 基于YOLOv5的视频计数 — 汽车计数实现
基于YOLOv5的视频计数 — 汽车计数实现
在视频中计数对象可能看起来有挑战性,但借助Python和OpenCV的强大功能,变得令人意外地易于实现。在本文中,我们将探讨如何使用YOLO(You Only Look Once)目标检测模型在视频流或文件中计数对象。我们将该过程分解为简单的步骤,使初学者能够轻松跟随。
本文将分为以下几个部分:
-
需求
-
启发式:汽车计数
-
检测过滤
-
启发式:实现
-
结论
需求
在我们深入了解该过程之前,让我们确保已安装所需的库。主要需要:
-
OpenCV:用于加载、操作和显示视频的所有实用程序。
-
Matplotlib(可选):我们将使用此实用程序在多边形内进行点验证。
如代码片段1所示,requirements.txt文件中列出了这些要求。
opencv-python==4.8.1.78
torch==2.1.0
matplotlib==3.8.0
ultralytics==8.0.203
pandas==2.1.2
requests==2.31.0
一旦我们查看了主要要求,就该了解我们将开发用于从视频中计数对象的启发式的时间了。
启发式:汽车计数
在此示例中,我们将使用一个视频场景,其中将对汽车进行计数。图2显示了一个示例帧。
 用于计数汽车的视频帧
用于计数汽车的视频帧
为了计数汽车,我们将使用Yolov5来检测视频中的对象。基于检测到的对象,我们将过滤与汽车、公共汽车和卡车有关的类别。由于检测基于边界框(具有坐标xmin、ymin、xmax、ymax的多边形),我们将需要获取每个边界框的中心点(xc, yc),该中心点将是我们对象的参考点。
最后,我们将绘制一个多边形,该多边形将是计数对象的参考,也就是说,如果对象的参考点在多边形内,我们将增加对象计数器,否则计数器不受影响。在下图中,我们可以看到多边形和多边形内的汽车数量的表示。
 检测(绿色点)、多边形(红色线)和计数器
检测(绿色点)、多边形(红色线)和计数器
到此为止,我们已经知道了需求是什么,以及我们将实施用于计数对象的启发式的方法。现在可以加载模型:Yolov5 Nano
在本例中,我们将使用Yolov5的nano版本(即yolov5n),我们将通过PyTorch Hub从Ultralytics存储库中扩展它。同样,为了加载和在每一帧上生成迭代器,我们将使用OpenCV(即cv2),下述代码是具体的实现方式:
import cv2
import torch
VIDEO_PATH="data/traffic.mp4"
HUB="ultralytics/yolov5"
YOLO="yolov5n"
def count_cars(cap: cv2.VideoCapture):
model = torch.hub.load(HUB, model=YOLO, pretrained=True)
while cap.isOpened():
status, frame = cap.read()
if not status:
break
# Detection filtering and heuristic
# will be implemented here.
cv2.imshow("frame", frame)
if cv2.waitKey(10) & 0xFF == ord('q'):
break
cap.release()
if __name__ == '__main__':
cap = cv2.VideoCapture(VIDEO_PATH)
count_cars(cap)
正如我们所看到的,我们已经定义了count_cars()函数,我们将在整个项目中对其进行更新。在4-6行,我们定义了视频所在路径、hub和模型名称的变量。从那里,让我们迅速跳到31-32行,在那里通过初始化cap对象加载视频,然后将其传递给count_cars()函数。
返回到第10行,通过PyTorch Hub,我们下载并初始化了yolov5n模型。随后,在第12行,我们生成一个迭代器,只要有要显示的帧,它就会保持活动状态。一旦帧完成,与迭代器相关的对象就会被释放(第26行)。
在第13行,我们读取帧,验证是否成功读取,并显示它们(第21行)。在这一部分,将出现一个窗口,用于查看从此迭代器显示的视频。最后,第23行是在按q键时删除弹出窗口。
检测过滤
过滤检测是指从Yolo预测中提取感兴趣的类别的过程。在这种情况下,我们将过滤掉分数大于0.5且类别为汽车、公共汽车或卡车的检测。同样,我们将需要找到边界框的中心点,我们将其用作对象的参考点。下面代码显示了这两个函数的实现。
import pandas as pd
def get_bboxes(preds: object):
df = preds.pandas().xyxy[0]
df = df[df["confidence"] >= 0.5]
df = df[df["name"].isin(["car", "bus", "truck"])]
return df[["xmin", "ymin", "xmax", "ymax"]].values.astype(int)
def get_center(bbox):
center = ((bbox[0] + bbox[2]) // 2, (bbox[1] + bbox[3]) // 2)
return center
正如我们所看到的,我们定义了两个函数get_bboxes()和get_center()。get_bboxes()函数(第3行)旨在提取所有分数大于0.5并过滤掉已经提到的类别的预测,返回一个坐标形式的边界框的numpy数组[xmin, ymin, xmax, ymax]。
get_center()函数(第10行)接收一个带有边界框坐标的numpy数组,并使用方程xc, yc = (xmin + xmax) // 2, (ymin + ymax) // 2分别计算中心点。
在这一点上,我们已经下载了模型,过滤了预测,并获得了每个对象的中心点。现在,我们唯一需要的是生成决定启发式区域的多边形。因此,让我们继续下一节!
启发式:实现
我们将定义的多边形可能会因视频、透视等而有所不同。在这种情况下,例如此示例,我们将使用8个点,如下图所示:
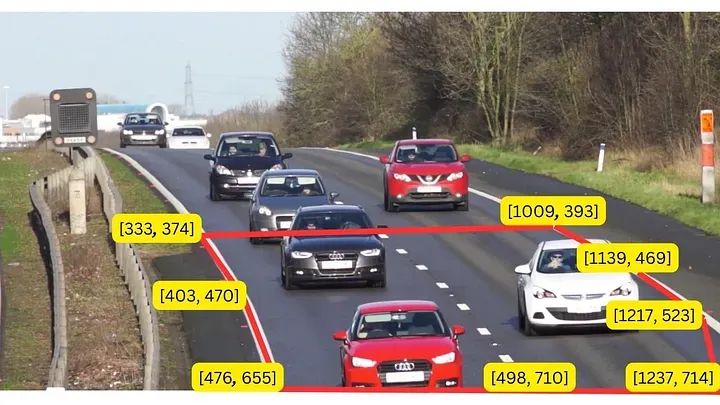 具有坐标的多边形
具有坐标的多边形
一旦我们定义了多边形,我们唯一需要做的就是验证每个对象的参考点是否在多边形内。如果在多边形内,我们就会增加一个计数器,如果不在,我们就继续。
import cv2
import numpy as np
import matplotlib.path as mplPath
POLYGON = np.array([
[333, 374],
[403, 470],
[476, 655],
[498, 710],
[1237, 714],
[1217, 523],
[1139, 469],
[1009, 393],
])
def is_valid_detection(xc, yc):
return mplPath.Path(POLYGON).contains_point((xc, yc))
def count_cars(cap: object):
model = torch.hub.load(HUB, model=YOLO, pretrained=True)
while cap.isOpened():
status, frame = cap.read()
if not status:
break
preds = model(frame)
bboxes = get_bboxes(preds)
detections = 0
for box in bboxes:
xc, yc = get_center(box)
if is_valid_detection(xc, yc):
detections += 1
让我们注意到在第5行,我们定义了多边形。在第17行,我们定义了关键函数:is_valid_detection(),它旨在验证参考点(xc, yc)是否在多边形内。这个函数在第37行调用,如果为真,它会增加有效检测计数器,否则什么也不做。
最后,为了可视化,我们将添加一些OpenCV行来显示计数器、每辆检测到的汽车的参考点和多边形。
def count_cars(cap: object):
model = torch.hub.load(HUB, model=YOLO, pretrained=True)
while cap.isOpened():
status, frame = cap.read()
if not status:
break
preds = model(frame)
bboxes = get_bboxes(preds)
detections = 0
for box in bboxes:
xc, yc = get_center(box)
if is_valid_detection(xc, yc):
detections += 1
# Draw poit of reference for each detection
cv2.circle(img=frame, center=(xc, yc), radius=5, color=(0,255,0), thickness=-1)
# Draw bounding boxes for each detection
cv2.rectangle(img=frame, pt1=(box[0], box[1]), pt2=(box[2], box[3]), color=(255, 0, 0), thickness=1)
# Draw the counter
cv2.putText(img=frame, text=f"Cars: {detections}", org=(100, 100), fontFace=cv2.FONT_HERSHEY_PLAIN, fontScale=3, color=(0,0,0), thickness=3)
# Draw the polygon
cv2.polylines(img=frame, pts=[POLYGON], isClosed=True, color=(0,0,255), thickness=4)
# Display frame
cv2.imshow("frame", frame)
结论
在本文中,我们看到了如何从视频中实现一个对象计数器。我们开发了一种计算汽车、卡车和公共汽车的实现,基于一个定义的多边形,即如果对象在多边形内,计数器就会增加。
-
计数器
+关注
关注
32文章
2256浏览量
94476 -
模型
+关注
关注
1文章
3226浏览量
48806 -
目标检测
+关注
关注
0文章
209浏览量
15605
原文标题:基于YOLOv5的视频计数 — 汽车计数实现
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【YOLOv5】LabVIEW+YOLOv5快速实现实时物体识别(Object Detection)含源码
Yolov5算法解读

【YOLOv5】LabVIEW+TensorRT的yolov5部署实战(含源码)
在RK3568教学实验箱上实现基于YOLOV5的算法物体识别案例详解
龙哥手把手教你学视觉-深度学习YOLOV5篇
怎样使用PyTorch Hub去加载YOLOv5模型
如何YOLOv5测试代码?
yolov5模型onnx转bmodel无法识别出结果如何解决?
YOLOv5在OpenCV上的推理程序
在C++中使用OpenVINO工具包部署YOLOv5模型
使用旭日X3派的BPU部署Yolov5

yolov5和YOLOX正负样本分配策略

YOLOv5网络结构训练策略详解
RK3588 技术分享 | 在Android系统中使用NPU实现Yolov5分类检测-迅为电子






 工商网监
工商网监
评论