SPDK_TIMER_POLL_ITERATIONS;
124 }
125 }
126
127 if (g_reactor_state != SPDK_REACTOR_STATE_RUNNING) {
128 break;
129 }
130 } /* 死循环结束 */
131
132 ...
133 spdk_free_thread();
134 return 0;
135 }
至此,reactor线程整体执行逻辑已分析完成,后续我们将以verify_event为线索开始分析各个子系统的初始化过程。
【SPDK】五、bdev子系统
SPDK从功能角度将各个独立的部分划分为“子系统“。例如对各种后端存储的访问属于bdev子系统,又例如对虚拟机呈现各种设备属于vhost子系统。不同场景下,各种工具可以通过组合不同的子系统来实现各种不同的功能。例如虚拟化场景下,vhost主要集成了bdev、vhost、scsi等子系统。这些子系统存在一定依赖关系,例如vhost子系统依赖bdev,这就需要将被依赖的子系统先初始化完成,才能执行其它子系统的初始化。
本篇博文我们先整体介绍一下SPDK子系统的初始化流程,然后再深入分析一下bdev子系统。vhost子系统我们将在独立的博文中展开分析。
SPDK子系统
通过前文的分析,我们知道主线程在执行_spdk_reactor_run时,首先处理的事件便是verify事件,该事件处理函数为spdk_subsystem_verify:
spdk/lib/event/subsystem.c:
2 spdk_subsystem_verify(void *arg1, void *arg2)
3 {
4 struct spdk_subsystem_depend *dep;
5
6 /* 检查当前应用中所有需要的子系统及其依赖系统是否均已成功注册 */
7 /* Verify that all dependency name and depends_on subsystems are registered */
8 TAILQ_FOREACH(dep, &g_subsystems_deps, tailq) {
9 if (!spdk_subsystem_find(&g_subsystems, dep->name)) {
10 SPDK_ERRLOG("subsystem %s is missingn", dep->name);
11 spdk_app_stop(-1);
12 return;
13 }
14 if (!spdk_subsystem_find(&g_subsystems, dep->depends_on)) {
15 SPDK_ERRLOG("subsystem %s dependency %s is missingn",
16 dep->name, dep->depends_on);
17 spdk_app_stop(-1);
18 return;
19 }
20 }
21
22 /* 按依赖关系对所有子系统进行排序 */
23 subsystem_sort();
24
25 /* 依据排序依次执行各个子系统的init函数 */
26 spdk_subsystem_init_next(0);
27 }
bdev子系统
bdev和vhost是虚拟化场景下两个最为主要的子系统,且vhost依赖bdev,因此我们先来分析一下bdev子系统。
我们可以看到bdev子系统的初始化函数为spdk_bdev_subsystem_initialize:
spdk/lib/event/subsystems/bdev/bdev.c:
2 .name = "bdev",
3 .init = spdk_bdev_subsystem_initialize,
4 .fini = spdk_bdev_subsystem_finish,
5 .config = spdk_bdev_config_text,
6 .write_config_json = _spdk_bdev_subsystem_config_json,
7 };
bdev子系统针对不同的后端存储设备实现了不同的“模块”,例如nvme模块主要实现了用户态对nvme设备的访问操作,virtio实现了用户态对virtio设备的访问操作,又例如malloc模块通过内存实现了一个vwin 的块设备。因此bdev子系统在初始化时主要针对配置文件中已经配置的后端存储模块进行初始化操作。
另外,bdev借助IO Channel的概念也实现了系统级的management_channel和模块级的module_channel。我们知道IO Channel是一个线程相关的概念,management_channel和module_channel也是如此:
- management_channel是线程唯一的一个对象,不同线程具备不同的的management_channel,同一个线程只有一个。目前management_channel中实现了一个线程内部独立的内存池,用来缓存bdev_io对象;
- module_channel是线程内部属于同一个模块的bdev所共享的一个对象,用来记录同一线程中属于同一模块的所有对象。例如同一个线程如果操作两个nvme的bdev对象且这两个bdev属于不同的nvme控制器,那么虽然这两个bdev对应不同的NVMe IO Channel,但是它们属于同一个module_channel。目前module_channel只含有一个模块级的引用计数和内存不足时的bdev io临时队列(当有内存空间时,实现IO重发)。
每个模块都会提供一个module_init函数,当bdev子系统初始化时会依次调用这些初始化函数。下面我们以NVMe和virtio两个模块为例,来简要看下模块的初始化逻辑。
- nvme模块初始化
nvme模块描述如下:
spdk/lib/bdev/nvme/bdev_nvme.c:
2 .name = "nvme",
3 .module_init = bdev_nvme_library_init,
4 .module_fini = bdev_nvme_library_fini,
5 .config_text = bdev_nvme_get_spdk_running_config,
6 .config_json = bdev_nvme_config_json,
7 .get_ctx_size = bdev_nvme_get_ctx_size,
8
9 };
这里我们可以看到nvme模块的初始化函数为bdev_nvme_library_init,另外bdev_nvme_get_ctx_size返回的context大小为nvme_bdev_io的大小。bdev子系统会以所有模块最大的context大小来创建bdev_io内存池,以此确保为所有模块申请bdev_io时都能获得足够的扩展内存(nvme_bdev_io即是对bdev_io的扩展)。
bdev_nvme_library_init函数从SPDK的配置文件中读取“Nvme”字段开始的相关信息,并通过这些信息创建一个NVMe控制器并获取其下的namespace,最后将namespace表示成一个bdev对象。这里我们打开看一下识别到对应NVMe控制器后的回调处理逻辑:
2 attach_cb(void *cb_ctx, const struct spdk_nvme_transport_id *trid,
3 struct spdk_nvme_ctrlr *ctrlr, const struct spdk_nvme_ctrlr_opts *opts)
4 {
5 struct nvme_ctrlr *nvme_ctrlr;
6 struct nvme_probe_ctx *ctx = cb_ctx;
7 char *name = NULL;
8 size_t i;
9
10 /* 首先根据DPDK中PCI驱动框架识别到的NVMe控制器信息来创建一个nvme_ctrlr对象 */
11 if (ctx) {
12 for (i = 0; i < ctx->count; i++) {
13 if (spdk_nvme_transport_id_compare(trid, &ctx->trids[i]) == 0) {
14 name = strdup(ctx->names[i]);
15 break;
16 }
17 }
18 } else {
19 name = spdk_sprintf_alloc("HotInNvme%d", g_hot_insert_nvme_controller_index++);
20 }
21
22 nvme_ctrlr = calloc(1, sizeof(*nvme_ctrlr));
23 ...
24 nvme_ctrlr->adminq_timer_poller = NULL;
25 nvme_ctrlr->ctrlr = ctrlr;
26 nvme_ctrlr->ref = 0;
27 nvme_ctrlr->trid = *trid;
28 nvme_ctrlr->name = name;
29
30 /* 将该nvme控制器对象添加为一个io device;每个io device可申请独立的IO Channel;
31 bdev_nvme_create_cb负责在IO Channel对象创建时初始化底层驱动相关对象,这里
32 即是获取一个新的queue pair */
33 spdk_io_device_register(ctrlr, bdev_nvme_create_cb, bdev_nvme_destroy_cb,
34 sizeof(struct nvme_io_channel));
35
36 /* 此处开始枚举nvme控制器下的所有namespace,并将其建为bdev对象。注意一点,此时并不会为
37 bdev申请IO channel,它是vhost子系统初始时,完成线程绑定后才创建的 */
38 if (nvme_ctrlr_create_bdevs(nvme_ctrlr) != 0) {
39 ...
40 }
41
42 nvme_ctrlr->adminq_timer_poller = spdk_poller_register(bdev_nvme_poll_adminq, ctrlr,
43 g_nvme_adminq_poll_timeout_us);
44
45 TAILQ_INSERT_TAIL(&g_nvme_ctrlrs, nvme_ctrlr, tailq);
46
47 ...
48 }
49
50 /* 注意:bdev初始化时并不调用该函数 */
51 static int
52 bdev_nvme_create_cb(void *io_device, void *ctx_buf)
53 {
54 struct spdk_nvme_ctrlr *ctrlr = io_device;
55 struct nvme_io_channel *ch = ctx_buf;
56
57 /* 分配一个nvme queue pair作为该IO Channel的实际对象 */
58 ch->qpair = spdk_nvme_ctrlr_alloc_io_qpair(ctrlr, NULL, 0);
59 ...
60 /* 向reactor注册一个poller,轮循新分配queue pair中已完成的响应信息 */
61 ch->poller = spdk_poller_register(bdev_nvme_poll, ch, 0);
62 return 0;
63 }
类似地,我们再看一下virtio模块的初始化。
- virtio模块初始化
virtio虽说起源于qemu-kvm虚拟化,但是它也是一种可用物理硬件实现的协议规范。因此SPDK也把它当做一种后端存储类型加以实现。当然,如果SPDK的vhost进程是运行在虚拟机中(而虚拟机virtio设备作为后端存储),virtio模块就是一个必不可少的驱动模块了。
我们以virtio-blk设备为例,来看一下其初始化过程:
spdk/lib/bdev/virtio/bdev_virtio_blk.c:
2 .name = "virtio_blk",
3 .module_init = bdev_virtio_initialize,
4 .get_ctx_size = bdev_virtio_blk_get_ctx_size,
5 };
bdev_virtio_initialize通过配置文件获取相关配置信息,并同样借助DPDK的用户态PCI设备管理框架识别到该设备后,调用virtio_pci_blk_dev_create来创建一个virtio_blk对象:
spdk/lib/bdev/virtio/bdev_virtio_blk.c:
2 virtio_pci_blk_dev_create(const char *name, struct virtio_pci_ctx *pci_ctx)
3 {
4 static int pci_dev_counter = 0;
5 struct virtio_blk_dev *bvdev;
6 struct virtio_dev *vdev;
7 char *default_name = NULL;
8 uint16_t num_queues;
9 int rc;
10
11 /* 分配一个virtio_blk_dev对象 */
12 bvdev = calloc(1, sizeof(*bvdev));
13 ...
14 vdev = &bvdev->vdev;
15
16 /* 为该virtio对象绑定用户态操作接口,注,该操作接口实现了virtio 1.0规范 */
17 rc = virtio_pci_dev_init(vdev, name, pci_ctx);
18 ...
19
20 /* 重置设备状态 */
21 rc = virtio_dev_reset(vdev, VIRTIO_BLK_DEV_SUPPORTED_FEATURES);
22 ...
23
24 /* 获取设备支持的最大队列数。如果支持多队列,从设备的配置寄存器中聊取;否则为1 */
25 /* TODO: add a way to limit usable virtqueues */
26 if (virtio_dev_has_feature(vdev, VIRTIO_BLK_F_MQ)) {
27 virtio_dev_read_dev_config(vdev, offsetof(struct virtio_blk_config, num_queues),
28 &num_queues, sizeof(num_queues));
29 } else {
30 num_queues = 1;
31 }
32
33 /* 初始化队列并创建bdev对象 */
34 rc = virtio_blk_dev_init(bvdev, num_queues);
35 ...
36
37 return bvdev;
38 }
39
40 static int
41 virtio_blk_dev_init(struct virtio_blk_dev *bvdev, uint16_t max_queues)
42 {
43 struct virtio_dev *vdev = &bvdev->vdev;
44 struct spdk_bdev *bdev = &bvdev->bdev;
45 uint64_t capacity, num_blocks;
46 uint32_t block_size;
47 uint16_t host_max_queues;
48 int rc;
49
50 /* 获取当前设备的块大小,默认为512字节 */
51 if (virtio_dev_has_feature(vdev, VIRTIO_BLK_F_BLK_SIZE)) {
52 virtio_dev_read_dev_config(vdev, offsetof(struct virtio_blk_config, blk_size),
53 &block_size, sizeof(block_size));
54 } else {
55 block_size = 512;
56 }
57
58 /* 获取设备容量 */
59 virtio_dev_read_dev_config(vdev, offsetof(struct virtio_blk_config, capacity),
60 &capacity, sizeof(capacity));
61
62 /* `capacity` is a number of 512-byte sectors. */
63 num_blocks = capacity * 512 / block_size;
64
65 /* 获取最大队列数 */
66 if (virtio_dev_has_feature(vdev, VIRTIO_BLK_F_MQ)) {
67 virtio_dev_read_dev_config(vdev, offsetof(struct virtio_blk_config, num_queues),
68 &host_max_queues, sizeof(host_max_queues));
69 } else {
70 host_max_queues = 1;
71 }
72
73 if (virtio_dev_has_feature(vdev, VIRTIO_BLK_F_RO)) {
74 bvdev->readonly = true;
75 }
76
77 /* bdev is tied with the virtio device; we can reuse the name */
78 bdev->name = vdev->name;
79
80 /* 按max_queues分配队列,并启动设备 */
81 rc = virtio_dev_start(vdev, max_queues, 0);
82 ...
83
84 /* 为bdev对象赋值 */
85 bdev->product_name = "VirtioBlk Disk";
86 bdev->write_cache = 0;
87 bdev->blocklen = block_size;
88 bdev->blockcnt = num_blocks;
89
90 bdev->ctxt = bvdev;
91 bdev->fn_table = &virtio_fn_table;
92 bdev->module = &virtio_blk_if;
93
94 /* 将virtio_blk_dev添加为一个io device;其IO Channel创建回调bdev_virtio_blk_ch_create_cb会申请一个
95 virtio的IO环作为该IO Channel的实际对象 */
96 spdk_io_device_register(bvdev, bdev_virtio_blk_ch_create_cb,
97 bdev_virtio_blk_ch_destroy_cb,
98 sizeof(struct bdev_virtio_blk_io_channel));
99
100 /* 注册该bdev对象,便于后续查找 */
101 rc = spdk_bdev_register(bdev);
102 ...
103
104 return 0;
105 }
【SPDK】六、vhost子系统
vhost子系统在SPDK中属于应用层或叫协议层,为虚拟机提供vhost-blk、vhost-scsi和vhost-nvme三种虚拟设备。这里我们以vhost-blk为分析对象,来讨论vhost子系统基本原理。
vhost子系统初始化
vhost子系统的描述如下:
spdk/lib/event/subsystems/vhost/vhost.c:
2 .name = "vhost",
3 .init = spdk_vhost_subsystem_init,
4 .fini = spdk_vhost_subsystem_fini,
5 .config = NULL,
6 .write_config_json = spdk_vhost_config_json,
7 };
8
9 static void
10 spdk_vhost_subsystem_init(void)
11 {
12 int rc = 0;
13
14 rc = spdk_vhost_init();
15
16 spdk_subsystem_init_next(rc);
17 }
vhost子系统初始化时,会依次偿试对vhost-scsi、vhost-blk和vhost-nvme进行初始化,如果配置文件中配置了对应类型的设备,那就会完成对应设备的创建并初始化监听socket等待qemu客户端进行连接。
spdk/lib/vhost/vhost.c:
2 spdk_vhost_init(void)
3 {
4 int ret;
5
6 ...
7
8 ret = spdk_vhost_scsi_controller_construct();
9 if (ret != 0) {
10 SPDK_ERRLOG("Cannot construct vhost controllersn");
11 return -1;
12 }
13
14 ret = spdk_vhost_blk_controller_construct();
15 if (ret != 0) {
16 SPDK_ERRLOG("Cannot construct vhost block controllersn");
17 return -1;
18 }
19
20 ret = spdk_vhost_nvme_controller_construct();
21 if (ret != 0) {
22 SPDK_ERRLOG("Cannot construct vhost NVMe controllersn");
23 return -1;
24 }
25
26 return 0;
27 }
vhost-blk初始化
vhost-blk初始化时主要完成了两部分工作:一是vhost设备通用部分,即建立监听socket并拉起监听线程等待客户端连接;另一方面是vhost-blk特有的初始化动作,即打开bdev设备并建立联系:
spdk/lib/vhost/vhost_blk.c:
2 spdk_vhost_blk_construct(const char *name, const char *cpumask, const char *dev_name, bool readonly)
3 {
4 struct spdk_vhost_blk_dev *bvdev = NULL;
5 struct spdk_bdev *bdev;
6 int ret = 0;
7
8 spdk_vhost_lock();
9
10 /* 首先通过bdev名称查找对应的bdev对象;bdev子系统在vhost子系统之前先完成初始化,正常情况下这里能找到对应的bdev */
11 bdev = spdk_bdev_get_by_name(dev_name);
12 ...
13
14 bvdev = spdk_dma_zmalloc(sizeof(*bvdev), SPDK_CACHE_LINE_SIZE, NULL);
15 ...
16
17 /* 打开对应的bdev,并将句柄记录到bvdev->bdev_desc中 */
18 ret = spdk_bdev_open(bdev, true, bdev_remove_cb, bvdev, &bvdev->bdev_desc);
19 ...
20
21 bvdev->bdev = bdev;
22 bvdev->readonly = readonly;
23
24 /* 完成vhost设备通用部分功能的初始化,并将该vhost设备的backend操作集合设为vhost_blk_device_backend;
25 说明:不同的vhost类型实现了不同的backend,以完成不同类型特定的一些操作过程。我们在后续分析客户端连接
26 操作时会深入分析backend的实现 */
27 ret = spdk_vhost_dev_register(&bvdev->vdev, name, cpumask, &vhost_blk_device_backend);
28 ...
29
30 spdk_vhost_unlock();
31 return ret;
32 }
vhost设备初始化主要提供了一个可供客户端(如qemu)连接的socket,并遵循vhost协议实现连接服务,这部分功能也是DPDK中已实现的功能,SPDK直接借用了相关代码:
spdk/lib/vhost/vhost.c:
2 spdk_vhost_dev_register(struct spdk_vhost_dev *vdev, const char *name, const char *mask_str,
3 const struct spdk_vhost_dev_backend *backend)
4 {
5 char path[PATH_MAX];
6 struct stat file_stat;
7 struct spdk_cpuset *cpumask;
8 int rc;
9
10
11 /* 将配置文件中读取的mask_str转换成位图记录到cpumask中,代表该vhost设备可以绑定的CPU核范围 */
12 cpumask = spdk_cpuset_alloc();
13 ...
14 if (spdk_vhost_parse_core_mask(mask_str, cpumask) != 0) {
15 ...
16 }
17 ...
18
19 /* 生成socket文件路径名,规则是设备路径名(vhost命令启动时-S参数指定)加上vhost对象名称,
20 例如 “/var/tmp/vhost.2” */
21 if (snprintf(path, sizeof(path), "%s%s", dev_dirname, name) >= (int)sizeof(path)) {
22 ...
23 }
24 ...
25
26 /* 生成socket监听句柄 */
27 if (rte_vhost_driver_register(path, 0) != 0) {
28 ...
29 }
30 if (rte_vhost_driver_set_features(path, backend->virtio_features) ||
31 rte_vhost_driver_disable_features(path, backend->disabled_features)) {
32 ...
33 }
34
35 /* 注册socket连接建立后的消息处理notify_op回调 */
36 if (rte_vhost_driver_callback_register(path, &g_spdk_vhost_ops) != 0) {
37 ...
38 }
39
40 /* 拉起一个监听线程,开始等待客户连接请求 */
41 if (spdk_call_unaffinitized(_start_rte_driver, path) == NULL) {
42 ...
43 }
44
45 vdev->name = strdup(name);
46 vdev->path = strdup(path);
47 vdev->id = ctrlr_num++;
48 vdev->vid = -1; /* 代表客户端连接对象,在客户端连接过程中生成 */
49 vdev->lcore = -1; /* 代表当前vhost设备绑定到哪个核上运行,也是在客户端连接后请求处理过程中生成 */
50 vdev->cpumask = cpumask;
51 vdev->registered = true;
52 vdev->backend = backend;
53
54 ...
55
56 TAILQ_INSERT_TAIL(&g_spdk_vhost_devices, vdev, tailq);
57
58 return 0;
59 }
_start_rte_driver会拉起一个监听线程执行fdset_event_dispatch函数,该函数等待客户端的连接请求。当qemu向socket发起连接请求时,监听线程收到该请求并调用vhost_user_server_new_connection建立一个新的连接,然后在新的连接上等待客户端发消息。收到消息时,监听线程会调用vhost_user_read_cb函数处理消息。消息的处理代表了vhost协议的基本原理,我们将在后续独立的博文介绍。
【SPDK】七、vhost客户端连接请求处理
vhost客户端连接后,将遵循vhost协议进行一系统复杂的消息传递与处理过程,最终服务端将生成一个可处理IO环中请求并返回响应的处理线程。本篇博文将分析其中最为重要两类消息的处理原理:内存映射消息和IO环信息传递消息。最后将一起来看一下vhost通用消息处理完成后,vhost-blk设备是如何完成最后的初始化动作的(其它类型的vhost设备大家可以自行阅读代码分析)。
vhost内存映射
vhost的reactor线程在处理IO请求时,需要访问虚拟机的内存空间。我们知道,虚拟机可见的内存是由qemu进程分配的,通过KVM内核模块将内存映射关系记录到EPT页表中(CPU硬件提供的地址转换功能),以此实现从GPA(Guest Physical Address)到HPA(Host Physical Address)的转换。同时qemu分配的这部分内存会映射到qemu虚拟地址空间中(Qemu Virtual Adress),以便qemu进程中IO线程可以访问虚拟机内存。映射关系如下图所示:
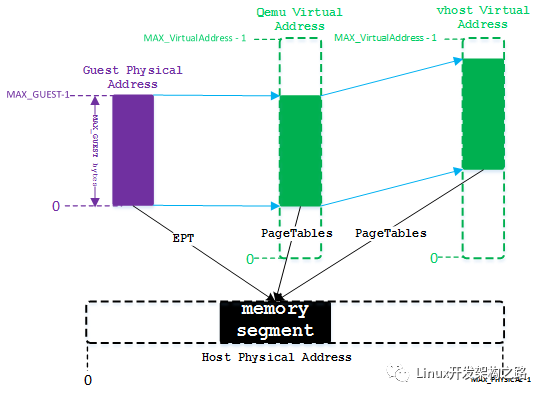
SPDK中vhost进程将取代qemu IO线程对IO进行处理,因此它也需要将虚拟机可见地址映射到自身的虚拟地址空间中(Vhost Virtual Address),并记录VVA到HPA的映射关系,便于将HPA发送给物理存储控制器进行DMA操作。
vhost进程映射虚拟机地址的基本原理就是通过大页内存的mmap系统调用:
- qemu进程通过大页文件(/dev/hugepages/xxx)为虚拟机申请内存,然后将大页文件句柄传递给vhost进程;
- vhost进程接收句柄后,会识别到qemu创建的大页文件(/dev/hugepages/xxx),然后调用mmap系统调用将该大页文件映射到自身虚拟地址空间中。
下面我们结合代码,再来深入理解一下内存映射过程。首先qemu连接vhost进程后,会通过发送VHOST_USER_SET_MEM_TABLE消息传递qemu内部的内存映射信息,vhost对该消息的处理过程如下:
spdk/lib/vhost/rte_vhost/vhost_user.c:
2 vhost_user_set_mem_table(struct virtio_net *dev, struct VhostUserMsg *pmsg)
3 {
4 uint32_t i;
5
6 memcpy(&dev->mem_table, &pmsg->payload.memory, sizeof(dev->mem_table));
7 memcpy(dev->mem_table_fds, pmsg->fds, sizeof(dev->mem_table_fds));
8 dev->has_new_mem_table = 1;
9
10 ...
11 return 0;
12 }
从上述代码,我们可以看到这里仅是简单地将socket消息中内容复制到dev对象中。注意一点,这里的dev代表客户端对象;对象类型名为virtio_net是由于这部分代码完全借用自DPDK导致,并不是说客户端是一个virtio_net对象。
后续在进行gpa地址转换前,后续通过vhost_setup_mem_table完成内存映射:
spdk/lib/vhost/rte_vhost/vhost_user.c:
2 vhost_setup_mem_table(struct virtio_net *dev)
3 {
4 struct VhostUserMemory memory = dev->mem_table;
5 struct rte_vhost_mem_region *reg;
6 void *mmap_addr;
7 uint64_t mmap_size;
8 uint64_t mmap_offset;
9 uint64_t alignment;
10 uint32_t i;
11 int fd;
12
13 ...
14 dev->mem = rte_zmalloc("vhost-mem-table", sizeof(struct rte_vhost_memory) +
15 sizeof(struct rte_vhost_mem_region) * memory.nregions, 0);
16 dev->mem->nregions = memory.nregions;
17
18 for (i = 0; i < memory.nregions; i++) {
19 fd = dev->mem_table_fds[i]; /* 取出大页文件句柄,注,这里是经过内核处理后的句柄,不是qemu中的原始句柄号 */
20 reg = &dev->mem->regions[i];
21
22 reg->guest_phys_addr = memory.regions[i].guest_phys_addr; /* 虚拟机物理内存地址,gpa*/
23 reg->guest_user_addr = memory.regions[i].userspace_addr; /* qemu中的虚拟地址,qva*/
24 reg->size = memory.regions[i].memory_size; /* 内存段大小 */
25 reg->fd = fd;
26
27 mmap_offset = memory.regions[i].mmap_offset; /* 映射段内偏移,通常为零 */
28 mmap_size = reg->size + mmap_offset; /* 映射段大小 */
29
30 ...
31
32 /* 将大页文件重新映射到当前进程中 */
33 mmap_addr = mmap(NULL, mmap_size, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_POPULATE, fd, 0);
34
35 reg->mmap_addr = mmap_addr;
36 reg->mmap_size = mmap_size;
37 reg->host_user_addr = (uint64_t)(uintptr_t)mmap_addr + mmap_offset; /* vhost虚拟地址,vva */
38
39 ...
40 }
41
42 return 0;
43 }
vhost IO环信息传递
vhost内存映射完成后,便可进行IO环信息的传递,处理完成后使得vhost进程可以访问IO环中信息。
这里注意一点,vhost在处理IO环相关消息时,首先会通过vhost_user_check_and_alloc_queue_pair来创建IO环相关对象。IO环相关的消息主要有VHOST_USER_SET_VRING_NUM、VHOST_USER_SET_VRING_ADDR、VHOST_USER_SET_VRING_BASE、VHOST_USER_SET_VRING_KICK、VHOST_USER_SET_VRING_CALL,这里我们重点分析一下VHOST_USER_SET_VRING_ADDR消息的处理:
spdk/lib/vhost/rte_vhost/vhost_user.c:
2 vhost_user_set_vring_addr(struct virtio_net *dev, VhostUserMsg *msg)
3 {
4 struct vhost_virtqueue *vq;
5 uint64_t len;
6
7 /* 如果还未完成vhost内存的映射,则先进行内存映射,可参考前文分析 */
8 if (dev->has_new_mem_table) {
9 vhost_setup_mem_table(dev);
10 dev->has_new_mem_table = 0;
11 }
12 ...
13
14 /* 根据消息中的索引找到对应的vq对象 */
15 vq = dev->virtqueue[msg->payload.addr.index];
16
17 /* The addresses are converted from QEMU virtual to Vhost virtual. */
18 len = sizeof(struct vring_desc) * vq->size;
19 /* 将消息中包含的desc数组的qva地址转换成vva地址,便于vhost线程后续访问IO环中desc数组中内容 */
20 vq->desc = (struct vring_desc *)(uintptr_t)qva_to_vva(dev, msg->payload.addr.desc_user_addr, &len);
21
22 dev = numa_realloc(dev, msg->payload.addr.index);
23 vq = dev->virtqueue[msg->payload.addr.index];
24
25 /* 同理将avail数组的qva地址转换成vva地址 */
26 len = sizeof(struct vring_avail) + sizeof(uint16_t) * vq->size;
27 vq->avail = (struct vring_avail *)(uintptr_t)qva_to_vva(dev, msg->payload.addr.avail_user_addr, &len);
28
29 /* 同理将used数组的qva地址转换成vva地址 */
30 len = sizeof(struct vring_used) + sizeof(struct vring_used_elem) * vq->size;
31 vq->used = (struct vring_used *)(uintptr_t)qva_to_vva(dev, msg->payload.addr.used_user_addr, &len);
32
33 ...
34 return 0;
35 }
vhost-blk回调处理
vhost设备完成内存映射及IO环信息传递动作后,就进行不同vhost设备特有的初始化动作:
spdk/lib/vhost/rte_vhost/vhost_user.c:
2 vhost_user_msg_handler(int vid, int fd)
3 {
4
5 /* 从socket句柄中读取消息 */
6 ret = read_vhost_message(fd, &msg);
7 ...
8
9 /* 如果消息中涉及IO环则先创建IO环对象 */
10 ret = vhost_user_check_and_alloc_queue_pair(dev, &msg);
11
12 /* 根据不同的消息类型进行处理 */
13 switch (msg.request) {
14 case VHOST_USER_GET_CONFIG:
15 ...
16 }
17
18 if (!(dev->flags & VIRTIO_DEV_RUNNING) && virtio_is_ready(dev)) {
19 dev->flags |= VIRTIO_DEV_READY;
20
21 if (!(dev->flags & VIRTIO_DEV_RUNNING)) {
22
23 /* 通过notify_ops回调设备相关的初始化函数 */
24 if (dev->notify_ops->new_device(dev->vid) == 0)
25 dev->flags |= VIRTIO_DEV_RUNNING;
26 }
27 }
28
29 return 0;
30 }
g_spdk_vhost_ops的new_device函数指向start_device,这里仍是vhost设备通用的初始化逻辑:
spdk/lib/vhost/vhost.c:
2 start_device(int vid)
3 {
4 struct spdk_vhost_dev *vdev;
5 int rc = -1;
6 uint16_t i;
7
8 /* 根据客户端vid找到对应的vhost_dev设备 */
9 vdev = spdk_vhost_dev_find_by_vid(vid);
10
11 /* 将客户端对象(virtio_net)中记录的IO环信息同步一份到vhost_dev中,后续IO处理时主要操作vhost_dev对象 */
12 vdev->max_queues = 0;
13 memset(vdev->virtqueue, 0, sizeof(vdev->virtqueue));
14 for (i = 0; i < SPDK_VHOST_MAX_VQUEUES; i++) {
15 if (rte_vhost_get_vhost_vring(vid, i, &vdev->virtqueue[i].vring)) {
16 continue;
17 }
18
19 if (vdev->virtqueue[i].vring.desc == NULL ||
20 vdev->virtqueue[i].vring.size == 0) {
21 continue;
22 }
23
24 /* Disable notifications. */
25 if (rte_vhost_enable_guest_notification(vid, i, 0) != 0) {
26 SPDK_ERRLOG("vhost device %d: Failed to disable guest notification on queue %"PRIu16"n", vid, i);
27 goto out;
28 }
29
30 vdev->max_queues = i + 1;
31 }
32
33 /* 同理,将客户端对象中的内存映射表同步一份到vhost_dev中 */
34 if (rte_vhost_get_mem_table(vid, &vdev->mem) != 0) {
35
36 }
37
38 /* 为vhost_dev对象分配一个运行核 */
39 vdev->lcore = spdk_vhost_allocate_reactor(vdev->cpumask);
40
41 /* 记录该vdev对象内存表中虚拟地址到物理地址的映射关系,后续操作物理DMA时可用 */
42 spdk_vhost_dev_mem_register(vdev);
43
44 /* 向vhost_dev对象的运行核发送一个事件,使该核上的reactor线程可以执行backend的start_device函数 */
45 rc = spdk_vhost_event_send(vdev, vdev->backend->start_device, 3, "start device");
46 ...
47
48 return rc;
49 }
vhost_dev的运行核上的reactor线程会执行backend的start_device,即spdk_vhost_blk_start:
spdk/lib/vhost/vhost_blk.c:
2 spdk_vhost_blk_start(struct spdk_vhost_dev *vdev, void *event_ctx)
3 {
4 struct spdk_vhost_blk_dev *bvdev;
5 int i, rc = 0;
6
7 bvdev = to_blk_dev(vdev);
8 ...
9
10 /* 为vhost设备中的每个队列分配task数组,task与队列中元素个数相同,一一对应 */
11 rc = alloc_task_pool(bvdev);
12 ...
13
14 if (bvdev->bdev) {
15 /* 为vhost_blk对应申请IO Channel,此时已确定执行线程上下文 */
16 bvdev->bdev_io_channel = spdk_bdev_get_io_channel(bvdev->bdev_desc);
17 ...
18 }
19
20 /* 在当前reactor线程中添加一个poller,用来处理IO环中的所有请求 */
21 bvdev->requestq_poller = spdk_poller_register(bvdev->bdev ? vdev_worker : no_bdev_vdev_worker, bvdev, 0);
22 ...
23 return rc;
24 }
至此,SPDK中vhost进程的初始化流程已介绍完毕,过程非常漫长,大家可以在对数据面的处理流程有一定的熟悉之后再来阅读分析这部分代码,这样可以理解得更深刻。
-
存储
+关注
关注
13文章
4296浏览量
85796 -
虚拟化
+关注
关注
1文章
371浏览量
29790 -
源码
+关注
关注
8文章
639浏览量
29184
发布评论请先 登录
相关推荐
虚拟现实+工业该如何发展?六大应用场景抢先看
在AT32系列MCU上Flash模拟EEPRO的应用原理和使用方法
数字电路实验的虚拟化设计方案
简要介绍了操作系统虚拟化的概念,以及实现操作系统虚拟化的技术
虚拟主机用途_虚拟主机使用方法步骤_虚拟主机如何绑定域名
超全的SPDK性能评估指南
如何使用一种形式化方法的3D虚拟祭祀场景建模语言与环境
虚拟现实头盔如何_虚拟现实头盔的使用方法
I/O软件模拟虚拟化和类虚拟化
DWIN屏使用方法总结(下)

“虚拟人+虚拟场景”颠覆传统直播模式
pwru的使用方法、经典场景及实现原理
SPDK Thread模型设计与实现 NVMe-oF的使用案例
探究I/O虚拟化及Virtio接口技术(下)





 工商网监
工商网监
评论