 服务器数据恢复—异常断电导致存储瘫痪的数据恢复案例
服务器数据恢复—异常断电导致存储瘫痪的数据恢复案例
服务器存储数据恢复环境:
一台存储中有一组由12块SAS硬盘组建的RAID6磁盘阵列,划分为一个卷,分配给几台Vmware ESXI主机做共享存储。该卷中存放了大量Windows虚拟机,这些虚拟机系统盘是统一大小,数据盘大小不确定,数据盘是精简模式。
服务器存储故障:
机房断电导致服务器存储异常关机,加电后存储无法使用。
服务器存储数据恢复过程:
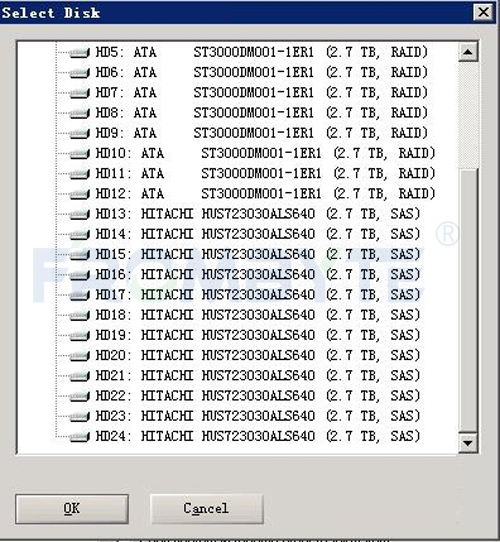
1、将故障服务器存储的所有磁盘和备份数据的目标磁盘接入到Windows Server服务器上。将磁盘都设为脱机(只读)状态,看到的连接状态如下所示(HD1-HD12为目标备份磁盘,HD13-HD24为源故障磁盘,型号为HUS723030ALS640):
 北亚企安数据恢复——存储数据恢复
北亚企安数据恢复——存储数据恢复
2、使用工具在底层读取HD13-HD24扇区,发现了大量损坏扇区,数据恢复工程师初步推断出现这种情况的原因是这种硬盘的读取机制与常见硬盘不一样。尝试更换主机、HBA卡、扩展柜,并将操作系统更换为Linux,均呈现相同故障表现。与用户方工程师沟通,用户方工程师回应此控制器对磁盘没有特殊要求。
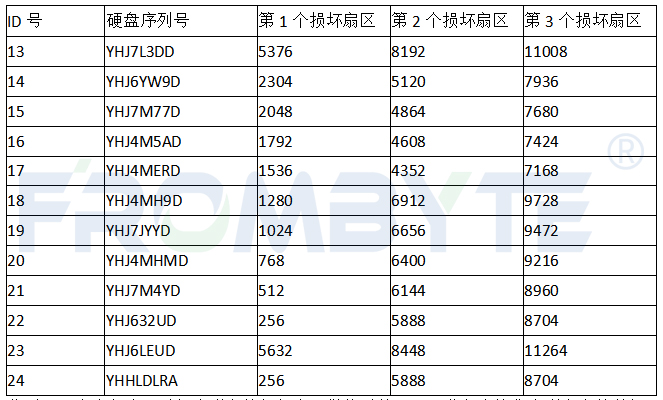
检测硬盘损坏扇区的分布规律,服务器数据恢复工程师发现以下规则:
a、损坏扇区分布以256个扇区为单位。
b、除损坏扇区片断的起始位置不固定外,后面的损坏扇区都是以2816个扇区为间隔。
所有磁盘的损坏扇区(部分)分布:
 北亚企安数据恢复——存储数据恢复
北亚企安数据恢复——存储数据恢复
北亚企安数据恢复工程师编写小程序,绕过处理每个磁盘的损坏扇区,将所有盘的数据做只读镜像。
3、基于镜像文件分析所有磁盘的底层数据。
经过分析发现损坏扇区呈规律性出现:
-每段损坏扇区区域大小总为256。
-损坏扇区分布为固定区域,每跳过11个256扇区遇到一个坏的256扇区。
-损坏扇区的位置一直存在于RAID的P校验或Q校验区域。
-所有硬盘中只有10号盘中有一个自然坏道。
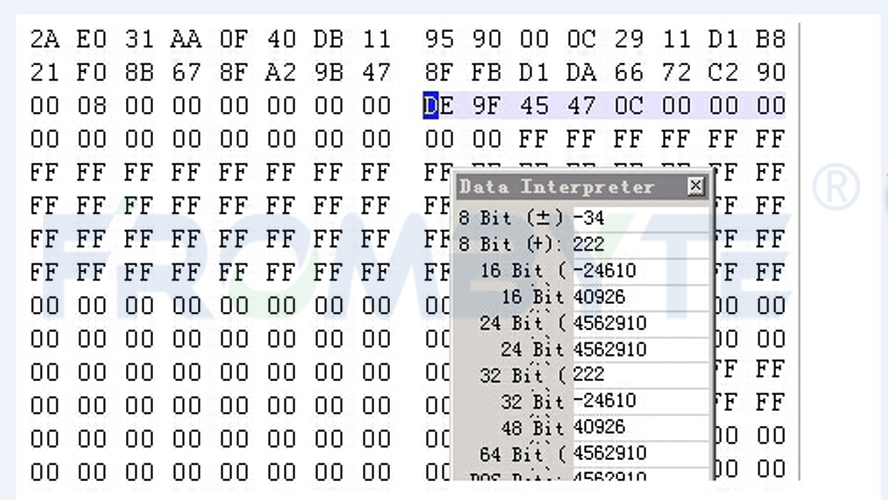
分析HD13、HD23、HD24的0-2扇区得知分区大小为52735352798扇区,按RAID6的模式计算,将分区大小除以9等于5859483644扇区,与物理硬盘大小以及DS800控制器中保留的RAID信息区域大小吻合。根据物理硬盘底层表现,分区表大小为512字节,后面无8字节校验,大量的0扇区也无8字节校验。故原存储并未启用存储中常用的DA技术(520字节扇区)。
分区大小如下图(GPT分区表项底层表现,涂色部分表示分区大小,单位512字节扇区,64bit):
 北亚企安数据恢复——存储数据恢复
北亚企安数据恢复——存储数据恢复
4、存储使用的是标准RAID6阵列,只需要分析出RAID成员盘数量以及RAID走向就可以重组RAID。
-分析RAID条带大小
整个存储被划分为一个大的卷,分配给几台ESXI做共享存储,卷的文件系统是VMFS。该VMFS卷中存放了大量的Windows虚拟机。Windows虚拟机大多使用NTFS文件系统,因此可以根据NTFS中MFT的顺序分析出RAID条带大小以及RAID走向。
-分析RAID是否存在掉线盘
镜像完所有磁盘后发现最后一块硬盘中并没有像其他硬盘一样有大量的坏道。最后一块硬盘中有大量未损坏扇区,这些未损坏扇区大多是全0扇区,因此可以判断这块硬盘是热备盘。
5、根据分析出来的RAID结构重组RAID。重组完成后能看到目录结构,但不确定是否为最新状态。随机检测几个虚拟机发现部分虚拟机数据异常,初步判断RAID中存在掉线的磁盘。依次将RAID中的每一块磁盘踢掉,然后查看刚才数据异常的地方,没有找到问题原因。
6、分析底层数据后发现问题不是出在RAID层面,而是出在VMFS文件系统层面。由于VMFS文件系统如果大于16TB会存在一些其他的记录信息,因此在组建RAID的时候需要跳过这些记录信息。再次重组RAID后查看以前数据异常的地方,已经没有问题了。
针对其中的一台虚拟机做验证,将所有磁盘加入RIAD中后,这台虚拟机是可以启动的,但缺盘的情况下启动有问题,因此可以判断整个RAID处在不缺盘的状态为最佳。
验证数据:
1、验证虚拟机
验证较为重要的虚拟机,发现大多数虚拟机都可以开机,进入登录界面。部分虚拟机开机蓝屏或开机检测磁盘,但是使用光盘修复之后都可以正常启动。
部分虚拟机开机如下:
 北亚企安数据恢复——存储数据恢复
北亚企安数据恢复——存储数据恢复
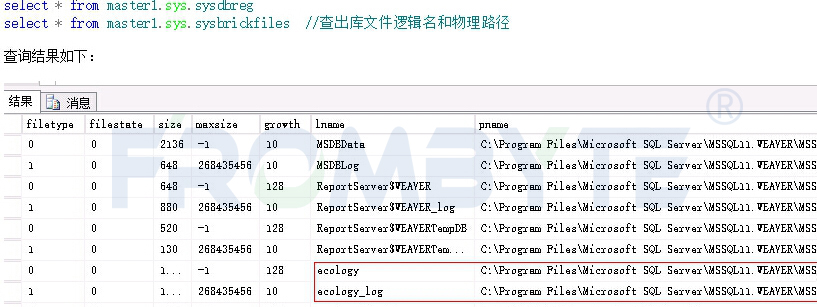
2、验证数据库
验证重要虚拟机中的数据库,发现数据库都正常。通过查询master数据库中的系统视图,查出所有数据库信息如下:
 北亚企安数据恢复——存储数据恢复
北亚企安数据恢复——存储数据恢复
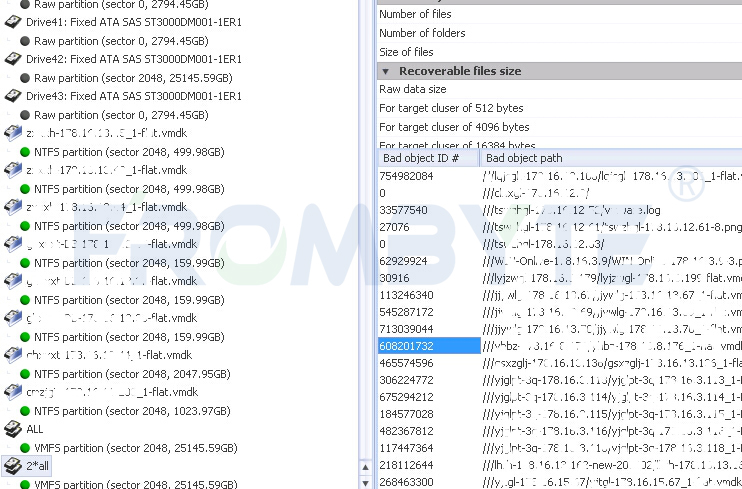
3、检测整个VMFS卷是否完整
由于虚拟机数量很多,每台都验证的话,所需的时间会很长,因此检测整个VMFS卷,在检测VMFS卷的过程中发现部分虚拟机或虚拟机的文件被破坏。
 北亚企安数据恢复——存储数据恢复
北亚企安数据恢复——存储数据恢复
批量恢复数据:
1、和用户方沟通并且通报了目前恢复数据的情况。用户对几台重要的虚拟机进行验证后,认可恢复的数据。于是北亚企安数据恢复工程师着手恢复所有数据。
准备好目标RAID,将重组的RAID数据镜像到目标阵列上,然后使用工具解析整个VMFS。
2、将恢复出来的VMFS卷连接到虚拟化环境中的一台ESXI5.5主机上,尝试将该VMFS卷挂载到的ESXI5.5的环境中。由于版本(用户方的ESXI主机是5.0版本)原因或VMFS本身有损坏,导致挂载不成功。
移交数据:
北亚企安数据恢复工程师将目标阵列上的数据带到用户方现场,使用工具导出VMFS卷中的虚拟机。
1、将目标阵列上的数据通过HBA卡连接到用户的VCenter服务器上。
2、在VCenter服务器安装工具,然后使用工具解释VMFS卷。
3、使用工具将VMFS卷中的虚拟机导入到VCenter服务器上。
4、使用VCenter的上传功能将虚拟机上传到ESXI的存储中。
5、将上传完的虚拟机添加到清单,开机验证。
6、如果有虚拟机开机出现问题,则尝试使用命令行模式修复;或者重建虚拟机并将恢复的虚拟机磁盘(既VMDK文件)拷贝过去。
7、由于部分虚拟机的数据盘很大,而数据很少。这种情况就可以直接导出数据,然后新建一个虚拟磁盘,最后将导出的数据拷贝至新建的虚拟磁盘中即可。
统计了一下整个存储中虚拟机的数量,整个存储中大约有200台虚拟机。目前的情况只能通过上述方式将恢复出来的虚拟机一台一台的恢复到用户的ESXI中。
总结:
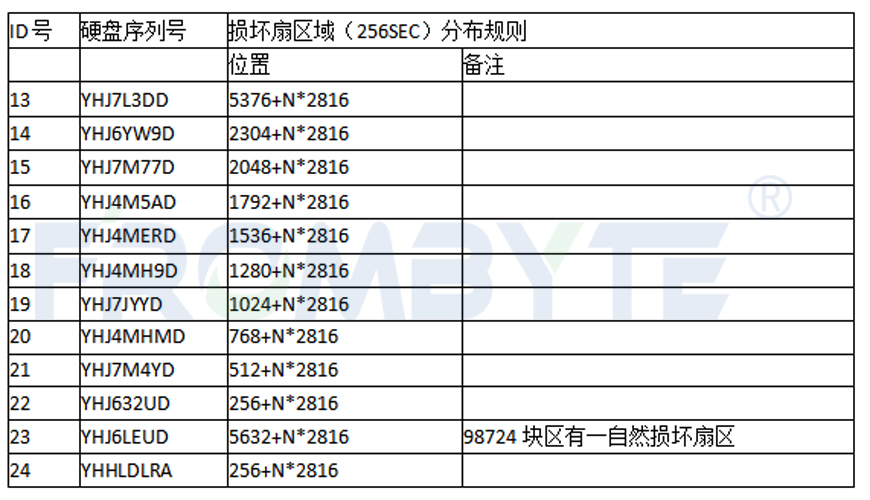
所有磁盘坏道的规律如下表:
 北亚企安数据恢复——存储数据恢复
北亚企安数据恢复——存储数据恢复
经过分析后得到关于坏道的规则表现:
-除去SN:YHJ6LEUD上的一个自然坏道外,其余坏道均分布于RAID6的Q校验块中。
-坏道区域多数表现为完整的256个扇区,正好是当时创建RAID6时的一个完整RAID块大小。
-活动区域表现为坏道,非活动区域坏道有可能不出现,如热备盘,由于上线不足10%,所以坏道数量就比其他在线盘少。
-其他非Q校验区域完好,无任何故障。
结论:通过上述坏道规则表现可推断:坏道为控制器生成Q校验,向硬盘下达IO指令时,可能表现为非标指令,硬盘内部处理异常,导致出现规律性坏道。
存储故障是由坏道引起的,导致恢复出来的数据有部分破坏,但不影响整体,结果也在可接受范围内。
审核编辑 黄宇
-
服务器
+关注
关注
12文章
9123浏览量
85320 -
数据恢复
+关注
关注
10文章
568浏览量
17432 -
RAID6
+关注
关注
0文章
9浏览量
5933
发布评论请先 登录
相关推荐
服务器数据恢复—异常断电导致linux系统无法启动的数据恢复案例
虚拟机数据恢复—异常断电导致XenServer虚拟机不可用的数据恢复案例
服务器数据恢复—意外断电导致虚拟机虚拟磁盘损坏的数据恢复案例
服务器数据恢复—异常断电导致RAID信息丢失的数据恢复案例
服务器数据恢复—异常断电导致虚拟机配置文件丢失的数据恢复案例

服务器数据恢复—EqualLogic存储硬盘故障导致存储崩溃的数据恢复案例
服务器数据恢复—VMware虚拟机无法启动的数据恢复案例
服务器数据恢复—异常断电导致RAID管理信息丢失的数据恢复案例
服务器数据恢复—异常断电导致服务器raid卡硬件损坏的数据恢复案例
服务器数据恢复-异常断电导致服务器故障的数据恢复案例
【服务器数据恢复】断电导致服务器RAID信息丢失的数据恢复案例






 工商网监
工商网监
评论