 接收UDP报文的过程
接收UDP报文的过程
最近工作中遇到某个服务器应用程序 UDP 丢包,在排查过程中查阅了很多资料,总结出来这篇文章,供更多人参考。
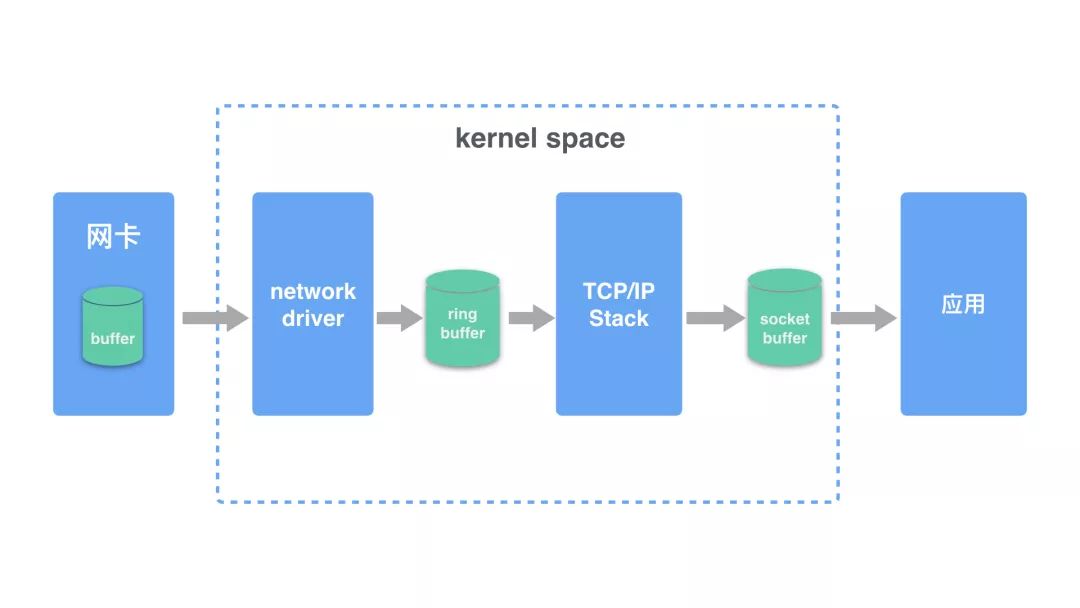
在开始之前,我们先用一张图解释 linux 系统接收网络报文的过程。
- 首先网络报文通过物理网线发送到网卡
- 网络驱动程序会把网络中的报文读出来放到 ring buffer 中,这个过程使用 DMA(Direct Memory Access),不需要 CPU 参与
- 内核从 ring buffer 中读取报文进行处理,执行 IP 和 TCP/UDP 层的逻辑,最后把报文放到应用程序的 socket buffer 中
- 应用程序从 socket buffer 中读取报文进行处理
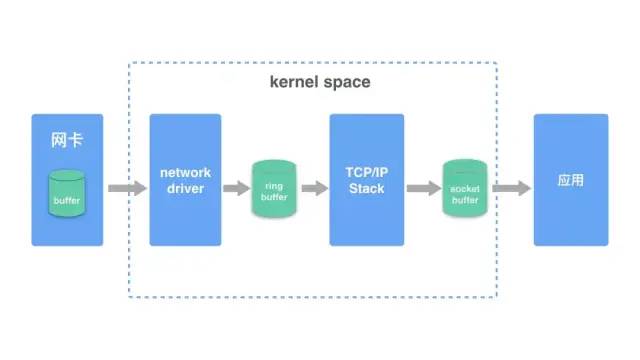
在接收 UDP 报文的过程中,图中任何一个过程都可能会主动或者被动地把报文丢弃,因此丢包可能发生在网卡和驱动,也可能发生在系统和应用。
之所以没有分析发送数据流程,一是因为发送流程和接收类似,只是方向相反;另外发送流程报文丢失的概率比接收小,只有在应用程序发送的报文速率大于内核和网卡处理速率时才会发生。
本篇文章假定机器只有一个名字为 eth0 的 interface,如果有多个 interface 或者 interface 的名字不是 eth0,请按照实际情况进行分析。
NOTE:文中出现的 RX(receive) 表示接收报文,TX(transmit) 表示发送报文。
确认有 UDP 丢包发生
要查看网卡是否有丢包,可以使用 ethtool -S eth0 查看,在输出中查找 bad 或者 drop 对应的字段是否有数据,在正常情况下,这些字段对应的数字应该都是 0。如果看到对应的数字在不断增长,就说明网卡有丢包。
另外一个查看网卡丢包数据的命令是 ifconfig,它的输出中会有 RX(receive 接收报文)和 TX(transmit 发送报文)的统计数据:
~# ifconfig eth0
...
RX packets 3553389376 bytes 2599862532475 (2.3 TiB)
RX errors 0 dropped 1353 overruns 0 frame 0
TX packets 3479495131 bytes 3205366800850 (2.9 TiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
...
此外,linux 系统也提供了各个网络协议的丢包信息,可以使用 netstat -s 命令查看,加上 --udp 可以只看 UDP 相关的报文数据:
[root@holodesk02 GOD]# netstat -s -u
IcmpMsg:
InType0: 3
InType3: 1719356
InType8: 13
InType11: 59
OutType0: 13
OutType3: 1737641
OutType8: 10
OutType11: 263
Udp:
517488890 packets received
2487375 packets to unknown port received.
47533568 packet receive errors
147264581 packets sent
12851135 receive buffer errors
0 send buffer errors
UdpLite:
IpExt:
OutMcastPkts: 696
InBcastPkts: 2373968
InOctets: 4954097451540
OutOctets: 5538322535160
OutMcastOctets: 79632
InBcastOctets: 934783053
InNoECTPkts: 5584838675
对于上面的输出,关注下面的信息来查看 UDP 丢包的情况:
- packet receive errors 不为空,并且在一直增长说明系统有 UDP 丢包
- packets to unknown port received 表示系统接收到的 UDP 报文所在的目标端口没有应用在监听,一般是服务没有启动导致的,并不会造成严重的问题
- receive buffer errors 表示因为 UDP 的接收缓存太小导致丢包的数量
NOTE:并不是丢包数量不为零就有问题,对于 UDP 来说,如果有少量的丢包很可能是预期的行为,比如丢包率(丢包数量/接收报文数量)在万分之一甚至更低。
网卡或者驱动丢包
之前讲过,如果 ethtool -S eth0 中有 rx_***_errors 那么很可能是网卡有问题,导致系统丢包,需要联系服务器或者网卡供应商进行处理。
# ethtool -S eth0 | grep rx_ | grep errors
rx_crc_errors: 0
rx_missed_errors: 0
rx_long_length_errors: 0
rx_short_length_errors: 0
rx_align_errors: 0
rx_errors: 0
rx_length_errors: 0
rx_over_errors: 0
rx_frame_errors: 0
rx_fifo_errors: 0
netstat -i 也会提供每个网卡的接发报文以及丢包的情况,正常情况下输出中 error 或者 drop 应该为 0。
如果硬件或者驱动没有问题,一般网卡丢包是因为设置的缓存区(ring buffer)太小,可以使用 ethtool 命令查看和设置网卡的 ring buffer。
ethtool -g 可以查看某个网卡的 ring buffer,比如下面的例子
# ethtool -g eth0
Ring parameters for eth0:
Pre-set maximums:
RX: 4096
RX Mini: 0
RX Jumbo: 0
TX: 4096
Current hardware settings:
RX: 256
RX Mini: 0
RX Jumbo: 0
TX: 256
Pre-set 表示网卡最大的 ring buffer 值,可以使用 ethtool -G eth0 rx 8192 设置它的值。
Linux 系统丢包
linux 系统丢包的原因很多,常见的有:UDP 报文错误、防火墙、UDP buffer size 不足、系统负载过高等,这里对这些丢包原因进行分析。
UDP 报文错误
如果在传输过程中UDP 报文被修改,会导致 checksum 错误,或者长度错误,linux 在接收到 UDP 报文时会对此进行校验,一旦发明错误会把报文丢弃。
如果希望 UDP 报文 checksum 及时有错也要发送给应用程序,可以在通过 socket 参数禁用 UDP checksum 检查:
int disable = 1;
setsockopt(sock_fd, SOL_SOCKET, SO_NO_CHECK, (void*)&disable, sizeof(disable)
防火墙
如果系统防火墙丢包,表现的行为一般是所有的 UDP 报文都无法正常接收,当然不排除防火墙只 drop 一部分报文的可能性。
如果遇到丢包比率非常大的情况,请先检查防火墙规则,保证防火墙没有主动 drop UDP 报文。
UDP buffer size 不足
linux 系统在接收报文之后,会把报文保存到缓存区中。因为缓存区的大小是有限的,如果出现 UDP 报文过大(超过缓存区大小或者 MTU 大小)、接收到报文的速率太快,都可能导致 linux 因为缓存满而直接丢包的情况。
在系统层面,linux 设置了 receive buffer 可以配置的最大值,可以在下面的文件中查看,一般是 linux 在启动的时候会根据内存大小设置一个初始值。
- /proc/sys/net/core/rmem_max:允许设置的 receive buffer 最大值
- /proc/sys/net/core/rmem_default:默认使用的 receive buffer 值
- /proc/sys/net/core/wmem_max:允许设置的 send buffer 最大值
- /proc/sys/net/core/wmem_dafault:默认使用的 send buffer 最大值
但是这些初始值并不是为了应对大流量的 UDP 报文,如果应用程序接收和发送 UDP 报文非常多,需要讲这个值调大。可以使用 sysctl 命令让它立即生效:
sysctl -w net.core.rmem_max=26214400 # 设置为 25M
也可以修改 /etc/sysctl.conf 中对应的参数在下次启动时让参数保持生效。
如果报文报文过大,可以在发送方对数据进行分割,保证每个报文的大小在 MTU 内。
另外一个可以配置的参数是 netdev_max_backlog,它表示 linux 内核从网卡驱动中读取报文后可以缓存的报文数量,默认是 1000,可以调大这个值,比如设置成 2000:
sudo sysctl -w net.core.netdev_max_backlog=2000
系统负载过高
系统 CPU、memory、IO 负载过高都有可能导致网络丢包,比如 CPU 如果负载过高,系统没有时间进行报文的 checksum 计算、复制内存等操作,从而导致网卡或者 socket buffer 出丢包;memory 负载过高,会应用程序处理过慢,无法及时处理报文;IO 负载过高,CPU 都用来响应 IO wait,没有时间处理缓存中的 UDP 报文。
linux 系统本身就是相互关联的系统,任何一个组件出现问题都有可能影响到其他组件的正常运行。对于系统负载过高,要么是应用程序有问题,要么是系统不足。对于前者需要及时发现,debug 和修复;对于后者,也要及时发现并扩容。
应用丢包
上面提到系统的 UDP buffer size,调节的 sysctl 参数只是系统允许的最大值,每个应用程序在创建 socket 时需要设置自己 socket buffer size 的值。
linux 系统会把接受到的报文放到 socket 的 buffer 中,应用程序从 buffer 中不断地读取报文。所以这里有两个和应用有关的因素会影响是否会丢包:socket buffer size 大小以及应用程序读取报文的速度。
对于第一个问题,可以在应用程序初始化 socket 的时候设置 socket receive buffer 的大小,比如下面的代码把 socket buffer 设置为 20MB:
uint64_t receive_buf_size = 20*1024*1024; //20 MB
setsockopt(socket_fd, SOL_SOCKET, SO_RCVBUF, &receive_buf_size, sizeof(receive_buf_size));
如果不是自己编写和维护的程序,修改应用代码是件不好甚至不太可能的事情。很多应用程序会提供配置参数来调节这个值,请参考对应的官方文档;如果没有可用的配置参数,只能给程序的开发者提 issue 了。
很明显,增加应用的 receive buffer 会减少丢包的可能性,但同时会导致应用使用更多的内存,所以需要谨慎使用。
另外一个因素是应用读取 buffer 中报文的速度,对于应用程序来说,处理报文应该采取异步的方式
包丢在什么地方
想要详细了解 linux 系统在执行哪个函数时丢包的话,可以使用 dropwatch 工具,它监听系统丢包信息,并打印出丢包发生的函数地址:
# dropwatch -l kas
Initalizing kallsyms db
dropwatch > start
Enabling monitoring...
Kernel monitoring activated.
Issue Ctrl-C to stop monitoring
1 drops at tcp_v4_do_rcv+cd (0xffffffff81799bad)
10 drops at tcp_v4_rcv+80 (0xffffffff8179a620)
1 drops at sk_stream_kill_queues+57 (0xffffffff81729ca7)
4 drops at unix_release_sock+20e (0xffffffff817dc94e)
1 drops at igmp_rcv+e1 (0xffffffff817b4c41)
1 drops at igmp_rcv+e1 (0xffffffff817b4c41)
通过这些信息,找到对应的内核代码处,就能知道内核在哪个步骤中把报文丢弃,以及大致的丢包原因。
此外,还可以使用 linux perf 工具监听 kfree_skb(把网络报文丢弃时会调用该函数) 事件的发生:
sudo perf record -g -a -e skb:kfree_skb
sudo perf script
关于 perf 命令的使用和解读,网上有很多文章可以参考。
总结
- UDP 本身就是无连接不可靠的协议,适用于报文偶尔丢失也不影响程序状态的场景,比如视频、音频、游戏、监控等。对报文可靠性要求比较高的应用不要使用 UDP,推荐直接使用 TCP。当然,也可以在应用层做重试、去重保证可靠性
- 如果发现服务器丢包,首先通过监控查看系统负载是否过高,先想办法把负载降低再看丢包问题是否消失
- 如果系统负载过高,UDP 丢包是没有有效解决方案的。如果是应用异常导致 CPU、memory、IO 过高,请及时定位异常应用并修复;如果是资源不够,监控应该能及时发现并快速扩容
- 对于系统大量接收或者发送 UDP 报文的,可以通过调节系统和程序的 socket buffer size 来降低丢包的概率
- 应用程序在处理 UDP 报文时,要采用异步方式,在两次接收报文之间不要有太多的处理逻辑
-
Linux
+关注
关注
87文章
11292浏览量
209317 -
服务器
+关注
关注
12文章
9123浏览量
85320 -
UDP
+关注
关注
0文章
325浏览量
33931 -
报文
+关注
关注
0文章
38浏览量
4027
发布评论请先 登录
相关推荐
UDP有发送缓存区吗?如何解决UDP丢包的问题呢?

通信必备知识!TCP与UDP协议介绍及使用

请问STM32F4通过W5500能不能得到网口的所有UDP和TCP报文?
ESP32C6 WiFi报文出现大量重传是什么原因导致的?
ESP32C6作为UDP Server,使用recvfrom无法及时收到第一帧报文的原因?如何解决?
如何关闭UDP接收时的校验?
如何解决LWIP中UDP数据收发文件接收的问题?
关于W5500芯片UDP发送报文到不同IP的问题
icmp报文和ip报文分析

教你动手写UDP协议栈—DNS报文解析
UDP协议的报文格式
简述linux系统UDP丢包问题分析思路(上)
简述linux系统UDP丢包问题分析思路(下)
UDP丢包的原因和解决方案





 工商网监
工商网监
评论