 ADAS系统中的可行使区域Freespace到底如何检测?
ADAS系统中的可行使区域Freespace到底如何检测?
自动驾驶有可能大大减少交通事故、道路拥堵以及相关的经济损失。安全的自动驾驶需要检测周围的障碍物、移动物体并识别可驾驶区域。对于城市驾驶的所有附近物体以及高速公路驾驶的远处物体都必须执行此操作。当前的自动驾驶汽车通常会结合使用雷达、激光雷达、摄像头、高精度 GPS 和先前的地图信息来确定汽车周围的障碍物和路面上的安全行驶区域。
自由空间检测Freespace为自动驾驶车辆提供了对环境的信息感知。对于Freespace来说,最好的传感器检测方式是Velodyne 多光束激光传感器。这种高性能传感器能够对物体以及可行驶表面进行检测和分类。但是鉴于成本关系,要在自动驾驶领域大量普及显得不太可能。基于视觉的系统可以通过提供远距离物体和路面检测和分类来补充其他传感器。但是,视觉传感器在雨、雾和雪中的性能会显着下降,限制了其在晴朗天气下的适用性。
当然,这几十年来,基于图像处理的研究一直在扩展到解决道路分割问题。早期的方法,包括 FCN和 SegNet,提出了编码器-解码器架构,其中编码器可以生成多个尺度的特征图,解码器可以提供高预测精度的像素级分类。RBNet研究道路结构与其边界布置之间的上下文关系。RBA使用由反向注意力和边界注意力单元组成的残差细化模块。除了基于低级特征的算法之外,鉴于深度卷积神经网络最近在计算机视觉任务中取得的成功,DNN 成为解决自动驾驶中感知挑战的良好候选者。
此外,业内也还进行了许多其他的尝试,比如利用深度CNN 解决分割问题的研究,CNN 应用于自动驾驶感知任务的工作已经产生了专门的网络,可以检测摄像头画面中的其他车辆和车道,并且已经通过将自由空间问题视为语义分割的任务进行研究。然而,可能的道路障碍物和道路结构的多样性使得针对每种可能的障碍物和道路场景训练特定网络变得不切实际。特别是,获得涵盖所有可能场景的训练数据将非常困难。相反,采用更通用的检测器来确定可以安全行驶的自由路面Freespace将比检测道路目标语义显得更加实用。
本文将重点介绍两类不同类型的可行使区域检测方案。
基于占据网格的Freespace检测
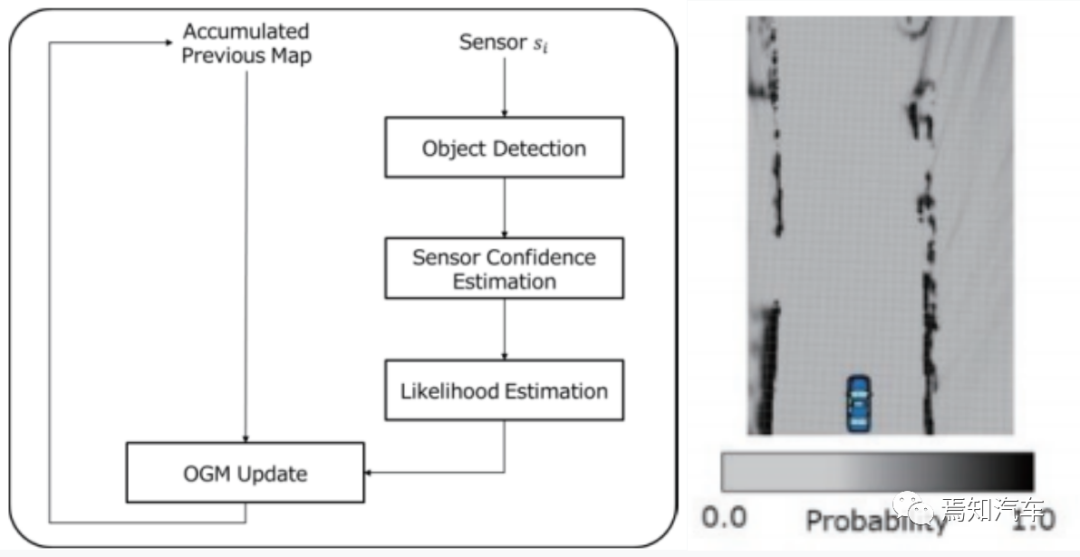
典型的可行使区域检测方法是通过占据网格图Occupancy Grid Map 的方式进行,占据网格图OGM是将区域分割为格子状,并通过分配给各各自单元的随机变量判别假设的方法。OGM是多个传感器输出的综合判定,由于与路径规划的搜索算法具有高度亲和性,在业内被用来作为可行使区域的有效代表。
如下图,首先通过各传感器对场景对象进行检测,期间,需要对各个传感器检测结果的置信度进行估计,随后需要对如上得出的可行使区域检测估计结果进行最大似然估计,从而更新占据网格信息。在这个更新过程中,通常需要使用先前累积的先验地图进行分析。
在占据网格图OGM生成网格图过程中,需要根据给定的数据计算映射的事后概率如下:
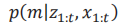
m表示地图,即到特定时刻为止传感器的全部观测量,*表示该特定时刻为止时,本车移动具体轨迹。例如,在100x100单元的地图中,由于各单元具有确定性占有/可能性占有两种状态。对于这样非常高维度的空间处理,若推定如上公式的后验概率,则需要大量的计算量。估计地图m的时候概率问题,替换为推定各小区后验概率的问题,此时,各小区后验概率如下:
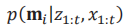
这种表示方式中,m表示具有索引单元格的网格图,映射m是各个单元mi的集合。
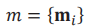
此时,用上式可以映射出后验概率如下:
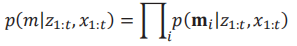
通过对如上后验概率的推断,可以得出相应的可行驶区域位置。
对于如上定义的传感器可靠性组合方法进行叙述。考虑传感器可靠性在不同场景应用下的概率可以用如下方程进行计算。
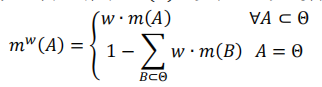
通过对各传感器进行综合推断,可以更新OGM的后验概率。
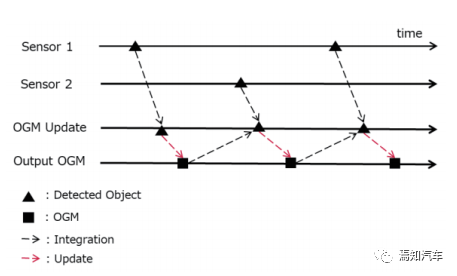
一般来说,在整合各传感器输出时,在对每个传感器生成OGM时,使用了将OGM彼此融合的方法。但是,在该方法中,由于需要生成与使用传感器数目相当的OGM。因此如果传感器数目增加,则存储器负荷和计算量也将增加。因此,较好的方法是不为每个传感器生成OGM,而是在传感器数据处理期间就进行融合运算生成对应共同的OGM。采用由各个传感器输出逐次更新的方法,由此能够更加高效的更新OGM。如下图表示了更新不同传感器的时间戳OGM。
基于 GoogLeNet 的网络
和 OverFeat 架构检测自由路面
另一种可行驶区域的检测方法是通过训练一个基于 GoogLeNet 和 OverFeat 架构的网络来检测高速快速公路环境中的自由路面。经过训练的网络在自由空间检测任务上表现非常出色。这将有可能基于计算机视觉的传感器用作自动驾驶汽车可行使区域检测,包括对一般障碍物的检测和安全驾驶区域的检测。
在本文中,网络的任务是在给定单个 640 x 480 分辨率相机帧的情况下检测自由路面。图像的每个 4 x 4 像素非重叠块被分类为自由路面或非自由路面。如果某个斑块包含车辆可以安全行驶的道路部分,则该斑块应被归类为自由路面。某些特定情况下,补丁如果不包含障碍物,例如另一辆车,或车辆无法行驶的表面,例如人行道/路肩,那对应的道路空间将不被定为可行使区域。
该数据集由 30 多个小时的 1 兆像素分辨率视频组成,由在湾区高速公路上行驶的车辆上的前置摄像头录制,相应的数据用车道和汽车标签进行提前标注。
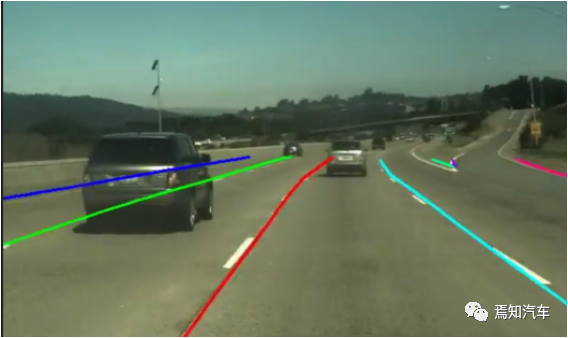
**图 1. **数据集中车道标签示例。80 米内的所有车道标记均已标记,该场景下无论遮挡情况
车道标注(见图1)指示高速公路上距离车辆80米以内的所有车道的位置,包括被其他车辆遮挡的车道,车道标签是根据相机和激光雷达点云数据生成的。首先自动提取泳道,然后由人工标注人员进行检查和纠正。
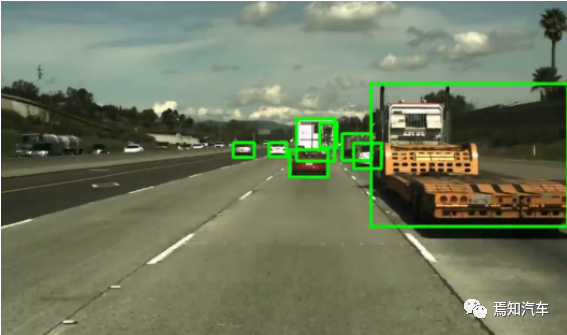
**图 2. **数据集中的汽车标签示例。100 米内所有完全可见和部分遮挡的车辆都标有边界框
汽车标注(见图 2)由车辆约 100 米内所有可见和部分遮挡车辆的边界框组成(最终组合标签见图 3)。汽车标签由人工标注团队通过 Amazon Mechanical Turk 生成。

**图 3. **显示自由路面标签的汽车和车道标签组合示例。绿色阴影区域显示标记为自由空间的图像区域。
在此数据集中,自由驾驶空间定义为两个车道标签之间不包含车辆的区域。网络预计会产生一个像素掩模,该像素掩模指示与上面定义的相同区域作为自由空间。定性结果将显示试驾的道路图像,并标明可行驶的路面。同时将定量地根据正确分类的图像块的F1分数来评估结果。我们直观地预计网络性能会随着车辆前方距离的增加而降低。理想情况下,该网络将能够识别各种道路结构和各种障碍物类型中的自由路面。最终数据集包含 13,000 个训练图像,1,300 张验证图像和 1,300 张测试图像。
该网络使用修改后的 GoogLeNet风格网络来生成图像特征。修改后的网络遵循 GoogLeNet 架构,仅到平均池化层为止。平均池化对于图像网络 ImageNet 分类任务效果很好,但自由空间检测任务需要本地信息,而平均池化将激活量减少为单个激活向量时可能会丢失这些信息。
图像中自由空间的定位是通过修改后的 OverFeat架构完成的,输入图像特征如上面生成的。该自由空间的定位是通过对图像特征激活后执行大小维度为 1 x 1 卷积来完成的,然后使用类似的全连接层和 softmax 分类得到注意力权重,从而生成0-1之间的概率分布关系值。Softmax计算后,实际上之前较高的得分会被增强,而较低的得分则会被抑制或淹没。也就是说,较高的Softmax会保留模型中认为更加重要的图层,降低的得分则会淹没不相关的图层,将输出向量输出到线性层进行处理,以此来更快更精准的确定环境的类别。应该注意的是,图像特征激活对应体积下的空间维度相对于原始图像尺寸要小一些。因此,在图像特征激活体积的空间维度上执行分类相对于原始图像中的受检测分类所提供的可行驶区域定位会差很多。
为了解决这个问题,在全连接层中使用额外的深度通道来表示图像中的特定位置。例如,最终的softmax激活量空间维度为 20 x 15,其中每个位置代表原始图像中的 32 x 32 像素块。然而,每个空间位置的深度为 128,因为原始图像中每个 32 x 32 像素块内都有 8 x 8 个 4 x 4 像素的块,并且有 2 个类:自由空间和非自由空间。这使得自由空间补丁的定位能够达到更精细的分辨率,同时仍然能够从原始图像的较大补丁中获取上下文信息。
这里介绍的训练网络在检测高速公路环境中的自由路面方面取得了良好的效果。该网络在 Caffe 框架中实现,并进行了一些修改。该网络在单个 Nvidia GeForce GTX TITAN Black GPU 上进行训练。该网络使用在 ImageNet 上训练的 BVLC GoogLeNet 的权重进行初始化,并使用自由空间数据集进行微调。
这些结果是通过在 ImageNet 数据上预训练 GoogLeNet 风格的架构并使用自由空间数据进行微调来实现的。通过相对较少的训练(仅 60,000 次迭代),该网络就能够正确识别自由路面,同时将其他车辆指示为障碍物。该网络还能够区分道路边界和其他道路标记。
该模型采用动量为 0.9 的小批量随机梯度下降进行训练。初始学习率设置为 0.01,每 3200 减少 0.96迭代。最终模型经过 60,000 次迭代训练批量大小为 10,即 46 个 epoch。典型定性测试集的结果如图 4 和 5 所示。

图 4. 红色阴影区域显示图像中该像素块的正确类别的 softmax 分数。该网络成功预测开放路面为空闲空间,同时指示卡车和其余车辆为非空闲空间。
图 5. 红色阴影区域显示图像中该像素块的正确类别的 softmax 分数。该网络成功地将开放路面预测为自由空间。请注意,尽管这两个区域在视觉上非常相似,但两侧的路肩并未标记为空闲。
以上两者测试图像显示,通过学习网络可以非常成功地将道路上的障碍物正确分类为非自由空间。它还成功区分了道路车道和路肩,即使这两个路面在视觉上非常相似。同时,该网络还可以随着车辆沿着道路曲线行驶过程中进行实时跟踪检测。
实际上,通过本文介绍的网络可以知道,局部像素信息不足以区分道路车道和路肩,因此较高级别的特征为了做出这种区分,网络层是必要的。随着其他车辆周围和道路边缘的检测变得更加清晰,网络可以进行定性区分。然而,这些改进并不能通过 F1 指标很好地衡量,因为它们只占用几个像素块。而这些细微的差异被大部分路面和主要包含天空和背景的图像顶部的大量正确分类所掩盖。
在未来的工作中,我们打算在更多不同的条件下收集更多的数据。特别是在城市情况下,涉及更多类型的障碍物,例如行人的语义区分。基于该实验结果,可以将该网络架构将扩展到更复杂的城市情况下的一般自由空间检测。
同时,必须制定更合适的量化指标,以更好地区分网络改进。在训练时,网络可以很快学会检测大部分空闲路面。在我们这里所用的数据集中,图像底部的大部分区域是自由路面,而图像顶部的大部分区域不是路面。
此外,更受人关注的区域是自由路面和非自由路面之间的边界区分。这种边界实际上需要进一步的模型训练,才能有助于网络在这些边界上做出更好的预测,最终在自由空间和障碍物或道路边缘之间提供非常清晰的边界。准确一点的说,在未来的工作中,道路模型学习网络的训练可能会把整个损失函数集中在边界上,而不是对所有像素块进行平均加权。因此,集中力量在自由空间边界上训练的学习网络将有可能会提供更好的结果。
审核编辑:刘清
-
传感器
+关注
关注
2550文章
51034浏览量
753039 -
解码器
+关注
关注
9文章
1143浏览量
40716 -
编码器
+关注
关注
45文章
3638浏览量
134417 -
ADAS系统
+关注
关注
4文章
226浏览量
25691 -
卷积神经网络
+关注
关注
4文章
367浏览量
11863
原文标题:行车篇 | ADAS系统中的可行使区域Freespace到底如何检测?
文章出处:【微信号:阿宝1990,微信公众号:阿宝1990】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
ADAS高级驾驶辅助系统

爱普生晶体在车载系统应用案例-ADAS系统的部分应用

使用FPGA构建ADAS系统简易过程
康谋分享 | AD/ADAS的性能概览:在AD/ADAS的开发与验证中“大海捞针”!





千亿高级驾驶辅助市场不可或缺的技术,是提升LiDAR和ADAS性能的关键!
机器视觉检测解决方案:高风险区域防闯检测

自动驾驶中多模态下的Freespace检测轻量化设计实现






 工商网监
工商网监
评论