 深入浅出理解PagedAttention CUDA实现
深入浅出理解PagedAttention CUDA实现
vLLM 中,LLM 推理的 prefill 阶段 attention 计算使用第三方库 xformers 的优化实现,decoding 阶段 attention 计算则使用项目编译 CUDA 代码实现。具体代码在 vllm 的 csrc/attention/attention_kernels.cu 文件里,开发者洋洋洒洒写了八百多行 CUDA 代码。
Attention 计算时使用页式(paged)管理 KVCache 用于增加服务吞吐率,但对延迟有负面影响,因此高效的 PA 实现方法,利用页式内存管理同时尽量降低其负面影响,对框架的综合性能表现至关重要。
本文章将描述 PA CUDA Kernel 的实现细节,这些细节是公开的论文和博客所不涉及的,但却对框架的速度至关重要。另外,PA 实现改编自 FasterTransformers 某个版本的 MHA 实现,NV 原始版本对 GPU 特性的运用也是相当老道的,值得大家借鉴。
vLLM 中有两个版本 PA,使用一个简单的启发式方法来决定是使用 V1 还是 V2 版本。V1 是本文介绍的版本,改编自 FasterTransformers 的 MHA 实现。V2 是参考 FlashDecoding 方式进行实现,对 sequence 维度进行切分以增加并行粒度,关于 FlashDecoding 可以参考本人知乎文章。V1 适合长度小于 8192 或者 num_seqs * num_heads>512 的情况。
参数定义和数据结构
num_seq:本次推理请求 sequence 数目。
num_head:Query 的 head 数目。
num_kv_heads:Key、Value 的 head 数目,对于 MHA 和 num_head 相同,如果是 GQA、MQA 则 num_kv_heads 小于 num_head。
head_size hidden dimension,特征的维度。
PA 使用 tensor 的维度信息:
out [num_seqs, num_heads, head_size]
Q [num_seqs, num_heads, head_size]
KCache [num_blocks, num_kv_heads, head_size/x, block_size, x]:x 表示一个向量化的大小,如 float16 -> 16 / sizeof(float16) = 8。
VCache [num_blocks, num_kv_heads, head_size, block_size]
Paged 内存管理相关的辅助数据结构:
blk_size:也就是 block_size,是 KVCache page 的最高维,KVCache 是若干个 page 的集合,每个 page 存(blk_size, num_head,head_size)个 K、V 的元素。
head_mapping [num_heads] 用于 MQA, GQA,确定用的 KV_head
block_tables [num_seqs, max_num_blocks_per_seq] block_tables 映射表,表示每个 sequence 映射到哪几个 block 上
context_lens [num_seqs] 用于变长
课前问题
如果你能回答以下两个问题,那么说明你已经非常熟练地掌握了 PA 实现,并可以用批判性的眼光审阅本文,找出其中可能存在的错误。如果你暂时无法回答这些问题,请不要担忧,阅读完本文后会给你答案。
Q1:为什么 K Cache 的 layout 和 V Cache layout 不一样?
Q2:PA 实现和 FlashAttention 有什么区别?
PagedAttention算子计算流程
首先,按照 CUDA 编程模型对任务进行并行划分,grid 大小(num_heads, num_seqs),grid 中每个 CUDA thread block 大小(NUM_THREADS),NUM_THREADS 是常量默认为 128,也就说每个 thread block 包含 128 个线程,负责完成 output 矩阵一行(包含 head_size 个元素)结果的 attention 计算任务。thread block 中的线程进一步划分若干个WARP。
众所周知,WARP 是 GPU 一个基本的执行单元,由 32 个线程组成,这些线程以 SMIT 方式在硬件上同时执行相同的指令,在不同的数据上进行操作。在 PA 中比较特殊的是,warp 内 32 个线程进一步划分为 blk_size 个 thread group,这和 paged KVCache 设计 x 息息相关的,马上会细讲。
Attention 计算 softmax(QK^T)V,一图胜前言,后面流程介绍将围绕下面这幅图展开。其中 thread block, warp, thread group, thread 别用不同颜色表示。
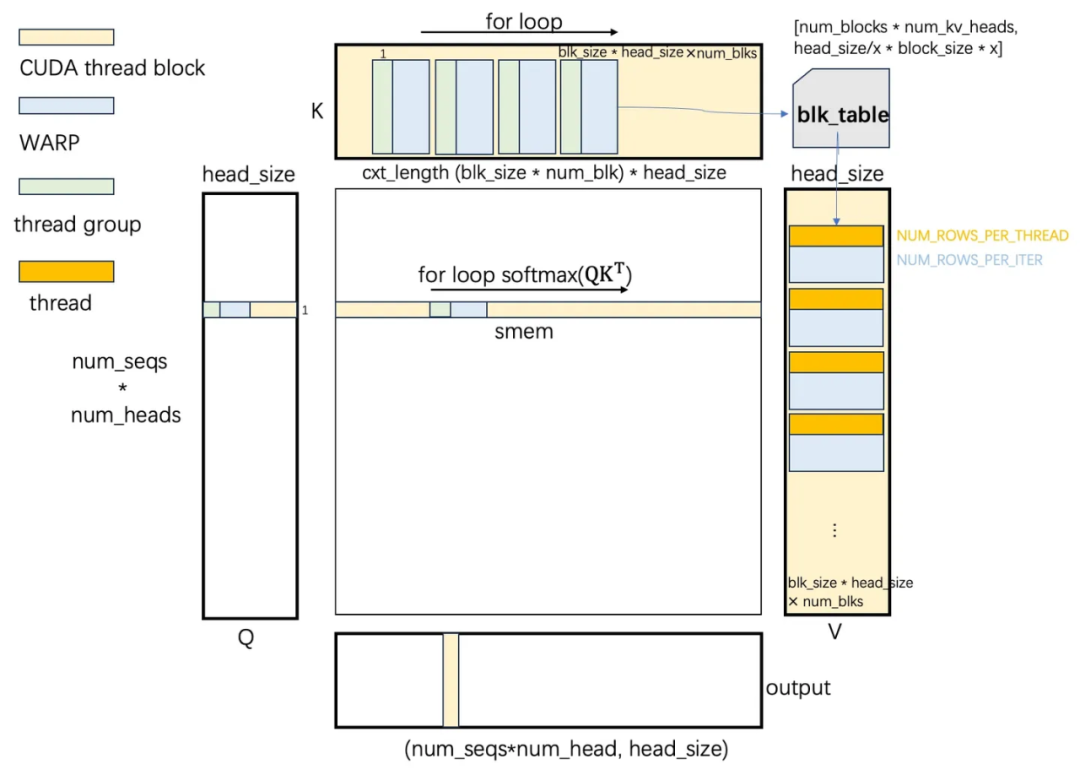
▲ 图1:PagedAttention CUDA计算流程
在上图的左侧部分,我们看到了 Q 矩阵,这部分描述了从显存读取 Q 数据到共享内存的过程。在这个过程中,一个 CUDA 线程块会读取图中 Q 矩阵的一行(包含 head_size个元素)并将其存入共享内存。
这个过程是通过一个循环来实现的,在每次迭代中,每个 thread group 会读取 16 字节的 Q 数据(例如,如果使用 float16,那么就是 8 个元素)。每个 warp 会读取 16*blk_size 字节的 Q 数据,这些数据对应于一个 sequence 的一个 head,由 CUDA grid 索引指定。当循环访问结束后,共享内存存储 Q 行的一部分。如下图所示,绿色部分表示存储在一个线程读入共享内存中的数据。
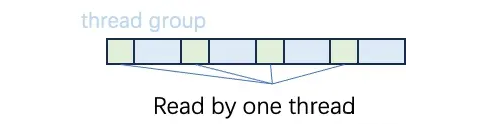
图 1 中上面部分 K 矩阵部分描述了从显存读取 K Cache 到寄存器的过程。每个序列的 K Cache 包含 cxt_length * num_kv_heads * head_size 个元素,但由于采用了页式内存管理,这些元素在内存中的存储并不连续。每个 thread block 只负责计算一个 sequence 一个 head 的 QK^T,因此只需要 ctx_length * head_size 个 K Cache 元素。
然而,由于 ctx_length 维度的存储是不连续的,并且以 blk_size 个 token 为粒度分布在不同的内存地址,我们需要根据query的head_idx和 seq_idx 访问 block_table 以找到 K Cache的physical_block_num。为了方便后续的描述,我们可以将 K Cache 视为(:, head_size)的形状,其中 head_size 个元素组成一行。
K Cache 的布局为 [num_blocks, num_kv_heads, head_size/x, block_size, x],这是为了优化写入 shared memory 的操作。在 Q 和 K 矩阵的同一行元素被读入寄存器并进行点乘运算后,结果需要被存入 shared memory。
如果一个 warp 中所有线程都计算 Q、K 同一行数据,会导致写入 shared memory 的同一个位置,这将造成 warp 内不同线程顺序地写入。因此,为了优化,warp的线程最好计算 Q 和 K 的不同行数据。因此,在设计 K Cache 布局时,我们将 block_size 放在比 head_size 更低的维度。
由于 warp size 大于 block_size,我们需要将 head_size 拆分为 head_size/x 和 x 两个维度,借 x 到最低维度,以确保每个线程读入的数据量和计算量都足够大。最后,每个线程组派一个线程去写入 shared memory,这样一个 warp 有 blk_size 个线程并行写入 shared memory,从而增加了 shared memory 的访问带宽。这种设计策略是为了实现高效的并行计算和内存访问,以提高整体的计算性能。
在代码实现中,访问 K 矩阵需要一个循环,该循环使得 CUDA 线程块中的所有 warp 依次访问 num_block 个页面。在每次循环迭代中,每个 warp 负责访问连续的 blk_size个K Cache 行,这涉及到的数据量为 blk_size * head_size 个元素。同时,每个 thread group 负责访问 K Cache 的一行,将 head_size 个元素加载到自己的寄存器中。
接着,寄存器中的 Q 和 K 数据元素立即进行点乘运算,运算结果被写入 shared memory 中。因此,线程块的 shared memory 存储了一行 QK^T 的结果,包含 ctx_length 个元素。这种实现方式充分利用了 CUDA 的并行计算能力,以提高数据处理的效率。
然后,thread block 对 shared memory 中元素进行 max,sum 方式 reduction,然后计算得到 softmax 结果。
图 1 右边 V 矩阵部分描述从显存读 V Cache 到寄存器过程。和 K Cache 一样,CUDA thread block 依次访问 num_blk 个物理块到寄存器,每个 warp 负责 blk_size 个 token 的 page 内存,page 的真实物理地址同样需要进行索引。
不过这里不需要以 thread group 为单位访问 16 字节,而是每个 thread 访问 16 字节的元素。访问完就可以与 shared memory 的 softmax(QK^T) 中间结果对应位置 16 字节的数据进行点乘,得到一个 float 结果,写到 output 对应位置中。
为什么V Cache的layout是 [num_blocks, num_kv_heads, head_size, block_size],和 K Cache layout 不一样?这是因为 V 要去做点乘的对象在shared memory,只需要读,不涉及并行写的问题。
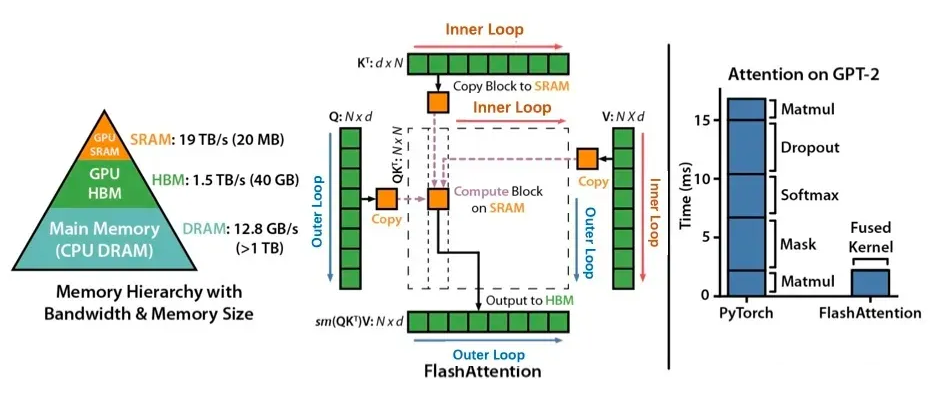
和 FlashAttention(FA)有什么不同?结合我的图和中间 FAv2 的流程图对比就一目了然了。FA 用了两层循环,每次写一个 Tile 的 output tensor,而 PA 一直只有一层循环,每次写一行 output tensor。因为每次都有整行的 QK^T 中间结果,不需要 online softmax 这种花哨技巧。
PAv1的问题
以我粗浅的理解指出几点 vLLM PAv1 的问题。一、和 MHA 相比,MQA 和 GAQ 没有减少对 KV Cache 的读写次数。读 K、V Cache 时候只是做了一个 head_idx 的转换,会重复从显存读相同的 head。二、对于 seq length 很长情况没法适应,因为没有沿着 ctx_length 或者 batch 维度做切分。这点 FlashAttention 和 FlashDecoding 就做了,因此 PAv2 借鉴了 FA 的切分思想。
总结
vLLM 的 paged attention v1 实现继承自 FasterTransformers MHA 实现,它和 FlashAttention 的并行任务划分方式不同。其中对 KVCache layout 的设计比较巧妙,充分利用了 shared memory 写带宽,是一种常用 CUDA 编程技巧。
审核编辑:刘清
-
寄存器
+关注
关注
31文章
5336浏览量
120224 -
Cache
+关注
关注
0文章
129浏览量
28329 -
内存管理
+关注
关注
0文章
168浏览量
14132 -
MQA
+关注
关注
0文章
3浏览量
6041
原文标题:vLLM皇冠上的明珠:深入浅出理解PagedAttention CUDA实现
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐






 工商网监
工商网监
评论