 两种应用于3D对象检测的点云深度学习方法
两种应用于3D对象检测的点云深度学习方法
随着激光雷达传感器(“光检测和测距”的缩写,有时称为“激光扫描”,现在在一些最新的iPhone上可用)或 RGB-D 摄像头(一种 RGB-D 摄像头)的兴起,3D 数据变得越来越广泛。D 图像是标准 RGB 图像与其关联的“深度图”的组合,目前由 Kinect 或英特尔实感技术使用。3D 数据可以对传感器周围环境进行丰富的空间表示,并可应用于机器人、智能家居设备、无人驾驶汽车或医学成像。
3D 数据可以采用多种格式:RGB-D 图像、多边形网格、体素、点云。点云只是一组无序的坐标三元组 (x, y, z),这种格式已经变得非常流行,因为它保留了所有原始 3D信息,不使用任何离散化或 2D 投影。从根本上讲,基于 2D 的方法无法提供准确的 3D 位置信息,这对于机器人或自动驾驶等许多关键应用来说是个问题。
因此,直接在点云输入上应用机器学习技术非常有吸引力:它可以避免执行 2D 投影或体素化时发生的几何信息丢失。由于 3D 数据固有的丰富特征表示,点云深度学习在过去 5 年中引起了广泛关注。
但也存在一些挑战:输入的高维度和非结构化性质,以及可用数据集的小规模及其噪声水平。此外,点云本质上是被遮挡和稀疏的:3D 对象的某些部分对传感器来说只是隐藏的,或者信号可能会丢失或被阻挡。除此之外,点云本质上是不规则的,使得 3D 卷积与 2D 情况非常不同(见下图)。
受 ML6 客户的几个用例的启发,我们研究了两种应用于 3D 对象检测的点云深度学习方法(VoteNet 和 3DETR)。两者都是由 Facebook 研究团队发明的(请参阅下面的链接部分中 Facebook 研究文章的链接[5]、[6]和[7])。该模型的目标是使用点云(从 RGB-D 图像预处理)并估计定向 3D 边界框以及对象的语义类别。
1、数据预处理
我们一直使用的主要数据集是 SUN RGB-D 数据集。它包括室内场景(卧室、家具店、办公室、教室、浴室、实验室、会议室等)的 10,335 个 RGB-D 图像。这些场景使用围绕 37 种对象的 64,595 个定向 3D 边界框进行注释,其中包括椅子、桌子、枕头、沙发……(请参阅链接[1]、[2]、[3]和[4]链接部分详细说明数据集的各种来源以及用于创建数据集的方法)。在训练期间通过应用点云的随机子采样、翻转、旋转和随机缩放来使用数据增强。
RGB-D 图像到浊点的转换是通过图像中给定坐标处的 2D 坐标和深度值的线性变换来完成的,同时考虑到相机的固有特性。基本的三角学考虑导致了这种线性变换的数学公式(有关更详细的解释,请参阅[8])。下图(由 yodayoda Inc. 在[8]中提供)说明了该操作。预处理可以使用Matlab函数来完成,例如 Facebook 团队的代码(需要对代码进行一些更改才能使其与免费版本 Octave 一起使用,这会显着减慢预处理速度)或使用 Open3D 开源库(请参阅 链接部分链接[9]到图书馆的主页)。
2、Pointnet++ 和 VoteNet
第一种方法 VoteNet ([5]) 使用 Pointnet++ ([7]) 作为主干(均来自同一作者 Charles R. Qi)。
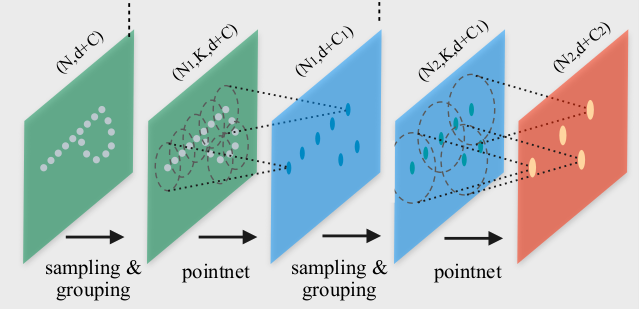
Pointnet++ 将点云作为输入并输出输入云的子集,但每个点都有更多特征,并且现在丰富了有关局部几何图案的上下文。这与卷积网络类似,只是输入云以数据相关的方式进行子采样,特定点周围的邻域由度量距离定义,并且该邻域中的点数是可变的。下图(摘自[7])说明了 Pointnet++ 架构。
图片
该图像上的 Pointnet 层创建每个局部区域的抽象(由固定半径定义)。每个局部区域都被转换为由其质心和丰富特征组成的向量,从而形成邻域的抽象表示。在我们的特定情况下,原始输入点云由可变数量(20,000 或 40,000)的三元组(x、y、z)组成,Pointnet++ 主干网的输出是一组 1,024 个维度为 3+256 的点。主干中的每个 Pointnet 层只是一个多层感知器(每个 1 或 2 个隐藏层)。
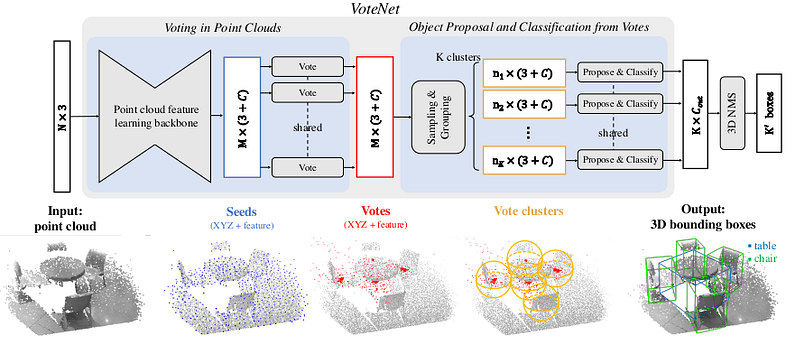
用于 3D 对象检测的 VoteNet 方法使用 Pointnet++ 的输出并应用“深度霍夫投票”。下图说明了该方法(摘自[5])。
图片
主干输出的每个点(具有丰富的特征)都被输入到共享的多层感知器中以生成投票(“投票模块”):该投票神经网络输出点(其输入)和点的质心之间的位移三元组。它所属的对象(如果有)。它经过训练,可以最大限度地减少位移的范数,并添加一些有助于投票聚合的额外功能。
如上图所示,投票被聚集。每个簇都被馈送到“提议和分类模块”(实际上是 2 个多层感知器),该模块输出一个预测向量,包括:客观性得分、边界框参数和语义分类得分。这三个元素中的每一个都构成一个损失函数(如果我们添加上面提到的投票回归损失,那么总共 4 个元素):对象交叉熵损失、边界框估计损失和类别预测损失。
3、3DETR
3DETR 方法(在[6]中描述)是一种纯粹基于Transformer的方法,与普通transformer架构相比几乎没有任何修改,这是非常了不起的。3DETR 架构如下图所示(摘自[6])。

图片
Transformer编码器从子采样+集合聚合层接收输入,就像上面描述的 Pointnet++ 主干一样(除了在这种情况下该操作仅应用一次,而不是在 Pointnet++ 中应用多次)。然后,Transformer 编码器应用多层自注意力和非线性投影(在我们的例子中,有 3 个多头注意力层,每个层有 8 个头)。不需要位置嵌入,因为该信息已包含在输入中。自注意力机制是排列不变的,并且允许表示长范围依赖。话虽这么说,编码器中的自注意力层可以使用掩码进行修改,以便关注局部模式而不是全局模式。
解码器由多个transformer块组成(在我们的例子中为 8 个)。它接收查询并预测 3D 边界框。查询是通过从输入云中采样一些点(在我们的例子中为 128 个)并将它们输入到位置嵌入层和随后的多层感知器中来生成的。
4、实战案例
这是来自 SUN RGB-D 数据集的 RGB-D 图像的示例。
然后图像被预处理成 20,000 或 80,000 个点的点云。你可以使用 MeshLab 可视化各种 3D 数据,包括点云。
VoteNet 或 3DETR算法现在可以预测边界框(和对象类)。
5、性能表现
为了评估 3D 对象检测技术,最广泛使用的指标是平均精度 (mAP):平均精度 (AP) 是精度-召回率曲线下的面积,平均精度 (mAP) 是所有对象的平均值 类。IoU(交并集)阈值固定为 0.25 或 0.5,为我们提供 AP25 或 AP50 指标。这控制了预测边界框和真实边界框之间所需的重叠。
我们在 Google Cloud Platform 虚拟机上的 SUN RGB-D 训练集上对 VoteNet 模型进行了 180 个 epoch 的训练(如[5]的作者所建议),并在测试集上获得了 57% 的 AP25(如[5])。我们的 VoteNet 模型大小合理,具有大约 100 万个可训练参数。
至于3DETR模型,该模型更大,有700万个可训练参数,需要训练360个epoch才能在SUN RGB-D数据集上达到57%的AP25。这需要几天的训练。幸运的是,[6]的作者公开了一个在 SUN RGB-D 上预训练了 1080 个 epoch 的模型。我们对其进行了测试,得到了与 VoteNet 相同的 AP25,即 57%。编码器中带有屏蔽自注意力的 3DETR 模型版本也可用,并且性能稍好一些。应该指出的是,根据[6]的作者的说法,性能增益在另一个数据集上更为重要(ScanNetV2 请参阅下面该数据集的更多信息)。
6、迁移学习
一个重要的考虑因素是将预训练模型(例如[5]和[6]的作者提供的模型)转移到我们客户的数据上的能力。这在 3D 对象检测的情况下尤其重要,因为数据难以注释、被遮挡且有噪声。
我们测试了在 ScanNetV2 数据集上训练的 VoteNet 到 SUN RGB-D 数据集的可迁移性。ScanNetV2(详细信息请参阅[10])是一个由室内场景重建的 1,200 个 3D 网格的带注释数据集。它确实包括 18 个对象类别 虽然 SUN RGB-D 和 ScanNetV2 都属于相似的室内场景领域,但它们实际上完全不同:ScanNetV2 中的场景覆盖更大的表面、更完整并包含更多对象。对 ScanNetV2 数据集中的顶点进行采样以创建输入点云。
我们使用在 ScanNetV2 上预训练了 180 个 epoch 的 VoteNet 模型。我们尽可能保留了这个模型的内容:主干模块、投票模块以及除最后一个输出层之外的所有提案和分类模块。有趣的是,该模型仅在 SUN RGB-D 上进行了 30 个 epoch 的微调,就达到了与在 SUN RGB-D 上从头开始训练 180 个 epoch 的相同 VoteNet 模型相同的性能。
这是一个令人鼓舞的结果,让我们相信我们的预训练模型可以轻松地从其他类型的室内域转移到 ML6 客户端的数据,而不需要大型注释数据集。
审核编辑:汤梓红
- 传感器
+关注
关注
2541文章
49687浏览量
746238 - 摄像头
+关注
关注
59文章
4731浏览量
94143 - 激光雷达
+关注
关注
966文章
3852浏览量
188442 - 深度学习
+关注
关注
73文章
5415浏览量
120485
原文标题:点云目标识别深度网络
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先登录
相关推荐
基于深度学习的方法在处理3D点云进行缺陷分类应用
两种建立元件3D图形的方法介
3D点云技术介绍及其与VR体验的关系
基于图卷积的层级图网络用于基于点云的3D目标检测
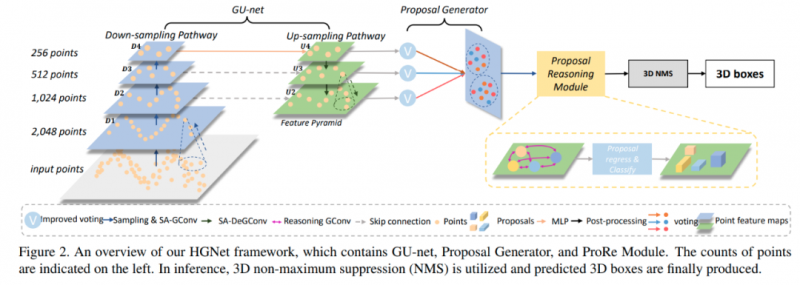
基于层级图网络的图卷积,用点云完成3D目标检测
如何在LiDAR点云上进行3D对象检测





 工商网监
工商网监
评论