 盘点GPU Fabric典型拓扑结构
盘点GPU Fabric典型拓扑结构
当前,许多超大规模厂商正在竞相构建大型 GPU 集群,以适应GenAI训练工作负载。本文探讨了针对GenAI训练工作负载进行优化的各种网络拓扑结构,如Meta的Rail-Only 拓扑和Dragonfly拓扑,以及网络中可能存在的一些拥塞点和各种拥塞控制解决方案。
01GPU Fabric拓扑
有两种构建 GPU 拓扑的方法:
# Fat-tree CLOS 具有非阻塞的any-to-any连接,不依赖于正在训练的模型。
这是公有云提供商的首选方案,其 GPU 集群可用于训练各种模型,包括具有大型嵌入表的推荐模型,这些嵌入表可跨所有 GPU 上创建 all-to-all 通信。然而,为成千上万的 GPU 提供非阻塞连接是非常昂贵的,与扁平的spine/leaf拓扑相比,它需要更多交换机和更多的跳数。这些拓扑更有可能出现拥塞和长尾延迟。
# 针对特定训练工作负载优化的拓扑。
这种方法在为 LLM 训练工作负载构建专用 GPU 集群的超大规模厂商中很流行。优化拓扑使集群高效且可持续。例如谷歌使用的3D torus和optical spine交换机,以及 Meta 使用的rail-optimized leaf交换机。一些 HPC 架构还使用dragonfly拓扑来优化 GPU 之间的跳数。
Meta:Rail-Only 拓扑
Meta的一篇论文(《Meta和MIT最新网络架构研究,对传统架构提出挑战》)分析了大型 GPU 集群中的流量模式。他们将GPU 分组为高带宽 (HB) 域集群,每个集群有 256 个 GPU。256 个 GPU 是GH200超级计算机的一部分,其中所有GPU 都通过NVSwitch层次架构连接。HB 域通过rail-optimized交换机连接。从GPT-3/OPT-175B 模型的流量模式分析可得出以下结论:
整个集群99%的GPU对不承载任何流量;
论文中的热图反映了观察结果。该论文提出,具有rail -only交换机的拓扑可以与非阻塞 CLOS 拓扑一样执行。在rail -only交换机中,所有 M 个 HB 域中的第 N 个 GPU 通过 400Gbps 链路连接到 M x400G rail交换机。
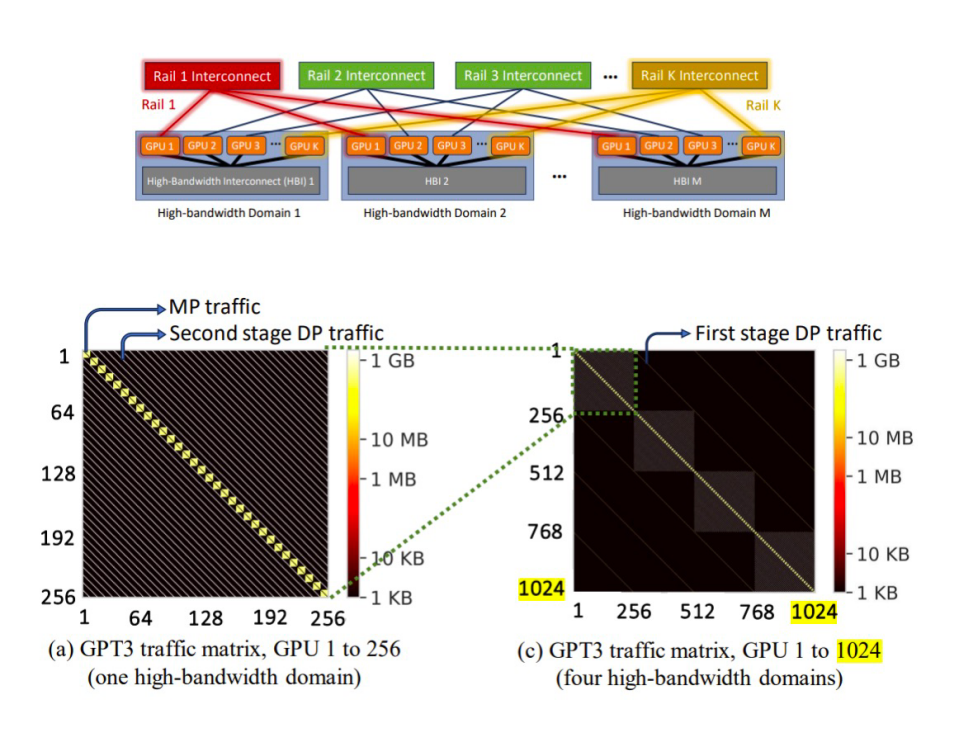
| 训练 GPT-3 模型时 GPU 对之间的流量模式
在下面的拓扑中,当 GPU 需要将数据移动到不同rail中的另一台服务器GPU 时,它会首先使用 NVlink 将数据移动到与目标 GPU 属于同一rail的服务器内 GPU 内存中。之后,数据可以通过rail交换机传送到目的地。这可以实现消息聚合和网络流量优化。
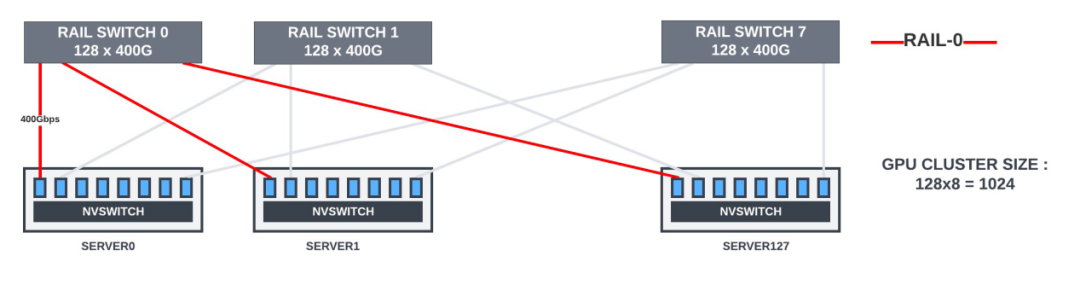
| 具有rail-only交换机的 1024 个 GPU 集群的拓扑
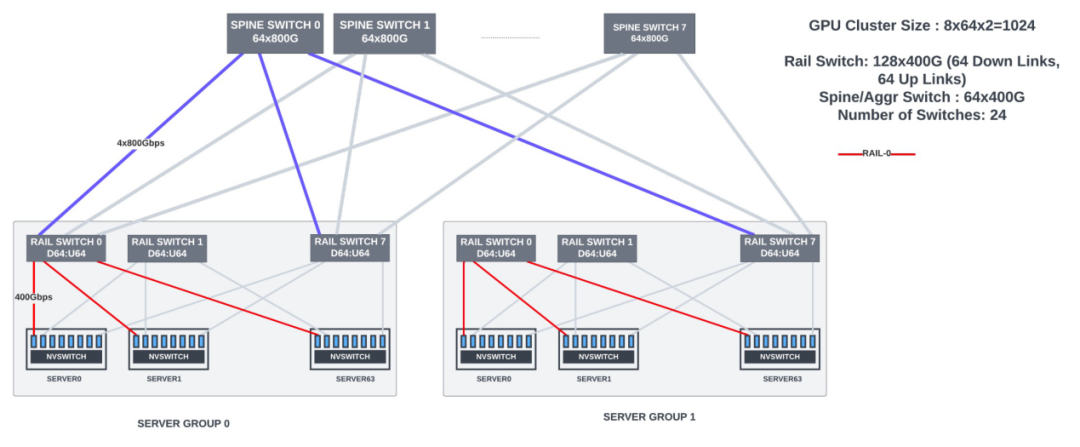
| 具有rail 和spine交换机的 1024 个 GPU 集群的 CLOS 拓扑
rail-optimized连接适用于大多数 LLM/Transformer模型。对于大于1024个 GPU的集群,需要使用spine交换机来实现 GPU 间的数据并行通信。
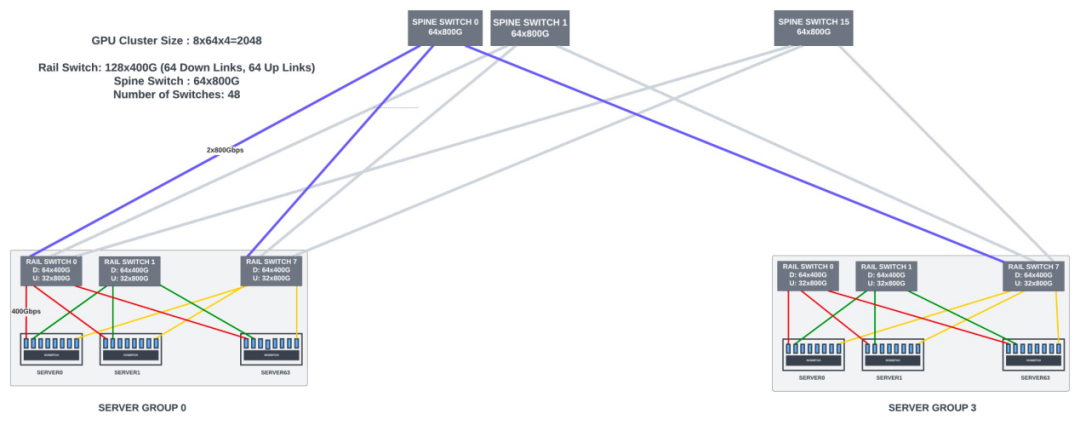
| 具有 Rail-Spine 交换机的 2048 GPU 集群
Dragonfly拓扑
Dragonfly是由John Kim等人在2008年的论文Technology-Driven, Highly-Scalable Dragonfly Topology中提出,它的特点是网络直径小、成本较低,早期主要用于HPC集群。在这种拓扑结构中,Pod 或交换机组连接到服务器,这些 Pod 还通过高带宽链路直接相互连接。Dragonfly比传统的leaf-spine拓扑需要的交换机更少,但当部署用于以太网/IP通信时,它也面临着一定的挑战。
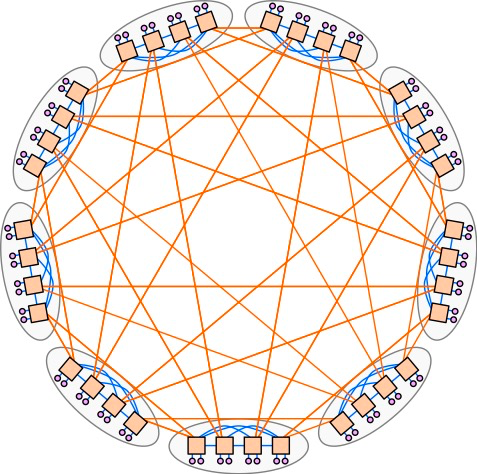
| Dragonfly 拓扑示例
Dragonfly网络在扩展性方面存在问题,每次需要增加网络容量时,都必须对Dragonfly网络进行重新布线,这增加了网络的复杂性和管理难度。
在 Hot Interconnects 2023 上,Bill Dally 博士提出了一种拓扑,其中组和组之间可以直接连接到光电路交换机(OCS)。这样,就算添加额外的组、更改直接链路,也不会对连接性造成太多的干扰。通过引入OCS技术,可以实现布线自动化,从而有效解决了扩展过程中重新布线的难题,提高了网络的可管理性和灵活性。
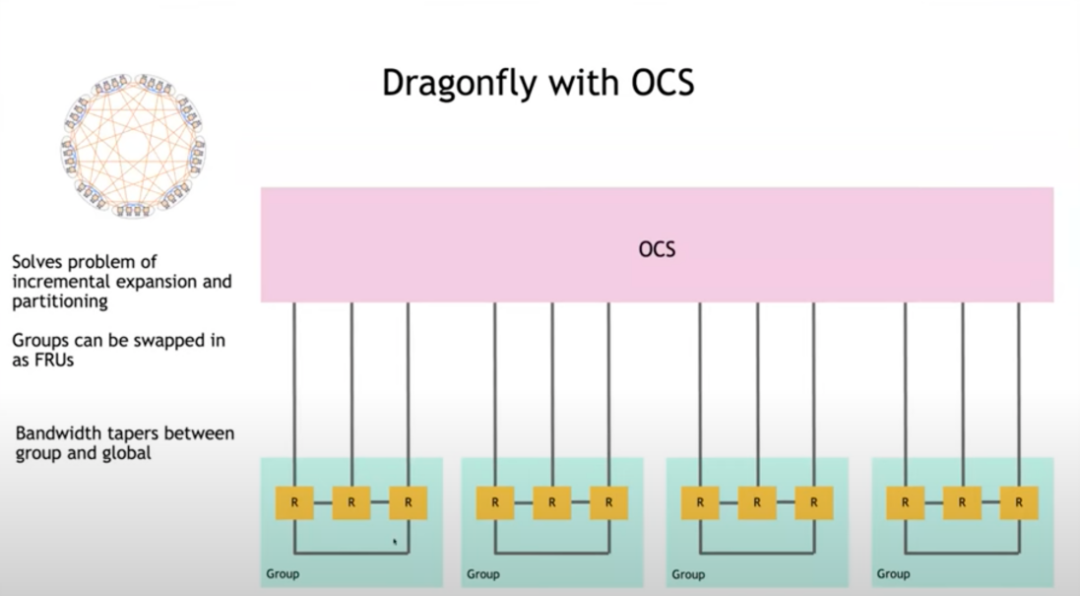
02Fabric拥塞
无损传输对于优化训练性能至关重要。任何网络丢失都会触发 RoCE 中使用标准NIC的 go-back-N 重传,这会浪费带宽并导致长尾延迟。
虽然可以在所有链路上启用链路级PFC,但如果分配的缓冲区在队列之间进行共享,那么扩展的PFC可能会造成排队阻塞、浪费缓冲区空间、死锁、PFC风暴等。PFC 应作为防止流量丢失的最后手段。
我们先看看网络中的拥塞点:
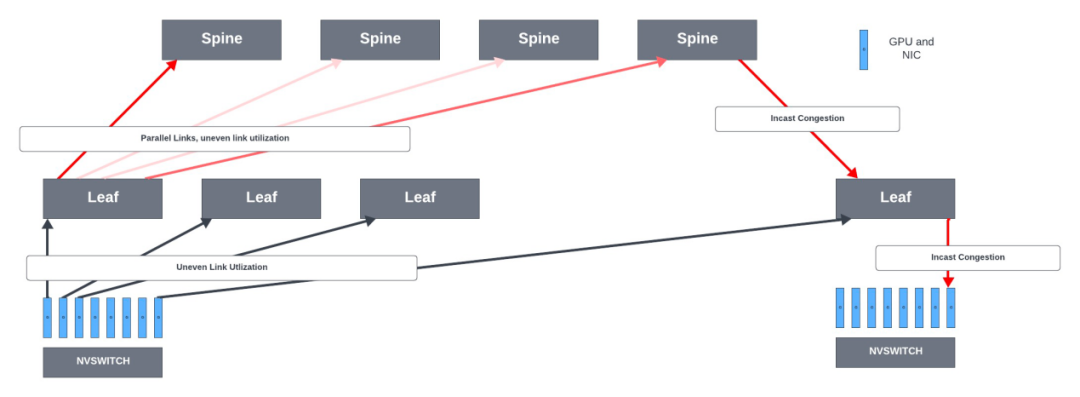
| 网络拥塞点
NIC -> Leaf Links
在rail-optimized的leaf 交换机中,对于服务器间流量,NCCL/PXN 利用节点内的 NVSwitch 将数据移动到与目标位于同一rail上的 GPU,然后在不跨越rail的情况下将数据发送到目标GPU,从而实现NIC到leaf的流量优化。
虽然每个 GPU 可以向其rail交换机发送 400Gbps 的数据,但并非所有 GPU 到leaf交换机的链路都是完全饱和的,在服务器到leaf链路之间会产生不均匀的带宽分配。因此,一些超大规模企业不喜欢rail-optimized的leaf交换机,他们更喜欢在从服务器到leaf交换机的所有可用链路上对 GPU 流量进行负载平衡。
Leaf -> Spine Links
在rail-optimized网络中,leaf-spine主要是数据并行流量,这些流具有较高的带宽并且持续时间较长。例如,每个H100 GPU 具有 80GB 内存,梯度可能会占用该内存的 1/10 (约8GB)。当 GPU 使用单个 QP(流)通过 400Gbps 上行链路发送 8GB 数据时,会产生大于160ms 的流量,需要由rail交换机处理。
当可以通过这些路径到达目的地时,ECMP 会在leaf和spine链路之间的可用并行等价路径上分发数据包。ECMP 旨在分散网络流量以提高链路利用率并防止拥塞。交换机使用哈希函数来决定发送数据包的路径。然而,当系统熵值非常低时,哈希可能会导致并行链路利用率不均匀以及某些链路严重拥塞的冲突。某些流量模式在使用 ECMP 负载均衡时,链路利用率可能低于 50%。
Spine -> Leaf Links
Spine到Leaf的拥塞可能在以下情况时发生:
spine交换机和每个leaf 交换机之间可能存在多个并行链路,用于负载均衡链路间流量的 ECMP 可能会造成链路利用率不均匀。
In-cast流量。Incast 是一种流量模式,其中许多流汇聚到交换机的同一输出口上,耗尽该接口的缓冲区空间并导致数据包丢失。当 GPU 集群中并行运行多个训练任务时,也可能会发生这种情况。
Leaf -> NIC links
它们承载高带宽流水线并行和数据并行流量。
流水线并行流量负载在很大程度上取决于模型架构和分区。它具有高带宽和突发性,GPU 之间具有微秒突发性。这两种流量模式结合在一起可能导致链路发生incast情况。
03拥塞控制解决方案
下面列出的各种技术可用于缓解 GPU fabric中的拥塞,最终的部署取决于支持这些协议的网卡/交换机以及GPU集群的规模。
提高链路利用率:如果任意两台交换机或交换机/网卡之间的所有并行路径都可以到达目的地,则将流量均匀分布在这些路径上。动态/自适应负载均衡和数据包喷洒(packet spraying)就属于这一类。更多到达目的地的路径将有助于减少网络交换机中的队列堆积。
发送端驱动的拥塞控制算法 (CCA) 依赖于 ECN 或来自交换机的实时遥测。根据遥测数据,发送端将调节发送给fabric的流量。
接收端驱动的拥塞控制:接收端向发送端分配用于传输数据包的Credit。
Scheduled fabric。
可以更好地处理拥塞的新传输协议。
动态/自适应负载均衡
当目的地可以使用并行链路到达时,以太网交换机中的动态/自适应负载均衡会动态地将流量从拥塞链路转移到空闲链路。为了不对流内的数据包重新排序,大多数实现都会寻找流中的间隔(gap)来进行负载均衡。如果gap足够大,就表示这个gap之前的数据包已经传输了很远,不用担心通过空闲链路发送的数据包会比之前的数据包提前到达目的地。
动态负载均衡的一种极端形式是packet-level spraying。
packet spraying
另一种流行的方法是packet spraying。Fabric中的每个交换机均匀地在所有可用(且不拥塞)的并行链路上进行packet spraying,可以将并行链路利用率提高到90%以上。当一个流 (QP) 的数据包被spray时,它们会采用不同的路径通过fabric,经历不同的拥塞延迟,并且可能会无序地到达目标 GPU。
NIC 应具有处理无序 RDMA 事务的逻辑/硬件。Nvidia 的 ConnectX NIC可以处理无序 (OOO) RDMA 操作。然而,它们在不损失性能的情况下支持的重新排序量是有限的。Nvidia 对此功能提供有限的现场支持,尚不清楚其最新版本的NIC是否正式支持数据包重新排序。
云提供商的另一种选择是使用支持 RDMA 操作重新排序的硬件来构建自己的网卡,并在客户构建的 GPU 服务器中使用它们。在构建自定义NIC时,使用 Nvidia 的 Bluefield DPU 也是一种选择。Bluefield支持无序RDMA操作,(很可能)将它们存储在本地内存中,然后在重新排序事务时将数据包写入GPU内存。然而,与标准NIC中的简单 ASIC/FPGA 相比,DPU更加昂贵且耗电。除了数据包排序之外,它们还有许多 AI/ML 训练工作负载并不需要的功能。如果 Bluefield 确实使用本地内存进行重新排序,则会增加事务的额外延迟,并浪费 NIC 中用于存储数据包的内存资源,而数据包在重新排序时可以存储在 GPU 内存中。
亚马逊/微软的自定义NIC支持数据包重新排序。其他交换机供应商也可能正在构建可以支持数据包重新排序的智能网卡(或网卡中使用的 ASIC)。
Scheduled Fabric
为了顺利工作,Scheduled Fabric在每个端点leaf交换机中都需要大量入口缓冲/状态,以便对发往集群中的所有端点 GPU 的数据包进行排队,它还需要在这些端点交换机上为所有无损队列提供大的出口缓冲区。
在传输数据包之前,有一个额外的 RTT 延迟(用于端点交换机之间的请求-授予握手)。此外,该方案目前还没有明确的标准,每个供应商都有自己的专有协议,控制平面管理非常复杂,尤其是当某些链路/交换机发生故障并需要增加额外容量时,这需要客户对每个供应商的产品有深入的了解。供应商锁定的风险很高。
EQDS
边缘排队数据报服务(EQDS,Edge-Queued Datagram Service)是一种为数据中心提供的新数据报服务,它将几乎所有队列从核心网络转移到发送主机。这使得它能够支持多个(冲突的)高层协议,同时只根据任何接收端驱动的信用/credit方案向网络发送数据包。这意味着发送端只有在从接收端收到Credit时才能发送数据包,而接收端只有在有足够的缓冲区空间时才授予Credit,并计量授予不超过接收端的访问链路速度。这样,网络交换机可以使用非常小的缓冲区运行,并最大限度地减少拥塞/数据包丢失。
EQDS 使用packet spraying来均衡网络核心中的负载,避免流冲突,并提高吞吐量。此外,这个协议的优点是它没有引入另一个传输层协议,它通过动态隧道向现有传输层提供数据报服务。
EQDS 可以在端点 NIC 的软件中实现。但是,对于高带宽服务器,应该在 NIC 硬件中实现。Broadcom 收购了发布此协议的公司,并且可能正在构建具有此功能的 NIC 硬件。
DCQCN
对于 RoCEv2 RDMA 流量,需要更快的拥塞响应,而无需通过主机软件。2015 年由 微软和 Mellanox 提出的DCQCN拥塞控制算法,通常在网卡中实现。当交换机检测到拥塞时, 将出口包打上ECN标记, 接收端收到ECN包后, 因为有发送端的QP信息, 发送拥塞通知包CNP给发送端, 这时候假如发送端收到多个接收端发来的ECN包, 发送方会使用DCQCN来降速和调度发送。一段时间发送端没有收到CNP时, 这个时候需要恢复流量。
为了使该算法发挥作用,交换机不应在 ECN 标记之前发送 PFC,PFC 是在极端拥塞情况下防止数据包丢失的最后手段。
阿里HPCC/HPCC++
虽然 ECN 指示网络中存在拥塞,但指示的粒度非常粗,只有一种状态可以指示数据包是否在fabric中的某台交换机中遇到拥塞。当发送端开始降低速率时,拥塞/队列堆积已经发生,这会增加网络的延迟,并且拥塞控制算法(如 DCQCN)必须迅速采取行动以避免触发 PFC。另外,依赖ECN的方案很难计算出发送速率要降低多少。
阿里在2019年的SIGCOMM上提出了HPCC(高精度拥塞控制),试图解决以上问题,其背后的关键思想是利用来自INT的精确链路负载信息来计算准确的流量更新。数据包从发送端传播到接收端的过程中,路径上的每个交换机都会利用其交换 ASIC 的 INT(带内遥测) 功能插入一些元数据,报告数据包出端口的当前负载,包括时间戳 (ts)、队列长度 (qLen)、传输字节 (txBytes) 和链路带宽容量 (B)。当接收方收到数据包时,会将交换机记录的所有元数据通过ACK发送给发送端。然后发送端根据带有网络负载信息的 ACK 决定如何调整其流量。
HPCC 通过利用交换机的遥测信息,可以实现更快的收敛、更小的fabric队列以及发送端的公平性。HPCC++ 对 HPCC 拥塞控制算法添加了额外的增强功能,以加快收敛速度。
谷歌CSIG
CSIG是交换机向端点设备发送拥塞信号的另一种方式,谷歌在 OCP 2023 中开源了该协议。CSIG旨在以更少的数据包开销实现与 HPCC/HPCC++ 类似的目标。CSIG 的一些显着特征如下:
CSIG使用固定长度的报头来承载信号,而 INT 使用随跳数增长的可变长度报头,这使其在带宽和开销方面更加高效。
CSIG 比 INT 更具可扩展性,因为它使用比较和替换机制从路径上的瓶颈设备收集信号,而 INT 使用逐跳追加机制,要求每个设备插入自己的信息。
CSIG 标签在结构上与 VLAN 标签相似,这使得网络能够重新利用现有的 VLAN 重写逻辑来支持 CSIG 标签。这可以简化网络内隧道和加密的实现和兼容性。
现有的 CCA 可以使用 CSIG 信息来调整流量,以便更准确地控制网络和incast拥塞。
亚马逊SRD
亚马逊开发了一种名为SRD (可扩展可靠数据报) 的新传输协议来解决 RoCEv2 的局限性。SRD 不保留数据包顺序,而是通过尽可能多的网络路径发送数据包,同时避免路径过载。SRD 的创新在于有意通过多个路径分别发包,虽然包到达后通常是乱序的,但AWS实现了在接收处以极快的速度进行重新排序,最终在充分利用网络吞吐能力的基础上,极大地降低了传输延迟。
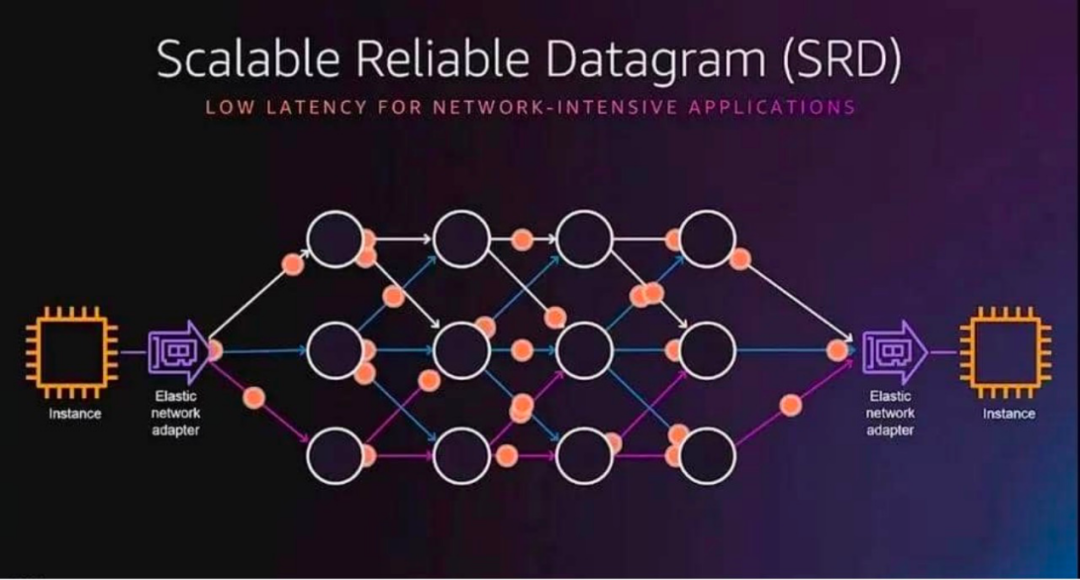
SRD 集成在亚马逊的 Elastic Fabric Adapter (EFA) 中,并与商用以太网交换机配合使用。它使用标准 ECMP 进行多路径负载平衡。发送方通过操作数据包封装来控制 ECMP 路径选择。发送方知道每个多路径中的拥塞情况(通过为每个路径收集的 RTT),并且可以调节通过每个路径发送的数量。SRD 根据传入确认数据包的时序和 RTT 变化所指示的速率估计来调整其每个连接的传输速率。
谷歌Falcon
在 2023 年 OCP 全球峰会上,谷歌开放了其硬件辅助传输层 Falcon。Falcon 的构建原理与 SRD 相同,通过多路径连接、处理网卡中的无序数据包、选择性重传以及更快更好的基于延迟的拥塞控制 (swift) 来实现低延迟和高带宽的可靠传输。网络交换机不需要任何修改来支持该传输层。
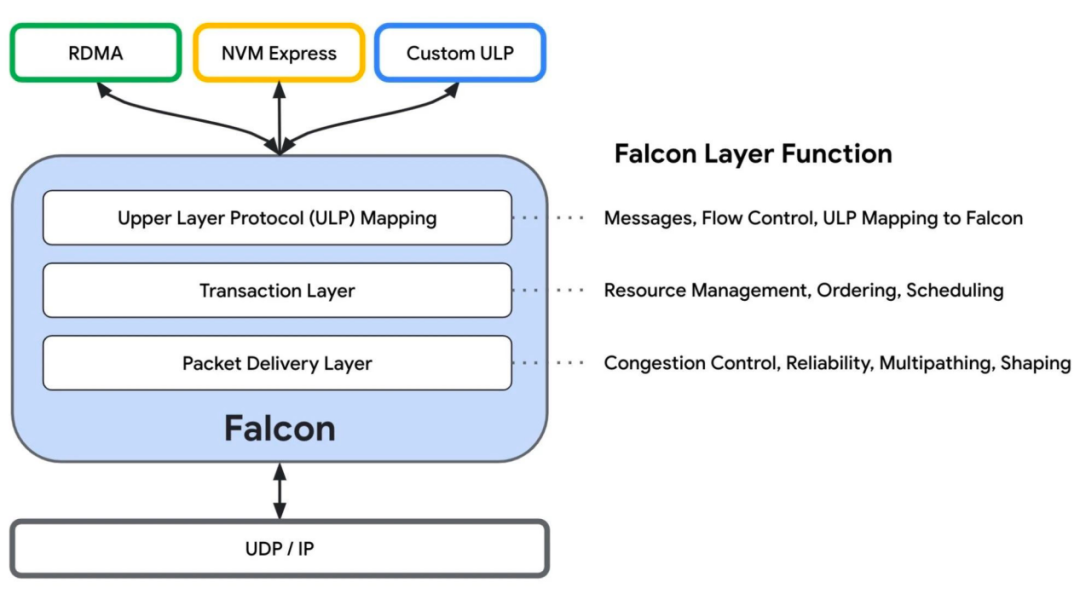
新协议
2023年7月成立的超以太网联盟(UEC)的目标之一是优化链路级和端到端网络传输协议或创建新协议,以使以太网fabric能够更好地处理大型 AI/ML 集群。然而,由于UEC 联盟的创始成员都已在其交换机/网卡和主机堆栈中适应了不同的专有解决方案,因此尚不清楚他们将以多快的速度实现这些目标。
即使提出了一个新协议,也不清楚具有定制解决方案的超大规模厂商是否会立即适应新标准。与 RDMA/RoCE 一样,任何新的传输协议都需要经历多代才能获得可靠的实现。与此同时,商业交换机供应商必须继续关注行业发展方向,并为终端拥塞控制提供更好的遥测和拥塞信号选择。
04总 结
本文详细叙述了 genAI/LLM 模型的 GPU 流量模式,以及如何针对这些流量模式优化网络拓扑。当前,该行业正处于为大型 GPU 集群部署以太网fabric的早期阶段。如果packet spraying和端到端拥塞控制在 AI/ML/HPC 集群中使用的大型 IB 网络表现依然出色,那么以太网fabric将受益于相同的功能。然而,在超大规模厂商确定适合自己的方案,并发布其协议(通过 UEC 或独立)以供网卡/交换机适应之前,拓扑和拥塞管理功能还需要一些试验和调整。总的来说,以太网fabric和交换机供应商的前途非常光明!
审核编辑:汤梓红
-
负载
+关注
关注
2文章
564浏览量
34326 -
gpu
+关注
关注
28文章
4729浏览量
128890 -
拓扑结构
+关注
关注
6文章
323浏览量
39189 -
模型
+关注
关注
1文章
3226浏览量
48807
原文标题:盘点GPU Fabric典型拓扑结构及拥塞控制技术
文章出处:【微信号:SDNLAB,微信公众号:SDNLAB】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
典型的电磁炉拓扑结构及应用分析

不同的充电拓扑结构介绍
合适的CAN总线拓扑结构如何选择?
基于拓扑结构的升压Boost
什么是Fabric, Switched交换结构
什么是电路拓扑结构_多种pfc电路的拓扑结构介绍
AMD Infinity Fabric升级后可支持CPU-GPU之间的连接
AMD Infinity Fabric总线升级,最多支持8个GPU芯片的连接
典型的线性音频放大器拓扑结构
拓扑视图与实际拓扑结构间的差异





 工商网监
工商网监
评论