 STL内容介绍
STL内容介绍
1 什么是STL?
STL(Standard Template Library),即标准模板库,是一个具有工业强度的,高效的C++程序库。它被容纳于C++标准程序库(C++ Standard Library)中,是ANSI/ISO C++标准中最新的也是极具革命性的一部分。该库包含了诸多在计算机科学领域里所常用的基本数据结构和基本算法。为广大C++程序员们提供了一个可扩展的应用框架,高度体现了软件的可复用性。
STL的一个重要特点是数据结构和算法的分离。尽管这是个简单的概念,但这种分离确实使得STL变得非常通用。例如,由于STL的sort()函数是完全通用的,你可以用它来操作几乎任何数据集合,包括链表,容器和数组;
STL另一个重要特性是它不是面向对象的。为了具有足够通用性,STL主要依赖于模板而不是封装,继承和虚函数(多态性)——OOP的三个要素。你在STL中找不到任何明显的类继承关系。这好像是一种倒退,但这正好是使得STL的组件具有广泛通用性的底层特征。另外,由于STL是基于模板,内联函数的使用使得生成的代码短小高效;
从逻辑层次来看,在STL中体现了泛型化程序设计的思想,引入了诸多新的名词,比如像需求(requirements),概念(concept),模型(model),容器(container),算法(algorithmn),迭代子(iterator)等。与OOP(object-oriented programming)中的多态(polymorphism)一样,泛型也是一种软件的复用技术;
从实现层次看,整个STL是以一种类型参数化的方式实现的,这种方式基于一个在早先C++标准中没有出现的语言特性--模板(template)。
2 STL内容介绍
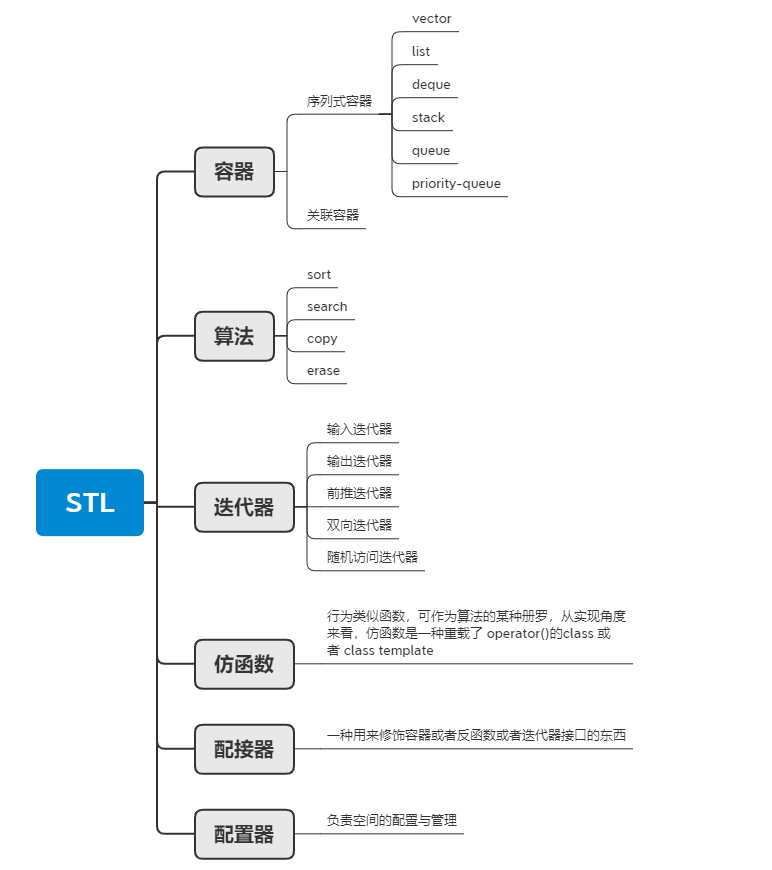
STL中六大组件:
容器(Container),是一种数据结构,如list,vector,和deques ,以模板类的方法提供。为了访问容器中的数据,可以使用由容器类输出的迭代器;
迭代器(Iterator),提供了访问容器中对象的方法。例如,可以使用一对迭代器指定list或vector中的一定范围的对象。迭代器就如同一个指针。事实上,C++的指针也是一种迭代器。但是,迭代器也可以是那些定义了operator*()以及其他类似于指针的操作符地方法的类对象;
算法(Algorithm),是用来操作容器中的数据的模板函数。例如,STL用sort()来对一个vector中的数据进行排序,用find()来搜索一个list中的对象,函数本身与他们操作的数据的结构和类型无关,因此他们可以在从简单数组到高度复杂容器的任何数据结构上使用;
仿函数(Functor)
适配器(Adaptor)
分配器(allocator)
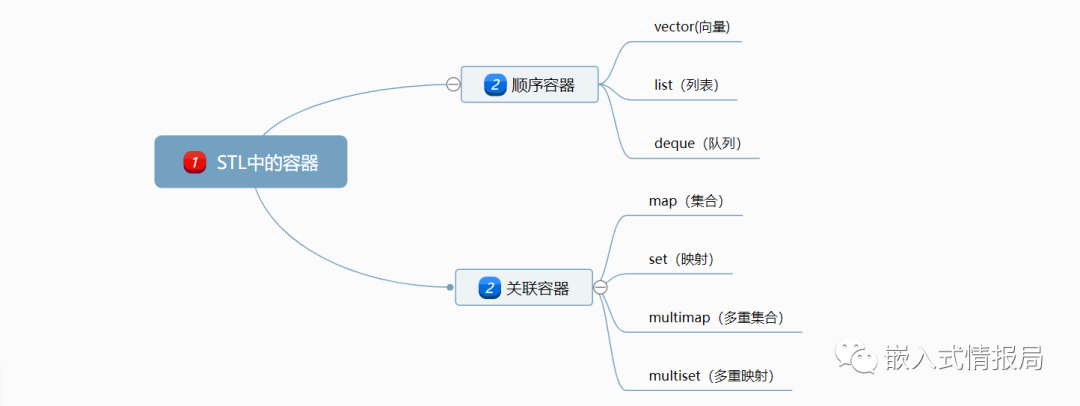
2.1 容器
STL中的容器有队列容器和关联容器,容器适配器(congtainer adapters:stack,queue,priority queue),位集(bit_set),串包(string_package)等等。
(1)序列式容器(Sequence containers),每个元素都有固定位置--取决于插入时机和地点,和元素值无关,vector、deque、list;
Vector:将元素置于一个动态数组中加以管理,可以随机存取元素(用索引直接存取),数组尾部添加或移除元素非常快速。但是在中部或头部安插元素比较费时;
Deque:是“double-ended queue”的缩写,可以随机存取元素(用索引直接存取),数组头部和尾部添加或移除元素都非常快速。但是在中部或头部安插元素比较费时;
List:双向链表,不提供随机存取(按顺序走到需存取的元素,O(n)),在任何位置上执行插入或删除动作都非常迅速,内部只需调整一下指针;
(2)关联式容器(Associated containers),元素位置取决于特定的排序准则,和插入顺序无关,set、multiset、map、multimap等。
Set/Multiset:内部的元素依据其值自动排序,Set内的相同数值的元素只能出现一次,Multisets内可包含多个数值相同的元素,内部由二叉树实现,便于查找;
Map/Multimap:Map的元素是成对的键值/实值,内部的元素依据其值自动排序,Map内的相同数值的元素只能出现一次,Multimaps内可包含多个数值相同的元素,内部由二叉树实现,便于查找;
容器类自动申请和释放内存,无需new和delete操作。
2.2 STL迭代器
Iterator(迭代器)模式又称Cursor(游标)模式,用于提供一种方法顺序访问一个聚合对象中各个元素, 而又不需暴露该对象的内部表示。或者这样说可能更容易理解:Iterator模式是运用于聚合对象的一种模式,通过运用该模式,使得我们可以在不知道对象内部表示的情况下,按照一定顺序(由iterator提供的方法)访问聚合对象中的各个元素。
迭代器的作用:能够让迭代器与算法不干扰的相互发展,最后又能无间隙的粘合起来,重载了*,++,==,!=,=运算符。用以操作复杂的数据结构,容器提供迭代器,算法使用迭代器;常见的一些迭代器类型:iterator、const_iterator、reverse_iterator和const_reverse_iterator.
2.3 算法
函数库对数据类型的选择对其可重用性起着至关重要的作用。举例来说,一个求方根的函数,在使用浮点数作为其参数类型的情况下的可重用性肯定比使用整型作为它的参数类性要高。而C++通过模板的机制允许推迟对某些类型的选择,直到真正想使用模板或者说对模板进行特化的时候,STL就利用了这一点提供了相当多的有用算法。它是在一个有效的框架中完成这些算法的——你可以将所有的类型划分为少数的几类,然后就可以在模版的参数中使用一种类型替换掉同一种类中的其他类型。
STL提供了大约100个实现算法的模版函数,比如算法for_each将为指定序列中的每一个元素调用指定的函数,stable_sort以你所指定的规则对序列进行稳定性排序等等。只要我们熟悉了STL之后,许多代码可以被大大的化简,只需要通过调用一两个算法模板,就可以完成所需要的功能并大大地提升效率。
算法部分主要由头文件,和组成。
是所有STL头文件中最大的一个(尽管它很好理解),它是由一大堆模版函数组成的,可以认为每个函数在很大程度上都是独立的,其中常用到的功能范围涉及到比较、交换、查找、遍历操作、复制、修改、移除、反转、排序、合并等等。
体积很小,只包括几个在序列上面进行简单数学运算的模板函数,包括加法和乘法在序列上的一些操作。
中则定义了一些模板类,用以声明函数对象。
STL中算法大致分为四类:
- 非可变序列算法:指不直接修改其所操作的容器内容的算法。
- 可变序列算法:指可以修改它们所操作的容器内容的算法。
- 排序算法:对序列进行排序和合并的算法、搜索算法以及有序序列上的集合操作。
- 数值算法:对容器内容进行数值计算。
以下对所有算法进行细致分类并标明功能:
<一>查找算法(13个):判断容器中是否包含某个值
adjacent_find: 在iterator对标识元素范围内,查找一对相邻重复元素,找到则返回指向这对元素的第一个元素的 ForwardIterator。否则返回last。重载版本使用输入的二元操作符代替相等的判断。
binary_search: 在有序序列中查找value,找到返回true。重载的版本实用指定的比较函数对象或函数指针来判断相等。
count: 利用等于操作符,把标志范围内的元素与输入值比较,返回相等元素个数。
count_if: 利用输入的操作符,对标志范围内的元素进行操作,返回结果为true的个数。
equal_range: 功能类似equal,返回一对iterator,第一个表示lower_bound,第二个表示upper_bound。
find: 利用底层元素的等于操作符,对指定范围内的元素与输入值进行比较。当匹配时,结束搜索,返回该元素的 一个InputIterator。
find_end: 在指定范围内查找"由输入的另外一对iterator标志的第二个序列"的最后一次出现。找到则返回最后一对的第一 个ForwardIterator,否则返回输入的"另外一对"的第一个ForwardIterator。重载版本使用用户输入的操作符代 替等于操作。
find_first_of: 在指定范围内查找"由输入的另外一对iterator标志的第二个序列"中任意一个元素的第一次出现。重载版本中使 用了用户自定义操作符。
find_if: 使用输入的函数代替等于操作符执行find。
lower_bound: 返回一个ForwardIterator,指向在有序序列范围内的可以插入指定值而不破坏容器顺序的第一个位置。重载函 数使用自定义比较操作。
upper_bound: 返回一个ForwardIterator,指向在有序序列范围内插入value而不破坏容器顺序的最后一个位置,该位置标志 一个大于value的值。重载函数使用自定义比较操作。
search: 给出两个范围,返回一个ForwardIterator,查找成功指向第一个范围内第一次出现子序列(第二个范围)的位 置,查找失败指向last1。重载版本使用自定义的比较操作。
search_n: 在指定范围内查找val出现n次的子序列。重载版本使用自定义的比较操作。
<二>排序和通用算法(14个):提供元素排序策略
inplace_merge: 合并两个有序序列,结果序列覆盖两端范围。重载版本使用输入的操作进行排序。
merge: 合并两个有序序列,存放到另一个序列。重载版本使用自定义的比较。
nth_element: 将范围内的序列重新排序,使所有小于第n个元素的元素都出现在它前面,而大于它的都出现在后面。重 载版本使用自定义的比较操作。
partial_sort: 对序列做部分排序,被排序元素个数正好可以被放到范围内。重载版本使用自定义的比较操作。
partial_sort_copy: 与partial_sort类似,不过将经过排序的序列复制到另一个容器。
partition: 对指定范围内元素重新排序,使用输入的函数,把结果为true的元素放在结果为false的元素之前。
random_shuffle: 对指定范围内的元素随机调整次序。重载版本输入一个随机数产生操作。
reverse: 将指定范围内元素重新反序排序。
reverse_copy: 与reverse类似,不过将结果写入另一个容器。
rotate: 将指定范围内元素移到容器末尾,由middle指向的元素成为容器第一个元素。
rotate_copy: 与rotate类似,不过将结果写入另一个容器。
sort: 以升序重新排列指定范围内的元素。重载版本使用自定义的比较操作。
stable_sort: 与sort类似,不过保留相等元素之间的顺序关系。
stable_partition: 与partition类似,不过不保证保留容器中的相对顺序。
<三>删除和替换算法(15个)
copy: 复制序列
copy_backward: 与copy相同,不过元素是以相反顺序被拷贝。
iter_swap: 交换两个ForwardIterator的值。
remove: 删除指定范围内所有等于指定元素的元素。注意,该函数不是真正删除函数。内置函数不适合使用remove和 remove_if函数。
remove_copy: 将所有不匹配元素复制到一个制定容器,返回OutputIterator指向被拷贝的末元素的下一个位置。
remove_if: 删除指定范围内输入操作结果为true的所有元素。
remove_copy_if: 将所有不匹配元素拷贝到一个指定容器。
replace: 将指定范围内所有等于vold的元素都用vnew代替。
replace_copy: 与replace类似,不过将结果写入另一个容器。
replace_if: 将指定范围内所有操作结果为true的元素用新值代替。
replace_copy_if: 与replace_if,不过将结果写入另一个容器。
swap: 交换存储在两个对象中的值。
swap_range: 将指定范围内的元素与另一个序列元素值进行交换。
unique: 清除序列中重复元素,和remove类似,它也不能真正删除元素。重载版本使用自定义比较操作。
unique_copy: 与unique类似,不过把结果输出到另一个容器。
<四>排列组合算法(2个):提供计算给定集合按一定顺序的所有可能排列组合
next_permutation: 取出当前范围内的排列,并重新排序为下一个排列。重载版本使用自定义的比较操作。
prev_permutation: 取出指定范围内的序列并将它重新排序为上一个序列。如果不存在上一个序列则返回false。重载版本使用 自定义的比较操作。
<五>算术算法(4个)
accumulate: iterator对标识的序列段元素之和,加到一个由val指定的初始值上。重载版本不再做加法,而是传进来的 二元操作符被应用到元素上。
partial_sum: 创建一个新序列,其中每个元素值代表指定范围内该位置前所有元素之和。重载版本使用自定义操作代 替加法。
inner_product: 对两个序列做内积(对应元素相乘,再求和)并将内积加到一个输入的初始值上。重载版本使用用户定义 的操作。
adjacent_difference: 创建一个新序列,新序列中每个新值代表当前元素与上一个元素的差。重载版本用指定二元操作计算相 邻元素的差。
<六>生成和异变算法(6个)
fill: 将输入值赋给标志范围内的所有元素。
fill_n: 将输入值赋给first到first+n范围内的所有元素。
for_each: 用指定函数依次对指定范围内所有元素进行迭代访问,返回所指定的函数类型。该函数不得修改序列中的元素。
generate: 连续调用输入的函数来填充指定的范围。
generate_n: 与generate函数类似,填充从指定iterator开始的n个元素。
transform: 将输入的操作作用与指定范围内的每个元素,并产生一个新的序列。重载版本将操作作用在一对元素上,另外一 个元素来自输入的另外一个序列。结果输出到指定容器。
<七>关系算法(8个)
equal: 如果两个序列在标志范围内元素都相等,返回true。重载版本使用输入的操作符代替默认的等于操 作符。
includes: 判断第一个指定范围内的所有元素是否都被第二个范围包含,使用底层元素的<操作符,成功返回 true。重载版本使用用户输入的函数。
lexicographical_compare: 比较两个序列。重载版本使用用户自定义比较操作。
max: 返回两个元素中较大一个。重载版本使用自定义比较操作。
max_element: 返回一个ForwardIterator,指出序列中最大的元素。重载版本使用自定义比较操作。
min: 返回两个元素中较小一个。重载版本使用自定义比较操作。
min_element: 返回一个ForwardIterator,指出序列中最小的元素。重载版本使用自定义比较操作。
mismatch: 并行比较两个序列,指出第一个不匹配的位置,返回一对iterator,标志第一个不匹配元素位置。 如果都匹配,返回每个容器的last。重载版本使用自定义的比较操作。
<八>集合算法(4个)
set_union: 构造一个有序序列,包含两个序列中所有的不重复元素。重载版本使用自定义的比较操作。
set_intersection: 构造一个有序序列,其中元素在两个序列中都存在。重载版本使用自定义的比较操作。
set_difference: 构造一个有序序列,该序列仅保留第一个序列中存在的而第二个中不存在的元素。重载版本使用 自定义的比较操作。
set_symmetric_difference: 构造一个有序序列,该序列取两个序列的对称差集(并集-交集)。
<九>堆算法(4个)
make_heap: 把指定范围内的元素生成一个堆。重载版本使用自定义比较操作。
pop_heap: 并不真正把最大元素从堆中弹出,而是重新排序堆。它把first和last-1交换,然后重新生成一个堆。可使用容器的 back来访问被"弹出"的元素或者使用pop_back进行真正的删除。重载版本使用自定义的比较操作。
push_heap: 假设first到last-1是一个有效堆,要被加入到堆的元素存放在位置last-1,重新生成堆。在指向该函数前,必须先把 元素插入容器后。重载版本使用指定的比较操作。
sort_heap: 对指定范围内的序列重新排序,它假设该序列是个有序堆。重载版本使用自定义比较操作。
2.4 仿函数
2.4.1 概述
仿函数(functor),就是使一个类的使用看上去象一个函数。其实现就是类中实现一个operator(),这个类就有了类似函数的行为,就是一个仿函数类了。
有些功能的的代码,会在不同的成员函数中用到,想复用这些代码。
1)公共的函数,可以,这是一个解决方法,不过函数用到的一些变量,就可能成为公共的全局变量,再说为了复用这么一片代码,就要单立出一个函数,也不是很好维护。
2)仿函数,写一个简单类,除了那些维护一个类的成员函数外,就只是实现一个operator(),在类实例化时,就将要用的,非参数的元素传入类中。
2.4.2 仿函数(functor)在编程语言中的应用
1)C语言使用函数指针和回调函数来实现仿函数,例如一个用来排序的函数可以这样使用仿函数
#include < stdio.h >
#include < stdlib.h >
//int sort_function( const void *a, const void *b);
int sort_function( const void *a, const void *b)
{
return *(int*)a-*(int*)b;
}
int main()
{
int list[5] = { 54, 21, 11, 67, 22 };
qsort((void *)list, 5, sizeof(list[0]), sort_function);//起始地址,个数,元素大小,回调函数
int x;
for (x = 0; x < 5; x++)
printf("%in", list[x]);
return 0;
}
2)在C++里,我们通过在一个类中重载括号运算符的方法使用一个函数对象而不是一个普通函数。
#include < iostream >
#include < algorithm >
using namespace std;
template< typename T >
class display
{
public:
void operator()(const T &x)
{
cout < < x < < " ";
}
};
int main()
{
int ia[] = { 1,2,3,4,5 };
for_each(ia, ia + 5, display< int >());
system("pause");
return 0;
}
2.4.3 仿函数在STL中的定义
要使用STL内建的仿函数,必须包含头文件。而头文件中包含的仿函数分类包括
1)算术类仿函数
加:plus
减:minus
乘:multiplies
除:divides
模取:modulus
否定:negate
例子:
#include < iostream >
#include < numeric >
#include < vector >
#include < functional >
using namespace std;
int main()
{
int ia[] = { 1,2,3,4,5 };
vector< int > iv(ia, ia + 5);
//120
cout < < accumulate(iv.begin(), iv.end(), 1, multiplies< int >()) < < endl;
//15
cout < < multiplies< int >()(3, 5) < < endl;
modulus< int > modulusObj;
cout < < modulusObj(3, 5) < < endl; // 3
system("pause");
return 0;
}
2)关系运算类仿函数
等于:equal_to
不等于:not_equal_to
大于:greater
大于等于:greater_equal
小于:less
小于等于:less_equal
从大到小排序:
#include < iostream >
#include < algorithm >
#include< functional >
#include < vector >
using namespace std;
template < class T >
class display
{
public:
void operator()(const T &x)
{
cout < < x < < " ";
}
};
int main()
{
int ia[] = { 1,5,4,3,2 };
vector< int > iv(ia, ia + 5);
sort(iv.begin(), iv.end(), greater< int >());
for_each(iv.begin(), iv.end(), display< int >());
system("pause");
return 0;
}
3)逻辑运算仿函数
逻辑与:logical_and
逻辑或:logical_or
逻辑否:logical_no
除了使用STL内建的仿函数,还可使用自定义的仿函数,具体实例见文章3.4.7.2小结
2.5 容器适配器
标准库提供了三种顺序容器适配器:queue(FIFO队列)、priority_queue(优先级队列)、stack(栈)
什么是容器适配器
适配器是使一种事物的行为类似于另外一种事物行为的一种机制”,适配器对容器进行包装,使其表现出另外一种行为。例 如,stack >实现了栈的功能,但其内部使用顺序容器vector来存储数据。(相当于是vector表现出 了栈的行为)。
容器适配器
要使用适配器,需要加入一下头文件:
#include //stack
#include //queue、priority_queue
- 定义适配器
1、初始化
stack stk(dep);
2、覆盖默认容器类型
stack > stk;
- 使用适配器
2.5.1 stack
stack< int > s;
stack< int, vector< int > > stk; //覆盖基础容器类型,使用vector实现stk
s.empty(); //判断stack是否为空,为空返回true,否则返回false
s.size(); //返回stack中元素的个数
s.pop(); //删除栈顶元素,但不返回其值
s.top(); //返回栈顶元素的值,但不删除此元素
s.push(item); //在栈顶压入新元素item
实例:括号匹配
#include< iostream >
#include< cstdio >
#include< string >
#include< stack >
using namespace std;
int main()
{
string s;
stack< char > ss;
while (cin > > s)
{
bool flag = true;
for (char c : s) //C++11新标准,即遍历一次字符串s
{
if (c == '(' || c == '{' || c == '[')
{
ss.push(c);
continue;
}
if (c == '}')
{
if (!ss.empty() && ss.top() == '{')
{
ss.pop();
continue;
}
else
{
flag = false;
break;
}
}
if (!ss.empty() && c == ']')
{
if (ss.top() == '[')
{
ss.pop();
continue;
}
else
{
flag = false;
break;
}
}
if (!ss.empty() && c == ')')
{
if (ss.top() == '(')
{
ss.pop();
continue;
}
else
{
flag = false;
break;
}
}
}
if (flag) cout < < "Match!" < < endl;
else cout < < "Not Match!" < < endl;
}
}
2.5.2 queue & priority_queue
queue< int > q; //priority_queue< int > q;
q.empty(); //判断队列是否为空
q.size(); //返回队列长度
q.push(item); //对于queue,在队尾压入一个新元素
//对于priority_queue,在基于优先级的适当位置插入新元素
//queue only:
q.front(); //返回队首元素的值,但不删除该元素
q.back(); //返回队尾元素的值,但不删除该元素
//priority_queue only:
q.top(); //返回具有最高优先级的元素值,但不删除该元素
3 常用容器用法介绍
3.1 vector
3.1.1 基本函数实现
1.构造函数
- vector():创建一个空vector
- vector(int nSize):创建一个vector,元素个数为nSize
- vector(int nSize,const t& t):创建一个vector,元素个数为nSize,且值均为t
- vector(const vector&):复制构造函数
- vector(begin,end):复制[begin,end)区间内另一个数组的元素到vector中
2.增加函数
- void push_back(const T& x):向量尾部增加一个元素X
- iterator insert(iterator it,const T& x):向量中迭代器指向元素前增加一个元素x
- iterator insert(iterator it,int n,const T& x):向量中迭代器指向元素前增加n个相同的元素x
- iterator insert(iterator it,const_iterator first,const_iterator last):向量中迭代器指向元素前插入另一个相同类型向量的[first,last)间的数据
3.删除函数
- iterator erase(iterator it):删除向量中迭代器指向元素
- iterator erase(iterator first,iterator last):删除向量中[first,last)中元素
- void pop_back():删除向量中最后一个元素
- void clear():清空向量中所有元素
4.遍历函数
- reference at(int pos):返回pos位置元素的引用
- reference front():返回首元素的引用
- reference back():返回尾元素的引用
- iterator begin():返回向量头指针,指向第一个元素
- iterator end():返回向量尾指针,指向向量最后一个元素的下一个位置
- reverse_iterator rbegin():反向迭代器,指向最后一个元素
- reverse_iterator rend():反向迭代器,指向第一个元素之前的位置
5.判断函数
- bool empty() const:判断向量是否为空,若为空,则向量中无元素
6.大小函数
- int size() const:返回向量中元素的个数
- int capacity() const:返回当前向量张红所能容纳的最大元素值
- int max_size() const:返回最大可允许的vector元素数量值
7.其他函数
- void swap(vector&):交换两个同类型向量的数据
- void assign(int n,const T& x):设置向量中第n个元素的值为x
- void assign(const_iterator first,const_iterator last):向量中[first,last)中元素设置成当前向量元素
8.看着清楚
1.push_back 在数组的最后添加一个数据
2.pop_back 去掉数组的最后一个数据
.at-Domain Parked 得到编号位置的数据
4.begin 得到数组头的指针
5.end 得到数组的最后一个单元+1的指针
6.front 得到数组头的引用
7.back 得到数组的最后一个单元的引用
8.max_size 得到vector最大可以是多大
9.capacity 当前vector分配的大小
10.size 当前使用数据的大小
11.resize 改变当前使用数据的大小,如果它比当前使用的大,者填充默认值
12.reserve 改变当前vecotr所分配空间的大小
13.erase 删除指针指向的数据项
14.clear 清空当前的vector
15.rbegin 将vector反转后的开始指针返回(其实就是原来的end-1)
16.rend 将vector反转构的结束指针返回(其实就是原来的begin-1)
17.empty 判断vector是否为空
18.swap 与另一个vector交换数据
3.1.2 基本用法
#include < vector >
using namespace std;
3.1.3 简单介绍
- Vector<类型>标识符
- Vector<类型>标识符(最大容量)
- Vector<类型>标识符(最大容量,初始所有值)
- Int i[5]={1,2,3,4,5}
- Vector<类型>vi(I,i+2);//得到i索引值为3以后的值
- Vector< vector< int> >v; 二维向量//这里最外的<>要有空格。否则在比较旧的编译器下无法通过
3.1.4 实例
3.1.4.1 pop_back()&push_back(elem)实例在容器最后移除和插入数据
#include < string.h >
#include < vector >
#include < iostream >
using namespace std;
int main()
{
vector< int >obj;//创建一个向量存储容器 int
for(int i=0;i< 10;i++) // push_back(elem)在数组最后添加数据
{
obj.push_back(i);
cout<
输出结果为:
0,1,2,3,4,5,6,7,8,9,
0,1,2,3,4,
3.1.4.2 clear()清除容器中所有数据
#include < string.h >
#include < vector >
#include < iostream >
using namespace std;
int main()
{
vector< int >obj;
for(int i=0;i< 10;i++)//push_back(elem)在数组最后添加数据
{
obj.push_back(i);
cout<
输出结果为:
0,1,2,3,4,5,6,7,8,9,
3.1.4.3 排序
#include < string.h >
#include < vector >
#include < iostream >
#include < algorithm >
using namespace std;
int main()
{
vector< int >obj;
obj.push_back(1);
obj.push_back(3);
obj.push_back(0);
sort(obj.begin(),obj.end());//从小到大
cout< < "从小到大:"<
输出结果为:
从小到大:
0,1,3,
从大到小:
3,1,0,
1.注意 sort 需要头文件 #include
2.如果想 sort 来降序,可重写 sort
bool compare(int a,int b)
{
return a< b; //升序排列,如果改为return a >b,则为降序
}
int a[20]={2,4,1,23,5,76,0,43,24,65},i;
for(i=0;i< 20;i++)
cout< < a[i]< < endl;
sort(a,a+20,compare);
3.1.4.4 访问(直接数组访问&迭代器访问)
#include < string.h >
#include < vector >
#include < iostream >
#include < algorithm >
using namespace std;
int main()
{
//顺序访问
vector< int >obj;
for(int i=0;i< 10;i++)
{
obj.push_back(i);
}
cout< < "直接利用数组:";
for(int i=0;i< 10;i++)//方法一
{
cout<
输出结果为:
直接利用数组:0 1 2 3 4 5 6 7 8 9
利用迭代器:0 1 2 3 4 5 6 7 8 9
3.1.4.5 二维数组两种定义方法(结果一样)
方法一
#include < string.h >
#include < vector >
#include < iostream >
#include < algorithm >
using namespace std;
int main()
{
int N=5, M=6;
vector< vector< int > > obj(N); //定义二维动态数组大小5行
for(int i =0; i< obj.size(); i++)//动态二维数组为5行6列,值全为0
{
obj[i].resize(M);
}
for(int i=0; i< obj.size(); i++)//输出二维动态数组
{
for(int j=0;j< obj[i].size();j++)
{
cout<
方法二
#include < string.h >
#include < vector >
#include < iostream >
#include < algorithm >
using namespace std;
int main()
{
int N=5, M=6;
vector< vector< int > > obj(N, vector< int >(M)); //定义二维动态数组5行6列
for(int i=0; i< obj.size(); i++)//输出二维动态数组
{
for(int j=0;j< obj[i].size();j++)
{
cout<
输出结果为:
0 0 0 0 0 0
0 0 0 0 0 0
0 0 0 0 0 0
0 0 0 0 0 0
0 0 0 0 0 0
3.2 deque
所谓的deque是”double ended queue”的缩写,双端队列不论在尾部或头部插入元素,都十分迅速。而在中间插入元素则会比较费时,因为必须移动中间其他的元素。双端队列是一种随机访问的数据类型,提供了在序列两端快速插入和删除操作的功能,它可以在需要的时候改变自身大小,完成了标准的C++数据结构中队列的所有功能。
Vector是单向开口的连续线性空间,deque则是一种双向开口的连续线性空间。deque对象在队列的两端放置元素和删除元素是高效的,而向量vector只是在插入序列的末尾时操作才是高效的。deque和vector的最大差异,一在于deque允许于常数时间内对头端进行元素的插入或移除操作,二在于deque没有所谓的capacity观念,因为它是动态地以分段连续空间组合而成,随时可以增加一段新的空间并链接起来。换句话说,像vector那样“因旧空间不足而重新配置一块更大空间,然后复制元素,再释放旧空间”这样的事情在deque中是不会发生的。也因此,deque没有必要提供所谓的空间预留(reserved)功能。
虽然deque也提供Random Access Iterator,但它的迭代器并不是普通指针,其复杂度和vector不可同日而语,这当然涉及到各个运算层面。因此,除非必要,我们应尽可能选择使用vector而非deque。对deque进行的排序操作,为了最高效率,可将deque先完整复制到一个vector身上,将vector排序后(利用STL的sort算法),再复制回deque。
deque是一种优化了的对序列两端元素进行添加和删除操作的基本序列容器。通常由一些独立的区块组成,第一区块朝某方向扩展,最后一个区块朝另一方向扩展。它允许较为快速地随机访问但它不像vector一样把所有对象保存在一个连续的内存块,而是多个连续的内存块。并且在一个映射结构中保存对这些块以及顺序的跟踪。
3.2.1 声明deque容器
#include< deque > // 头文件
deque< type > deq; // 声明一个元素类型为type的双端队列que
deque< type > deq(size); // 声明一个类型为type、含有size个默认值初始化元素的的双端队列que
deque< type > deq(size, value); // 声明一个元素类型为type、含有size个value元素的双端队列que
deque< type > deq(mydeque); // deq是mydeque的一个副本
deque< type > deq(first, last); // 使用迭代器first、last范围内的元素初始化deq
3.2.2 deque的常用成员函数
deque< int > deq;
- deq[ ]:用来访问双向队列中单个的元素。
- deq.front():返回第一个元素的引用。
- deq.back():返回最后一个元素的引用。
- deq.push_front(x):把元素x插入到双向队列的头部。
- deq.pop_front():弹出双向队列的第一个元素。
- deq.push_back(x):把元素x插入到双向队列的尾部。
- deq.pop_back():弹出双向队列的最后一个元素。
3.2.3 deque的一些特点
- 支持随机访问,即支持[ ]以及at(),但是性能没有vector好。
- 可以在内部进行插入和删除操作,但性能不及list。
- deque两端都能够快速插入和删除元素,而vector只能在尾端进行。
- deque的元素存取和迭代器操作会稍微慢一些,因为deque的内部结构会多一个间接过程。
- deque迭代器是特殊的智能指针,而不是一般指针,它需要在不同的区块之间跳转。
- deque可以包含更多的元素,其max_size可能更大,因为不止使用一块内存。
- deque不支持对容量和内存分配时机的控制。
- 在除了首尾两端的其他地方插入和删除元素,都将会导致指向deque元素的任何pointers、references、iterators失效。不过,deque的内存重分配优于vector,因为其内部结构显示不需要复制所有元素。
- deque的内存区块不再被使用时,会被释放,deque的内存大小是可缩减的。不过,是不是这么做以及怎么做由实际操作版本定义。
- deque不提供容量操作:capacity()和reverse(),但是vector可以。
3.2.4 实例
#include< iostream >
#include< stdio.h >
#include< deque >
using namespace std;
int main(void)
{
int i;
int a[10] = { 0,1,2,3,4,5,6,7,8,9 };
deque< int > q;
for (i = 0; i <= 9; i++)
{
if (i % 2 == 0)
q.push_front(a[i]);
else
q.push_back(a[i]);
} /*此时队列里的内容是: {8,6,4,2,0,1,3,5,7,9}*/
q.pop_front();
printf("%dn", q.front()); /*清除第一个元素后输出第一个(6)*/
q.pop_back();
printf("%dn", q.back()); /*清除最后一个元素后输出最后一个(7)*/
deque< int >::iterator it;
for (it = q.begin(); it != q.end(); it++) {
cout < < *it < < 't';
}
cout < < endl;
system("pause");
return 0;
}
输出结果:
3.3 list
3.3.1 list定义
List是stl实现的双向链表,与向量(vectors)相比, 它允许快速的插入和删除,但是随机访问却比较慢。使用时需要添加头文件
#include
3.3.2 list定义和初始化
listlst1; //创建空list
list lst2(5); //创建含有5个元素的list
listlst3(3,2); //创建含有3个元素的list
listlst4(lst2); //使用lst2初始化lst4
listlst5(lst2.begin(),lst2.end()); //同lst4
3.3.3 list常用操作函数
Lst1.assign() 给list赋值
Lst1.back() 返回最后一个元素
Lst1.begin() 返回指向第一个元素的迭代器
Lst1.clear() 删除所有元素
Lst1.empty() 如果list是空的则返回true
Lst1.end() 返回末尾的迭代器
Lst1.erase() 删除一个元素
Lst1.front() 返回第一个元素
Lst1.get_allocator() 返回list的配置器
Lst1.insert() 插入一个元素到list中
Lst1.max_size() 返回list能容纳的最大元素数量
Lst1.merge() 合并两个list
Lst1.pop_back() 删除最后一个元素
Lst1.pop_front() 删除第一个元素
Lst1.push_back() 在list的末尾添加一个元素
Lst1.push_front() 在list的头部添加一个元素
Lst1.rbegin() 返回指向第一个元素的逆向迭代器
Lst1.remove() 从list删除元素
Lst1.remove_if() 按指定条件删除元素
Lst1.rend() 指向list末尾的逆向迭代器
Lst1.resize() 改变list的大小
Lst1.reverse() 把list的元素倒转
Lst1.size() 返回list中的元素个数
Lst1.sort() 给list排序
Lst1.splice() 合并两个list
Lst1.swap() 交换两个list
Lst1.unique() 删除list中相邻重复的元素
3.3.4 List使用实例
3.3.4.1 迭代器遍历list
for(list< int >::const_iteratoriter = lst1.begin();iter != lst1.end();iter++)
{
cout< < *iter;
}
cout<
3.3.4.2 综合实例1
#include < iostream >
#include < list >
#include < numeric >
#include < algorithm >
using namespace std;
typedef list< int > LISTINT;
typedef list< int > LISTCHAR;
void main()
{
//用LISTINT创建一个list对象
LISTINT listOne;
//声明i为迭代器
LISTINT::iterator i;
listOne.push_front(3);
listOne.push_front(2);
listOne.push_front(1);
listOne.push_back(4);
listOne.push_back(5);
listOne.push_back(6);
cout < < "listOne.begin()--- listOne.end():" < < endl;
for (i = listOne.begin(); i != listOne.end(); ++i)
cout < < *i < < " ";
cout < < endl;
LISTINT::reverse_iterator ir;
cout < < "listOne.rbegin()---listOne.rend():" < < endl;
for (ir = listOne.rbegin(); ir != listOne.rend(); ir++) {
cout < < *ir < < " ";
}
cout < < endl;
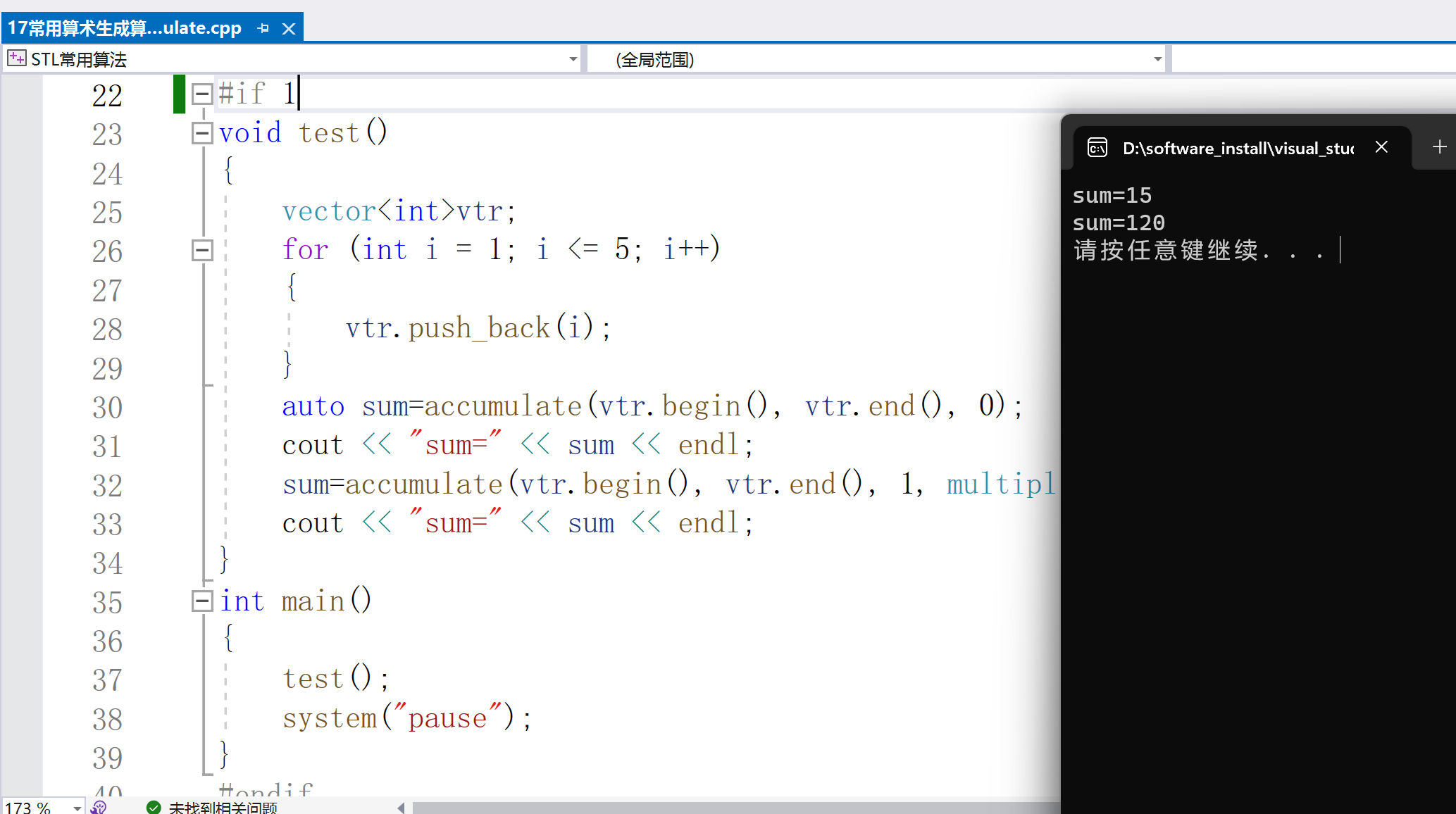
int result = accumulate(listOne.begin(), listOne.end(), 0);
cout < < "Sum=" < < result < < endl;
cout < < "------------------" < < endl;
//用LISTCHAR创建一个list对象
LISTCHAR listTwo;
//声明i为迭代器
LISTCHAR::iterator j;
listTwo.push_front('C');
listTwo.push_front('B');
listTwo.push_front('A');
listTwo.push_back('D');
listTwo.push_back('E');
listTwo.push_back('F');
cout < < "listTwo.begin()---listTwo.end():" < < endl;
for (j = listTwo.begin(); j != listTwo.end(); ++j)
cout < < char(*j) < < " ";
cout < < endl;
j = max_element(listTwo.begin(), listTwo.end());
cout < < "The maximum element in listTwo is: " < < char(*j) < < endl;
system("pause");
}
输出结果
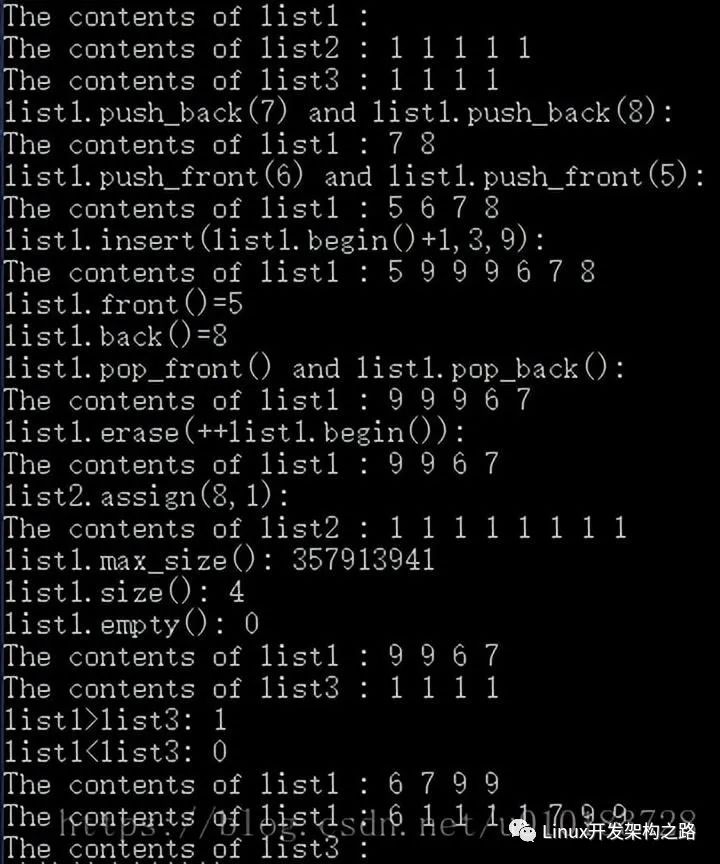
3.3.4.3 综合实例2
#include < iostream >
#include < list >
using namespace std;
typedef list< int > INTLIST;
//从前向后显示list队列的全部元素
void put_list(INTLIST list, char *name)
{
INTLIST::iterator plist;
cout < < "The contents of " < < name < < " : ";
for (plist = list.begin(); plist != list.end(); plist++)
cout < < *plist < < " ";
cout < < endl;
}
//测试list容器的功能
void main(void)
{
//list1对象初始为空
INTLIST list1;
INTLIST list2(5, 1);
INTLIST list3(list2.begin(), --list2.end());
//声明一个名为i的双向迭代器
INTLIST::iterator i;
put_list(list1, "list1");
put_list(list2, "list2");
put_list(list3, "list3");
list1.push_back(7);
list1.push_back(8);
cout < < "list1.push_back(7) and list1.push_back(8):" < < endl;
put_list(list1, "list1");
list1.push_front(6);
list1.push_front(5);
cout < < "list1.push_front(6) and list1.push_front(5):" < < endl;
put_list(list1, "list1");
list1.insert(++list1.begin(), 3, 9);
cout < < "list1.insert(list1.begin()+1,3,9):" < < endl;
put_list(list1, "list1");
//测试引用类函数
cout < < "list1.front()=" < < list1.front() < < endl;
cout < < "list1.back()=" < < list1.back() < < endl;
list1.pop_front();
list1.pop_back();
cout < < "list1.pop_front() and list1.pop_back():" < < endl;
put_list(list1, "list1");
list1.erase(++list1.begin());
cout < < "list1.erase(++list1.begin()):" < < endl;
put_list(list1, "list1");
list2.assign(8, 1);
cout < < "list2.assign(8,1):" < < endl;
put_list(list2, "list2");
cout < < "list1.max_size(): " < < list1.max_size() < < endl;
cout < < "list1.size(): " < < list1.size() < < endl;
cout < < "list1.empty(): " < < list1.empty() < < endl;
put_list(list1, "list1");
put_list(list3, "list3");
cout < < "list1 >list3: " < < (list1 > list3) < < endl;
cout < < "list1< list3: " < < (list1 < list3) < < endl;
list1.sort();
put_list(list1, "list1");
list1.splice(++list1.begin(), list3);
put_list(list1, "list1");
put_list(list3, "list3");
system("pause");
}
输出结果:
3.4 map/multimap
map和multimap都需要#include,唯一的不同是,map的键值key不可重复,而multimap可以,也正是由于这种区别,map支持[ ]运算符,multimap不支持[ ]运算符。在用法上没什么区别。
C++中map提供的是一种键值对容器,里面的数据都是成对出现的,如下图:每一对中的第一个值称之为关键字(key),每个关键字只能在map中出现一次;第二个称之为该关键字的对应值。

Map是STL的一个关联容器,它提供一对一(其中第一个可以称为关键字,每个关键字只能在map中出现一次,第二个可能称为该关键字的值)的数据 处理能力,由于这个特性,它完成有可能在我们处理一对一数据的时候,在编程上提供快速通道。这里说下map内部数据的组织,map内部自建一颗红黑树(一 种非严格意义上的平衡二叉树),这颗树具有对数据自动排序的功能,所以在map内部所有的数据都是有序的。
3.4.1 基本操作函数
begin() 返回指向map头部的迭代器
clear() 删除所有元素
count() 返回指定元素出现的次数
empty() 如果map为空则返回true
end() 返回指向map末尾的迭代器
equal_range() 返回特殊条目的迭代器对
erase() 删除一个元素
find() 查找一个元素
get_allocator() 返回map的配置器
insert() 插入元素
key_comp() 返回比较元素key的函数
lower_bound() 返回键值>=给定元素的第一个位置
max_size() 返回可以容纳的最大元素个数
rbegin() 返回一个指向map尾部的逆向迭代器
rend() 返回一个指向map头部的逆向迭代器
size() 返回map中元素的个数
swap() 交换两个map
upper_bound() 返回键值>给定元素的第一个位置
value_comp() 返回比较元素value的函数
3.4.2 声明
//头文件
#include< map >
map< int, string > ID_Name;
// 使用{}赋值是从c++11开始的,因此编译器版本过低时会报错,如visual studio 2012
map< int, string > ID_Name = {
{ 2015, "Jim" },
{ 2016, "Tom" },
{ 2017, "Bob" } };
3.4.3 迭代器
共有八个获取迭代器的函数:* begin, end, rbegin,rend* 以及对应的 * cbegin, cend, crbegin,crend*。
二者的区别在于,后者一定返回 const_iterator,而前者则根据map的类型返回iterator 或者 const_iterator。const情况下,不允许对值进行修改。如下面代码所示:
map< int,int >::iterator it;
map< int,int > mmap;
const map< int,int > const_mmap;
it = mmap.begin(); //iterator
mmap.cbegin(); //const_iterator
const_mmap.begin(); //const_iterator
const_mmap.cbegin(); //const_iterator
返回的迭代器可以进行加减操作,此外,如果map为空,则 begin = end。

3.4.4 插入操作
3.4.4.1 用insert插入pair数据
//数据的插入--第一种:用insert函数插入pair数据
#include < map >
#include < string >
#include < iostream >
using namespace std;
int main()
{
map< int, string > mapStudent;
mapStudent.insert(pair< int, string >(1, "student_one"));
mapStudent.insert(pair< int, string >(2, "student_two"));
mapStudent.insert(pair< int, string >(3, "student_three"));
map< int, string >::iterator iter;
for(iter = mapStudent.begin(); iter != mapStudent.end(); iter++)
cout<
3.4.4.2 用insert函数插入value_type数据
//第二种:用insert函数插入value_type数据,下面举例说明
#include < map >
#include < string >
#include < iostream >
using namespace std;
int main()
{
map< int, string > mapStudent;
mapStudent.insert(map< int, string >::value_type (1, "student_one"));
mapStudent.insert(map< int, string >::value_type (2, "student_two"));
mapStudent.insert(map< int, string >::value_type (3, "student_three"));
map< int, string >::iterator iter;
for(iter = mapStudent.begin(); iter != mapStudent.end(); iter++)
cout<
3.4.4.3 用insert函数进行多个插入
insert共有4个重载函数:
// 插入单个键值对,并返回插入位置和成功标志,插入位置已经存在值时,插入失败
pair< iterator,bool > insert (const value_type& val);
//在指定位置插入,在不同位置插入效率是不一样的,因为涉及到重排
iterator insert (const_iterator position, const value_type& val);
// 插入多个
void insert (InputIterator first, InputIterator last);
//c++11开始支持,使用列表插入多个
void insert (initializer_list< value_type > il);
下面是具体使用示例:
#include < iostream >
#include < map >
int main()
{
std::map< char, int > mymap;
// 插入单个值
mymap.insert(std::pair< char, int >('a', 100));
mymap.insert(std::pair< char, int >('z', 200));
//返回插入位置以及是否插入成功
std::pair< std::map< char, int >::iterator, bool > ret;
ret = mymap.insert(std::pair< char, int >('z', 500));
if (ret.second == false) {
std::cout < < "element 'z' already existed";
std::cout < < " with a value of " < < ret.first- >second < < 'n';
}
//指定位置插入
std::map< char, int >::iterator it = mymap.begin();
mymap.insert(it, std::pair< char, int >('b', 300)); //效率更高
mymap.insert(it, std::pair< char, int >('c', 400)); //效率非最高
//范围多值插入
std::map< char, int > anothermap;
anothermap.insert(mymap.begin(), mymap.find('c'));
// 列表形式插入
anothermap.insert({ { 'd', 100 }, {'e', 200} });
return 0;
}
3.4.4.4 用数组方式插入数据
//第三种:用数组方式插入数据,下面举例说明
#include < map >
#include < string >
#include < iostream >
using namespace std;
int main()
{
map< int, string > mapStudent;
mapStudent[1] = "student_one";
mapStudent[2] = "student_two";
mapStudent[3] = "student_three";
map< int, string >::iterator iter;
for(iter = mapStudent.begin(); iter != mapStudent.end(); iter++)
cout<
以上三种用法,虽然都可以实现数据的插入,但是它们是有区别的,当然了第一种和第二种在效果上是完成一样的,用insert函数插入数据,在数据的 插入上涉及到集合的唯一性这个概念,即当map中有这个关键字时,insert操作是插入数据不了的,但是用数组方式就不同了,它可以覆盖以前该关键字对 应的值,用程序说明
mapStudent.insert(map::value_type (1, "student_one"));
mapStudent.insert(map::value_type (1, "student_two"));
上面这两条语句执行后,map中1这个关键字对应的值是“student_one”,第二条语句并没有生效,那么这就涉及到我们怎么知道insert语句是否插入成功的问题了,可以用pair来获得是否插入成功,程序如下
pair::iterator, bool> Insert_Pair;
Insert_Pair = mapStudent.insert(map::value_type (1, "student_one"));
我们通过pair的第二个变量来知道是否插入成功,它的第一个变量返回的是一个map的迭代器,如果插入成功的话Insert_Pair.second应该是true的,否则为false。
下面给出完成代码,演示插入成功与否问题
//验证插入函数的作用效果
#include < map >
#include < string >
#include < iostream >
using namespace std;
int main()
{
map< int, string > mapStudent;
pair< map< int, string >::iterator, bool > Insert_Pair;
Insert_Pair = mapStudent.insert(pair< int, string >(1, "student_one"));
if(Insert_Pair.second == true)
cout< < "Insert Successfully"<
大家可以用如下程序,看下用数组插入在数据覆盖上的效果
//验证数组形式插入数据的效果
#include < map >
#include < string >
#include < iostream >
using namespace std;
int main()
{
map< int, string > mapStudent;
mapStudent[1] = "student_one";
mapStudent[1] = "student_two";
mapStudent[2] = "student_three";
map< int, string >::iterator iter;
for(iter = mapStudent.begin(); iter != mapStudent.end(); iter++)
cout<
3.4.5 查找、删除、交换
查找
// 关键字查询,找到则返回指向该关键字的迭代器,否则返回指向end的迭代器
// 根据map的类型,返回的迭代器为 iterator 或者 const_iterator
iterator find (const key_type& k);
const_iterator find (const key_type& k) const;
删除
// 删除迭代器指向位置的键值对,并返回一个指向下一元素的迭代器
iterator erase( iterator pos )
// 删除一定范围内的元素,并返回一个指向下一元素的迭代器
iterator erase( const_iterator first, const_iterator last );
// 根据Key来进行删除, 返回删除的元素数量,在map里结果非0即1
size_t erase( const key_type& key );
// 清空map,清空后的size为0
void clear();
交换
// 就是两个map的内容互换
void swap( map& other );
3.4.6 容量
// 查询map是否为空
bool empty();
// 查询map中键值对的数量
size_t size();
// 查询map所能包含的最大键值对数量,和系统和应用库有关。
// 此外,这并不意味着用户一定可以存这么多,很可能还没达到就已经开辟内存失败了
size_t max_size();
// 查询关键字为key的元素的个数,在map里结果非0即1
size_t count( const Key& key ) const; //
3.4.7 排序
map中的元素是自动按Key升序排序,所以不能对map用sort函数;
这里要讲的是一点比较高深的用法了,排序问题,STL中默认是采用小于号来排序的,以上代码在排序上是不存在任何问题的,因为上面的关键字是int 型,它本身支持小于号运算,在一些特殊情况,比如关键字是一个结构体或者自定义类,涉及到排序就会出现问题,因为它没有小于号操作,insert等函数在编译的时候过 不去,下面给出两个方法解决这个问题。
3.4.7.1 小于号 < 重载
#include < iostream >
#include < string >
#include < map >
using namespace std;
typedef struct tagStudentinfo
{
int niD;
string strName;
bool operator < (tagStudentinfo const& _A) const
{ //这个函数指定排序策略,按niD排序,如果niD相等的话,按strName排序
if (niD < _A.niD) return true;
if (niD == _A.niD)
return strName.compare(_A.strName) < 0;
return false;
}
}Studentinfo, *PStudentinfo; //学生信息
int main()
{
int nSize; //用学生信息映射分数
map< Studentinfo, int >mapStudent;
map< Studentinfo, int >::iterator iter;
Studentinfo studentinfo;
studentinfo.niD = 1;
studentinfo.strName = "student_one";
mapStudent.insert(pair< Studentinfo, int >(studentinfo, 90));
studentinfo.niD = 2;
studentinfo.strName = "student_two";
mapStudent.insert(pair< Studentinfo, int >(studentinfo, 80));
for (iter = mapStudent.begin(); iter != mapStudent.end(); iter++)
cout < < iter- >first.niD < < ' ' < < iter- >first.strName < < ' ' < < iter- >second < < endl;
return 0;
}
3.4.7.2 仿函数的应用,这个时候结构体中没有直接的小于号重载
//第二种:仿函数的应用,这个时候结构体中没有直接的小于号重载,程序说明
#include < iostream >
#include < map >
#include < string >
using namespace std;
typedef struct tagStudentinfo
{
int niD;
string strName;
}Studentinfo, *PStudentinfo; //学生信息
class sort
{
public:
bool operator() (Studentinfo const &_A, Studentinfo const &_B) const
{
if (_A.niD < _B.niD)
return true;
if (_A.niD == _B.niD)
return _A.strName.compare(_B.strName) < 0;
return false;
}
};
int main()
{
//用学生信息映射分数
map< Studentinfo, int, sort >mapStudent;
map< Studentinfo, int >::iterator iter;
Studentinfo studentinfo;
studentinfo.niD = 1;
studentinfo.strName = "student_one";
mapStudent.insert(pair< Studentinfo, int >(studentinfo, 90));
studentinfo.niD = 2;
studentinfo.strName = "student_two";
mapStudent.insert(pair< Studentinfo, int >(studentinfo, 80));
for (iter = mapStudent.begin(); iter != mapStudent.end(); iter++)
cout < < iter- >first.niD < < ' ' < < iter- >first.strName < < ' ' < < iter- >second < < endl;
system("pause");
}
3.4.8 unordered_map
在c++11标准前,c++标准库中只有一种map,但是它的底层实现并不是适合所有的场景,如果我们需要其他适合的map实现就不得不使用比如boost库等三方的实现,在c++11中加了一种map unordered_map,unordered_set,他们的实现有什么不同呢?
map底层采用的是红黑树的实现查询的时间复杂度为O(logn),看起来并没有unordered_map快,但是也要看实际的数据量,虽然unordered_map的查询从算法上分析比map快,但是它有一些其它的消耗,比如哈希函数的构造和分析,还有如果出现哈希冲突解决哈希冲突等等都有一定的消耗,因此unordered_map的效率在很大的程度上由它的hash函数算法决定,而红黑树的效率是一个稳定值。
unordered_map的底层采用哈希表的实现,查询的时间复杂度为是O(1)。所以unordered_map内部就是无序的,数据是按散列函数插入到槽里面去的,数据之间无顺序可言,如果我们不需要内部有序,这种实现是没有问题的。unordered_map属于关联式容器,采用std::pair保存key-value形式的数据。用法与map一致。特别的是,STL中的map因为是有序的二叉树存储,所以对key值需要有大小的判断,当使用内置类型时,无需重载operator < ;但是用用户自定义类型的话,就需要重载operator < 。 unoredered_map全程使用不需要比较元素的key值的大小,但是,对于元素的==要有判断,又因为需要使用hash映射,所以,对于非内部类型,需要程序员为其定义这二者的内容,对于内部类型,就不需要了。unordered库使用“桶”来存储元素,散列值相同的被存储在一个桶里。当散列容器中有大量数据时,同一个桶里的数据也会增多,造成访问冲突,降低性能。为了提高散列容器的性能,unordered库会在插入元素是自动增加桶的数量,不需要用户指定。但是,用户也可以在构造函数或者rehash()函数中,指定最小的桶的数量。
还有另外一点从占用内存上来说因为unordered_map才用hash结构会有一定的内存损失,它的内存占用回高于map。
最后就是她们的场景了,首先如果你需要对map中的数据排序,就首选map,他会把你的数据按照key的自然排序排序(由于它的底层实现红黑树机制所以会排序),如果不需要排序,就看你对内存和cpu的选择了,不过一般都会选择unordered_map,它的查找效率会更高。
至于使用方法和函数,两者差不多,由于篇幅限制这里不再赘述,unordered_multimap用法亦可类推。
3.5 set/multiset
std::set 是关联容器,含有 Key 类型对象的已排序集。用比较函数compare进行排序。搜索、移除和插入拥有对数复杂度。 set 通常以红黑树实现。
set容器内的元素会被自动排序,set与map不同,set中的元素即是键值又是实值,set不允许两个元素有相同的键值。不能通过set的迭代器去修改set元素,原因是修改元素会破坏set组织。当对容器中的元素进行插入或者删除时,操作之前的所有迭代器在操作之后依然有效。
由于set元素是排好序的,且默认为升序,因此当set集合中的元素为结构体或自定义类时,该结构体或自定义类必须实现运算符‘<’的重载。
multiset特性及用法和set完全相同,唯一的差别在于它允许键值重复。
set和multiset的底层实现是一种高效的平衡二叉树,即红黑树(Red-Black Tree)。
3.5.1 set常用成员函数
- begin()--返回指向第一个元素的迭代器
- clear()--清除所有元素
- count()--返回某个值元素的个数
- empty()--如果集合为空,返回true
- end()--返回指向最后一个元素的迭代器
- equal_range()--返回集合中与给定值相等的上下限的两个迭代器
- erase()--删除集合中的元素
- find()--返回一个指向被查找到元素的迭代器
- get_allocator()--返回集合的分配器
- insert()--在集合中插入元素
- lower_bound()--返回指向大于(或等于)某值的第一个元素的迭代器
- key_comp()--返回一个用于元素间值比较的函数
- max_size()--返回集合能容纳的元素的最大限值
- rbegin()--返回指向集合中最后一个元素的反向迭代器
- rend()--返回指向集合中第一个元素的反向迭代器
- size()--集合中元素的数目
- swap()--交换两个集合变量
- upper_bound()--返回大于某个值元素的迭代器
- value_comp()--返回一个用于比较元素间的值的函数
3.5.2 代码示例
以下代码涉及的内容:
1、set容器中,元素类型为基本类型,如何让set按照用户意愿来排序?
2、set容器中,如何让元素类型为自定义类型?
3、set容器的insert函数的返回值为什么类型?
#include < iostream >
#include < string >
#include < set >
using namespace std;
/* 仿函数CompareSet,在test02使用 */
class CompareSet
{
public:
//从大到小排序
bool operator()(int v1, int v2)
{
return v1 > v2;
}
//从小到大排序
//bool operator()(int v1, int v2)
//{
// return v1 < v2;
//}
};
/* Person类,用于test03 */
class Person
{
friend ostream &operator< < (ostream &out, const Person &person);
public:
Person(string name, int age)
{
mName = name;
mAge = age;
}
public:
string mName;
int mAge;
};
ostream &operator< < (ostream &out, const Person &person)
{
out < < "name:" < < person.mName < < " age:" < < person.mAge < < endl;
return out;
}
/* 仿函数ComparePerson,用于test03 */
class ComparePerson
{
public:
//名字大的在前面,如果名字相同,年龄大的排前面
bool operator()(const Person &p1, const Person &p2)
{
if (p1.mName == p2.mName)
{
return p1.mAge > p2.mAge;
}
return p1.mName > p2.mName;
}
};
/* 打印set类型的函数模板 */
template< typename T >
void PrintSet(T &s)
{
for (T::iterator iter = s.begin(); iter != s.end(); ++iter)
cout < < *iter < < " ";
cout < < endl;
}
void test01()
{
//set容器默认从小到大排序
set< int > s;
s.insert(10);
s.insert(20);
s.insert(30);
//输出set
PrintSet(s);
//结果为:10 20 30
/* set的insert函数返回值为一个对组(pair)。
对组的第一个值first为set类型的迭代器:
1、若插入成功,迭代器指向该元素。
2、若插入失败,迭代器指向之前已经存在的元素
对组的第二个值seconde为bool类型:
1、若插入成功,bool值为true
2、若插入失败,bool值为false
*/
pair< set< int >::iterator, bool > ret = s.insert(40);
if (true == ret.second)
cout < < *ret.first < < " 插入成功" < < endl;
else
cout < < *ret.first < < " 插入失败" < < endl;
}
void test02()
{
/* 如果想让set容器从大到小排序,需要给set容
器提供一个仿函数,本例的仿函数为CompareSet
*/
set< int, CompareSet > s;
s.insert(10);
s.insert(20);
s.insert(30);
//打印set
PrintSet(s);
//结果为:30,20,10
}
void test03()
{
/* set元素类型为Person,当set元素类型为自定义类型的时候
必须给set提供一个仿函数,用于比较自定义类型的大小,
否则无法通过编译
*/
set< Person,ComparePerson > s;
s.insert(Person("John", 22));
s.insert(Person("Peter", 25));
s.insert(Person("Marry", 18));
s.insert(Person("Peter", 36));
//打印set
PrintSet(s);
}
int main(void)
{
//test01();
//test02();
//test03();
return 0;
}
multiset容器的insert函数返回值为什么?
#include < iostream >
#include < set >
using namespace std;
/* 打印set类型的函数模板 */
template< typename T >
void PrintSet(T &s)
{
for (T::iterator iter = s.begin(); iter != s.end(); ++iter)
cout < < *iter < < " ";
cout < < endl;
}
void test(void)
{
multiset< int > s;
s.insert(10);
s.insert(20);
s.insert(30);
//打印multiset
PrintSet(s);
/* multiset的insert函数返回值为multiset类型的迭代器,
指向新插入的元素。multiset允许插入相同的值,因此
插入一定成功,因此不需要返回bool类型。
*/
multiset< int >::iterator iter = s.insert(10);
cout < < *iter < < endl;
}
int main(void)
{
test();
return 0;
}
3.5.3 unordered_set
C++ 11中出现了两种新的关联容器:unordered_set和unordered_map,其内部实现与set和map大有不同,set和map内部实现是基于RB-Tree,而unordered_set和unordered_map内部实现是基于哈希表(hashtable),由于unordered_set和unordered_map内部实现的公共接口大致相同,所以本文以unordered_set为例。
unordered_set是基于哈希表,因此要了解unordered_set,就必须了解哈希表的机制。哈希表是根据关键码值而进行直接访问的数据结构,通过相应的哈希函数(也称散列函数)处理关键字得到相应的关键码值,关键码值对应着一个特定位置,用该位置来存取相应的信息,这样就能以较快的速度获取关键字的信息。比如:现有公司员工的个人信息(包括年龄),需要查询某个年龄的员工个数。由于人的年龄范围大约在[0,200],所以可以开一个200大小的数组,然后通过哈希函数得到key对应的key-value,这样就能完成统计某个年龄的员工个数。而在这个例子中,也存在这样一个问题,两个员工的年龄相同,但其他信息(如:名字、身份证)不同,通过前面说的哈希函数,会发现其都位于数组的相同位置,这里,就涉及到“冲突”。准确来说,冲突是不可避免的,而解决冲突的方法常见的有:开发地址法、再散列法、链地址法(也称拉链法)。而unordered_set内部解决冲突采用的是----链地址法,当用冲突发生时把具有同一关键码的数据组成一个链表。下图展示了链地址法的使用:

使用unordered_set需要包含#include头文件,同unordered_map类似,用法没有什么太大的区别,参考set/multiset。
除此之外unordered_multiset也是一种可选的容器。
-
C++
+关注
关注
21文章
2084浏览量
73289 -
STL
+关注
关注
0文章
85浏览量
18257 -
数据结构
+关注
关注
3文章
568浏览量
40023 -
程序设计
+关注
关注
3文章
261浏览量
30315
发布评论请先 登录
相关推荐
STL130N6F7 MOS管
STL130N6F7 MOS管
STL130N6F7 MOS管现货
X-CUBE-STL与ARM的STL的区别是什么?
effective stl中文版下载pdf
C++ STL的概念及举例
PLC控制系统设计教程: 加热炉送料系统——仿STL指令的编程方式梯形图举例


STL的概述

评论