 简单三步使用OpenVINO™搞定ChatGLM3的本地部署
简单三步使用OpenVINO™搞定ChatGLM3的本地部署
工具介绍
英特尔OpenVINO 工具套件是一款开源AI推理优化部署的工具套件,可帮助开发人员和企业加速生成式人工智能 (AIGC)、大语言模型、计算机视觉和自然语言处理等 AI 工作负载,简化深度学习推理的开发和部署,便于实现从边缘到云的跨英特尔 平台的异构执行。
ChatGLM3是智谱AI和清华大学KEG实验室联合发布的对话预训练模型。ChatGLM3-6B是ChatGLM3系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B引入了以下新特性:
1
更强大的基础模型:
ChatGLM3-6B的基础模型ChatGLM3-6B-Base采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,ChatGLM3-6B-Base具有在10B以下的预训练模型中领先的性能。
2
更完整的功能支持:
ChatGLM3-6B采用了全新设计的Prompt格式,除正常的多轮对话外,同时原生支持工具调用 (Function Call)、代码执行 (Code Interpreter) 和Agent任务等复杂场景。
3
更全面的开源序列:
除了对话模型ChatGLM3-6B外,还开源了基础模型ChatGLM-6B-Base、长文本对话模型ChatGLM3-6B-32K。以上所有权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。

图:基于Optimum-intel与OpenVINO部署生成式AI模型流程
英特尔为开发者提供了快速部署ChatGLM3-6B的方案支持。开发者只需要在GitHub上克隆示例仓库,进行环境配置,并将Hugging Face模型转换为OpenVINO IR模型,即可进行模型推理。由于大部分步骤都可以自动完成,因此开发者只需要简单的工作便能完成部署,目前该仓库也被收录在GhatGLM3的官方仓库和魔搭社区Model Card中,接下来让我们一起看下具体的步骤和方法:
示例仓库:
https://github.com/OpenVINO-dev-contest/chatglm3.openvino
官方仓库:
https://github.com/THUDM/ChatGLM3?tab=readme-ov-file#openvino-demo
Model Card:
https://www.modelscope.cn/models/ZhipuAI/chatglm3-6b/summary#
1
模型转换
当你按仓库中的README文档完成集成环境配置后,可以直接通过以下命令运行模型转换脚本:
python3 convert.py --model_id THUDM/chatglm3-6b –output {your_path}/chatglm3-6b-ov
该脚本首先会利用Transformers库从Hugging Face的model hub中下载并加载原始模型的PyTorch对象,如果开发者在这个过程中无法访问Hugging Face的model hub,也可以通过配置环境变量的方式,将模型下载地址更换为镜像网站,并将convert.py脚本的model_id参数配置为本地路径,具体方法如下:
$env:HF_ENDPOINT = https://hf-mirror.com
huggingface-cli download --resume-download --local-dir-use-symlinks False THUDM/chatglm3-6b --local-dir {your_path}/chatglm3-6b
python3 convert.py --model_id {your_path}/chatglm3-6b --output {your_path}/chatglm3-6b-ov
当获取PyTorch的模型对象后,该脚本会利用OpenVINO的PyTorch frontend进行模型格式的转换,执行完毕后,你将获取一个由.xml和.bin文件所构成的OpenVINO IR模型文件,该模型默认以FP16精度保存。
2
权重量化
该步骤为可选项,开发者可以通过以下脚本,将生成的OpenVINO模型通过权重量化策略,进一步地压缩为4-bits或者是8-bits的精度,以获取更低的推理延时及系统资源占用。
python3 quantize.py --model_path {your_path}/chatglm3-6b-ov --precision int4 --output {your_path}/chatglm3-6b-ov-int4
执行完毕后,你将获得经过压缩后的IR模型文件,以INT4对称量化为例,该压缩后的模型文件的整体容量大约为4GB左右。
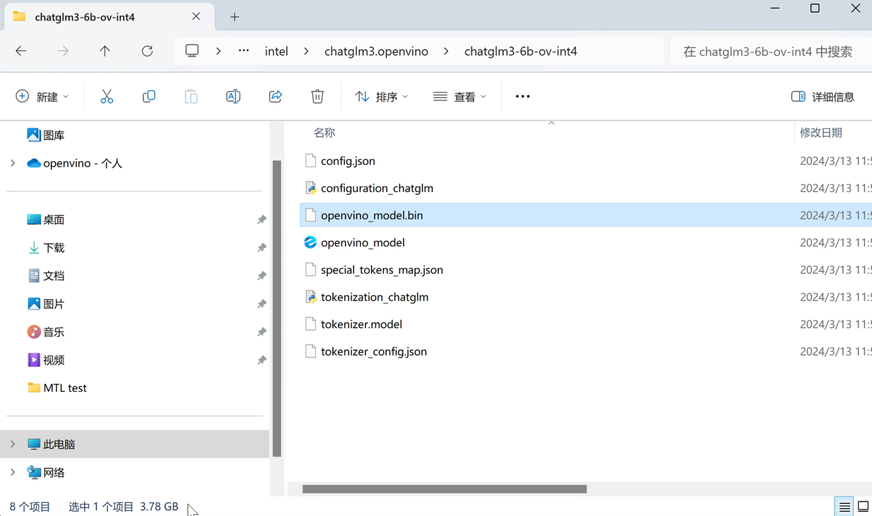
图:量化后的OpenVINO模型文件
同时在量化结束后,亦会在终端上打印模型的量化比例,如下图所示。

图:量化比例输出
由于OpenVINO NNCF工具的权重压缩策略只针对于大语言模型中的Embedding和Linear这两种算子,所以该表格只会统计这两类算子的量化比例。其中ratio-defining parameter是指我们提前通过接口预设的混合精度比例,也就是21%权重以INT8表示,79%以INT4表示,这也是考虑到量化对ChatGLM3模型准确度的影响,事先评估得到的配置参数,开发者亦可以通过这个示例搜索出适合其他模型的量化参数。此外鉴于第一层Embedding layer和模型最后一层操作对于输出准确度的影响,NNCF默认会将他们以INT8表示,这也是为何all parameters中显示的混合精度比例会有所不同。当然开发者也可以通过nncf.compress_weights接口中设置all_layers=True,开关闭该默认策略。
示例:
https://github.com/openvinotoolkit/nncf/tree/develop/examples/llm_compression/openvino/tiny_llama_find_hyperparams
3
模型转换
最后一步就是模型部署了,这里展示的是一个Chatbot聊天机器人的示例,这也是LLM应用中最普遍,也是最基础的pipeline,而OpenVINO可以通过Optimum-intel工具为桥梁,复用Transformers库中预置的pipeline,因此在这个脚本中我们会对ChatGLM3模型再做一次封装,以继承并改写OVModelForCausalLM类中的方法,实现对于Optimum-intel工具的集成和适配。以下为该脚本的运行方式:
python3 chat.py --model_path {your_path}/chatglm3-6b-ov-int4 --max_sequence_length 4096 --device CPU
如果开发者的设备中包含英特尔的GPU产品,例如Intel ARC系列集成显卡或是独立显卡,可以在这个命令中将device参数改为GPU,以激活更强大的模型推理能力。
在终端里运行该脚本后,会生成一个简易聊天对话界面,接下来你就可以验证它的效果和性能了。
总结
通过模型转换、量化、部署这三个步骤,我们可以轻松实现在本地PC上部署ChatGLM3-6b大语言模型,经测试该模型可以流畅运行在最新的Intel Core Ultra异构平台及至强CPU平台上,作为众多AI agent和RAG等创新应用的核心基石,大语言模型的本地部署能力将充分帮助开发者们打造更安全,更高效的AI解决方案。
审核编辑:刘清
-
人工智能
+关注
关注
1791文章
47182浏览量
238195 -
计算机视觉
+关注
关注
8文章
1698浏览量
45967 -
pytorch
+关注
关注
2文章
807浏览量
13196 -
OpenVINO
+关注
关注
0文章
92浏览量
196
原文标题:简单三步使用OpenVINO™ 搞定ChatGLM3的本地部署 | 开发者实战
文章出处:【微信号:英特尔物联网,微信公众号:英特尔物联网】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
用Ollama轻松搞定Llama 3.2 Vision模型本地部署

使用OpenVINO Model Server在哪吒开发板上部署模型
使用OpenVINO 2024.4在算力魔方上部署Llama-3.2-1B-Instruct模型
用OpenVINO C# API在intel平台部署YOLOv10目标检测模型

简单三步!高效预测半导体器件使用寿命
【AIBOX】装在小盒子的AI足够强吗?

Optimum Intel三步完成Llama3在算力魔方的本地量化和部署
简单两步使用OpenVINO™搞定Qwen2的量化与部署任务

英特尔集成显卡+ChatGLM3大语言模型的企业本地AI知识库部署
如何在MacOS上编译OpenVINO C++项目呢?

三步完成在英特尔独立显卡上量化和部署ChatGLM3-6B模型
ChatGLM3-6B在CPU上的INT4量化和部署





 工商网监
工商网监
评论