 Ambarella展示了在其CV3-AD芯片上运行LLM的能力
Ambarella展示了在其CV3-AD芯片上运行LLM的能力
Ambarella前不久展示了在其CV3-AD芯片上运行LLM的能力。这款芯片是CV3系列中最强大的,专为自动驾驶设计。
CV3-AD一年前开始出样,使用Ambarella现有的AI软件堆栈,运行Llama2-13B模型时,可以实现每秒推理25个token。
Ambarella的CEO Fermi Wang表示:“当transformer在今年早些时候变得流行时,我们开始问自己,我们拥有一个强大的推理引擎,我们能做到吗?我们进行了一些快速研究,发现我们确实可以。我们估计我们的性能可能接近Nvidia A100。”
Ambarella工程师正在展示Llama2-13B在CV3-AD上的实时演示,CV3-AD是一款50W的自动驾驶芯片。
Ambarella芯片上的CVFlow引擎包括其NVP(Neural Vector Processor)和一个GVP(General Vector Processor),演示中的LLM正在NVP上运行。NVP采用数据流架构,Ambarella已将诸如卷积之类的高级运算符指令组合成图表,描述数据如何通过处理器进行该运算符的处理。所有这些运算符之间的通信都使用片上内存完成。CV3系列使用LPDDR5(而非HBM),功耗约为50W。
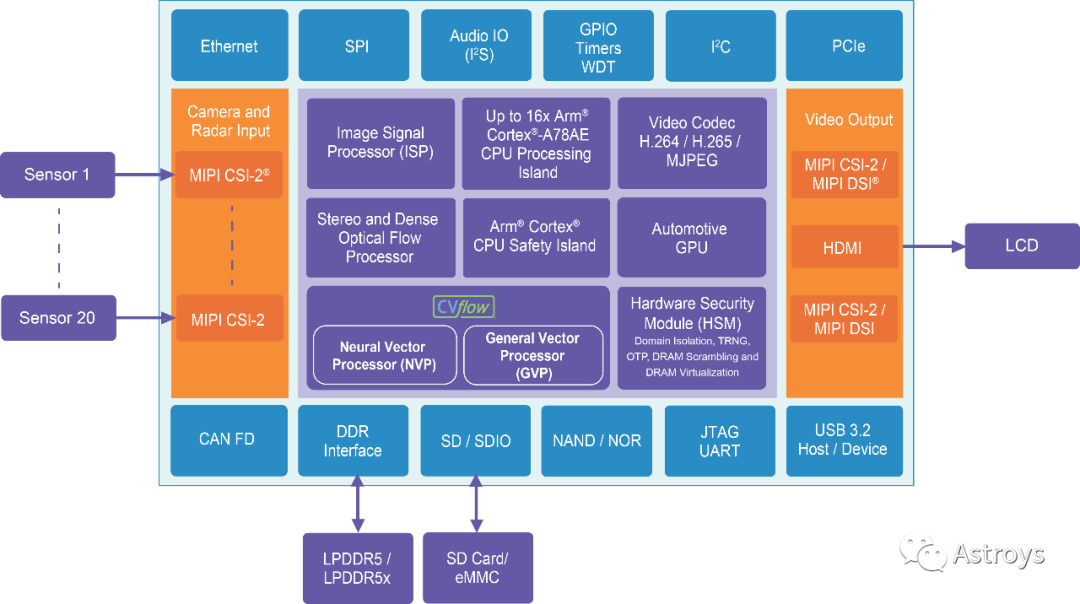
Ambarella的CTO Les Kohn表示,LLM演示确实需要一些新软件。实现transformer架构核心操作的构建模块,目前这些操作针对的是像Llama2这样的模型。
他说:“随着时间的推移,我们将扩展这些功能以覆盖其它模型,但Llama2正在成为开源世界的事实标准。这绝对是一项不小的投资,但与从头开始开发软件相比,还差得远。”
Edge LLM发展路线图
Wang表示:“现在我们知道我们拥有这项技术,我们可以解决一些实际问题。如果你与LLM的研发人员交谈,问他们最头疼的是什么,一个显然是价格,另一个是功耗。”
CV3-AD设计用于50W的功率范围(包括整个芯片的功率,不仅仅是AI加速器)。因此,Wang希望Ambarella能够以大约四分之一的功耗,为LLM提供与A100相似的性能。
他说:“这意味着对于固定的数据中心功率,我可以增加四倍的AI性能。这是巨大的价值。尽管这种想法很简单,但我们相信我们可以为渴望使用LLM的任何人提供价值。在过去的六个月里,渴望使用LLM的人数迅速增加。”
虽然超大规模计算中心可能是首批跟进LLM趋势的,但Ambarella在安防摄像头和汽车领域的现有客户开始考虑如何在他们的边缘系统中实施LLM,以及LLM将如何实施他们的发展路线图。
Wang说:“我们相信LLM将成为我们需要在路线图中为当前客户提供的重要技术。当前的CV3可以运行LLM,而无需Ambarella进行太多额外的工程投资,所以这对我们来说并非分心之事。我们当前的市场在他们的路线图中已经有了LLM。” 多模态AI Kohn指出,在边缘计算中,具有生成文本和图像能力的大型多模态生成型AI潜力日益增大。
他说:“对于像机器人这样的应用,transformer网络已经可以用于计算机视觉处理,这比任何传统计算机视觉模型都要强大,因为这种模型可以处理零样本学习,这是小模型无法做到的。”
零样本学习指的是模型能够推断出在其训练数据中未出现的对象类别的信息。这意味着模型可以以更强大的方式预测和处理边缘情况,这在自动系统中尤其重要。
他补充说:“自动驾驶本质上是一种机器人应用:如果你看看L4/L5系统需要什么,很明显你需要更强大、更通用的AI模型,这些模型能以更类似于人类的方式理解世界,超越我们今天的水平。我们将这看作是为各种边缘应用获取更强大的AI处理能力的一种方式。”
LLM发展路线图
问及Ambarella是否会制造专门针对LLM的边缘芯片时,Wang表示:“这可能是我们需要考虑的事情。我们需要一个具有更多AI性能的LLM路线图。LLM本身需要大量的DRAM带宽,这几乎使得在芯片上集成其他功能变得不可能(因为其他功能也需要DRAM带宽)。”
Wang说,尽管在某些人看来,一个大型信息娱乐芯片应该能够同时处理其他工作负载和LLM,但目前这是不可能的。LLM所需的性能和带宽或多或少地需要一个单独的加速器。
Kohn补充说:“这取决于模型的大小。我们可能会看到目前使用的模型比较小的版本应用于像机器人学这样的领域,因为它们不需要处理大型模型所做的所有通用事务。但与此同时,人们希望有更强大的性能。所以,我认为最终我们将看到未来更优化的解决方案,它们将被应用于不同的价格/性能点。”
在边缘计算之外,CV3系列也有可能在数据中心中使用。Kohn说,CV3系列有多个PCIe接口,这在多芯片系统中可能很有用。他还补充说,该公司已经有一个可以利用的PCIe卡。
Wang表示:“对我们来说,真正的问题是,‘我们能否将当前产品和未来产品销售到超大规模计算中心或基于云的解决方案中?’这是一个我们还没有回答的问题,但我们已经确认了技术的可行性,并且我们有一些差异化。我们知道我们可以将这种产品销售到边缘设备和边缘服务器。我们正在制定一个计划,希望如果我们想要进入基于云的解决方案,我们可以证明进一步投资是合理的。”
审核编辑:刘清
-
处理器
+关注
关注
68文章
19259浏览量
229651 -
机器人
+关注
关注
211文章
28379浏览量
206914 -
LPDDR5
+关注
关注
2文章
89浏览量
12062 -
自动驾驶芯片
+关注
关注
3文章
47浏览量
5088 -
LLM
+关注
关注
0文章
286浏览量
327
原文标题:Ambarella展示在自动驾驶芯片上的LLM推理能力
文章出处:【微信号:Astroys,微信公众号:Astroys】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Arm KleidiAI助力提升PyTorch上LLM推理性能
树莓派跑LLM难上手?也许你可以试试Intel哪吒开发板
如何在 OrangePi 5 Pro 的 NPU 上运行 LLM

NVIDIA TensorRT-LLM Roadmap现已在GitHub上公开发布

什么是LLM?LLM在自然语言处理中的应用
LLM预训练的基本概念、基本原理和主要优势
大模型LLM与ChatGPT的技术原理
LLM模型的应用领域
什么是LLM?LLM的工作原理和结构
Meta发布基于Code Llama的LLM编译器
【算能RADXA微服务器试用体验】+ GPT语音与视觉交互:1,LLM部署
100%在树莓派上执行的LLM项目

超级芯片:云时代的潜在颠覆者
CV3域控芯片家族又添两员!各档规格完整覆盖,软件功能全面兼容





 工商网监
工商网监
评论