 什么是结构体的字节对齐现象
什么是结构体的字节对齐现象
什么是结构体的字节对齐现象
程序员,咱都用代码说话,先上 code:
(说明:以下代码均在 ARM 平台上,使用 Keil 进行编译测试)
//上面这个宏定义主要用于显示结构体成员变量相对结构体起始地址的偏移
typedef structstu1{ int a; char b; int c;}stu1;
void main(){ LOG_INFO("rnrn====== Struct Test ======rnrn"); LOG_INFO("offset_of(stu1,a):t%dn",offset_of(stu1,a)); LOG_INFO("offset_of(stu1,b):t%dn",offset_of(stu1,b)); LOG_INFO("offset_of(stu1,c):t%dn",offset_of(stu1,c)); LOG_INFO("sizeof(stu1) :t%dn",sizeof(stu1)); return ;}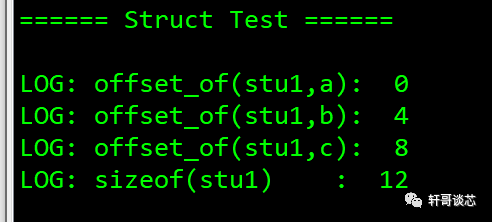
对于上面的运行结果,对字节对齐不了解的同学可能会疑惑,c的偏移量怎么会是8呢?不应该是 5 吗?
结构体的大小怎么会是12呢?不应该是 9 吗?
不了解的同学可能会这样理解:
c的偏移量是sizeof(int)+sizeof(char) = 5
结构体stu1占用的内存大小应该是sizeof(int)+sizeof(char)+sizeof(int)=9。
通过下图所示的stu1的内存结构可以知道,编译器对变量存储进行了一个特殊处理。

为了提高CPU的存储速度,编译器对一些变量的起始地址做了对齐处理。
在默认情况下,编译器规定各成员变量存放的起始地址相对于结构体的起始地址的偏移量,必须为该变量的类型所占用的字节数和编译器编译过程中采用的字节对齐数两者中最小值的整数倍。
有点绕,比如stu1 结构体中,变量 c 类型为 int,也就是占用 4 字节,编译器采用 4 字节对齐,因此偏移量必须是 4 的整数倍。
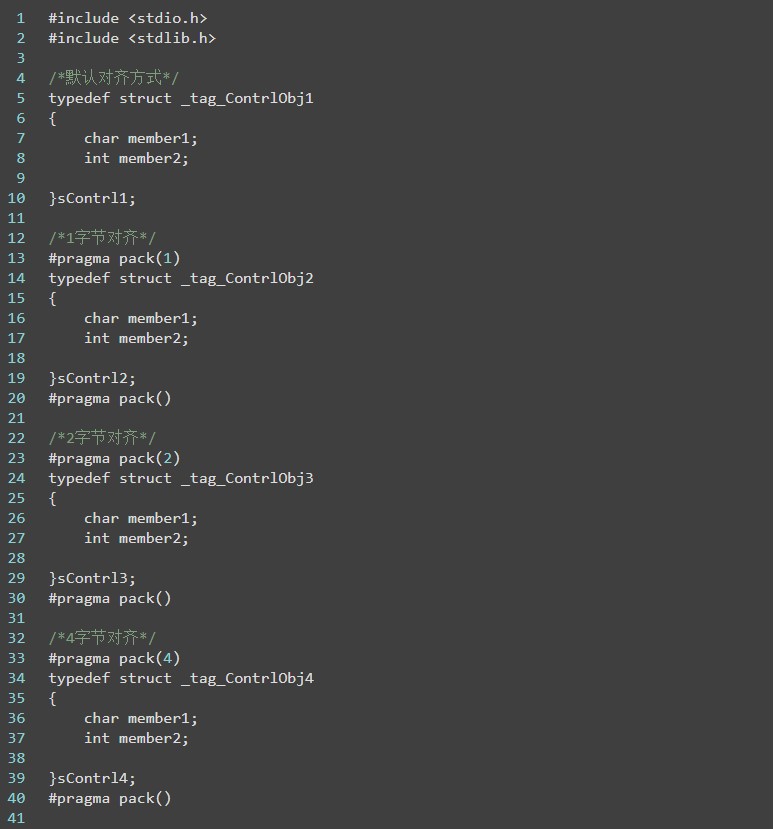
typedef structstu2{ int a; char b; char c int d;}stu2;再比上面的 stu2中,如对于变量 c,其类型为 char ,占用 1 字节,编译器采用 4 字节对齐,因此 它被分配的偏移量需要是 1 的整数倍,在上面的结构体 stu2 中,c 的偏移量为 5。
如图:

现在来分析前面的代码
假定a的起始地址为0,它占用了4字节,接下来的空闲地址就是4,是1的倍数,满足要求,所以b存放的起始地址是4,占用一个字节,接下来的空闲地址为5。c也是char变量,占用1字节, 因此可以放在地址 5 上面。
接下来看地址 6,对于 d,它占用了 4 个字节,同时需要注意的是,编译器默认按照结构体中占有内存最大的类型所占用的字节数进行字节对齐。在此结构体中占用内存最大的为整型,占用4字节,所以在此取两者的最小值4,6 并不是4的整数倍,所以向后移动,找到离6最近的8作为存放d的起始地址,d也占用4字节,最后结构体的大小为12。
需要注意的就是,变量b和 c后面2字节的存储空间是由编译器自动填充的,其中没有存储任何有用的信息。
-
ARM
+关注
关注
134文章
9084浏览量
367373 -
字节
+关注
关注
0文章
40浏览量
13726 -
代码
+关注
关注
30文章
4779浏览量
68518 -
结构体
+关注
关注
1文章
130浏览量
10840
发布评论请先 登录
相关推荐
C语言-结构体对齐详解
RM48HDK平台CCS结构体字节对齐总是咨询
CCS3.3 结构体成员对齐
请问在ccs4.2 中怎么设置结构体的字节对齐?
请问cc2640r2 ccs7.4结构体字节能实现对齐吗?


对结构体的对齐理解上有点偏差
结构体对齐为什么那么重要?

嵌套的结构体 字节是如何对齐的





 工商网监
工商网监
评论