 SiMa.ai推出针对Edge AI调整的SoC
SiMa.ai推出针对Edge AI调整的SoC
面临的主要技术挑战之一是边缘计算:如何在资源受限的嵌入式设备上执行计算密集型人工智能任务。在这种追求中,硬件和软件从根本上相互矛盾,因为设计人员试图同时平衡低功耗、低成本和高性能。
机器学习硬件初创公司SiMa.ai现在正试图通过设计“软件优先”的硬件来应对这一挑战,以实现前所未有的边缘AI性能。本周,SiMa.ai发布了他们的新MLSoC平台,这是一个以ML为中心的SoC,旨在使边缘AI比以往任何时候都更加直观和灵活。
在本文中,我们将讨论边缘AI的现状,以及SiMa.ai的新平台希望如何解决其一些缺点。
Edge AI的现状
当谈到将AI带到边缘时,也被称为TinyML,这个过程通常非常以硬件为中心。
通常,边缘AI的挑战在于设备资源非常有限,RAM、处理能力和电池寿命有限。因此,TinyML的设计过程通常围绕着将机器学习模型定制为设备的大多数预定硬件功能。
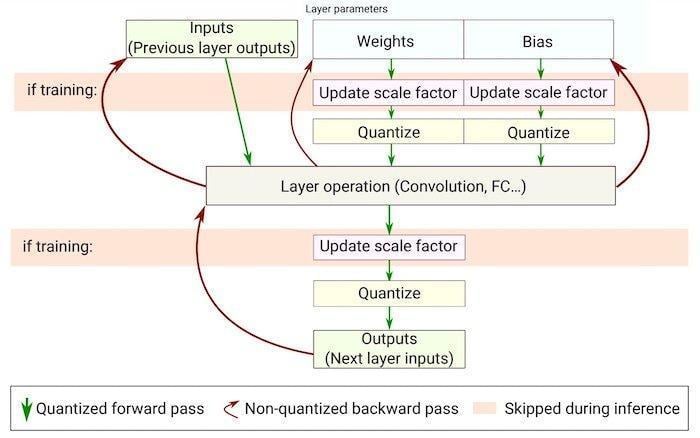
量化感知培训流程图。图片来源:Courtesy of
Novac等人
为此,软件流程包括获取给定的机器学习模型,在所需的数据集上对其进行训练,然后将其缩小以适应边缘设备的约束。这种模型缩放通常通过量化过程来完成,量化过程是降低模型权重和参数的精度以使它们消耗更少内存的过程。
通过这种方式,TinyML工程师可以采用大型机器学习模型,该模型旨在部署在更强大的设备上,并将其缩小以适应边缘设备。nbsp;
正如SiMa.ai所看到的,这种工作流程的问题在于,这些模型实际上并不是为边缘而设计的,而是为边缘而设计的。这在性能和灵活性方面受到限制,因为模型从未真正针对硬件进行优化,反之亦然。
SiMa的新SoC解决方案
为了解决这个问题,SiMa.ai最近发布了他们的MLSoC平台,这是一个“软件优先”的边缘AI SoC。
MLSoC平台基于16 nm工艺构建,是一种异构计算片上系统(SoC),集成了许多专用硬件模块用于AI加速。在这些硬件中,模块包括SiMa.ai专有的机器学习加速器(MLA)。该公司表示,它以10 TOPS/W的速度为神经网络计算提供50 TOPS。
SoC的应用处理单元(APU)由四个1.15 GHzArmCortex-A65双线程处理器组成。还有一个视频编码器和解码器模块以及一个计算机视觉单元(CVU),它由一个四核Synopsys ARC EV 74嵌入式视觉处理器组成。这些模块由4 MB片内存储器以及32位LPDDR4DRAM接口支持。更多信息可在MLSoC产品简介中找到。
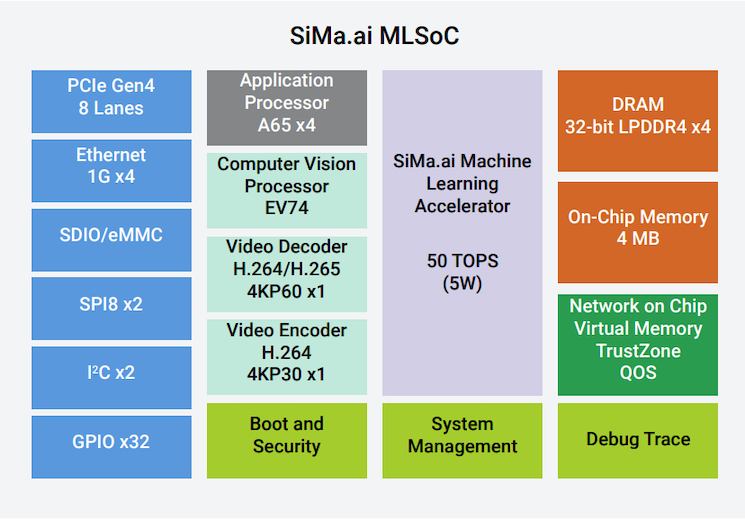
MLSoC的框图。图片来源:Courtesy of
SiMa.ai
然而,除了硬件之外,SiMa.ai声称其MLSoC平台是独一无二的,因为它是与其ML软件工具链共同设计的。具体来说,该公司声称其方法包括精心定义的中间表示以及新颖的编译器优化技术,以支持广泛的框架和网络。
这些框架包括TensorFlow,PyTorch和ONNX等热门框架,同时还声称支持超过120个网络。其想法是,通过使用MLSoC软件工具链,工程师可以开发专门针对MLSoC SoC的ML模型,从而提高设计灵活性、效率和性能。
重新构想TinyML的方法?
总的来说,该公司声称,他们的MLSoC平台现在正在向客户交付,与同类竞争对手相比,可以在计算机视觉方面提供10倍的性能/功耗解决方案。为了支持这一点,他们声称在ResNet-50 v1上具有500 FPS/W的一流DNN推理效率,批量大小为1。nbsp;
凭借其独特的软件/硬件兼容性方法,www.example.com希望重新想象业界对TinyML的方法,并借此释放前所未有的性能和效率。
审核编辑 黄宇
- soc
+关注
关注
38文章
3988浏览量
216771 - AI
+关注
关注
87文章
28544浏览量
265814 - EDGE
+关注
关注
0文章
176浏览量
42559 - ML
+关注
关注
0文章
143浏览量
34410
发布评论请先登录
相关推荐
通过无代码方法开发EdgeAI和ML







 工商网监
工商网监
评论