 从ID-based到LLM-based:可迁移推荐系统发展
从ID-based到LLM-based:可迁移推荐系统发展
 可迁移推荐系统发展历程
可迁移推荐系统发展历程
推荐系统的核心目标是通过建模用户的历史行为预测最有可能交互的下一个目标。而这一目标在用户交互记录较少的情况下尤为困难,即长期困扰推荐系统领域发展的冷启动问题。在这些新用户很少并且其交互序列有限的新推荐系统场景中,前期的模型训练往往缺乏足够的样本数据。对有限训练数据的建模也必然无法获得用户满意的推荐结果,使得平台成长受到很大阻碍。
迁移学习是学术界和工业界为了解决这一问题所一直关注的解决方案。如果可以向新场景中引入预先训练到的知识帮助建模用户序列或加速建模速度,这将极大缓解下游新场景中冷启动问题带来的巨大成本。
为此,对可迁移推荐系统的研究几乎贯穿了推荐系统领域发展的每一个阶段。从基于物品 ID 和用户 ID 的矩阵分解时代,可迁移推荐系统必须基于上下游场景的数据覆盖实现基于 ID 的推荐系统迁移学习。
到近几年模态理解技术发展迅猛,研究人员逐渐转向利用纯模态信息建模用户序列,从而实现在上下游场景没有数据覆盖的情况下实现可迁移推荐系统。再到当下利用大规模预训练语言模型(LLM)完成 ‘one-for-all’ 的推荐系统大模型得到大量关注。可迁移推荐系统乃至推荐系统大模型的研究已成为推荐系统领域发展的下一个方向。

基于ID的可迁移推荐系统
第一阶段是矩阵分解时代,使用 ID embedding 来建模物品的协同过滤算法是推荐系统的主流范式,并在之后的 15 年间主导了整个推荐系统社区。经典架构包括:双塔架构、CTR 模型、会话和序列推荐、Graph 网络。他们无不采用 ID embedding 来对物品进行建模,整个推荐系统现有的 SOTA 体系也几乎都是采用基于 ID 特征的建模手段。
这一阶段,可迁移推荐系统自然依靠 ID 实现,而且必须在上下游场景之间有数据重叠,即要求不同数据集之间存在共同用户或者物品,例如大公司里存在多个业务场景, 通过老的业务引流新的业务。这一阶段的早期工作有 PeterRec [1](SIGIR2020)、Conure [2](SIGIR2021)和 CLUE [3] (ICDM2021)等。
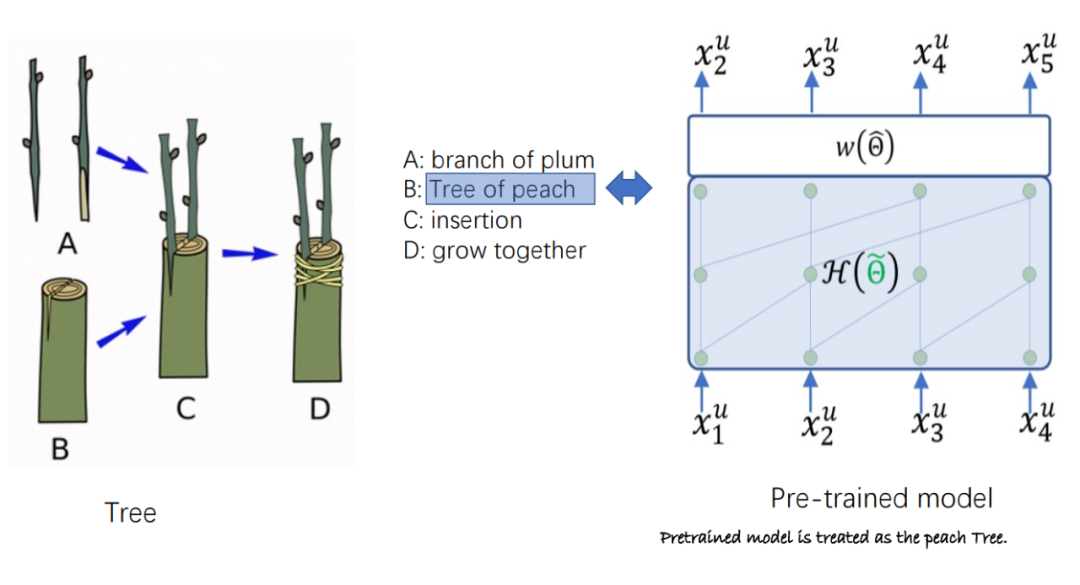
PeterRec 是推荐系统领域首篇论文明确提出基于自监督预训练(自回归与 Mask 语言模型)的用户表征具备通用性,并清晰地呈现出该预训练的通用表征可用于跨域推荐和用户画像预测,显著提升性能,其中,采用用户画像预测评估用户表征的通用性被后续相关论文广泛沿用。
同时,PeterRec 提出,通用型用户模型在下游任务迁移过程,应该做到参数有效共享(公司往往有上百种用户画像要预测,数十个业务推荐场景),并引入基于 Adapter 技术,也是推荐系统首次采用 Adapter,通过微调模型补丁实现不同任务有效迁移学习。另外,PeterRec 还发布了一套大规模的跨域推荐系统数据集。
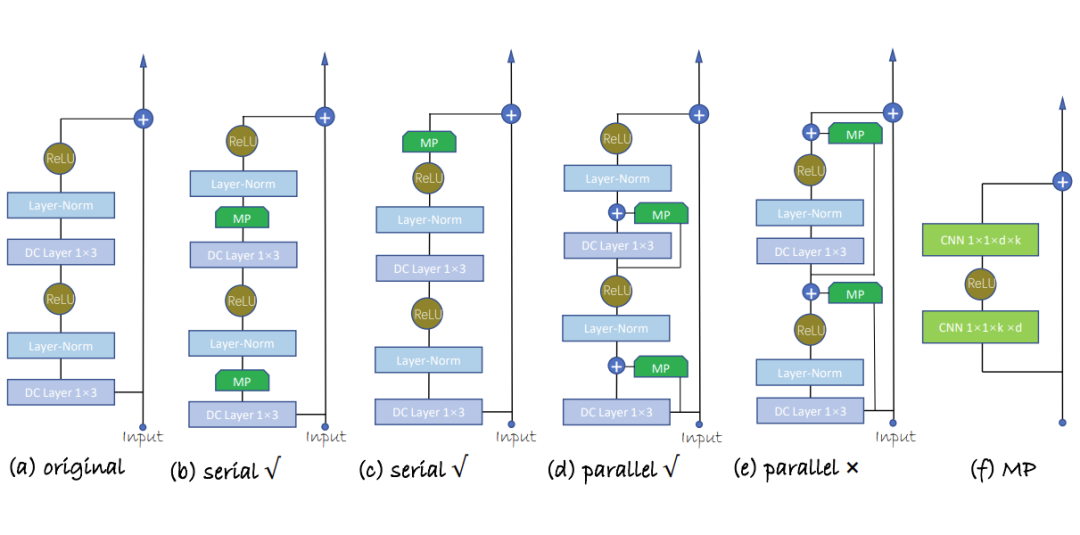
Conure 是推荐系统领域首个用户通用表征的终生学习(lifelong learning)模型,首次提出一个模型连续学习和同时服务多个不同的下游任务。作者提出的‘一人一世界’概念启发了当下推荐系统 one4all 模型的研究。
CLUE 认为 PeterRec 与 Conure 算法在学习用户表征时,采用自回归或者 mask 机制都是基于物品粒度的预测,而最优的用户表征显然应该是对完整的用户序列进行建模和训练,因此结合对比学习,获得了更优的结果。
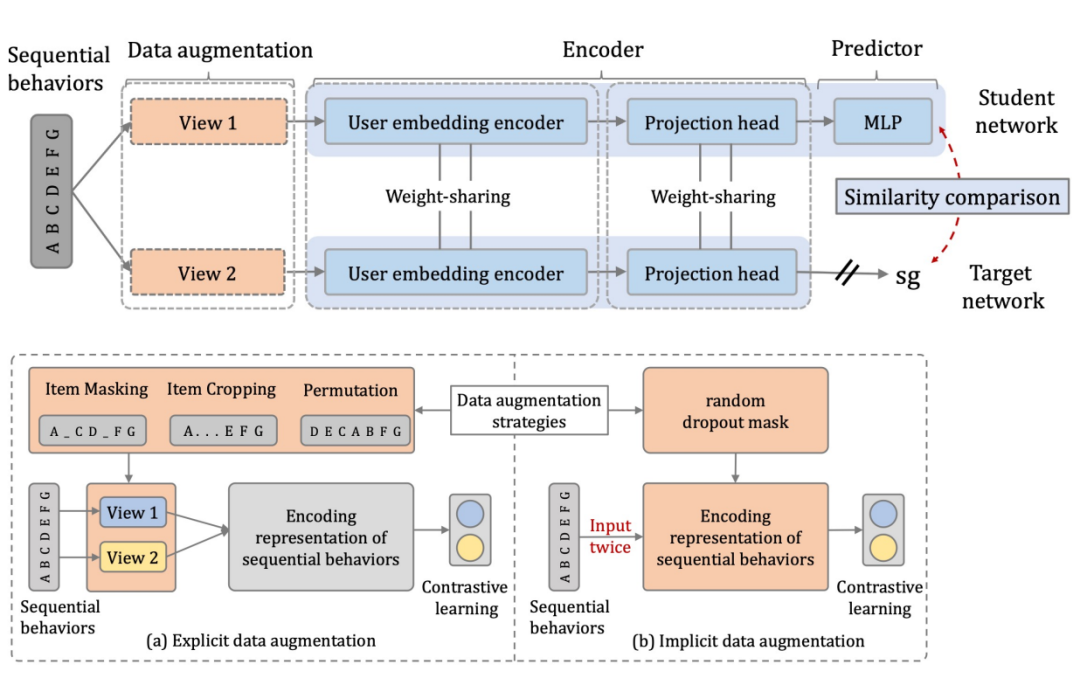
这期间有一些同时期或者 future work,包括阿里的 Star 模型(One Model to Serve All: Star Topology Adaptive Recommender for Multi-Domain CTR Prediction),以及 ShopperBERT 模型 (One4all User Representation for Recommender Systems in E-commerce)。

基于模态信息的可迁移推荐系统
以上工作基于共享(用户或者物品)ID 方式实现领域之间的迁移性和跨域推荐,比较适用于公司内部不同业务之间, 而现实中不同推荐系统很难共享用户与 item 的 ID 信息,使得跨平台推荐这一类研究具有明显的局限性。
相比之下,深度学习的其他社区,如自然语言处理(NLP)与计算机视觉(CV)领域近几年已经涌现出一系列有影响力的通用型大模型,又称基础模型(foundation model),如 BERT、GPT、Vision Transformer 等。相比推荐系统 ID 特征,NLP 与 CV 任务基于多模态文本与图像像素特征,可以较好的实现模型在不同任务之间的复用与迁移。
替换 ID 特征、基于模态内容实现不同系统与平台之间的迁移是该阶段的主流方向。这一阶段的代表性工作有 TransRec [4]、MoRec [5](SIGIR2023)、AdapterRec [6](WSDM2024)、NineRec [7] 等。另外,同时期的工作还有人大赵鑫老师团队 UnisRec 以及张永峰老师团队的 P5。
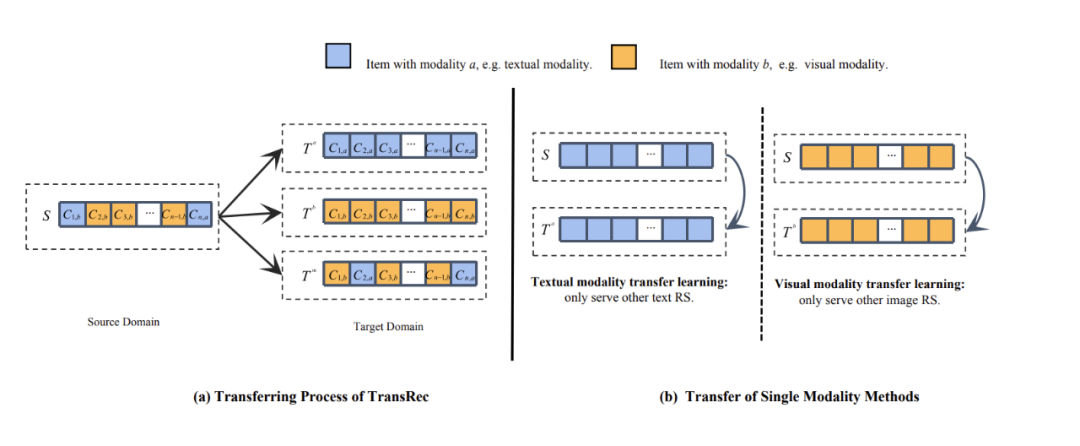
TransRec 是首个研究混合模态迁移的推荐系统模型,也是首次考虑图像像素的迁移学习模型。TransRec 采用端到端训练方式,而不是直接抽取离线 item 多模态表征。
与基于 ID 的序列推荐模型比较,经过 finetune 的 TransRec 可以有效提升推荐结果。TransRec 证实了大规模数据上利用混合模态信息预训练可以有效学习用户和物品的关系,并且可以迁移到下游推荐任务,实现通用推荐,论文还研究了 scaling effect 效果,并会发布多套多模态数据集。与 TransRec 同时期的工作是人大赵鑫老师团队 UnisRec,UnisRec 主要聚焦 text 模态。
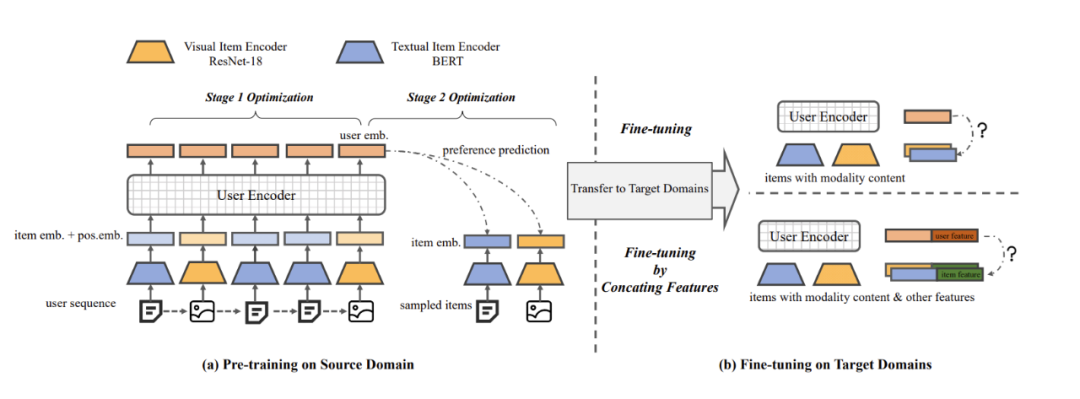
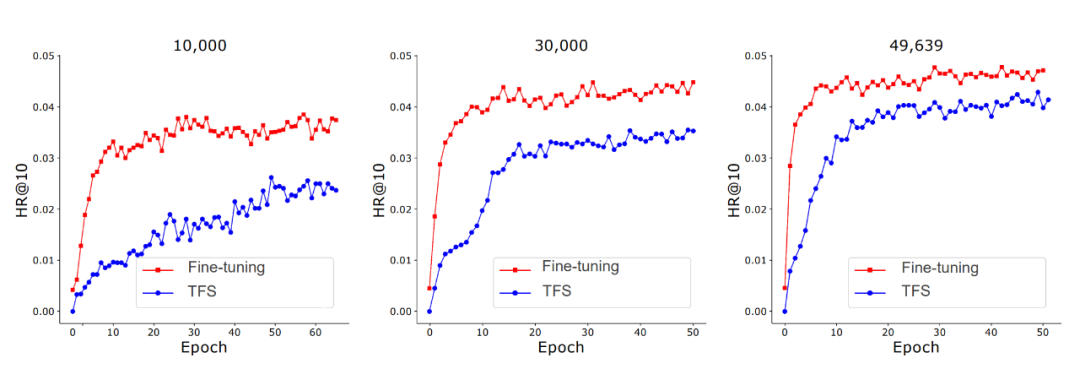
MoRec 首次系统性回答了使用最先进的模态编码器表征物品(MoRec)是否能取代经典的 itemID embedding 范式(DRec)这一问题。论文基于 MoRec 与 IDRec 的公平比较展开:如果在冷热场景下 MoRec 都能打败 IDRec,那么推荐系统将有望迎来经典范式的变革。这一观点来自于 MoRec 完全基于物品的模态信息,此类内容信息天生具有迁移能力,论文通过扎实的实验系统性证明了 MoRec 有潜力实现通用大模型。
结论 1:对于时序推荐架构 SASRec,在常规场景(既有热 item 也有一部分冷 item),MoRec 在文本上明显优于 IDRec,而在图片上则和 IDRec 效果相当。在冷启动场景,MoRec 大幅优于 IDRec,在热门商品推荐场景,MoRec 和 IDRec 效果相当。
结论 2:MoRec 为推荐系统和 NLP、CV 等多模态社区建立了联系,而且一般来说,可以很好的继承 NLP 和 CV 领域的最新进展。
结论 3:工业界流行的 Two-stage 离线特征提取推荐方式会导致 MoRec 性能显著下降(特别是对于视觉推荐),这在实践中不应该被忽视。同时,尽管多模态领域的预训练模型在近年来取得了革命性的成功,但其表征还没有做到通用性和泛化性,至少对于推荐系统是这样(MoRec 论文也被 Google DeepMind 团队邀请给了一个 talk,Google researcher 对该工作评价非常高)。受此启发,近期已经出现很多相关工作。
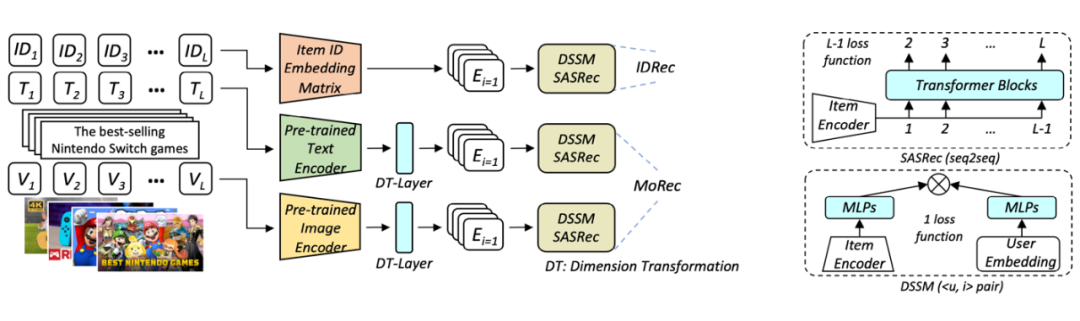
AdapterRec 首次系统性讨论了基于模态信息的高效迁移方法。论文评估了基于适配器(Adapter)的模型补丁。与以往工作在下游迁移时微调全部参数不同,AdapterRec 在迁移时在模型网络中插入并仅微调适配器网络。论文在大规模文本、图片模态数据上进行了丰富的验证实验。
结果表明,基于文本、图片模态的适配器都可以实现良好的迁移效果。基于文本模态时,适配器技术可以在微调极少量参数的计算成本下实现与微调全部参数相近的迁移结果。AdapterRec 证实了基于适配器技术的高效迁移方法是实现通用推荐系统大模型的重要环节。
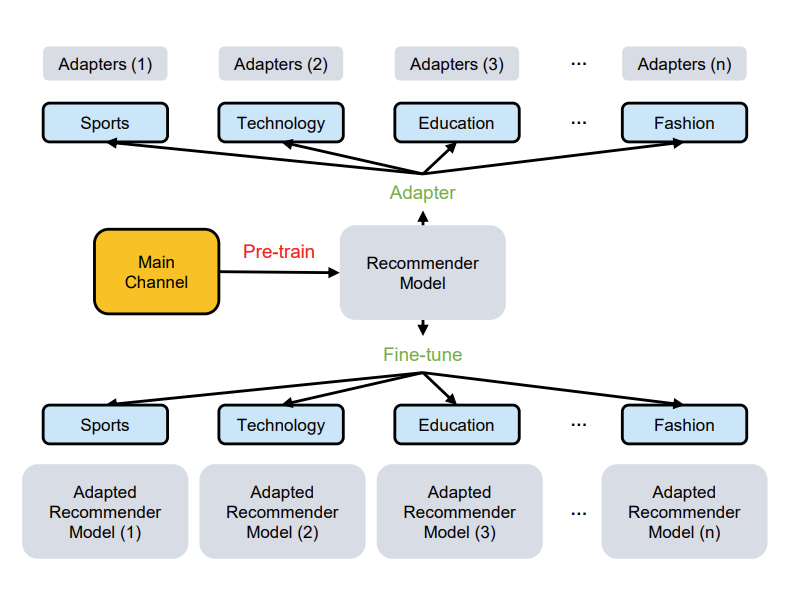
NineRec 提出了迄今为止推荐系统领域规模最大最多样的多模态迁移学习数据集。论文延续 MoRec 与 IDRec 公平比较的原则,系统性评估了 MoRec 的迁移能力并给出详见的指导建议与评估平台。NineRec 提供了一套大规模预训练数据集和九个下游场景数据集,其中仅预训练数据集就包含 200 万用户、14 万物品以及近 2500 万条交互记录信息。
论文设计大规模实验评估了多种经典推荐架构(SASRec,BERT4Rec,NextItNet,GRU4Rec)与物品编码器(BERT,Roberta,OPT,ResNet,Swin Transformer)的迁移表现,并验证了端到端迁移(End-to-End)与两阶段迁移(Two-stage)对于迁移推荐的影响。实验结果表明,利用端到端训练技术可以极大程度上激发模态信息的潜能,仅使用经典框架如 SASRec 即可超越近期同类型可迁移推荐模型。
论文还验证了基于纯模态信息的 zero-shot 迁移能力。NineRec 为基于模态的推荐系统迁移学习和推荐大模型发展提供了全新的平台和基准。NineRec(只有文本和图片模态)之后,团队联合发布了 MicroLens [11] 数据集,是当前最大的短视频推荐数据集包含原始短视频,是其他相关数据集规模的数千倍,用户量达到 3000 万,点击行为达到 10 亿,可以用于训练推荐系统大模型。NineRec 与 MicroLens 算力和数据集收集费用都超过百万人民币。
 基于LLM的可迁移推荐系统
基于LLM的可迁移推荐系统
当下人工智能领域进入大模型时代,越来越多的通用大模型在各个领域被提出,极大的促进了 AI 社区的发展。然而大模型技术在推荐系统领域应用还处于早期阶段。诸多问题并没有得到很好的回答,如利用大语言模型理解推荐任务是否能大幅超越原有的 ID 范式?是否越大规模参数的大模型网络可以带来通用推荐表征?回答这些问题是推动推荐系统社区进入大模型时代的敲门砖,受到了越来越多科研团队的关注。
这里主要介绍 P5 [8] 和 GPT4Rec [9],P5 是采用 LM 作为推荐 backbone,而 GPT4Rec 则是极限地评估 1750 亿的 item encoder 表能能力, 后续工作也非常多(例如基于 prompt,基于chain of thought,基于 ChatGPT 等),例如同时期的工作还有 Google 的 LLM for rating prediction [10],与 GPT4Rec 类似,都是采用迁移模型评估性能极限,一个专注 top-n item 推荐,一个专注 rating prediction。
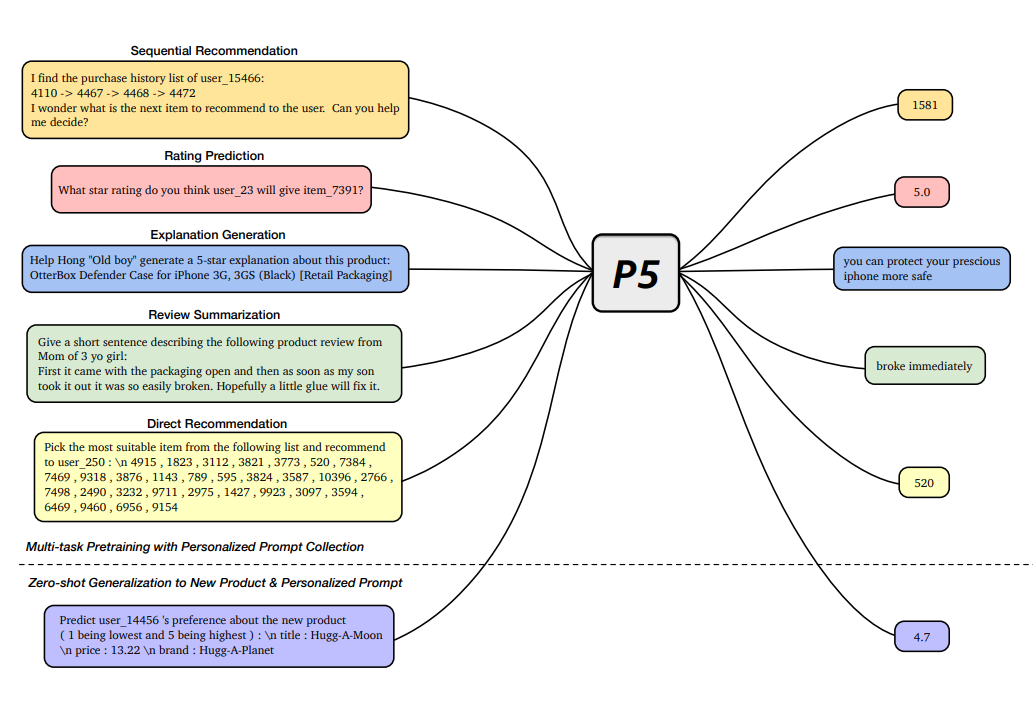
P5 提出了一种基于文本模态的多任务大模型框架,将多种经典推荐任务转化为统一的自然语言理解任务,包括序列推荐、评分预测、推荐理由、摘要以及直接推荐等多种任务。模型设计上,P5 通过基于提示(prompt)的自然语言格式来构建任务,将这些相关的推荐任务统一为序列到序列(seq-to-seq)框架中进行学习。数据方面,P5 将各种可用数据,例如用户信息、物品元数据、用户评论以及用户与物品的互动数据转化为自然语言序列。丰富的训练数据产生了满足个性化推荐需求的语义信息。
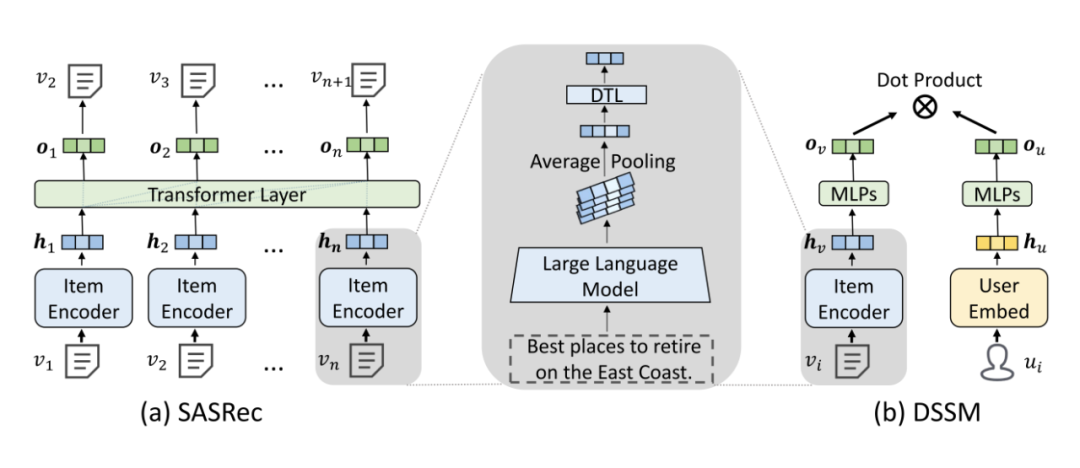
GPT4Rec 首次探索了使用百亿规模大语言模型作为物品编码器。论文提出并回答了几个关键性的问题:1)基于文本的协同过滤推荐算法(TCF)的性能随着物品编码器参数量不断增加表现如何?是否在千亿规模能达到上限?2)超大参数的 LLM,如 175B 参数 GPT-3,是否能产生通用的 item 表征?3)基于公平比较,装配了 175B 参数量的 LLM 的推荐系统算法能否打败基于 ID 的经典算法;4)基于 LLM 的 TCF 算法距离推荐系统通用大模型还有多远?
实验结果表明:
1. 175B 的参数 LM 可能还没有达到其性能上限,通过观察到 LLM 的参数量从 13B 到 175B 时,TCF 模型的性能还没有收敛。这一现象表明将来使用更多参数的 LLM 用作文本编码器是有带来更高的推荐准确性的潜力的;
2. 即使是由极其庞大的 LM(如 GPT-3)学习到的物品表示,也未必能形成一个通用的表征。在相应的推荐系统数据集微调仍然对于获得 SOTA 仍然是必要的,至少对文本推荐任务来说是如此;
3. 即使采用 175B 和微调的 66B 的语言模型,当使用 DSSM 作为推荐骨架时,TCF 仍然很大程度的劣于 IDRec,但是对于序列推荐模型,LLM 即便采用冻住的表征,也基本可以跟 IDRec 相媲美;
4. 虽然装配了 175B 参数量 LLM 的 TCF 模型的表现优于随机采样的 item 的推荐,甚至达到了 6-40 倍的提升。但与在推荐数据上重新训练的 TCF 模型相比,它们仍然有巨大的差距。另外,论文发现:
5. ChatGPT 在典型的推荐系统场景与 TCF 相比表现存在较大的差距,文章猜测需要更加精细的 prompt,ChatGPT 才有可能用于某些真实推荐场景。
 总结
总结
目前推荐系统社区内,基于模态内容的大模型研究仍处于起步阶段:
1. 基于传统的 ID 的推荐算法难以解决模态场景问题;
2. 已有的基于模态内容的跨域推荐系统文献通用性较低;
3. 非端到端的联合训练提取的特征可能存在粒度尺度不匹配等问题,通常只能生成次优的推荐水平;
4. 社区缺少包含模态内容的可用于迁移学习研究的大规模公开数据集,缺少基准和排行榜(leaderboard);
5. 已有文献中的推荐系统大模型参数量和训练数据太小(相对于 NLP 与 CV 领域),缺少开源的推荐系统大模型预训练参数。

参考文献
[1] Parameter-efficient transfer from sequential behaviors for user modeling and recommendation (SIGIR2020)
[2] One Person, One Model, One World: Learning Continual User Representation without Forgetting (SIGIR2021)
[3] Learning transferable user representations with sequential behaviors via contrastive pre-training (ICDM2021)
[4] TransRec: Learning Transferable Recommendation from Mixture-of-Modality Feedback. Arxiv2022/06
[5] Where to Go Next for Recommender Systems? ID- vs. Modality-based Recommender Models Revisited (SIGIR2023)
[6] Exploring Adapter-based Transfer Learning for Recommender Systems: Empirical Studies and Practical Insights (WSDM2024)
[7] NineRec: A Suite of Transfer Learning Datasets for ModalityBased Recommender Systems. Arxiv2023/09
[8] Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5) (Recsys2022)
[9] Exploring the Upper Limits of Text-Based Collaborative Filtering Using Large Language Models: Discoveries and Insights. Arxiv2023/05
[10] Do LLMs Understand User Preferences? Evaluating LLMs On User Rating Prediction. Arxiv2023/05
[11] A Content-Driven Micro-Video Recommendation Dataset at Scale. Arxiv2023/09
参考技术贴:
1)https://zhuanlan.zhihu.com/p/624557649 机器学习心得(八):推荐系统是不是即将迎来预训练时代?
2)https://zhuanlan.zhihu.com/p/633839409 SIGIR2023 | ID vs 模态: 推荐系统ID范式有望被颠覆?
3)https://zhuanlan.zhihu.com/p/642797247 推荐系统范式之争,LLM vs. ID?
4)https://zhuanlan.zhihu.com/p/437671278 推荐系统通用用户表征预训练研究进展
5)https://zhuanlan.zhihu.com/p/661836095 推荐系统何去何从(Google DeepMind受邀报告)
6)https://zhuanlan.zhihu.com/p/661954235 推荐系统预训练大模型范式发展
-
物联网
+关注
关注
2909文章
44557浏览量
372741
原文标题:从ID-based到LLM-based:可迁移推荐系统发展
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
什么是LLM?LLM在自然语言处理中的应用
LLM技术对人工智能发展的影响
NY8B062F 14 I/O+12-通道ADC 8位EPROM-Based单片机手册
端到端InfiniBand网络解决LLM训练瓶颈

从 MSP430™ MCU 到 MSPM0 MCU 的迁移指南

将软件从8位(字节)可寻址CPU迁移至C28x CPU
从Renesas RL78到基于Arm的MSPM0的迁移指南
什么是LLM?LLM的工作原理和结构
大语言模型(LLM)快速理解

李未可科技正式推出WAKE-AI多模态AI大模型

FPGA-Based DPU网卡的发展和应用





 工商网监
工商网监
评论