 高分工作!Uni3D:3D基础大模型,刷新多个SOTA!
高分工作!Uni3D:3D基础大模型,刷新多个SOTA!
我们近期的工作:3D视觉大模型Uni3D在ICLR 2024的评审中获得了688分,被选为Spotlight Presentation

在本文中,我们第一次将3D基础模型成功scale up到了十亿(1B)级别参数量,并使用一个模型在诸多3D下游应用中取得SoTA结果。代码和各个scale的模型(从6M-1B)均已开源,欢迎大家关注和使用:
论文:https://https://arxiv.org/pdf/2310.06773
代码:https://https://github.com/baaivision/Uni3D

我们主要探索了3D视觉中scale up模型参数量和统一模型架构的可能性。在NLP / 2D vision领域,scale up大模型(GPT-4,SAM,EVA等)已经取得了很impressive的结果,但是在3D视觉中模型的scale up始终没有成功。我们旨在将NLP/2D中scale up的成功复现到3D表征模型上。

在这项工作中,我们提出了一个3D基础大模型Uni3D,直接将3D backbone统一为ViT(Vision Transformer),以此利用丰富和强大的2D预训练大模型作为初始化。Uni3D使用CLIP模型中的文本/图像表征作为训练目标,通过学习三个模态的表征对齐(点云-图像-文本)实现3D点云对图像和文本的感知。同时,通过使用ViT中成功的scale up策略,我们将Uni3D逐步 scale up,训练了从Tiny到giant的5个不同scale的Uni3D模型,成功地将Uni3D扩展到10亿级别参数。
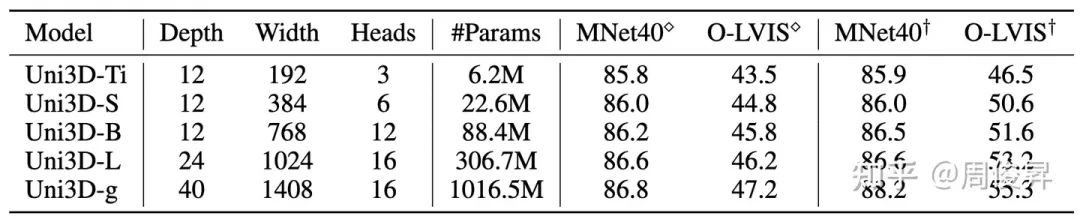
Uni3D模型不同scale下的参数量和zero-shot分类结果
Uni3D在多个3D任务上达到SoTA,如:zero-shot classification, few-shot classification,open-world understanding, open-world part segmentation.
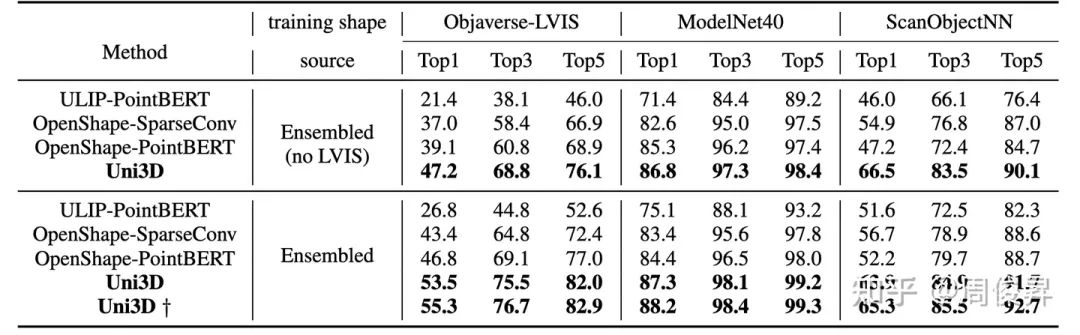
Zero-shot classification
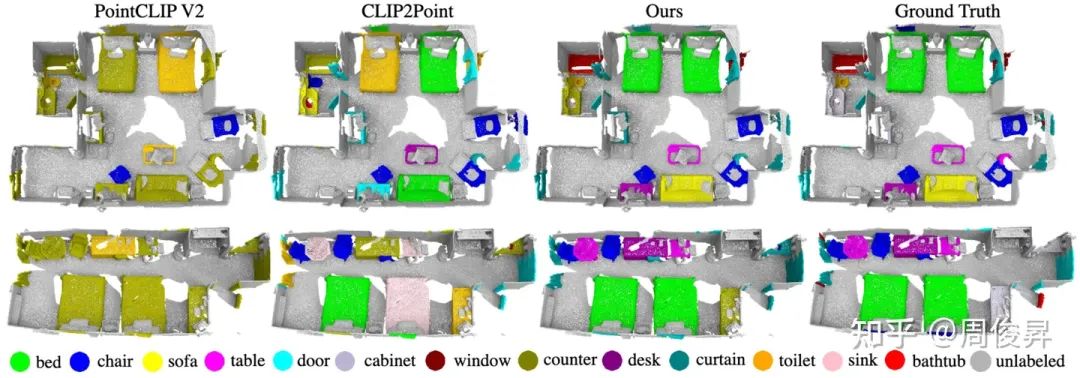
Real-world zero-shot recognition
由于学到了强大的多模态表征能力,Uni3D还能够做一些有意思的应用,如point cloud painting(点云绘画),text/image-based 3D shape retrieval(基于图像/文本的3D模型检索),point cloud captioning(点云描述):

Point cloud painting

Image-based 3D shape retrieval

Text-based 3D shape retrieval

Point cloud captioning.
- 3D视觉
+关注
关注
4文章
420浏览量
27396 - 大模型
+关注
关注
2文章
2066浏览量
1803
原文标题:ICLR 2024 | 高分工作!Uni3D:3D基础大模型,刷新多个SOTA!
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先登录
相关推荐
安宝特产品 安宝特3DAnalyzer:智能的3DCAD高级分析工具
欢创播报 腾讯元宝首发3D生成应用

裸眼3D笔记本电脑——先进的光场裸眼3D技术
包含具有多种类型信息的3D模型
Stability AI推出全新Stable Video3D模型
探索ICLR‘24 Spotlight中的首个十亿级别3D通用大模型

3D人体生成模型HumanGaussian实现原理
CASAIM沙盘模型3D打印的优势和应用



PADS VX2.7 下载安装及3D模型导入的注意事项
HT for Web (Hightopo) 使用心得(4)-3D场景 Graph3dView 与 Obj模型






 工商网监
工商网监
评论