 请问高端网络芯片如何处理数据包呢?
请问高端网络芯片如何处理数据包呢?
*本文系SDNLAB编译自瞻博网络技术专家兼高级工程总监Sharada Yeluri的博客
随着网络芯片带宽的持续提升,其内部数据包处理单元的工作负载也随之增加。然而,如果处理单元无法与网络接口的传入速率相匹配,将无法及时处理数据包,这不仅会导致数据包随机丢失,更会降低网络的吞吐量。
本文将深入探讨与数据包处理相关的各项工作和挑战,分析处理单元吞吐量的需求演变,以及在网络芯片中执行这些功能的多种方法和技术。
数据包处理
网络芯片中的数据包处理是指,当网络数据包通过路由器、交换机或防火墙中的芯片时,芯片对网络数据包执行的一系列操作。网络芯片主要检查数据包的L2/L3报头信息。从宏观层面来看,数据包处理的主要功能可以概述如下:
解析
第一步是对数据包报头进行分析,以了解其结构和所采用的协议(如以太网、VLAN、IP、TCP/UDP 以及现有的封装)。解析过程中会识别出后续处理步骤中需要使用的关键字段,例如源地址和目标地址、端口号和协议类型。
封装是网络通信中的一种常见做法,即在数据包外部添加额外的一层报头信息,通常是为了提供额外的功能,例如安全性(在 VPN 的情况下)和隧道(如 GRE 或 VXLAN)。这样就形成了具有外部报头和一个/多个内部报头的数据包。在这种情况下,解析逻辑需要同时检查外部报头和内部报头。此功能对于严重依赖封装技术对网络流量进行分段、保护和管理的现代网络基础设施至关重要。
分类
首先要确定数据包的来源。
数据包的来源包括其主机身份、接收接口(逻辑和物理)及其转发域。通常,会执行第 2 层地址和数据包进入的物理接口之间的绑定检查。然后根据数据包的报头字段(例如源/目标 IP 地址、端口号和协议类型)对数据包进行分类。分类决定了如何处理数据包,例如应用哪些服务质量 (QoS) 策略。
隧道终止
通过比较隧道报头字段与隧道端点信息,逻辑确定是否需要终止隧道。
对于需要终止的隧道,其封装的数据包将被解封装,恢复到原始格式后再被发送至最终目的地。外部/内部报头有许多变体,网络芯片可以根据其部署用例支持不同的隧道终止子集。一些常见的受支持的隧道技术包括 MPLS、VXLAN、GRE、MPLSoverUDP、IPinIP 等。
过滤
许多设备通过访问控制列表 (ACL) 实现数据包过滤。ACL通常由一组规则(即ACL条目)组成,每个ACL条目定义了一种访问控制策略,包括允许或拒绝特定类型的流量或访问请求。ACL通常基于源地址、目标地址、协议类型、端口号、时间等条件来控制网络访问。
路由查找
根据数据包的目标地址和路由表,处理器决定数据包的下一跳,并据此进行转发。这一过程涉及对 IPv4/IPv6 数据包执行最长前缀匹配查找,以及在转发 MPLS 数据包时执行索引查找,或者在基于目标 MAC 地址进行 L2 转发时进行精确匹配。查找结果可以直接指示数据包应离开的发送接口,或者指向一系列下一跳指令,这些指令被执行后将找到正确的发送接口。
下一跳处理
下一跳处理(执行存储在大内存中的一系列下一跳指令)决定了如何将数据包转发到其目的地。该处理过程会得出数据包必须离开的目标端口、实现ECMP 或 LAG 的负载平衡,以及确定推送或交换的 MPLS标签等。此外,数据包可选择性地执行策略控制和计数。
重写
最后一步,数据包报头将被修改以剥离封装报头(在隧道终止的情况下)、更新TTL 递减、V4 校验和更新、时间戳更新等。
入站数据包处理
在入站数据包处理完成后,如果目标队列拥塞,或者该数据包被选择为 WRED 丢弃对象,则数据包可能会被丢弃。当数据包被允许转发时,它会在片上缓冲区或外部内存缓冲区内排队等待。无论是入站处的数据包排队/出站的可选排队,还是出站调度,这些过程都极大地依赖于网络芯片的架构特性。
出站数据包处理
当数据包从缓冲区中读出,并准备离开出站接口时,它会在出站阶段进行进一步的处理,以便在传输前对数据包进行必要的修改。这些修改包括添加新的 L2 报头和/或 VLAN 标签、封装(当网络设备位于隧道入口点时)、添加 MPLS 标签等。此外,数据包还可以选择性地通过出站过滤/策略执行。这些实现方式因设备而异。
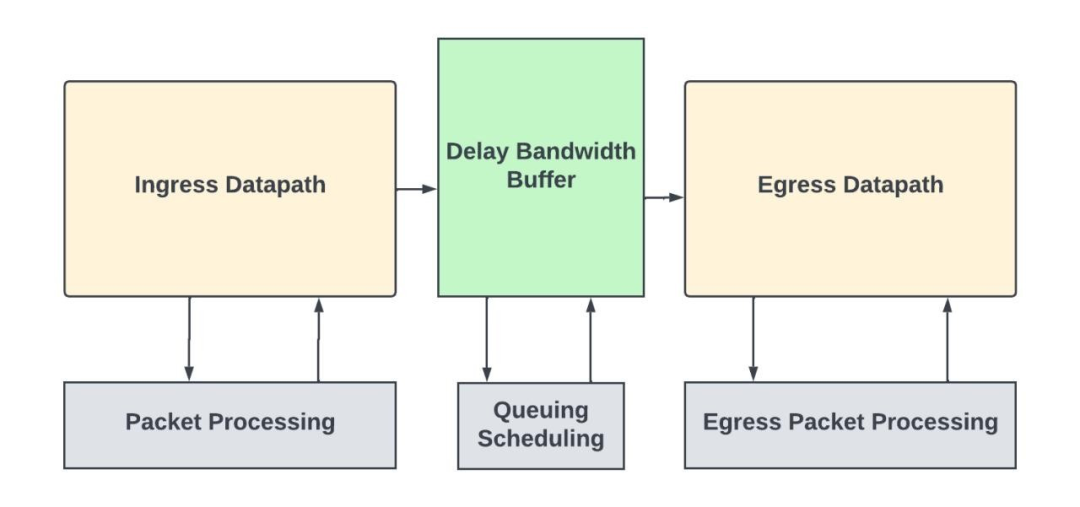
具有入站/出站数据路径和数据包处理子系统的独立网络交换机
大型路由器可以使用多个模块化路由芯片通过switch fabric相互连接,这些模块化路由芯片可使用术语“数据包转发实体(PFE)”来指代。在这些系统中,入站数据包处理发生在网络流量进入的 PFE 中,出站数据包处理发生在流量离开的 PFE 中。
数据包处理实现
数据包处理的实现方式取决于所需的灵活性、设备的总吞吐量、以及该功能的功耗/性能/面积预算。
专用处理引擎
大约二十年前,随着网络协议快速演化,新的可选/扩展报头和隧道标准也随之涌现。数据包的处理是通过大量高度灵活且可编程的专用处理引擎实现的。这些专用处理引擎通常包含存储在片上和/或片外指令存储器中的微码指令。与RISC和 X86 指令集不同,微码是一种低级指令集,通常以非常长的指令字 (VLIW)的形式打包。处理引擎通过这些微码指令序列解析存储在本地存储器中的数据包头的不同字段,以确定数据包的结构,并执行上述所有入站和出站处理功能。处理引擎的硬件并不了解任何网络协议,它只是盲目地执行指令以形成新的数据包头并计算输出接口。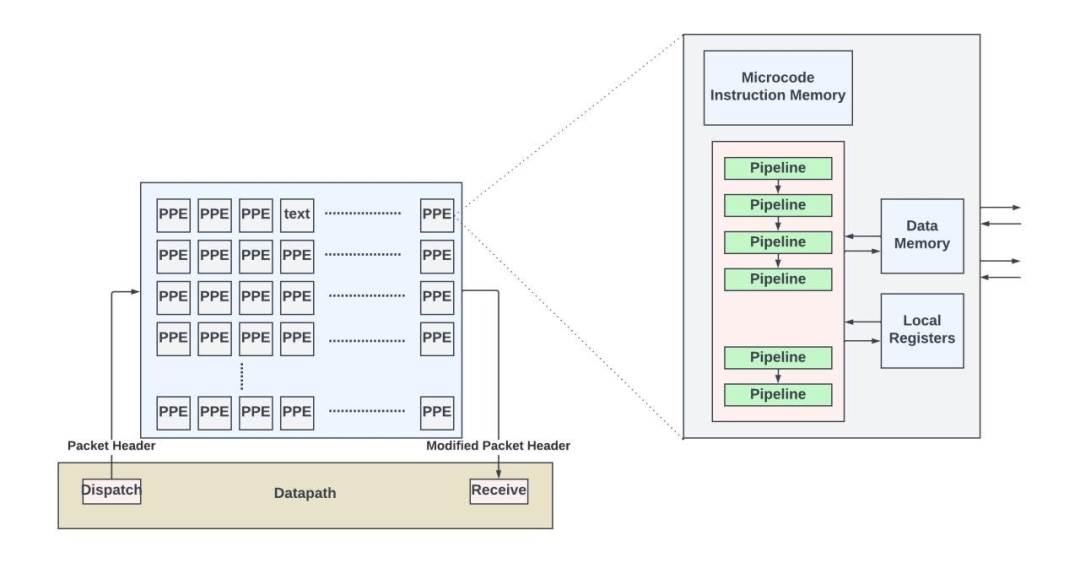
用于数据包处理的PPE
虽然基于微码的处理提供了无限的灵活性,但在芯片面积或每 Gbps 功耗方面效率较低。在混合方法中,一些功能(如过滤/最长前缀匹配查找、策略执行等)可以在硬件本地(硬件加速器)中实现,同时使用微代码指令进行数据包解析和其余的数据包转发功能。
数据包处理Pipeline
随着高端芯片开始封装更多的 WAN 带宽,混合方法无法满足每 Gbps 的功率/面积目标。十多年前,一些网络供应商开始使用硬件pipeline(同时以本地/功能特定的指令/排序操作的形式提供有限的灵活性)本地实现所有数据包处理功能。
下图是基于Juniper的Express Architecture pipeline实现的入站数据包处理pipeline的概念图。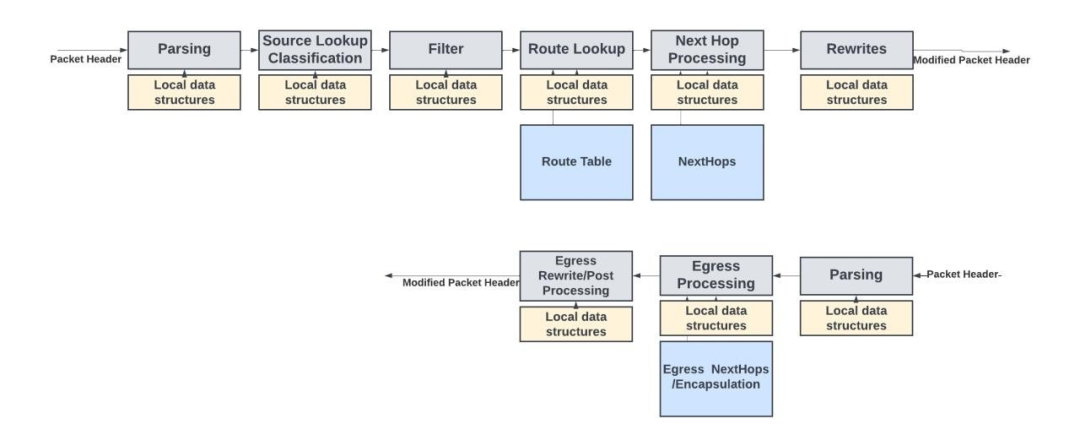
入站和出站数据包处理pipeline及其数据结构
该pipeline包含一系列后续块或模块,其中每个模块负责上文描述的特定功能。通常,整个数据包存储在数据路径存储器中,而报头(通常是数据包的前128字节)则通过数据包处理pipeline。由于数据包处理只关注 L4 的报头信息,因此不需要通过pipeline发送整个数据包。
根据吞吐量需求的不同,数据包报头以每周期一个数据包的速率或更低的速率通过pipeline发送。每个模块都有许多存储在 SRAM中的本地数据结构/配置。
Pipeline的灵活性
网络是一个不断发展的领域,为了适应新技术和新需求,经常会开发/标准化新协议和现有协议的扩展。从新的RFC 标准发布到其实际在网络芯片中得到应用,通常会有3-4 年的延迟时间。这就是为什么在这些pipeline中具有一定的灵活性非常重要。
例如,除了对已知的L2-L4报头的标准解析之外,硬件还可以支持灵活的解析功能,以解析未来的协议报头或现有协议的扩展。这可以通过一系列CAM(内容可寻址存储器)和规则集来实现,它们指定了要查找新协议的Type/Length/Value字段的字节偏移量。
并非所有的网络应用程序都经过相同的数据包处理。例如,某些数据包可能需要多次查找。第一次查找可能是 LPM(最长前缀匹配)查找,以确定数据包的下一个目的地。第二次查找可能涉及更具体的路由策略,比如基于策略的路由,其中决策基于数据包中的其他字段或应用类型。
类似地,在 MPLS 网络中,第一次查找可能涉及读取 MPLS 标签以在 MPLS 网络内做出转发决策。当数据包到达 MPLS 网络的边缘,并且标签被弹出时,需要进行第二次查找,以便根据数据包的原始 IP 报头确定数据包的下一跳。
Express 数据包处理pipeline中的查找功能提供了这样的选项,其中第一次查找的操作可以指示后续的查找,并且报头循环回查找函数的开头以进行下一次查找。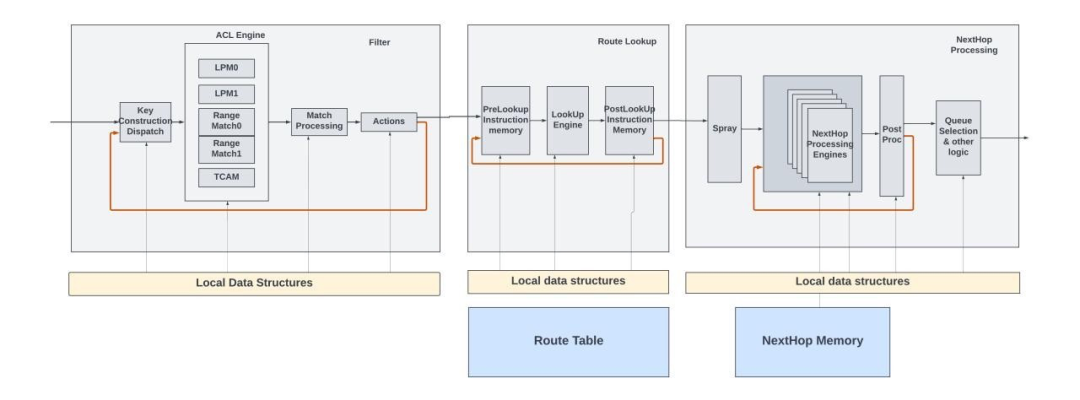
数据包如何在每个查找模块内循环
需要注意的是,在数据包处理pipeline中,因为每个数据包都经过不同的pipeline并具有不同数量的查找、过滤器和下一跳操作,因此无法不会保持数据包的原有顺序。网络设备必须确保同一数据流中的数据包不会被打乱顺序。粗略地判断数据流的方式是以数据包进入的输入端口/接口为准。而更为精细的判断方法则是查看数据包的五元组,并通过计算哈希函数来确定数据流。pipeline末端的重排序引擎可以将数据包重新按照每个端口或每个数据流的顺序排列好。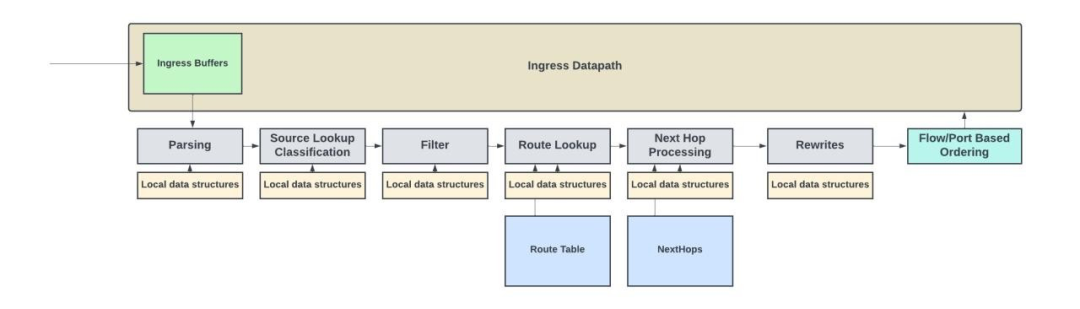
带有重排序引擎的数据包处理pipeline
再循环
在某些封装中,报头字节可能会超过 128B。对于那些在初次传递中无法检测到内部报头的情况,数据包需经历如下步骤:首先在剥离已解析的报头字节,接着从入口内存中读取额外的报头字节,并将新报头再次发回处理pipeline进行处理。在接下来的循环中,将重复处理步骤以处理内部报头。
再循环应用的示例包括MPLS over UDP,其中需要处理两个以上的堆栈,以及基于防火墙的隧道解封装。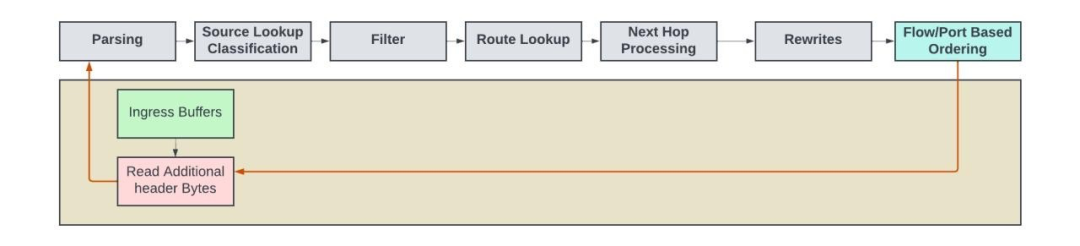
再循环的概念图
吞吐量
网络芯片所需的每秒数据包处理速率与能够进入设备的最小数据包大小(通常是 64B 以太网帧)、数据包间隙 (IPG) 以及设备的总 WAN 吞吐量成正比。
Packets per second = (bits/second) / (bits /packet + IPG/packet)
假设一个3.2Tbps 的设备需要处理连续到来的 64B 数据包,若要跟上这种处理节奏,在1GHz的时钟频率下,每周期几乎需要处理近5个数据包。由于每个pipeline最多只能每周期处理一个数据包,这意味着在这种情况下需要约5个数据包处理pipeline。就面积和功率而言,是相当昂贵的。
3.2Tbps 设备要满足 64B 数据包的线路速率需要 5 个pipeline
在实际网络流量中,平均数据包大小通常大于 64B。大多数流量通常使用最大传输单元 (MTU) 大小的数据包来最大化吞吐量。设计针对平均常用数据包大小优化的数据包处理引擎有助于实现更优的设计,有效利用芯片面积。那么,我们如何确定平均数据包大小呢?
一种方法是检查网络性能测试中使用的各种 IMIX 模式。
IMIX( Internet MIX)是网络性能测试中使用的概念,用于更准确地vwin
现实世界中的互联网流量模式。IMIX不使用统一的数据包大小,而是采用多种数据包大小的组合来代表互联网流量的多样性。例如,IMIX 可能包含小型数据包(64 字节,常见于 ACK 或控制消息)、中型数据包(大约 576 字节,通常用于特定应用数据)和大型数据包(大约 1500 字节,),并且它们之间有一定的分布比例。
对于 IMIX 数据包大小分布并没有一个普遍接受的标准。不同的组织可能会根据其特定需求和对网络流量的观察,定义自己的 IMIX 配置文件。谷歌和 Meta 在评估网络设备时都有自己的 IMIX 模式。
假设数据包处理需要以线速处理平均约 345 B大小的数据包,并在1.1GHz的时钟频率下运行,那么只需一条pipeline即可满足需求!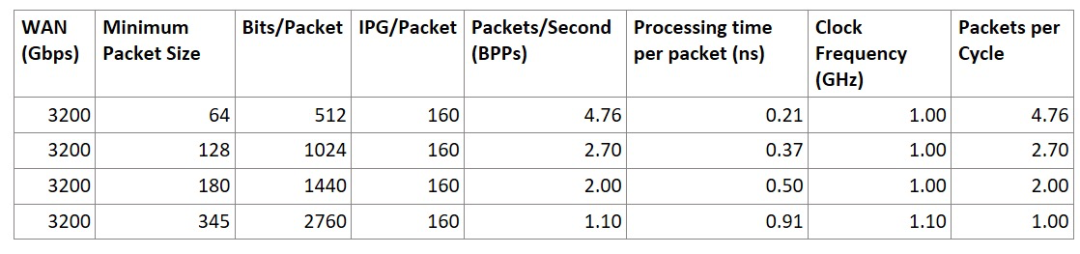
该表显示了增加平均数据包大小以满足线路速率时,如何减少pipeline数量
为了应对互联网流量可能存在突发性的特点,以及可能出现瞬态场景,即平均数据包大小小于350B,且有许多连续的小数据包涌入,这就需要在数据包处理输入端增设一个突发吸收缓冲区(即图中所示的入口缓冲区)。一旦这个缓冲区开始填满,硬件就可以执行优先级感知丢弃策略,即给予控制/保活数据包更高的优先级。丢弃策略的具体规定因供应商而异。
在上一代 Express Silicon (Express4) 中,为了实现3.2Tbps处理能力,并使得平均数据包大小达到约180B,决定增加两条pipeline。如下图所示,在实现这两条pipeline时,它们可以共享本地数据结构、路由表和下一跳内存资源。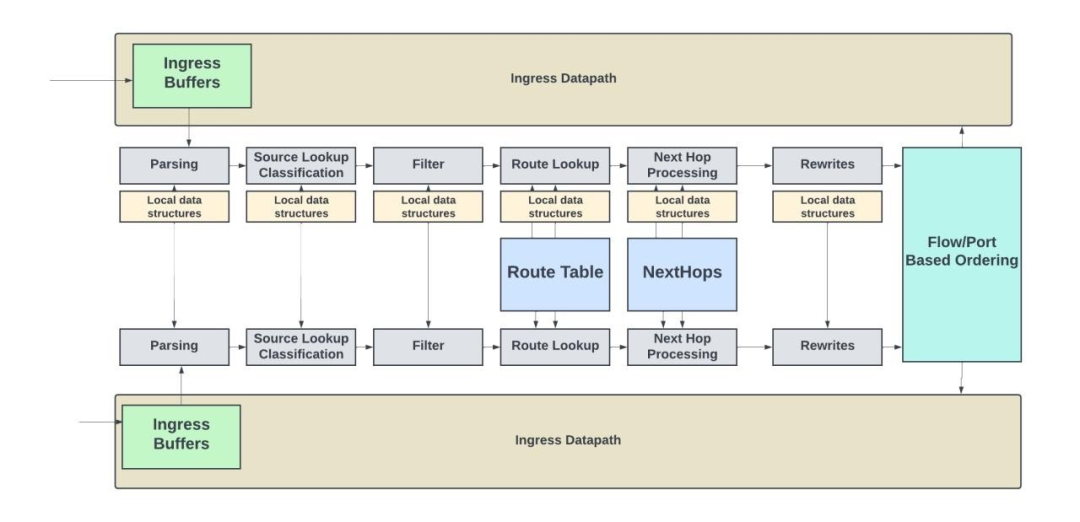
总结
本文阐述了高端路由器中数据包处理引擎所使用的技术,以实现每秒数十亿数据包的高性能处理,同时提供足够的处理灵活性。从宏观层面概述了数据包处理的基本原理,讨论了其如何随着时间演变,以及网络芯片供应商在不断增加广域网带宽时面临的吞吐量扩展挑战。
审核编辑:刘清
- 处理器
+关注
关注
68文章
18807浏览量
226410 - 以太网
+关注
关注
40文章
5254浏览量
168998 - 路由器
+关注
关注
22文章
3633浏览量
112576 - VLAN
+关注
关注
1文章
260浏览量
35398 - 网络芯片
+关注
关注
0文章
30浏览量
12079
原文标题:高端网络芯片如何处理数据包?
文章出处:【微信号:SDNLAB,微信公众号:SDNLAB】欢迎添加关注!文章转载请注明出处。
发布评论请先登录
相关推荐
Linux系统收发网络数据包的工作过程

DPDK在AI驱动的高效数据包处理应用
请问,CAN发送数据出现数据包丢失的情况
请问在串口通信中数据包的帧头和帧尾怎样加入到数据包?
网络数据包捕获机制研究
基于Jpcap的数据包捕获器的设计与实现
什么是数据包?
深度数据包检测技术研究
基于数据包长度的网络隐蔽通道
网络数据包分析软件wireshark的基本使用
Wireshark网络数据包分析软件简介
简述Linux系统收发网络数据包的过程







 工商网监
工商网监
评论