 美光HBM3E解决方案,高带宽内存助力AI未来发展
美光HBM3E解决方案,高带宽内存助力AI未来发展
美光近期发布的内存和存储产品组合创新备受瞩目,这些成就加速了 AI 的发展。美光8 层堆叠和 12 层堆叠 HBM3E 解决方案提供业界前沿性能,功耗比竞品1低 30%。美光 8 层堆叠 24GB HBM3E 产品将搭载于 NVIDIA H200 Tensor Core GPU 中。在 Six Five Media 最近的一期节目中,主持人 Daniel Newman(Futurum Group 首席执行官)和 Patrick Moorhead(Moor Insights & Strategy 首席执行官)与美光产品管理高级总监 Girish Cherussery 进行了视频访谈。
他们探讨了高带宽内存 (HBM)的广阔市场,并研究了其在当今技术领域的各种应用。这篇文章回顾了他们的谈话,其中话题包括 HBM 的复杂性、美光如何满足市场需求以及目前内存生态系统的发展情况。Girish 还为渴望了解 AI 内存和存储技术市场趋势的听众提供了宝贵的见解。
什么是高带宽内存?有哪些应用领域?
HBM 作为行业标准的封装内存,是一款变革性产品。其以较小的尺寸,在给定容量下实现更高的带宽和能效。正如 Girish 在 Six Five 播客节目中所言,AI 应用部署越来越多的复杂大语言模型 (LLM),由于 GPU 内存容量和带宽有限,训练这些模型面临着挑战。大语言模型的规模呈指数级增长,远远超过了内存容量的增长速度。这一趋势凸显了对内存容量日益增长的需求。
以 GPT-3 为例,该模型有大约 1750 亿个参数。这意味着需要约 800GB 的内存及更高的带宽,以防止出现性能瓶颈。最新的 GPT-4 模型的参数更多(估计达到万亿个)。采用传统方法增加内存器件会导致系统成本过高。
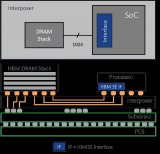
HBM 提供了一种高效的解决方案。美光基于其业界前沿 1β (1-beta) 技术,推出 11mm x 11mm 封装规格堆叠 8 或 12 层 24Gb 裸片的 HBM3E 内存,提供 24GB 或 36GB 容量。美光先进的设计和工艺创新,助力 HBM3E 实现超过 1.2 TB/s 的内存带宽,超过 9.2 Gb/s 的引脚速率。正如 Girish 所言,HBM3E 拥有 16 个独立的高频数据通道,类似于“高速公路车道”,可以更快地来回传输数据,提供所需性能。
美光 HBM3E 更高的容量和带宽缩短了大语言模型的训练时间,为客户节省了大量运营支出。HBM3E 容量更大,支持规模更大的大语言模型,有助于避免 CPU 卸载和 GPU 之间的通信延迟。
HBM3E 功耗很低,因为主机和内存之间的数据路径较短。DRAM 通过硅通孔 (TSV) 与主机通信,Girish 将其形象地比喻为牙签穿过汉堡。其从底层颗粒获取电源和数据,然后将其传输到顶部内存层。凭借基于 1β 制程节点的先进 CMOS 技术创新,以及多达 2 倍硅通孔和封装互连缩小 25% 的先进封装创新,美光 HBM3E 的功耗比竞品低 30%。在每个内存实例 8Gbps 的速率下,功耗降低了 30%,以拥有 500,000 个 GPU 安装基数的客户为例,仅在五年内就可以节约超过 1.23 亿美元运营成本。
因此,正如 Daniel Newman 所言,美光 HBM3E 内存在容量、速度和功耗方面表现优异,对数据中心的可持续发展需求产生了积极影响。
美光 HBM3E 如何满足生成式 AI和高性能计算的需求?
美光相信通过解决各种技术问题,可以帮助人们应对所面临的根本性难题,丰富所有人的生活。
如今,超级计算机模拟技术带来了巨大的内存和带宽需求。正如 Girish 所言,在新冠疫情期间,制药公司迫切需要找到用于治疗新冠病毒的新药物和化合物。HBM 作为高性能计算系统器件,可满足大规模计算的需求,解决当今时代的关键难题。因此,HBM 作为支持大规模计算系统发展的重要器件,以其紧凑的外形尺寸提供所需的性能和容量,同时大幅降低功耗,从根本上改变了人们对内存技术的看法。
随着 AI 时代计算规模的不断扩大,当下的数据中心面临着耗电量高、缺乏建设空间的难题。AI 和高性能计算 (HPC) 工作负载推动提高内存利用率和容量。冷却数据中心所需的能源消耗巨大,也是个挑战。对于采用 HBM 的系统而言,系统冷却位于 DRAM 堆栈顶部,而底部颗粒和 DRAM 层功耗所产生的热量则位于堆栈底部。这要求我们在设计的早期阶段就考虑功耗和散热问题。美光先进的封装创新技术提供了改善热阻抗的结构解决方案,有助于改善立方体的散热表现。结合大幅降低的功耗,整体散热表现将大大优于竞品。美光 HBM3E 的功耗更低、散热效率更高,有助于应对数据中心面临的重大挑战。
AI 内存解决方案的新兴趋势是什么?
生成式 AI 在从云到边缘的各种应用中迅速普及,推动了异构计算环境中系统架构的重大创新。AI 正在加速推动边缘应用的发展趋势,如工业 4.0、自动驾驶汽车、AI 个人电脑和 AI 智能手机等。正如 Girish 所分享的,这些长期趋势推动了内存子系统的重大技术创新,以提供更高的容量、带宽、可靠性和更低的功耗。
美光基于 1β 技术的 LPDDR5X 产品组合为这些系统提供了出色的性能/功耗,可用于边缘 AI 推理。美光率先在市场上推出基于 LPDDR5X 的创新型 LPCAMM2,旨在提升个人电脑用户的体验,推动 AI 个人电脑革命。
数据中心架构也在不断演变。美光单颗粒大容量 RDIMM 推动了全球数据中心服务器在 AI、内存数据库和通用计算工作负载方面的进步。我们率先上市的 128GB 大容量 RDIMM 性能卓越、容量大、延迟低,可高效处理需要更大容量内存的应用程序,包括从 GPU 卸载到 CPU 处理的 AI 工作负载。
我们还看到,由于 LPDDR 内存(低功耗 DRAM)在性能/功耗方面的优势,越来越多的数据中心将其用于 AI 加速和推理应用。美光显存 GDDR6X 的引脚速率达到惊人的 24 Gb/s,也被用于数据中心的推理应用中。
美光率先推出的另一种新兴内存解决方案 CXL 内存,可为数据中心应用提供内存和带宽扩展。美光 CXL 内存模块 CZ120可为 AI、内存数据库、高性能计算和通用计算工作负载提供内存扩展。
AI 正在为人类开创一个新时代,触及我们生活的方方面面。随着社会不断利用 AI 的潜力,AI 将继续推动数字经济中各行业的快速创新。数据是数字经济的核心,也是内存和存储解决方案的核心。美光已做好准备,凭借其技术实力、创新内存和存储解决方案的强大产品组合及强有力的路线图,以及致力于通过改变世界使用信息的方式丰富全人类生活的承诺,助推 AI 革命。
审核编辑:刘清
-
DRAM
+关注
关注
40文章
2310浏览量
183435 -
GPT
+关注
关注
0文章
352浏览量
15342 -
大模型
+关注
关注
2文章
2423浏览量
2637 -
生成式AI
+关注
关注
0文章
502浏览量
471 -
HBM3E
+关注
关注
0文章
78浏览量
248
原文标题:美光 HBM3E:高带宽内存助力 AI 未来发展
文章出处:【微信号:gh_195c6bf0b140,微信公众号:Micron美光科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
美光12层堆叠HBM3E 36GB内存启动交付
三星电子HBM3E内存获英伟达认证,加速AI GPU市场布局
SK海力士9月底将量产12层HBM3E高性能内存
三星否认HBM3E通过英伟达测试传闻
什么是HBM3E内存?Rambus HBM3E/3内存控制器内核
美光开始量产HBM3E解决方案
美光科技开始量产HBM3E高带宽内存解决方案
美光量产行业领先的HBM3E解决方案,加速人工智能发展

美光开始量产行业领先的 HBM3E 解决方案,加速人工智能发展






 工商网监
工商网监
评论