 AI服务器总体架构和关键技术
AI服务器总体架构和关键技术
本文来自“AI服务器白皮书(2023年)”,人工智能行业是对算力、算法和数据等数字资源进行创造、加工、整合,最终实现用机器替代人,为传统行业智慧赋能。算力、算法、数据是人工智能的三大要素。人工智能产业链包括三层:基础层、技术层和应用层。
(1)基础层:人工智能产业的基础,主要提供 AI 专有算力支持和开发环境的设备和服务,包括 AI 芯片、 系统开发框架、AI 服务器等基础设施等;
(2)技术层:在 AI 算力的支持下,通过系统开发框架进行各场景数据的训练和 学习,开发出计算机视觉、语音语义、知识图谱等 AI 算法,并将其搭载于硬件设备上形成行业级解决方案;
(3)应用层:针对不同的行业和场景,进行人工智能技术的商业化落地。
AI 服务器是人工智能基础层的核心物理设备,其面向深度学习神经网络需要的快速,低精度,浮点运算高度并行数值计算,搭载大量计算内核和高带宽内存资源,用于支撑深度学习训练和线上推理计算框架模型和应用,可以在多个节点之间高速互联、高效地扩展的硬件平台。有别于传统服务器以 CPU 提供主要算力,人工智能服务器多采用异构架构进行加速计算,常采用CPU+GPU、CPU+FPGA、CPU+ASIC 等多种形式。通过搭配不同的异构加速芯片,形成不同性能和可编程灵活性的人工智能算力硬件。目前广泛使用的 AI 服务器是 CPU+GPU。
通过 AI 服务器构成人工智能基础层的智能算力集群,联合智能模型平台和数据基础服务平台,支撑技术层和应用层的人工智能应用场景落地。随着大模型训练对云端算力的持续增长需求,AI 服务器部署规模越来越大,持续增长的计算速度和计算效率需求,推动着 AI 服务器的人工智能行业技术迭代。
(一)AI 服务器总体架构
随着人工智能和大模型应用的持续演进和广泛部署,“CPU+”架构已成为人工智能服务器的设计蓝本。
在这一架构中,CPU继续发挥其作为系统的中央处理单元的关键角色,负责任务的调度、系统管理和部分计算工作。然而,为了适应大模型和特定 AI 应用的计算密集性需求,服务器必须融合其他具有丰富计算核心的硬件加速器,能够在短时间内处理大量的数据和计算任务。
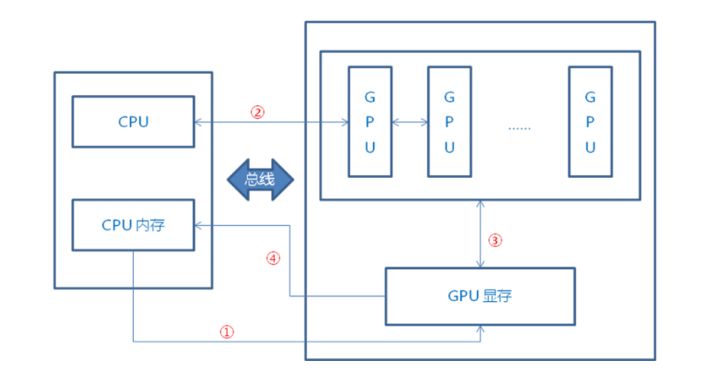
以人工智能计算领域中广泛使用的 GPU 计算部件为典型代表,详细描述了在现代“CPU+”架构中,人工智能加速部件与 CPU 的协同工作流程。在这种架构中,待处理的数据首先从 CPU 内存传输到GPU 的显存。这一步通常涉及大数据量的迁移,因此高带宽和低延迟的内存接口如 PCIe 和 NVLink 成为了优化的关键。一旦数据被载入显存,CPU 便开始向 GPU 发送程序指令。这些指令利用 GPU 的并行性能,驱动其多达数千的计算核心去执行。利用 GPU 的强大并行计算能力,显存中的数据会被快速处理。例如,在深度学习中,GPU可以并行处理大规模的矩阵乘法和卷积操作。计算完成后,结果存储在显存中,并在需要时传输回 CPU 内存。从“CPU+”这种架构的应用可以明显看出 CPU 的角色更偏向于指令协调和结果汇总,而实际上的高并行度计算任务则交给了 GPU 这类加速部件。这种分工策略符合 Amdahl 定律的观点:系统的总体性能提升受制于其最慢部分。
因此,通过优化可并行化的计算部分,将 CPU 和专门设计的硬件加速器如 GPU 结合,从而实现高效并行处理,满足日益增长的计算需求。
(二)异构计算加速计算芯片
异构计算指的是在一个计算系统中使用多种不同类型的处理器或核心来执行计算任务。这种方式旨在利用各种处理器的特定优势,以获得更高的性能或能效。
传统服务器系统内处理器以 CPU(即中央处理单元)为主。CPU 有很强的通用性,需要处理各种不同的数据类型,通常负责执行计算机和操作系统所需的命令和流程,因此其擅长无序超标量与复杂控制指令级的执行。
本轮人工智能热潮的理论基础是人工神经网络,为了更好地训练和使用深度神经网络,就需要对计算密集型大规模矩阵进行并行处理。CPU 的架构决定了其难以适用于大规模的人工智能计算。而异构计算加速器集成大量计算核心,简化逻辑控制单元设计,提升系统的并行计算性能。
当前异构计算加速器发展呈现多样化。人工智能芯片按照技术架构分类,可以划分为图像处理单元(GPU)、现场可编程门阵列(FPGA)、专用集成电路(ASIC)等。
GPU:AI 算力的核心
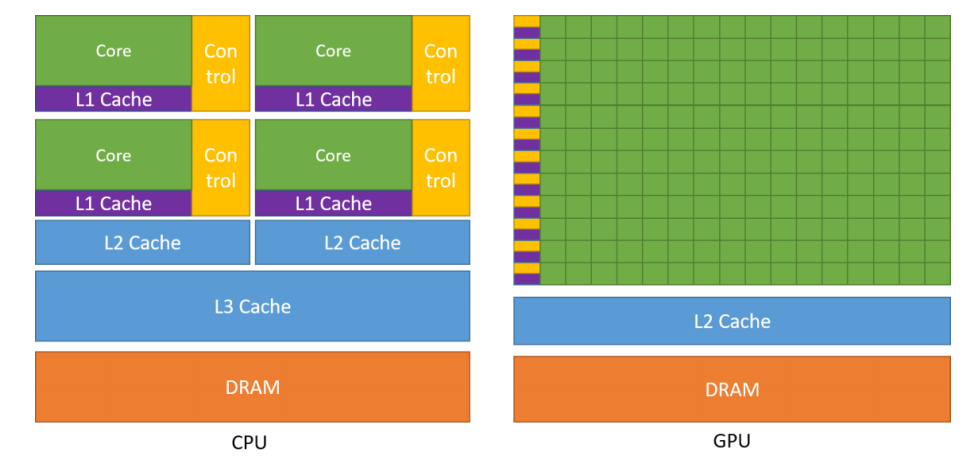
CPU 作为中央处理核心,其硬件架构中为了满足高性能和低 延 迟 的 需 求 , 特 地 增 强 了 高 速 缓 存 ( Cache ) 和 控 制 单 元(Control)的比例。相较之下,算术逻辑单元(ALU)在整体构造中所占的份额较小,这限制了 CPU 在大规模并行计算方面的表现。
GPU 的架构以计算单元为核心,采用了高度精简且高效的流水线设计,专为处理高度并行和线程化的计算任务而生,具有大规模并行计算的能力。
传统的 GDDR 显存模块通常焊接在 GPU 的 PCB 板上,这种配置可能会限制数据传输的速率和总存储容量。随着技术的发展,这些限制逐渐成为了图形处理性能的瓶颈。为了解决这个问题,HBM (High Bandwidth Memory) 技 术 应 运 而 生 。HBM 使用了 TSV(Through-Silicon Vias) 技术,允许多个 DRAM 芯片垂直堆叠起来,从而实现更高的数据带宽。HBM 与 GPU 核心的连接则是通过一个特殊的互连层实现,这不仅进一步提高了数据传输速率,而且大大减少了 PCB 的使用面积。
尽管 HBM 在带宽、体积和能效上都展现出了明显的优势,但由于其生产成本相对较高,GDDR 仍然是消费级 GPU 市场的主流选择。而在对性能和能效要求更高的数据中心环境中,HBM则得到了更广泛的应用。
(1) NVIDIA GPU
2022 年春季 GTC 大会上,英伟达发布其新款 NVIDIA GraceHopper 超级芯片产品,Hopper H100 Tensor Core GPU。
Tensor Cores 是专门针对矩阵乘法和累加(MMA)数学运算的高性能计算核心,为 AI 和 HPC 应用提供了开创性的性能。当 TensorCores 在一个 NVIDIA GPU 的多个流多处理器(SM)中并行操作时,与标准的浮点数(FP)、整数(INT)和融合乘法-累加(FMA)运算相比,它们能够大幅提高吞吐量和效率。
(2)英特尔 Gaudi2 GPU
Gaudi2 深度学习加速器,以第一代 Gaudi 高性能架构为基础,以多方位性能与能效比提升,加速高性能大语言模型运行。具备:24 个可编程 Tensor 处理器核心(TPCs);21 个 100Gbps(RoCEv2)以太网接口;96GB HBM2E 内存容量;2.4TB/秒的总内存带宽;48MB片上 SRAM。
Gaudi2 处理器提供 2.4T 的网络带宽,片上集成 24 x 100 GbpsRoCE V2 RDMA 网卡,可通过标准以太交换或直连路由实现 Gaudi 芯片内部通信;Gaudi2 的内存子系统包括 96 GB 的 HBM2E 内存,提供2.45 TB/秒的带宽,此外还有 48 MB 的本地 SRAM,带宽足以允许 MME、TPC、DMAs 和 RDMA NICs 并行操作;支持 FP32,TF32,BF16,FP16 和FP8。
通过在 GPT-3 模型上的测试,以及相关 MLPerf 基准测试结果,为 Gaudi2 提供了卓越性能和高效可扩展性的有力验证。
(3)海光 DCU
目前海光研发的 DCU 达 64 个内核,每个内核包含 4 个 SIMT 运算单元和 1 个标量整型运算单元,每个 SIMT 包含多个可配置浮点乘加运算单元,SIMT 的每个指令周期内可以并行处理 64 个独立的运算线程。这种多内核多线程的 SIMT 架构,可以保证 DCU 每个时钟周期完成 4096 次高精度浮点乘加运算。
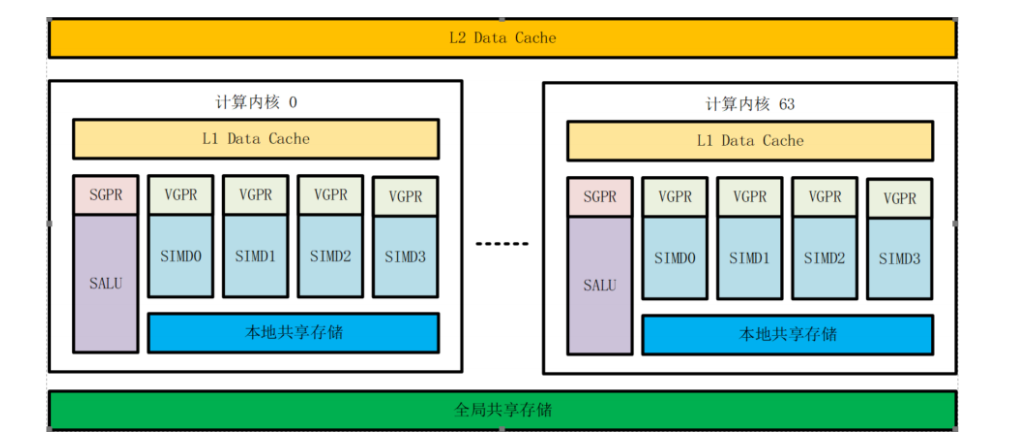
海光 DCU 具有生态友好、精度覆盖、安全筑底,三大特点。目前海光 DCU 与 Hygon、Intel、AMD 等 CPU 平台服务器整体兼容,与国内外主流 OS 全面适配。同时,与绝大部分主流框架(包括 TensorFlow、Pytorch、PaddlePaddle等)和算法模型(包括机器学习、深度学习 CV 与 NLP、大模型等)全面适配,并进行了大规模部署和上百个大型应用场景的验证。
(4)沐曦
MXC500 是沐曦第一代通用 GPU 计算卡产品,基于自研 IP 进行芯片设计,MXC500 采用通用 GPU 技术路线,通过内置大量并行计算单元实现人工智能等领域上层应用的并行计算加速。一方面,GPU 架构相比 CPU 等串行计算硬件能够实现大幅度的计算加速;另一方面,GPU 架构相比包括 NPU、DSA 等的 ASIC 计算芯片具有更好的通用性,能够适应广泛的应用领域和计算场景,并能够针对 AI 算法的进步实现快速的跟进创新。
MXC500 采用纯自研通用 GPU 架构,如下图,核心计算单元由8个DPC(Data Processing Cluster,数据处理组)组成,每个 DPC 包含大量 AP(Acceleration Processor,加速处理器),从而实现大规模并行计算加速。在 GPU 内部,Command Engine 负责将并行计算任务以线程(thread)为单位分发到不同的 AP 中进行处理,核心计算单元与内部的寄存器、L1 缓存、L2 缓存构成高速的数据通路,并通过高速数据总线与 PCIe 单元、多卡互联(采用私有协议 MetaXLink)、存储控制器、DMA(直接内存读取,Direct MemoryAccess)等外围电路模块进行通信。
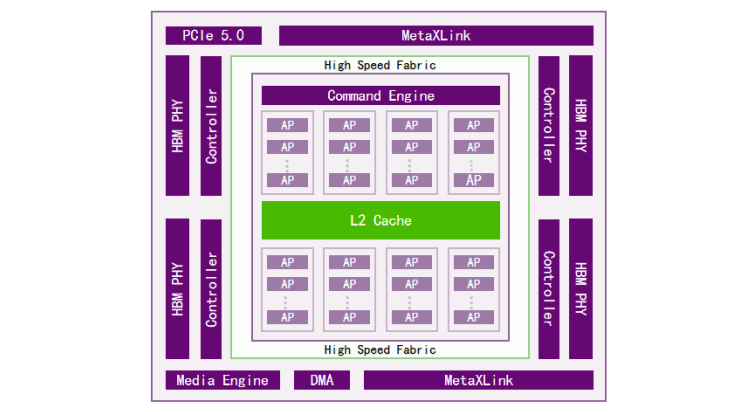
MXC500 内置 4 颗 HBM2e 颗粒,通过 2.5D 封装技术与核心计算芯粒封装到同一颗芯片内部。HBM2e 总容量为 64GB,带宽高达1.55TB/s。MXC500 通过沐曦自研的私有化通信协议 MetaXLink实现多GPU之间的直接互联,能够支持最多单机8卡全互联的拓扑。
审核编辑:汤梓红
-
gpu
+关注
关注
28文章
4729浏览量
128890 -
服务器
+关注
关注
12文章
9123浏览量
85324 -
AI
+关注
关注
87文章
30728浏览量
268886 -
人工智能
+关注
关注
1791文章
47183浏览量
238246
原文标题:GPU:AI服务器关键技术及核心
文章出处:【微信号:AI_Architect,微信公众号:智能计算芯世界】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
浅析AI服务器与普通服务器的区别
AI服务器的应用场景有哪些?

一文解析AI服务器技术 AI服务器和传统通用服务器的区别
AI服务器与传统服务器的区别是什么?
AI服务器架构的五大硬件拆解
物理服务器对ai发展的应用
AI服务器的特点和关键技术
什么是AI服务器?AI服务器的优势是什么?
GPU服务器AI网络架构设计






 工商网监
工商网监
评论