 OneLLM:对齐所有模态的框架!
OneLLM:对齐所有模态的框架!
今天为大家介绍香港中文大学联合上海人工智能实验室的最新研究论文,关于在LLM时代将各种模态的信息对齐的框架。
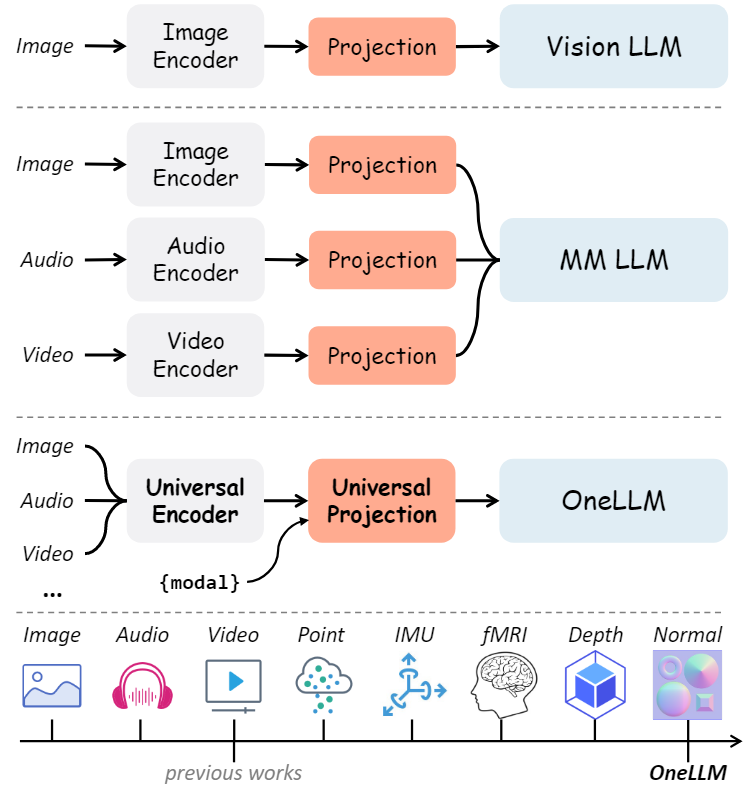
随着LLM的兴起,由于其强大的语言理解和推理能力,在学术和工业界中越来越受欢迎。LLM的进展也启发了研究人员将LLM作为多模态任务的接口,如视觉语言学习、音频和语音识别、视频理解等,因此多模态大语言模型(Multimodal Large Language Model, MLLM)也引起了研究人员的关注。然而,目前的研究依赖特定于单模态的编码器,通常在架构上有所不同,并且仅限于常见的模态。本文提出了OneLLM,这是一种MLLM,它使用一个统一的框架将八种模式与语言对齐。通过统一的多模态编码器和渐进式多模态对齐pipelines来实现这一点。不同多模态LLM的比较如下图所示,可以明显的看出OneLLM框架的工作方式与之前研究的区别。
OneLLM由轻量级模态标记器、通用编码器、通用投影模块(UPM)和LLM组成。与之前的工作相比,OneLLM 中的编码器和投影模块在所有模态之间共享。特定于模态的标记器,每个标记器仅由一个卷积层组成,将输入信号转换为一系列标记。此外,本文添加了可学习的模态标记,以实现模态切换并将不同长度的输入标记转换为固定长度的标记。
动机
众多特定于模态的编码器通常在架构上有所不同,需要付出相当大的努力将它们统一到一个框架中。此外,提供可靠性能的预训练编码器通常仅限于广泛使用的模式,例如图像、音频和视频。这种限制对 MLLM 扩展到更多模式的能力施加了限制。因此,MLLM 的一个关键挑战是如何构建一个统一且可扩展的编码器,能够处理广泛的模态。
贡献
本文提出了一个统一框架来将多模态输入与语言对齐。与现有的基于模态的编码器的工作不同,展示了一个统一的多模态编码器,它利用预训练的视觉语言模型和投影专家的混合,可以作为 MLLM 的通用且可扩展的组件。
OneLLM 是第一个在单个模型中集成八种不同模态的MLLM。通过统一的框架和渐进式多模态对齐pipelines,可以很容易地扩展OneLLM以包含更多数据模式。
本文策划了一个大规模的多模态指令数据集。在这个数据集上微调的 OneLLM 在多模态任务上取得了更好的性能,优于主流模型和现有的 MLLM。
相关工作
LLM的迅猛发展引起了研究人员的重视,因此有研究人员提出了视觉领域的大型视觉语言模型,并取得了较好的性能。除了视觉领域大语言模型之外,研究人员将其拓展到了多模态领域,如音频、视频和点云数据中,这些工作使得将多种模式统一为一个LLM成为可能即多模态大语言模型。X-LLM,ChatBridge,Anymal,PandaGPT,ImageBind-LLM等MLLM不断涌现。然而,当前的 MLLM 仅限于支持常见的模式,例如图像、音频和视频。目前尚不清楚如何使用统一的框架将 MLLM 扩展到更多模式。在这项工作中,提出了一个统一的多模态编码器来对齐所有模态和语言。将多种模式对齐到一个联合嵌入空间中对于跨模态任务很重要,这可以分为:判别对齐和生成对齐。判别对齐最具代表性的工作是CLIP,它利用对比学习来对齐图像和文本。后续工作将 CLIP 扩展到音频文本、视频文本等。本文的工作属于生成对齐。与之前的工作相比,直接将多模态输入与LLM对齐,从而摆脱训练模态编码器的阶段。
方法
模型架构
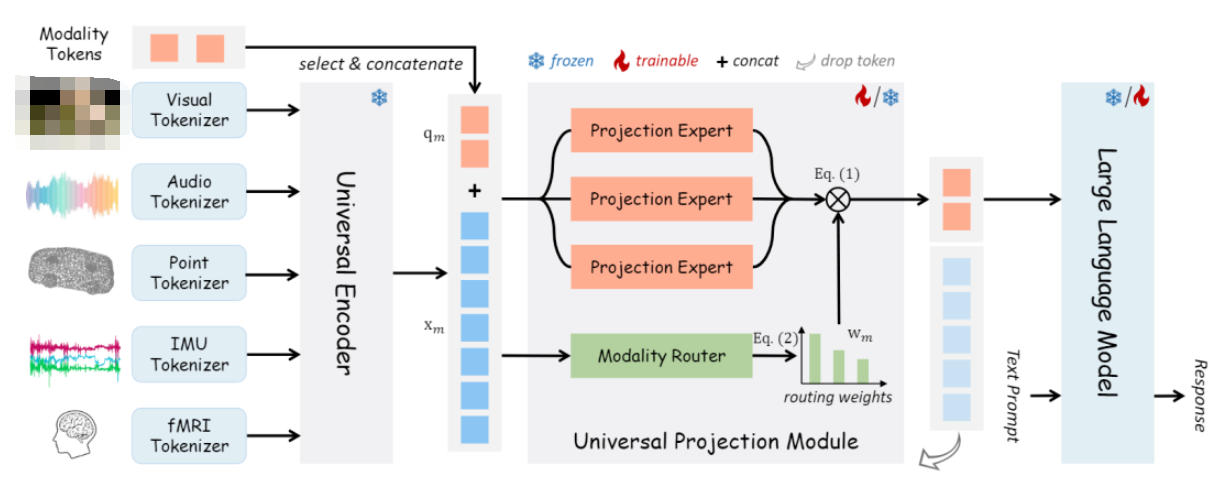
上图展示了 OneLLM 的四个主要组件:特定于模态的标记器、通用编码器、通用投影模块和 LLM。
模态标记器:模态标记器是将输入信号转换为标记序列,因此基于转换器的编码器可以处理这些标记。为每个模态设计了一个单独的标记器。对于图像和视频等二维位置信息的视觉输入,直接使用单个二维卷积层作为标记器。对于其他模态,将输入转换为 2D 或 1D 序列,然后使用 2D/1D 卷积层对其进行标记。
通用编码器:利用预训练的视觉语言模型作为所有模态的通用编码器。视觉语言模型在对大量图文数据进行训练时,通常学习视觉和语言之间的稳健对齐,因此它们可以很容易地转移到其他模式。在OneLLM中,使用CLIPViT作为通用计算引擎。保持CLIPViT的参数在训练过程中被冻结。
通用投影模块:与现有的基于模态投影的工作不同,提出了一个通用投影模块,将任何模态投影到 LLM 的嵌入空间中。由 K 个投影专家组成,其中每个专家都是在图像文本数据上预训练的一堆transformer层。尽管一位专家还可以实现任何模态到 LLM 的投影,但实证结果表明,多个专家更有效和可扩展。当扩展到更多模态时,只需要添加几个并行专家。
LLM:采用开源LLaMA2作为框架中的LLM。LLM的输入包括投影的模态标记和单词嵌入后的文本提示。为了简单起见,本文总是将模态标记放在输入序列的开头。然后LLM被要求以模态标记和文本提示为条件生成适当的响应。
渐进式多模态对齐
多模态对齐的简单方法是在多模态文本数据上联合训练模型。然而,由于数据规模的不平衡,直接在多模态数据上训练模型会导致模态之间的偏差表示。本文训练了一个图像到文本模型作为初始化,并将其他模式逐步接地到LLM中。包括图文对齐、多模态-文本对齐。同时为每个模态收集 X 文本对。图像-文本对包括LAION-400M和LAION-COCO。视频、音频和视频的训练数据分别为WebVid-2.5M、WavCaps和Cap3D。由于没有大规模的deep/normal map数据,使用预训练的 DPT 模型来生成deep/normal map。源图像和文本以及 CC3M。对于IMU-text对,使用Ego4D的IMU传感器数据。对于fMRI-text对,使用来自NSD数据集的 fMRI 信号,并将与视觉刺激相关的字幕作为文本注释。
多模态指令调优
在多模态文本对齐之后,OneLLM 成为一个多模态字幕模型,可以为任何输入生成简短的描述。为了充分释放OneLLM的多模态理解和推理能力,本文策划了一个大规模的多模态指令调优数据集来进一步微调OneLLM。在指令调优阶段,完全微调LLM并保持其余参数冻结。尽管最近的工作通常采用参数高效的方法,但凭经验表明,完整的微调方法更有效地利用 OneLLM 的多模态能力,特别是利用较小的 LLM(e.g.,LLaMA2-7B)。
实验
实现细节
架构:通用编码器是在LAION上预训练的CLIP VIT Large。LLM 是 LLAMA2-7B。UPM有K=3个投影专家,每个专家有8个transformer块和88M个参数。
训练细节:使用AdamW优化器,β1=0.9,β2==0.95,权重衰减为0.1。在前2K次迭代中应用了线性学习速率预热。对于阶段I,在16个A100 GPU上训练OneLLM 200K次迭代。有效批量大小为5120。最大学习率为5e-5。对于第II阶段,在8个GPU上训练 OneLLM 200K,有效批量大小为1080,最大学习率为1e-5。在指令调优阶段,在8个gpu上训练OneLLM 1 epoch,有效批大小为512,最大学习率为2e-5。
定量评价
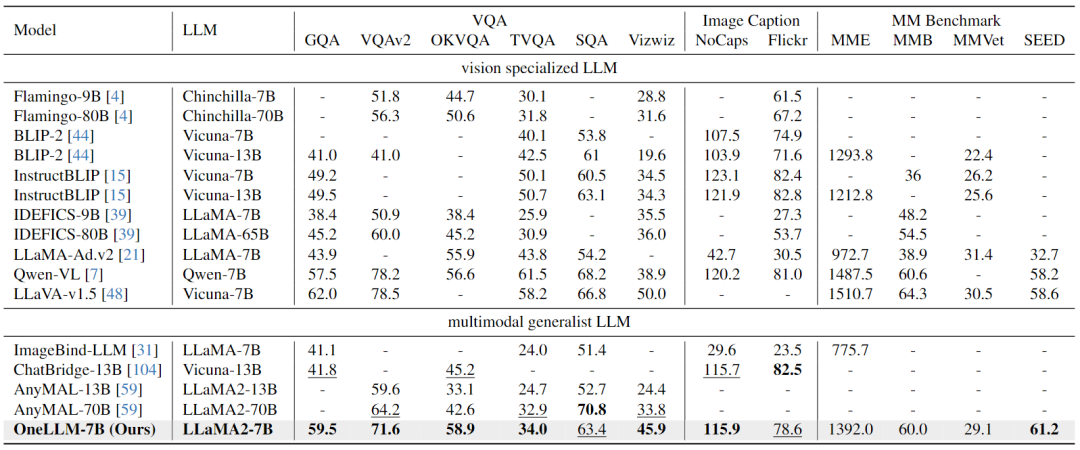
Image-Text Evaluation:下表结果表明,OneLLM还可以在视觉专门的LLM中达到领先水平,MLLM和视觉LLM之间的差距进一步缩小。
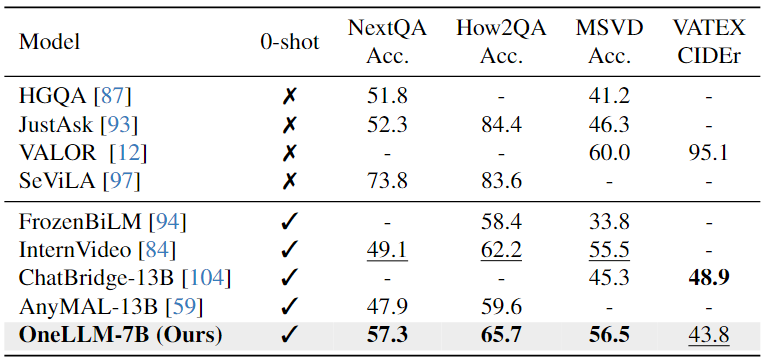
Video-Text Evaluation:下表可以看出,本文模型在相似的 VQA 数据集上进行训练明显增强了其紧急跨模态能力,有助于提高视频QA任务的性能。
Audio-Text Evaluation:对于Audio-Text任务,结果显示,在Clotho AQA上的zero-shot结果与完全微调的Pengi相当。字幕任务需要更多特定于数据集的训练,而QA任务可能是模型固有的零样本理解能力更准确的度量。
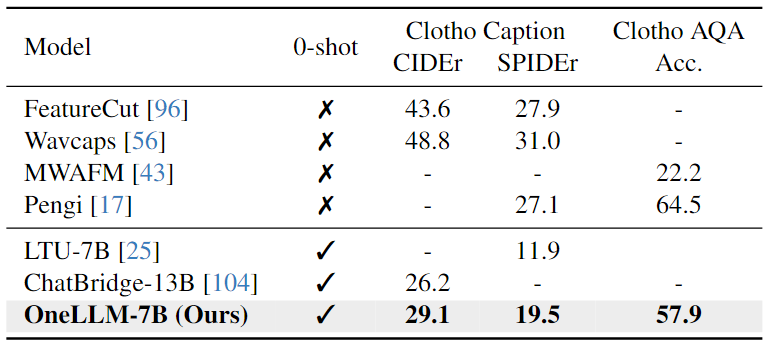
Audio-Video-Text Evaluation:下表结果表明,OneLLM-7B在所有三个数据集上都超过了 ChatBridge-13B。由于 OneLLM 中的所有模态都与语言很好地对齐,因此在推理过程中可以直接将视频和音频信号输入到 OneLLM。
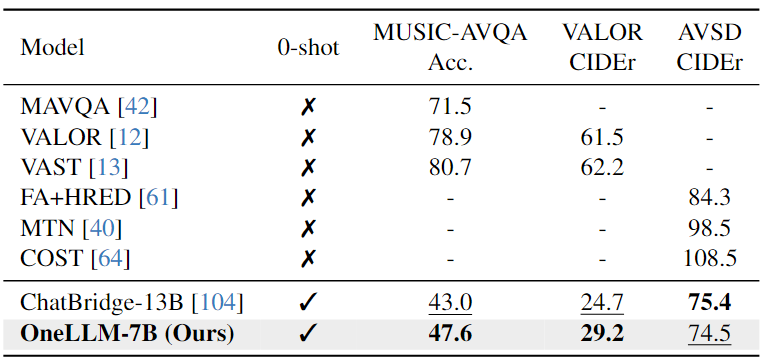
Point Cloud-Text Evaluation:从下表中可以看出,由于精心设计的指令提示在任务之间切换,OneLLM可以实现出色的字幕结果,而InstructBLIP和PointLLM 难以生成简短而准确的字幕。在分类任务中,OneLLM也可以获得与 PointLLM 相当的结果。
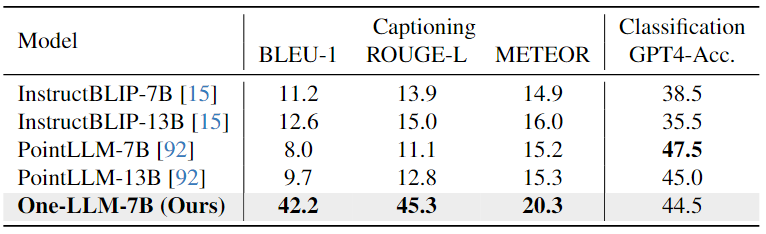
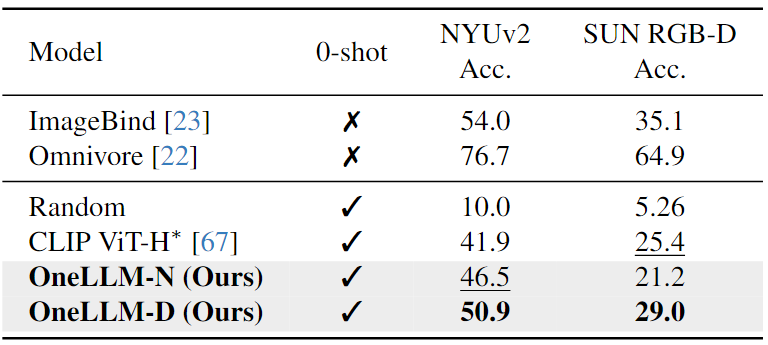
Depth/Normal Map-Text Evaluation:如下表中所示,与CLIP相比,OneLLM实现了优越的zero-shot分类精度。这些结果证实,在合成deep/normal map-text数据上训练的OneLLM可以适应现实世界的场景。
消融实验
为了探索 OneLLM 的一些关键设计。消融实验是在训练数据的一个子集上进行的,除了对专家数量的研究外,它只包含图像、音频和视频的多模态对齐和指令调整数据集。如果没有指定,其他设置保持不变。消融实验的结果如下表所示,
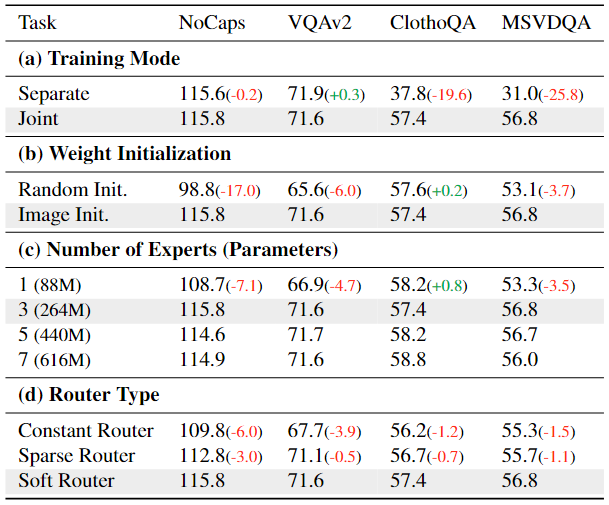
MLLM 的一个重要问题是联合训练的 MLLM 是否优于特定于模态的 MLLM。为了解决这个问题,在表7(a)中比较了单独训练的MLLM与联合训练的MLLMs的性能。在单独的训练中,模型只能访问自己的数据;在联合训练中,模型在所有数据上联合训练。在两个图文任务 NoCaps 和 VQAv2 上,可以看到单独和联合训练的模型取得了可比较的结果;虽然单独训练的音频和视频模型比 ClothoQA 和 MSVDQA 上的联合训练模型差得多。这表明联合训练通过允许跨模态迁移学习知识的转移,极大地有利于数据稀缺模态(例如音频和视频)。
表7(b)表明,具有图像-文本对齐的 OneLLM 可以帮助多模态文本对齐。如果使用随机初始化的模型直接将所有模态与文本对齐,图像和视频的性能会显着下降。相反,具有图像-文本预训练的 OneLLM 可以更好地平衡不同的模式。
具有三个投影专家的 OneLLM 足以保持所有模态。增加专家的数量并不能带来所需的改进,而一位专家的结果也不能令人满意。
软路由器优于其他两个路由器,表明其对多模态信号的动态路由的有效性。
定性分析
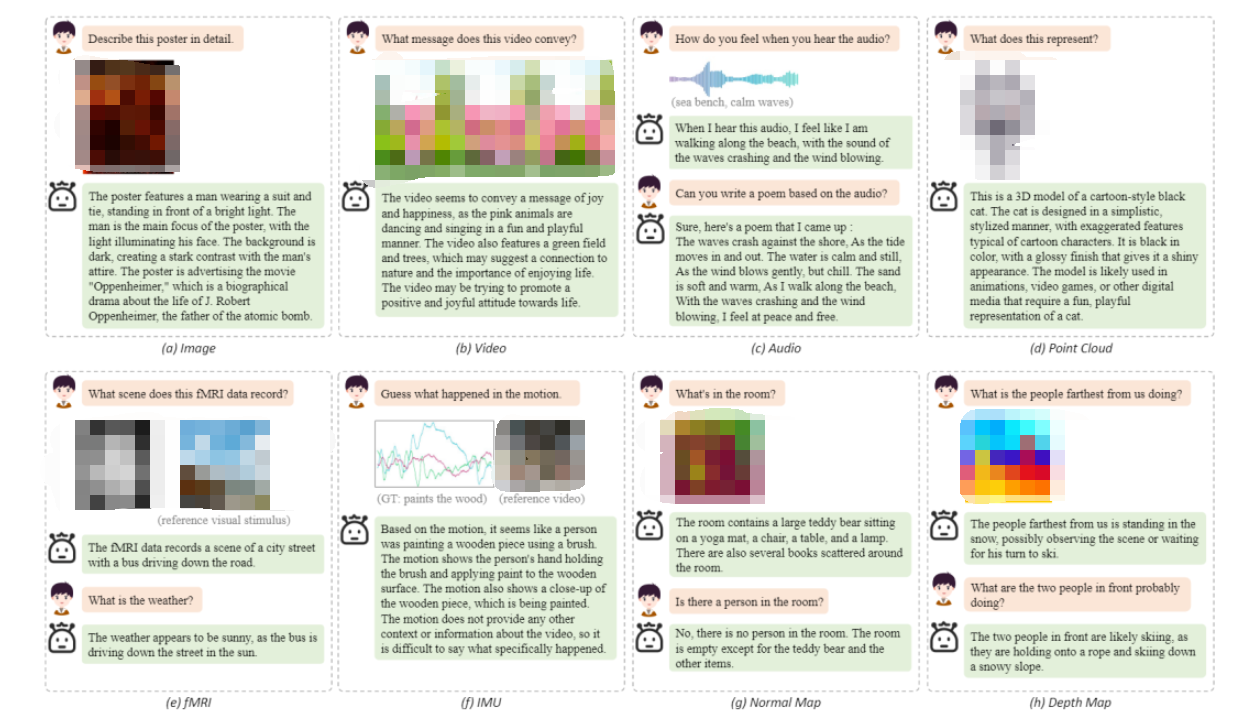
下图中给出了 OneLLM 在八种模态上的一些定性结果。展示了 OneLLM 可以(a)理解图像中的视觉和文本内容,(b)利用视频中的时间信息,(c)基于音频内容进行创造性写作,(d)理解3D形状的细节,(e)分析fMRI数据中记录的视觉场景,(f)基于运动数据猜测人的动作,以及(g)-(h)使用deep/normal map进行场景理解。
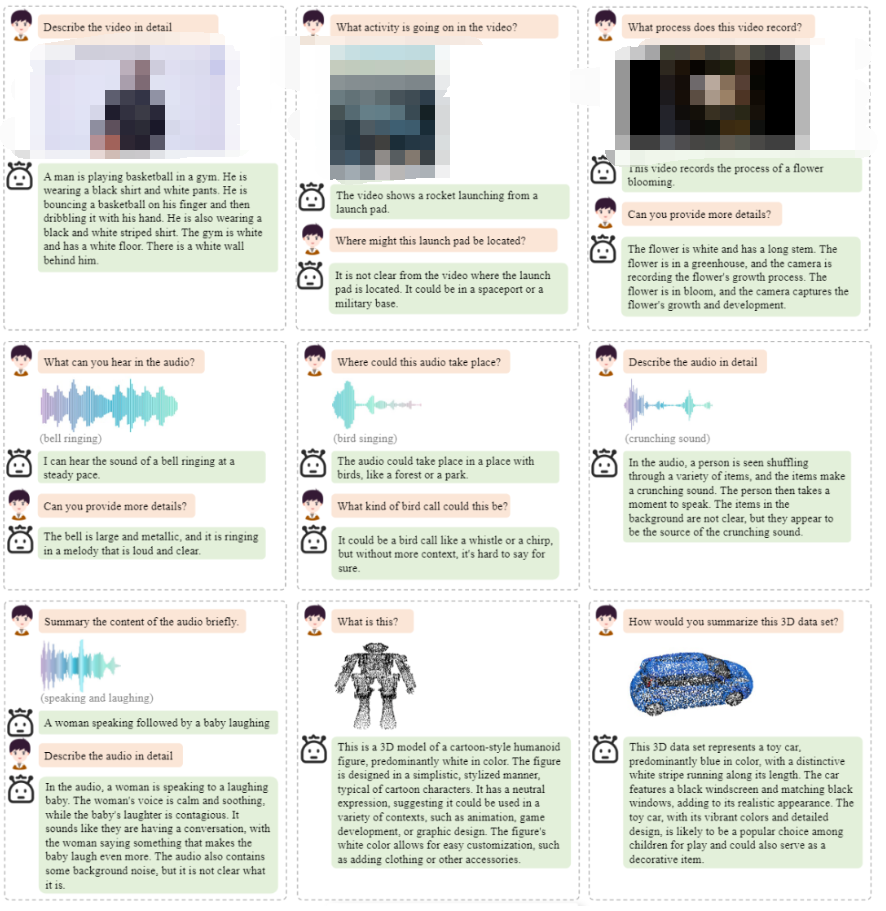
以下是OneLLM框架更多的定性分析结果。
总结
在这项工作中,本文介绍了 OneLLM,这是一种 MLLM,它使用一个统一的框架将八种模式与语言对齐。最初,训练一个基本的视觉LLM。在此基础上,设计了一个具有通用编码器、UPM 和 LLM 的多模态框架。通过渐进式对齐pipelines,OneLLM 可以使用单个模型处理多模态输入。此外,本文工作策划了一个大规模的多模态指令数据集,以充分释放OneLLM的指令跟踪能力。最后,在 25 个不同的基准上评估 OneLLM,显示出其出色的性能。
限制与未来工作:本文的工作面临两个主要挑战:
缺乏图像之外模态的大规模、高质量的数据集,这导致 OneLLM 和这些模式上的专业模型之间存在一定差距。
高分辨率图像、长序列视频和音频等的细粒度多模态理解。未来,将收集高质量的数据集,设计新的编码器来实现细粒度的多模态理解。
审核编辑:黄飞
-
编码器
+关注
关注
45文章
3638浏览量
134418 -
路由器
+关注
关注
22文章
3728浏览量
113697 -
大模型
+关注
关注
2文章
2423浏览量
2637 -
LLM
+关注
关注
0文章
286浏览量
327
原文标题:OneLLM:对齐所有模态的框架!
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
模态分解合集matlab代码
商汤日日新多模态大模型权威评测第一
KiCad的对齐工具不好用?
HarmonyOS NEXT应用元服务开发Intents Kit(意图框架服务)综述
ARM嵌入式系统中内存对齐的重要性

利用OpenVINO部署Qwen2多模态模型
鸿蒙ArkTS声明式开发:跨平台支持列表【半模态转场】模态转场设置

OpenAI超级对齐团队解散
鸿蒙ArkUI开发:【弹性布局(主轴&交叉轴对齐方式)】
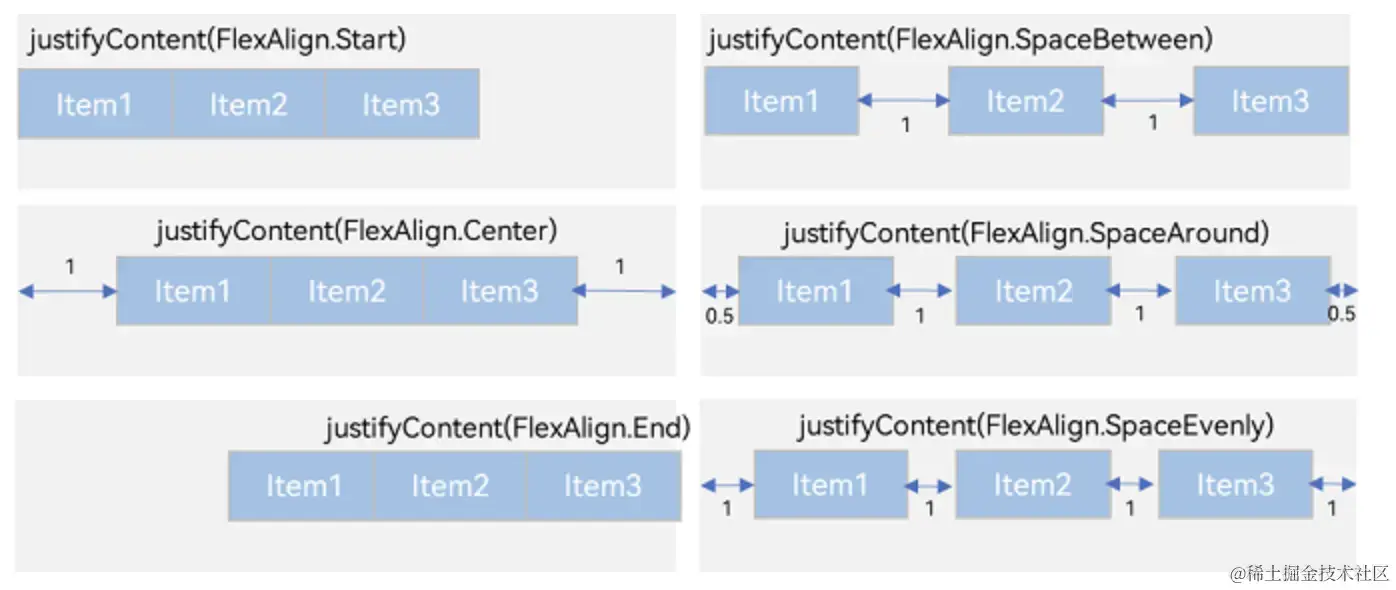
HarmonyOS开发ArkUI案例:【常用布局容器对齐方式】
OpenHarmony实战开发-如何实现模态转场
请问PWM波输出方式中的边沿对齐与中心对齐有什么区别呢?
什么是多模态?多模态的难题是什么?

keil arm工程中结构体1字节对齐如何实现
自动驾驶和多模态大语言模型的发展历程






 工商网监
工商网监
评论