 语音识别技术最新进展:视听融合的多模态交互成为主要演进方向
语音识别技术最新进展:视听融合的多模态交互成为主要演进方向
电子发烧友网报道(文/李弯弯)所谓“模态”,英文是modality,用通俗的话说,就是“感官”,多模态即将多种感官融合。多模态交互技术是近年来人工智能领域的一项重要创新。随着语音识别技术的发展,采用多种模态(声学、语言模型、视觉特征等)进行联合建模,基于深度学习的多模态语音识别取得了新进展。
多模态交互的原理及优势
多模态交互技术融合了多种输入方式,包括语音、手势、触摸和眼动等,使用户可以根据自己的喜好和习惯选择最方便的交互方式。多模态交互通过将不同输入方式的数据进行融合和处理,实现更准确、智能的交互响应,提高用户体验。
上周在星宸科技2023开发者大会暨产品发布会论坛上,科大讯飞企业数字化副总裁卢尧谈到,人工智能有三个层次,1、运算智能:能存会算;2、感知智能:能听会说,能看会认;3、认知智能:能理解会思考。而感知智能典型的进展是多模态交互。
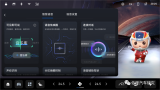
从卢尧的介绍来看,融合了视觉和语音的多模态免唤醒系统具有明显优势。如下图:这套多模态免唤醒交互系统,同时采用视觉检测和语音识别交互,误唤醒率仅为0.01%,交互响应成功率相较于仅基于语音识别交互系统大幅提升。
早在今年5月,科大讯飞AI研究院副院长高建清博士就在某论坛上介绍过公司在多模态语音交互技术方面的最新进展。据高建清介绍,科大讯飞依托语音与视觉方面的多年积累,打造了一套语音、视觉多模态融合的免唤醒多模态交互系统。
通过将麦克风提供的空间信息和音视频提供的说话人相关信息进行融合绑定,实现高准确度的说话人分离;通过多模态VAD与端到端意图技术的结合,实现无唤醒词的自然人机交互,具有可靠、自然、鲁棒的特点。
具体来看,基于多模态多通道的语音分离系统,将语音信号、麦克风阵列提供的空间信息以及主说话人的唇形输入分离模型,系统最终输出视频说话人的语音,抑制背景噪声及干扰说话人语音。在多人同时讲话、车载音乐情况下,语音识别效果相比单模分离系统有50%以上性能提升。不仅解决了传统麦克风阵列方法无法有效区分同向干扰的问题,还可提升非同向干扰分离场景的性能。
多模态交互技术的应用
语音识别是人工智能技术的一个重要分支,近些年来,智能语音也在多项技术难点上取得突破。业界普遍认为,在语音识别方面,视听融合的多模态交互技术成为技术演进的主要方向。
科大讯飞是国内主要的智能语音技术玩家,其多模语音增强技术融合语音与视觉的多模感知,让高噪音场景下的语音交互跨过实用门槛,目前已经在车载、会议、地铁购票和医疗挂号等场景落地。
在车载领域,人机交互系统需要攻克两大难题:一是环境噪音及人声干扰,尤其是麦克风阵列技术难以解决的同向人声干扰问题(如:驾驶员与左后方乘客同时说话);二是传统语音交互系统每次启动交互都需要说唤醒词,难以做到像人与人交流一样自然顺畅。
此前就有消息显示,科大讯飞多模态免唤醒交互解决方案将率先在广汽传祺和威马等自主品牌车型上部署应用。该方案能够适应复杂光线暗、语音嘈杂等多种工况,并支持主流SOC和DMS摄像头。
在地铁购票场景中,此前因为地铁站点太多,买票难以找到目的地站点,而且这些操作对于老年人不太友好,而语音购票的功能让这些问题迎刃而解。同时,因为地铁站人声嘈杂,也使得语音交互的体验并不友好。
根据此前的报道,深圳地铁12号线智能售票机及智慧客服终端上,率先采用了科大讯飞多模语音增强技术,该技术通过识别人脸唇形等信息,同时结合人声,使得即使在人声嘈杂的环境,语音识别的准确率也大大提升。
多模态语音识别技术在智能家居场景中也非常实用。融合语音、手势、视觉感知,用户可以过简单的口头指令控制智能家居设备,实现智能灯光、家居安防等功能,通过摄像头和深度学习技术,智能家居可以识别用户的手势动作,实现手势控制家居设备的操作。同时,通过视觉感知技术,识别用户的面部表情和情绪状态,根据不同情况提供相应的互动体验。
总结
经过多年的发展,语音识别技术已经相当成熟,并且在车载、智能家居等各种场景中实现应用,并给人们的生活带来便利。然而同时,一直以来语音识别也存在诸多难点,比如环境噪声、多人同时发出声音等情况,都会影响语音识别的准确率。而视听融合的多模态技术,将视觉和语音结合,能够很好的解决这些问题,使得语音识别的准确率大幅提升。
- 语音识别
+关注
关注
38文章
1684浏览量
112153
发布评论请先登录
相关推荐
聆思CSK6视觉语音大模型AI开发板入门资源合集(硬件资料、大模型语音/多模态交互/英语评测SDK合集)
李未可科技正式推出WAKE-AI多模态AI大模型

百度首席技术官王海峰解读文心大模型的关键技术和最新进展

语音数据集:AI语音技术的灵魂
情感语音识别:技术前沿与未来趋势
汽车多模态交互研究:大模型及多模态融合,推进AI Agent上车





 工商网监
工商网监
评论